注意事項
本記事で取り上げている Workbench についてはサポート終了となっています。詳しくは下記を参照ください。
https://docs.microsoft.com/ja-jp/azure/machine-learning/overview-what-happened-to-workbench
はじめに
この記事は Microsoft Azure Tech Advent Calendar 2017 の9日目の記事です。
このままシリーズ化するかどうかは未定ですが、その前に書きかけのシリーズ(1/2/3)を何とかしたい今日この頃です。
今さら Azure Machine Learning ?
今回取り上げるのは、Azure Machine Learning サービスです。Azure には、以前から Azure Machine Learning という機械学習を簡単に利用するための開発環境+展開環境を提供するサービスがあります。しかし、先日のイベントにおいて、新たに Azure Machine Learning サービスが発表され、以前の Azure Machine Learning は現在、Azure Machine Learning Studio という名称に変更されています。
というわけで、決して今さらな内容ではないことを、まずはご承知おきください。
説明の順序を考えると、Azure Machine Learning サービスがどのようなもので構成されているかをお伝えするのが先かもしれませんが、本記事では開発環境となる Workbench で大きく変わったデータの整形機能を紹介してみたいと思います。(全体感は追々ということで)
環境の準備
機能を単に紹介するよりは、実際に動かしてみたいと思います。セットアップが完了するまでそこそこ時間がかかるのでくじけず行きましょう。
Machine Learning 実験アカウントのセットアップ
Workbench を利用するためには、前提となるサービスの展開が必要になります。最近の Azure 系のドキュメントは割と手順がきれいに纏まっているので、細かい手順はこちらを参照いただくとして、ここでは要点だけざっくりと。
Machine Learning 実験、またはMachine Learning Experimentationを展開します。アクセスする経路によってまだ表記ゆれがあります(2017/12現在)

- シート数の指定は注意が必要です。パラメーターに明記されていますが、3名以上で利用する場合は課金額が変わってきます。
- Machine Learning 実験に対して、複数のワークスペースを作成できますが、初回の展開時には、まず一つ目を作成する必要があります。
Machine Learning Workbench のインストール
前述のセットアップ内に、Workbench のダウンロードリンクがあります。インストールの処理内で必要なコンポーネントを自動でダウンロードしてくるので、インターネット接続が可能な環境にインストールします。インストール対象のスペックによって前後しますが、30分から60分くらいは見ておく必要があるかと思います。
ちなみに、同時にインストールされるモジュール類は以下です。(2017年12月、0.1.1711.15263 で確認)
- Azure_cli_machinelearning (0.0.70+dev)
- Azureml.dataprep (0.1.1709.14033) and other azure libraries
- Conda (4.2.12)
- Numpy (1.11.3)
- Pandas (0.19.2)
- Dill (0.2.6)
- Numexpr (2.6.1)
- Scipy (0.18.1)
- Regex (2017.07.28)
- Xlrd (1.1.0)
- Pyarrow (0.6.0)
- scikit-learn (0.18.1)
- jupyter (1.0.0)
- psutil (5.2.2)
えー、それ古くない?というものもあろうかと思いますが、まずはこれらがインストールされます。
Machine Learning Workbench の起動
ここまでくれば、起動して動作を確認できます。Workbench の初回起動時には、サインインを求められます。

Machine Learning 実験の展開時に同時に作成したワークスペースにアクセスするためです。
サインインのアカウントには Machine Learning 実験の展開時に指定した、ワークスペースの所有者アカウントを使用します。
下記は、私のワークスペースの表示ですが、既に作成済みのプロジェクトが表示されています。
データ整形機能を使ってみる
ここからが本題です。
プロジェクトの作成
プロジェクトを新規作成します。とりあえず使ってみたい方はチュートリアルに従って Classifying Iris あたりから試していただくのがよいかと思います。
ここでは、空のプロジェクトを作成します。

プロジェクト名と格納先のディレクトリを指定します。VSTS の Git リポジトリを使用することで、複数の端末やエンジニアによる共同編集が行えるようになります。ちなみに、この記事を書いている時点(2017/12)では、Github等には未対応です。

プロジェクトが作成できました。

データの取得
どんなデータが分かりやすいか悩みましたが、あくまでもデータの整形が紹介したいポイントなので、以下のデータを使っていきたいと思います。
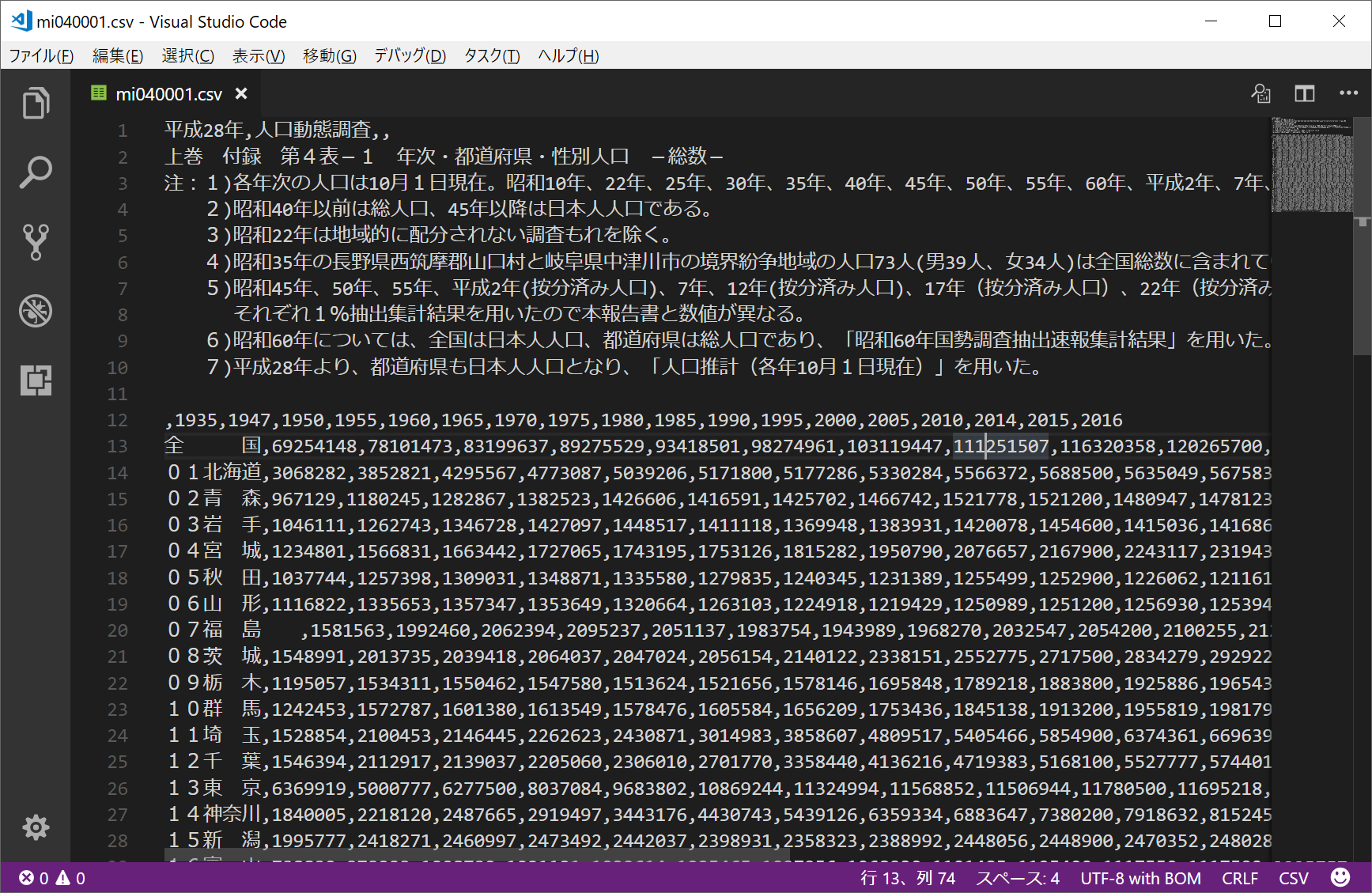
上記から、4_年次・都道府県・性別人口_(1) 総数 をダウンロードしておきます。データの内容は以下のような感じです。

なお、現時点ではいい感じに日本語表記が取り込めないので、エンコードを UTF-8 に変更します。
データの読み込み
データ用のビューに切り替えて、データソースを追加します。
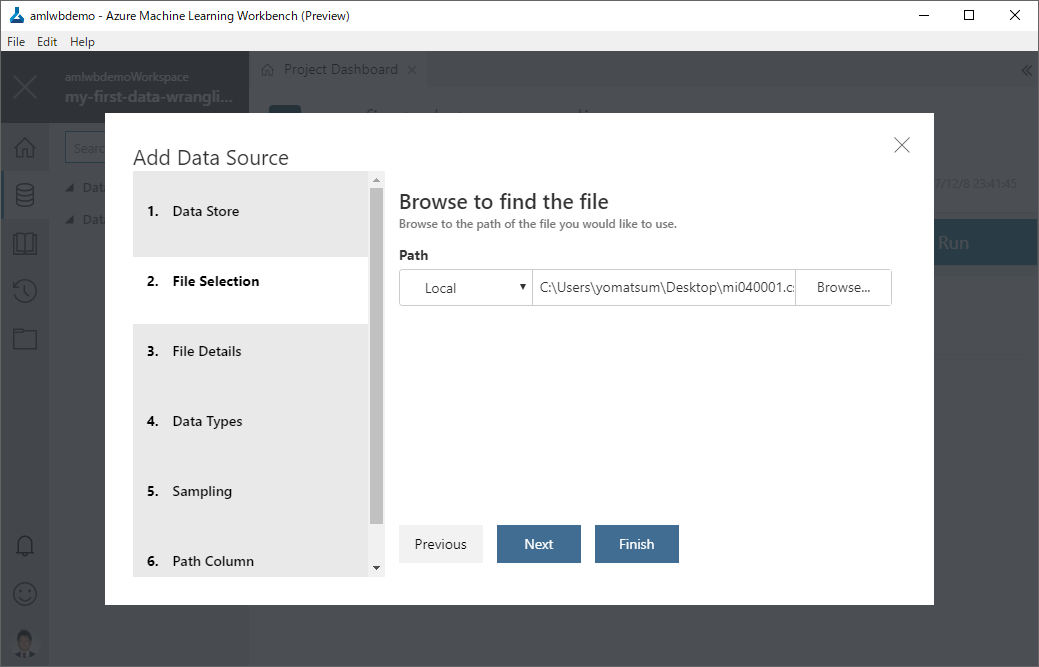
CSV としてダウンロードしてきているので、Text Files を指定して進めていきます。

CSV ファイルのパスを指定します。
次の画面では、指定するポイントがいくつかあります。
- Line to skip には 11 を指定しています。西暦年がヘッダーとして含まれていますが、自動的に除外されてしまっているため、取り込む開始行をコントロールするためです。
- File Encoding には UTF-8 を指定します。
- Promote Headers Mode には Use Headers From First File を指定します。ファイル内の先頭行がヘッダーになります。
上記を指定すると、プレビューとしての表示が変わります。

データ型は、既定の状態のままとします。事前にデータを見ていただくとわかるのですが、沖縄県については特定の年代のデータが欠落しています。このため、埋まっている文字列を自動的に考慮して String 型が指定されています。
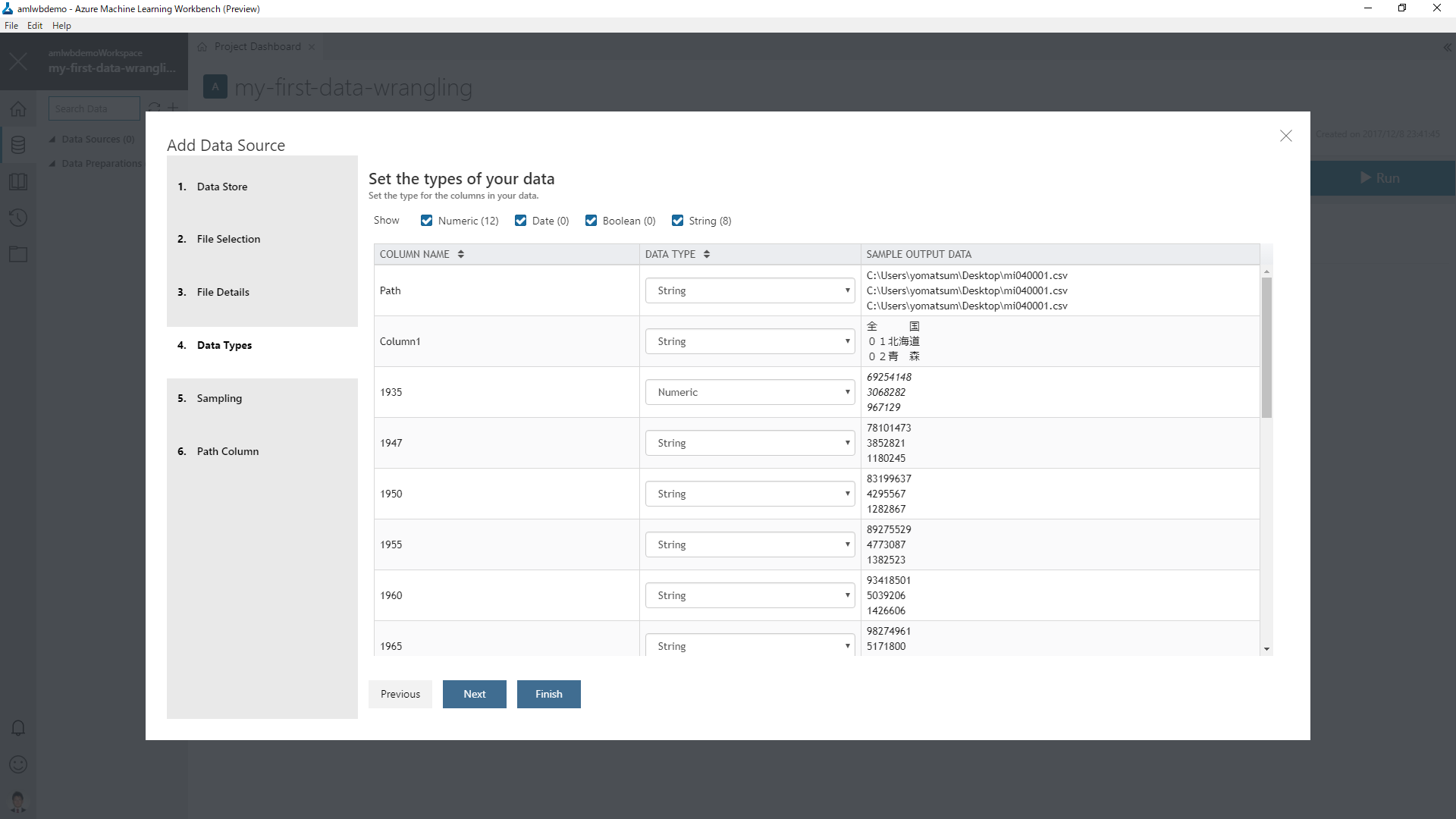
最後に、Path Column をどうするか指定します。今回は除外するという既定の設定を採用します。
これで、Workbench へのデータの取り込みは完了です。画面の右側に、データの読み込み時に設定した内容が STEPS として記録されています。
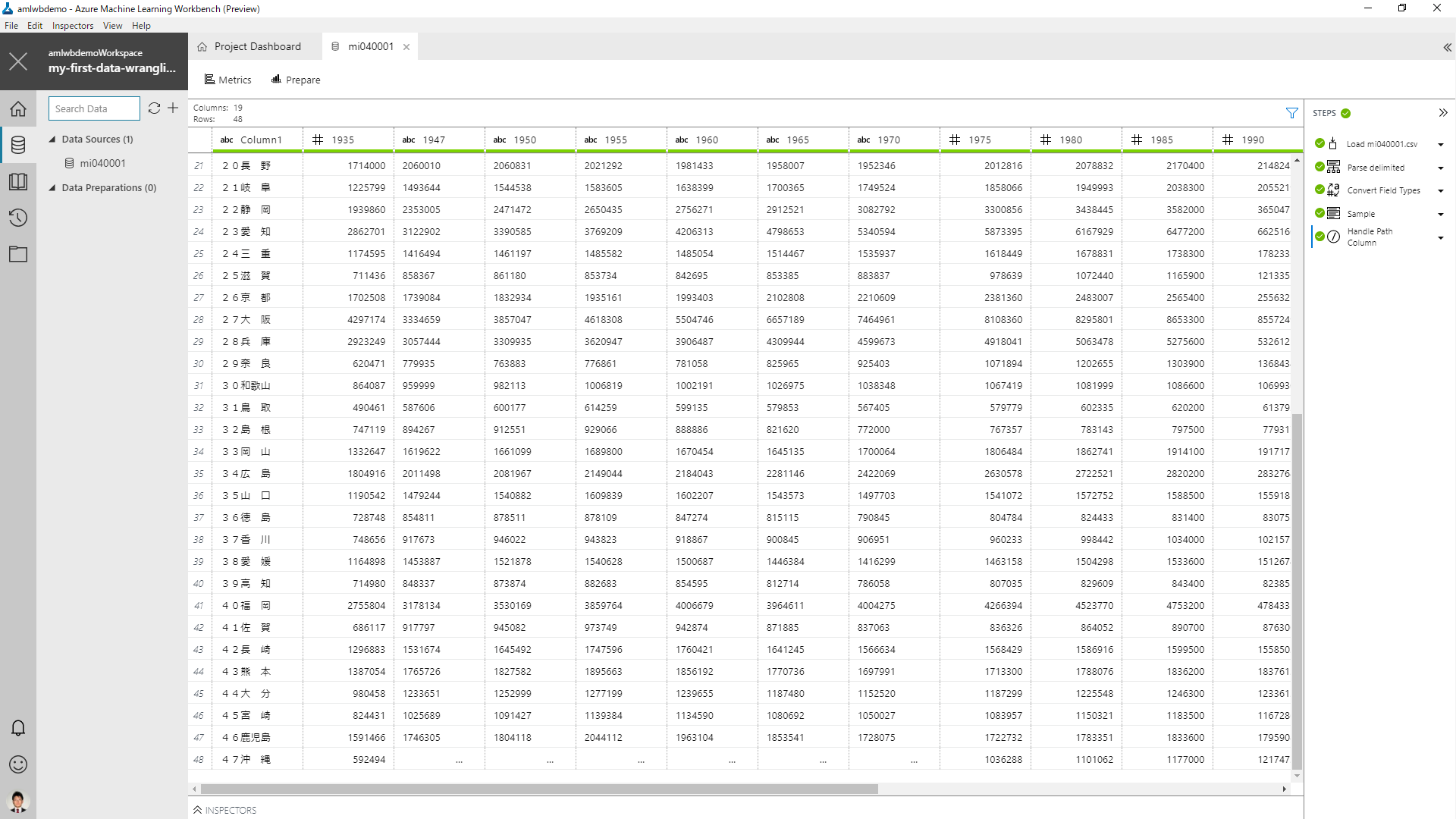
データの加工
実際の分析にデータを利用するためには、もう少しデータを加工する必要があるケースが大半です。ここでは、シンプルなデータの加工と、Workbench に備わっている便利な機能が分かるようなデータ加工を追加してみたいと思います。
読み込んだデータを加工するためには、Data Preparation を作成する必要があります。画面上部の Prepare をクリックすると、Data Preparation の作成画面が表示されます。適切な名前を設定しましょう。

データ加工用の画面に切り替わります。パッと見た感じは何も変わっていないように見えますが、新しいタブとして表示されています。

列の削除
数値データの欠損があったので、古いデータは今回は使わないという選択をしたと仮定します。1935年から1995年までのデータは取り除いてしまいます。
複数の列を選択し、右クリックから Remove Columns を選択します。

画面から列が削除され、ずいぶんとスッキリしました。

行の削除
全国合計のデータは不要な気がします。フィルターを使って取り除きましょう。

データを加工した列を追加
Column1 に都道府県番号が付与されているため、これを取り除いた列を作ってみましょう。Column1 の列を選択して右クリックから Derive Column by Example を選択します。
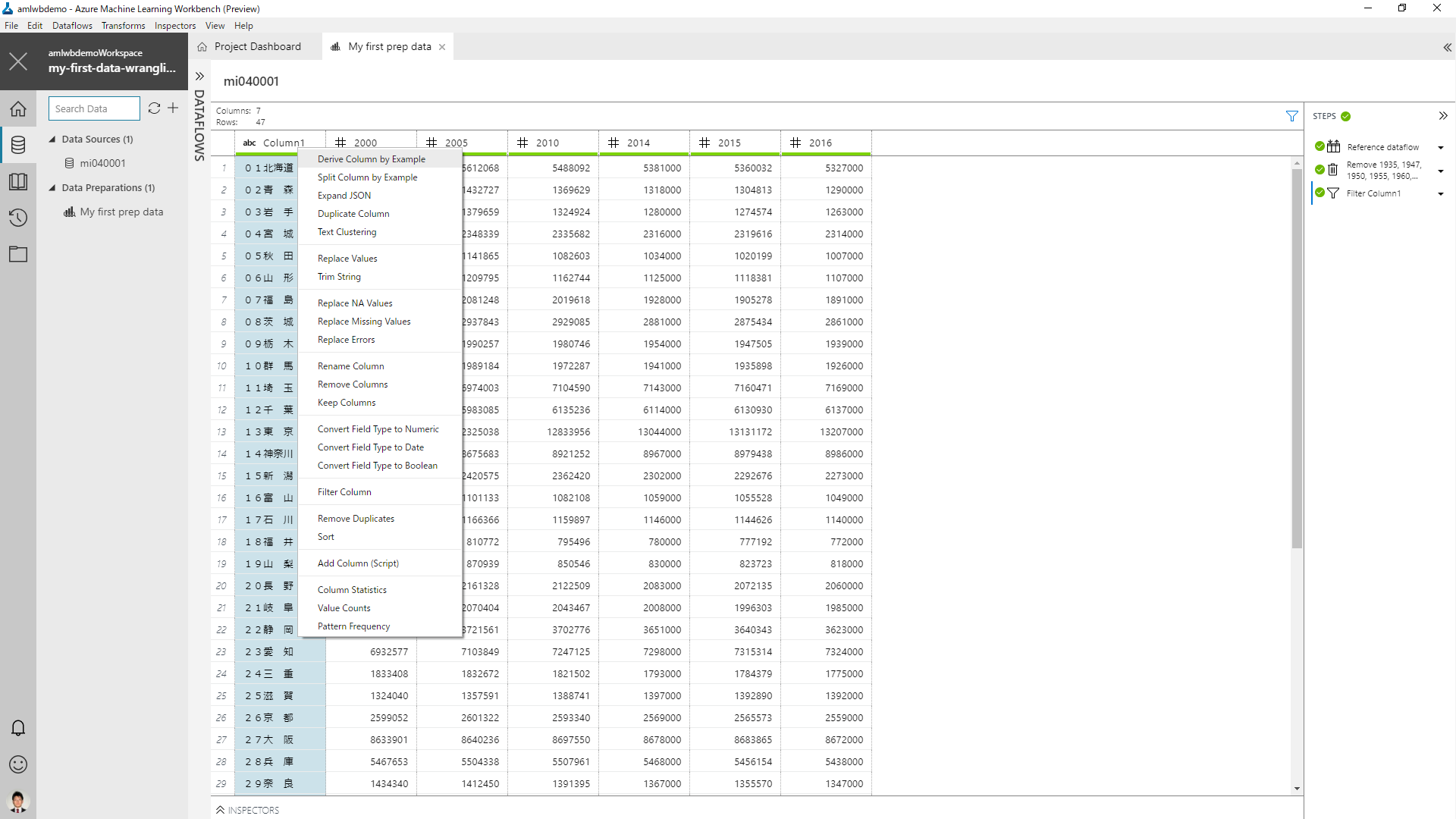
列に対してチェックボックスが表示され、空の列が追加されます。この追加された列に、加工後の期待する値を入力してみます。

まずは、1行目の「01北海道」に対して「北海道」を入力します。すると、追加された Column 列に都道府県番号が削除された値が一律で設定されます。通常、データの加工に関しては、私たちが加工のための変換ルールをコードで実装していく必要があります。(Excel でも関数を駆使しますよね。)Machine Learning Workbench はコードを検討するのではなく、どういう結果が欲しいかを記載することで、加工済みのデータを得ることができます。
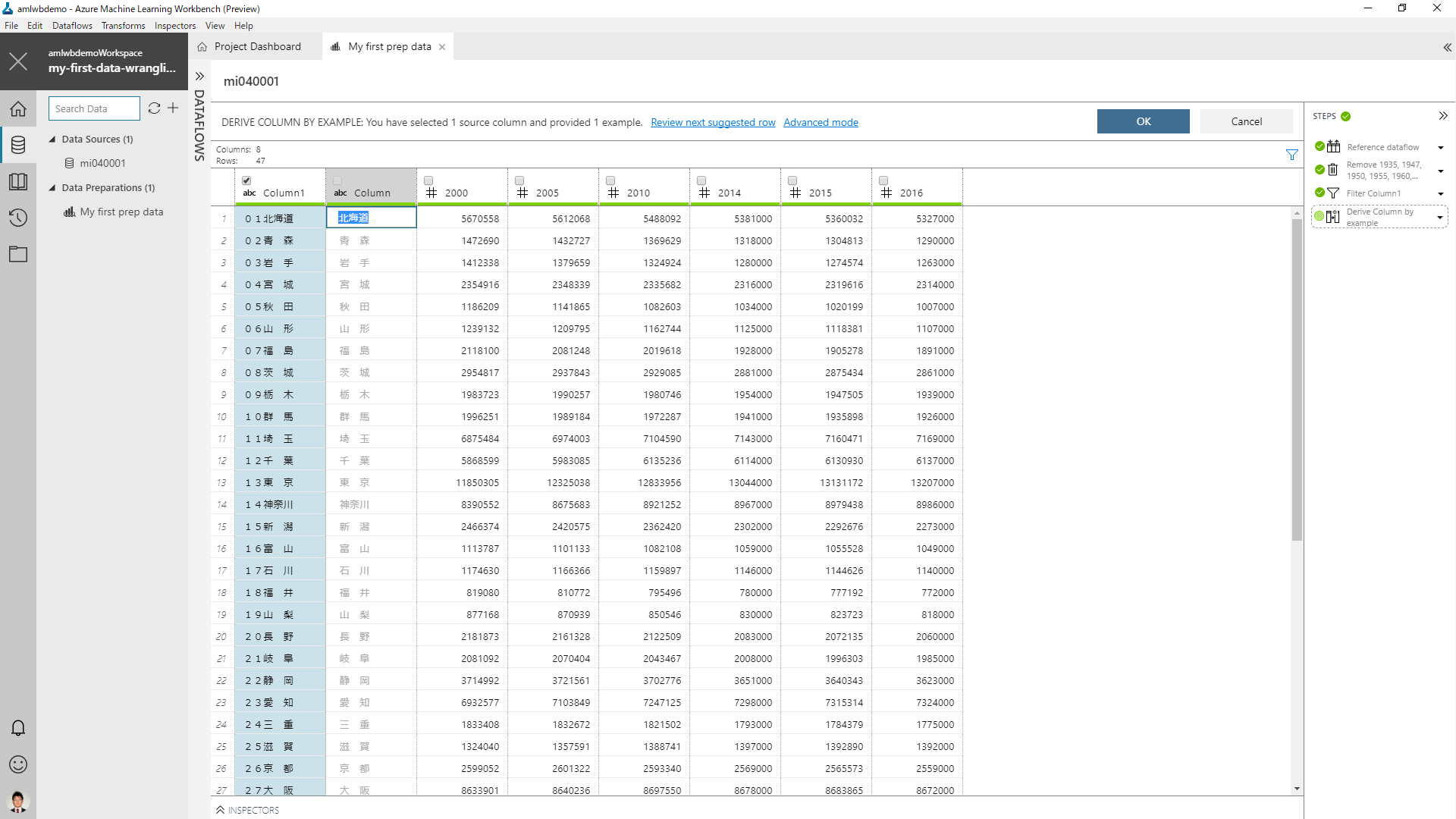
別の変換を試してみたいので、まずは「OK」をクリックして確定させます。併せて列名を「変換1」としておきます。

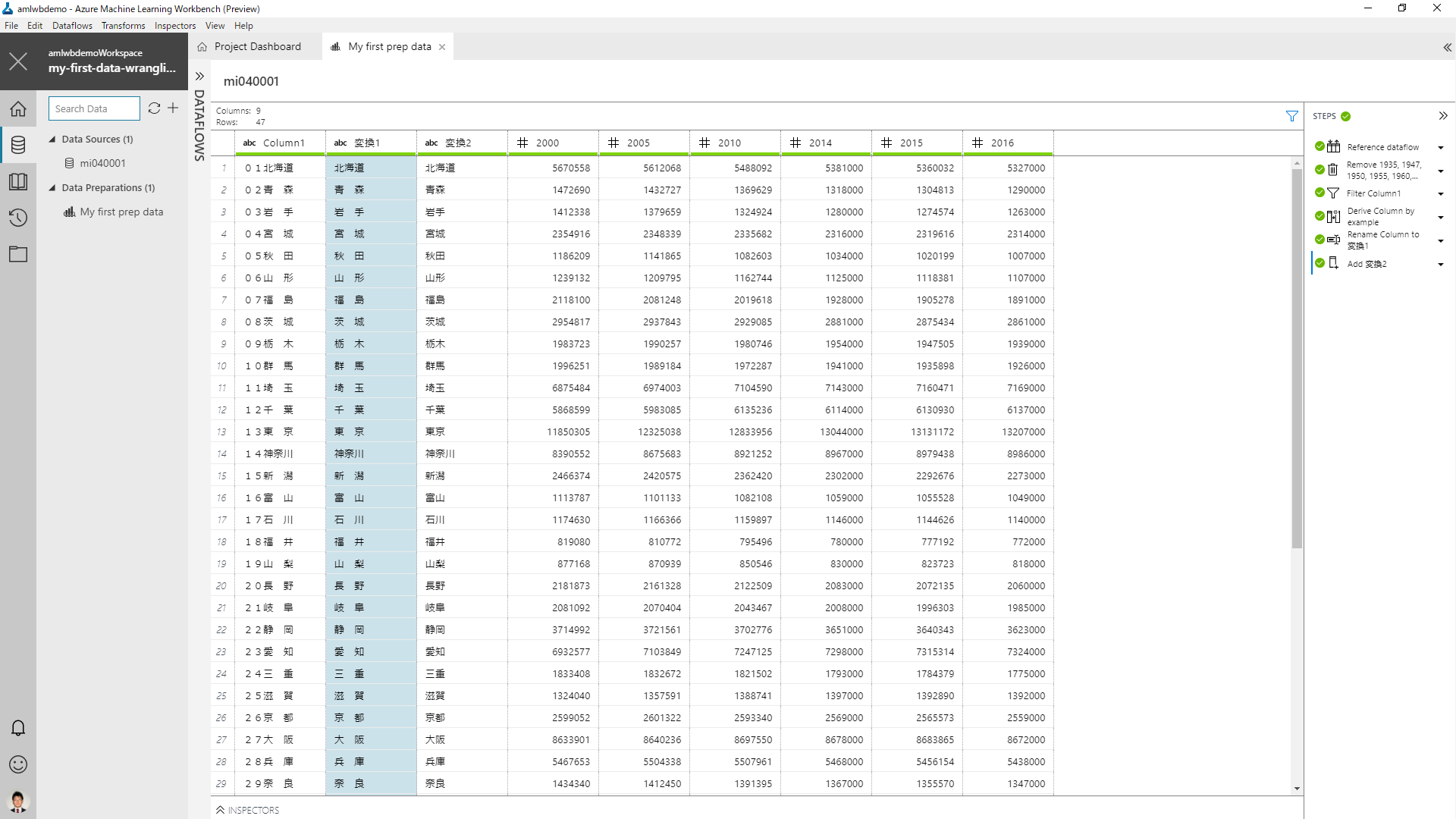
次に、少し欲張って都道府県番号と空白文字が除去できないかを試してみます。もう一度、Column1 から Derive Column by Example で新しく列を作成し、今度は2行目に「青森」を設定してみます。都道府県番号と同時に間の空白も除去してくれます。

その一方で、北海道や神奈川など三文字の場合は何も埋まりません。試しに北海道に対して「北海道」入力してみると、他の都道府県の処理が全部行われなくなってしまいます。(この後の説明は、この変換をキャンセルした状態で進めます)

このように、こちらの期待するありとあらゆる変換を満たしてくれるわけではありません。何ができるかについては、ドキュメントにまとまっているのでこちらを参照しましょう。
というわけで、空白を削除するところは自分でコードを書いてみます。変換1 列を右クリックして Add Column (Script) を選択します。

列名は任意の列名を指定します。挿入位置も指定できます。Python コードとしては、以下を入力してみます。
row["変換1"].replace(' ','')

これで、無事に空白も除去できました。
都道府県番号の除去については、今回コードを書かずに例を設定するという対応をしました。このように「例から変換ルールを導出する」部分については、PROSE なるものが使用されています。
PROSE (Microsoft Program Synthesis using Examples)
入力と出力のペアをいくつか例として与えることで、変換ルールを導出するためのライブラリです。Excel でいうところのフラッシュフィル機能ですよ、なんていう説明がなされています。
一通りのリソースは https://microsoft.github.io/prose/ からアクセスできます。動作用のサンプルもあります。
まとめ
Azure Machine Learning の第二世代として登場した Azure Machine Learning Workbench は、データの整形を効率的に行うための機能が備わっています。データ分析の8割の時間はデータ整形ともいわれることもありますので、積極的に活用していきたいと思います。