Splunkは様々なデータに対応した統合ログプラットフォームです。
SPLというサーチ言語を利用してログから自分の見たい情報を抽出、Commnadsを活要して集計処理やデータの加工など様々なことが可能です。
本記事ではSplunkそのものや様々なCommandsの解説はしないためSplunkをより詳しく知りたい方はチートシートや公式ドキュメントを参照いただければと思います。日本語マニュアルも充実しています。
summary indexについて
summary indexはより高速に必要データを検索するための手法の1つです。ZOZOでも過去にtechblogで取り上げています。
ダッシュボードなどで表示させたいデータが定まっているなら大規模になってしまったindexから都度Searchをかけるよりも事前にバックグラウンドで欲しいデータを収集し、別のindexに入れてそこからサーチをかければデータ量が少ないので結果表示までも早いよねって話です。
collect command
上述したtechblogでもcollect indexによるsummary indexが紹介されています。
以下のように時系列の何らかのイベント件数を高速で表示させたいと言った場合にSPLの末尾に| collect <収集先index名>を指定してやることで指定したindexにデータが格納されます。
index=main sourcetype=ms:iis:auto host=hoge
| timechart span=1m count
| collect index=summary-index
この結果timechartコマンドにより付与された時刻(_time)とその間のイベント件数(count)がsummary indexには入ります。
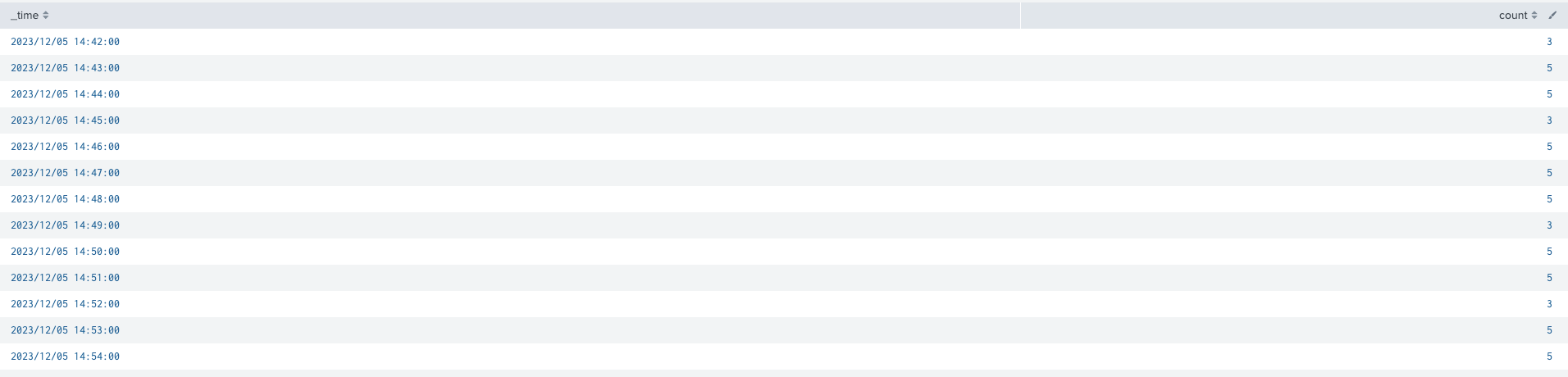
このサーチをレポートとしてスケジュールでバックグラウンドで実行することでsummary indexにデータが入っていきます。
このsummary indexからまたデータを呼び出すには以下のようなSPLを記載します。
index=summary-index
| table _time count
バックグラウンドで実行したサーチ側で既に分単位の件数データに変換されているので、summary index側ではこのタイミングで変換・集計などののCommandsを使うことなくtable形式で表示だけさせてやれば良いのでサーチにかかるコストも低いよねといった感じです。
collect commandで起こりうる問題
レポートとしてバックグラウンドで実行する際に対象のサーチを過去何分・何時間に渡り実行するかを選択するのですがここに落とし穴があります。
例えば大元となるindex側でなんらかの理由によりデータ取り込みが遅延した場合にcollect command側はその事情を知らないためデータを0件として扱います。
欠損したデータは大元に遅れてでも入っていてくれれば後で手動でcollect commandで収集し補完することも可能ですが、少し面倒です。
どう回避するか
公式ドキュメントに答えがありました。
SPLにcollect commandを記述するのではなくレポート機能からサマリーインデックスを有効化し、耐久サーチを有効化することで上述した問題を回避できるようです。
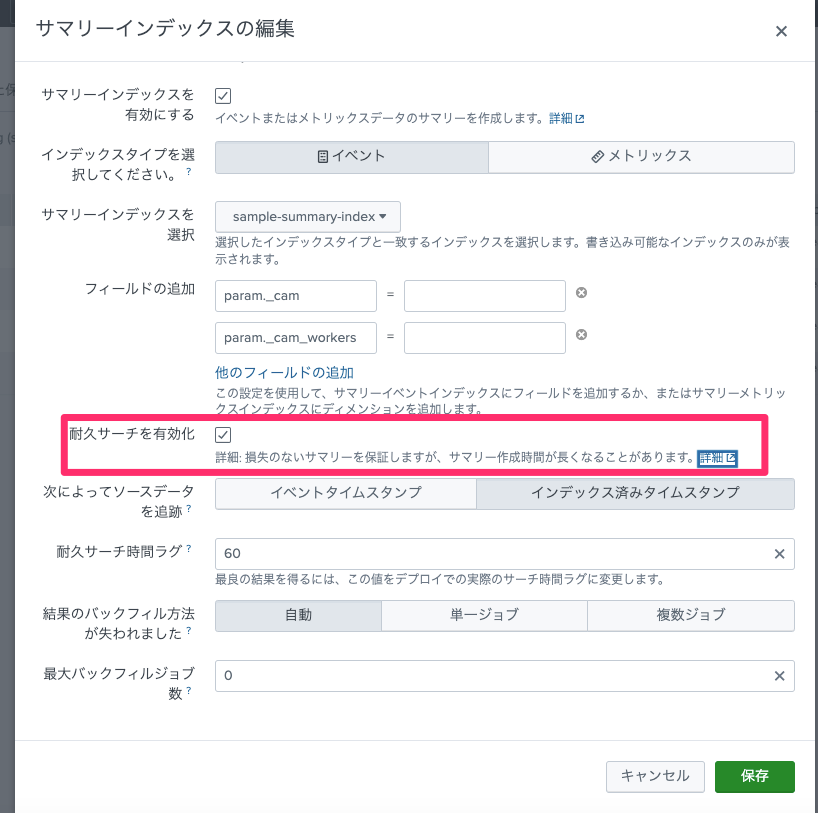
動きを見てみる
以下を元データとして同一間隔(今回は1分)でcollect commandで収集するケースとレポート機能のsummary indexの結果を比較します。
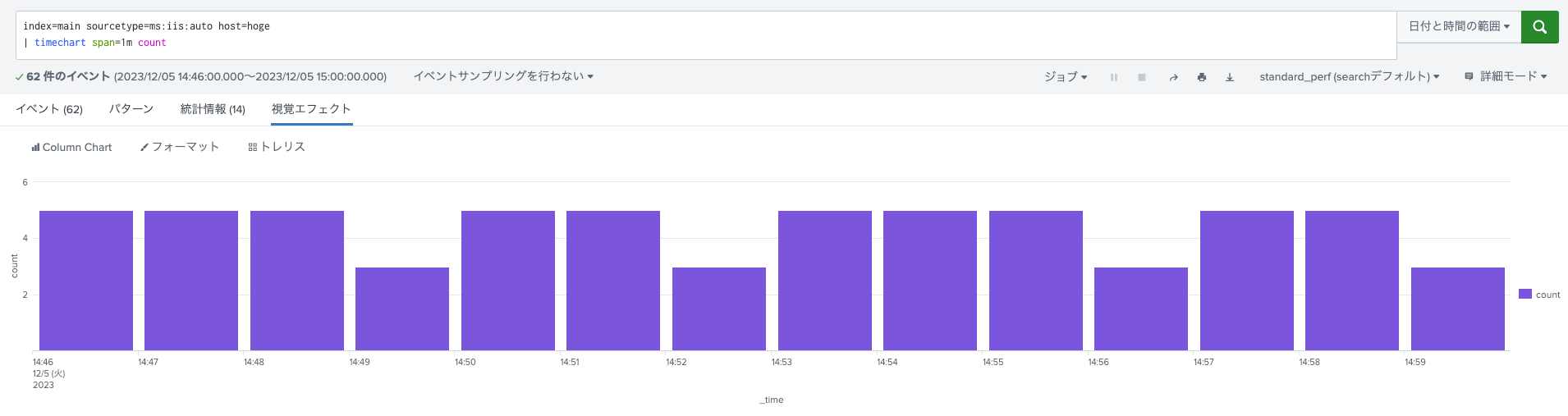
index=main sourcetype=ms:iis:auto host=hoge
| timechart span=1m count
host=hogeは単一のマシンでSplunkのAgentであるUniversal Forwarderがインストールされています。
host側のUniversal Forwarderを一時的に停止することで一時的にmain側のIndexにデータが入らなくなり、その後再度Universal Forwarderを起動すると停止した時点のデータからSplunkにデータを送ってくれるため問題となる事象が再現できます。
以下それぞれのサーチ結果です。
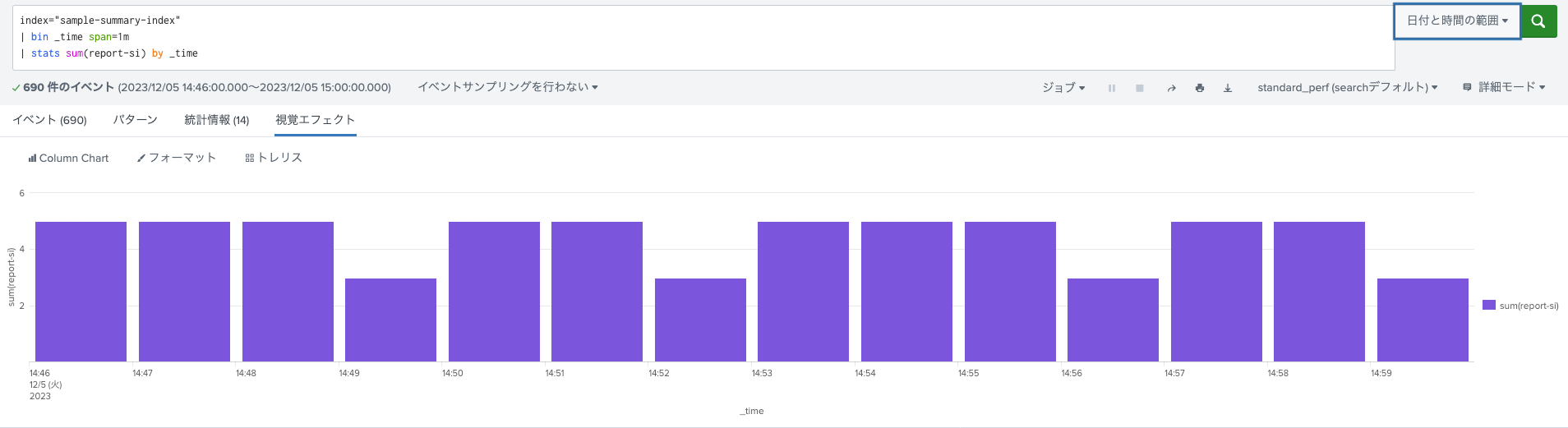
- Summary indexを使わない普通のサーチ文での集計結果
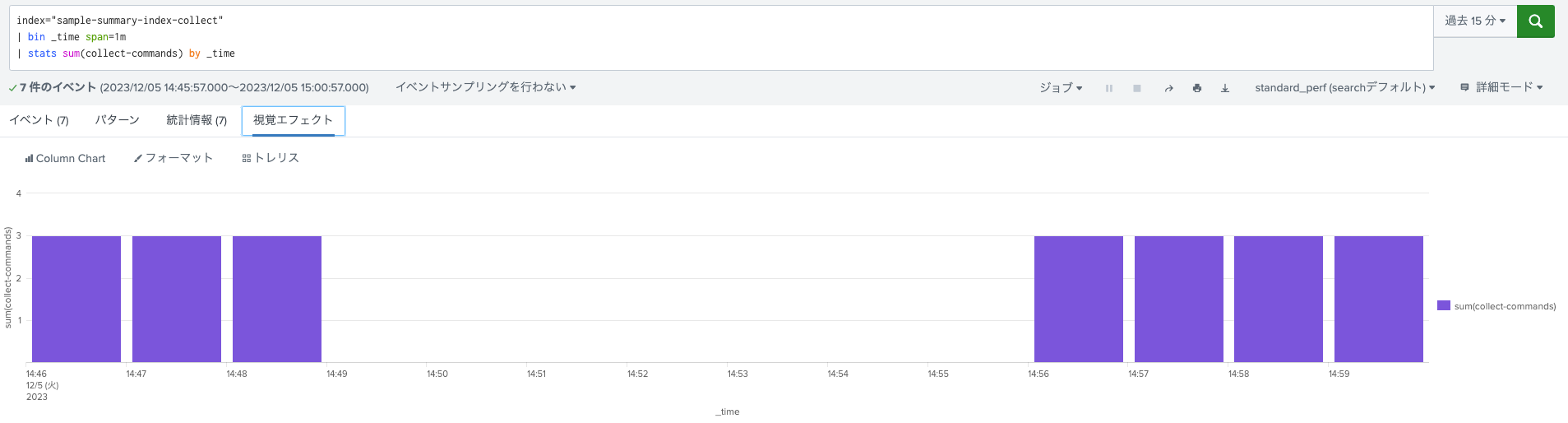
- collect commandで収集したsummary indexでの集計結果
- Universal Forwarderを停止していた時間でデータの欠損が確認できます(というかちょっと周期的に元データ件数とも乖離が見られる状態に。。今回は欠損するということを表現したかったのでこれで良しとしました。)
- レポート機能のsummary indexを使った場合
- Universal Forwarder再開まではログがない状態でしたが、後でしっかりデータが入ってきました。
まとめ
- レポート機能からsummary indexを有効化し耐久サーチを有効化することで、データ取り込み遅延時などのsummary indexデータ欠損を防ぐことができる
- ただし、summary indexに入ってくるまでに若干のタイムラグがあったためcollectコマンドよりかは収集が遅くなってしまうようです
- 今回のケースだと1分に1回収集しているがデータがsummary index側に入ってくるまでに3m程ラグがありました
今後も何かいい機能があれば検証してみたいと思います!