iOS 11のVision Frameworkでは、既存の機械学習モデルを使った画像認識だけでなく、カスタムの学習モデルを使った自分だけの画像認識エンジンを構築することができます。
今回は、先ごろAppleよりリリースされたTuri Createというツールを使ってオリジナルのCore MLモデルを作成し、Vision Frameworkから呼び出して使用することで、iOS上でオリジナルの犬猫識別エンジンを実装してみます。

動作環境
- MacBook Pro (13-inch, 2017)
- macOS 10.13.2 (17C88)
- Xcode 9.2 (9C40b)
- Anaconda 5.0.1 (Python 3.6)
Turi CreateはPython 2.7、Bing Image SearchはPython 3.6で動かすので、Anaconda上でTuri用、Bing用の環境をそれぞれ作成しました。

CUIが苦手な方はAnaconda Navigatorを起動して、下にある "+" (Create) ボタンをクリックし、Pythonのバージョンを選択することで環境を作成することができます。
それぞれの環境を切り替える際も、リストの横にある三角ボタンをクリックし、"Open Terminal"を選択すればその環境のターミナルが立ち上がります。
学習用画像の取得 (Bing Image Search API)
この手のエンジンを作る際に面倒なのが学習用の画像を大量に集めることですね。手元に画像がない場合はネットから学習用画像をクローリングしてくることになると思いますが、その方法は
- Google画像検索などの結果をスクレイピング
- 画像検索APIを利用
のいずれかになるでしょう。とりあえずそこそこの品質の画像を、一番手っ取り早く集められる方法を検討した結果、後者でBing Image Search APIを利用するのがよいという結論に達しました(Google Custom Search APIはバグか仕様か100枚以上取得できないらしいので回避)。
スクリプトに関しては下記で紹介されていたものをほぼ丸ごと使用させていただいています。
Python 3.6 + Bing API v7に対応させるために下記の部分を修正しています。
- sha3のimportを削除
- APIのリクエストメソッドをPOSTからGETに変更
- 戻り値の処理
# -*- coding: utf-8 -*-
import http.client
import json
import re
import requests
import os
import math
import pickle
import urllib
import hashlib
def make_dir(path):
if not os.path.isdir(path):
os.mkdir(path)
def make_correspondence_table(correspondence_table, original_url, hashed_url):
"""Create reference table of hash value and original URL.
"""
correspondence_table[original_url] = hashed_url
def make_img_path(save_dir_path, url):
"""Hash the image url and create the path
Args:
save_dir_path (str): Path to save image dir.
url (str): An url of image.
Returns:
Path of hashed image URL.
"""
save_img_path = os.path.join(save_dir_path, 'imgs')
make_dir(save_img_path)
file_extension = os.path.splitext(url)[-1]
if file_extension.lower() in ('.jpg', '.jpeg', '.gif', '.png', '.bmp'):
encoded_url = url.encode('utf-8') # required encoding for hashed
hashed_url = hashlib.sha3_256(encoded_url).hexdigest()
full_path = os.path.join(save_img_path, hashed_url + file_extension.lower())
make_correspondence_table(correspondence_table, url, hashed_url)
return full_path
else:
raise ValueError('Not applicable file extension')
def download_image(url, timeout=10):
response = requests.get(url, allow_redirects=True, timeout=timeout)
if response.status_code != 200:
error = Exception("HTTP status: " + response.status_code)
raise error
content_type = response.headers["content-type"]
if 'image' not in content_type:
error = Exception("Content-Type: " + content_type)
raise error
return response.content
def save_image(filename, image):
with open(filename, "wb") as fout:
fout.write(image)
if __name__ == "__main__":
query = 'cats' # 検索対象
save_dir_path = 'data/' + query
make_dir(save_dir_path)
num_imgs_required = 100 # Number of images you want. The number to be divisible by 'num_imgs_per_transaction'
num_imgs_per_transaction = 100 # default 30, Max 150
offset_count = math.floor(num_imgs_required / num_imgs_per_transaction)
url_list = []
correspondence_table = {}
headers = {
# Request headers
'Content-Type': 'multipart/form-data',
'Ocp-Apim-Subscription-Key': 'ここにAPIKeyをペースト', # API key
}
for offset in range(offset_count):
params = urllib.parse.urlencode({
# Request parameters
'q': query,
'count': num_imgs_per_transaction,
'offset': offset * num_imgs_per_transaction # increment offset by 'num_imgs_per_transaction' (for example 0, 150, 300)
})
try:
conn = http.client.HTTPSConnection('api.cognitive.microsoft.com')
conn.request("GET", "/bing/v7.0/images/search?%s" % params, "{body}", headers)
# 7.0からはPOSTではなくGETになった模様
response = conn.getresponse()
data = response.read()
save_res_path = os.path.join(save_dir_path, 'pickle_files')
make_dir(save_res_path)
with open(os.path.join(save_res_path, '{}.pickle'.format(offset)), mode='wb') as f:
pickle.dump(data, f)
conn.close()
except Exception as err:
print("[Errno {0}] {1}".format(err.errno, err.strerror))
else:
decode_res = data.decode('utf-8')
data = json.loads(decode_res)
pattern = r"&r=(http.+)&p=" # extract an URL of image
for values in data['value']:
# ここの処理も不要
# unquoted_url = urllib.parse.unquote(values['contentUrl'])
# img_url = re.search(pattern, unquoted_url)
# if img_url:
# url_list.append(img_url.group(1))
url = values['contentUrl']
print(url)
url_list.append(url)
for url in url_list:
try:
img_path = make_img_path(save_dir_path, url)
image = download_image(url)
save_image(img_path, image)
print('saved image... {}'.format(url))
except KeyboardInterrupt:
break
except Exception as err:
print("%s" % (err))
correspondence_table_path = os.path.join(save_dir_path, 'corr_table')
make_dir(correspondence_table_path)
with open(os.path.join(correspondence_table_path, 'corr_table.json'), mode='w') as f:
json.dump(correspondence_table, f)
queryの部分に取得したい画像のキーワードを入れ、API Keyを取得したものに置き換えて
$ python bing.py
と実行すればフォルダ内に画像がわさわさと保存されていくはずです。
今回はキーワードを'dogs'と'cats'の2種類で実行し、犬と猫の画像を約100枚ずつ集めました。
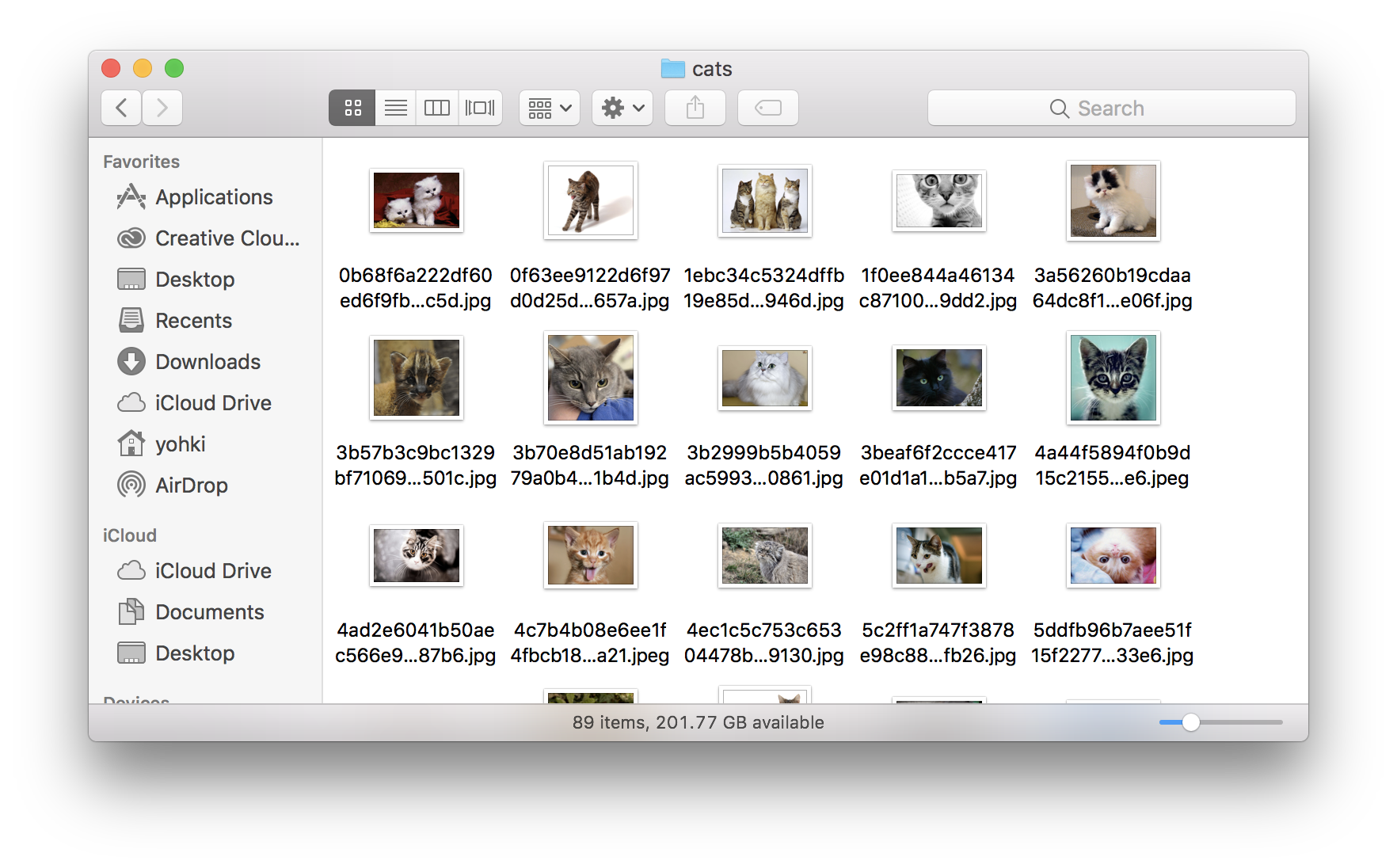
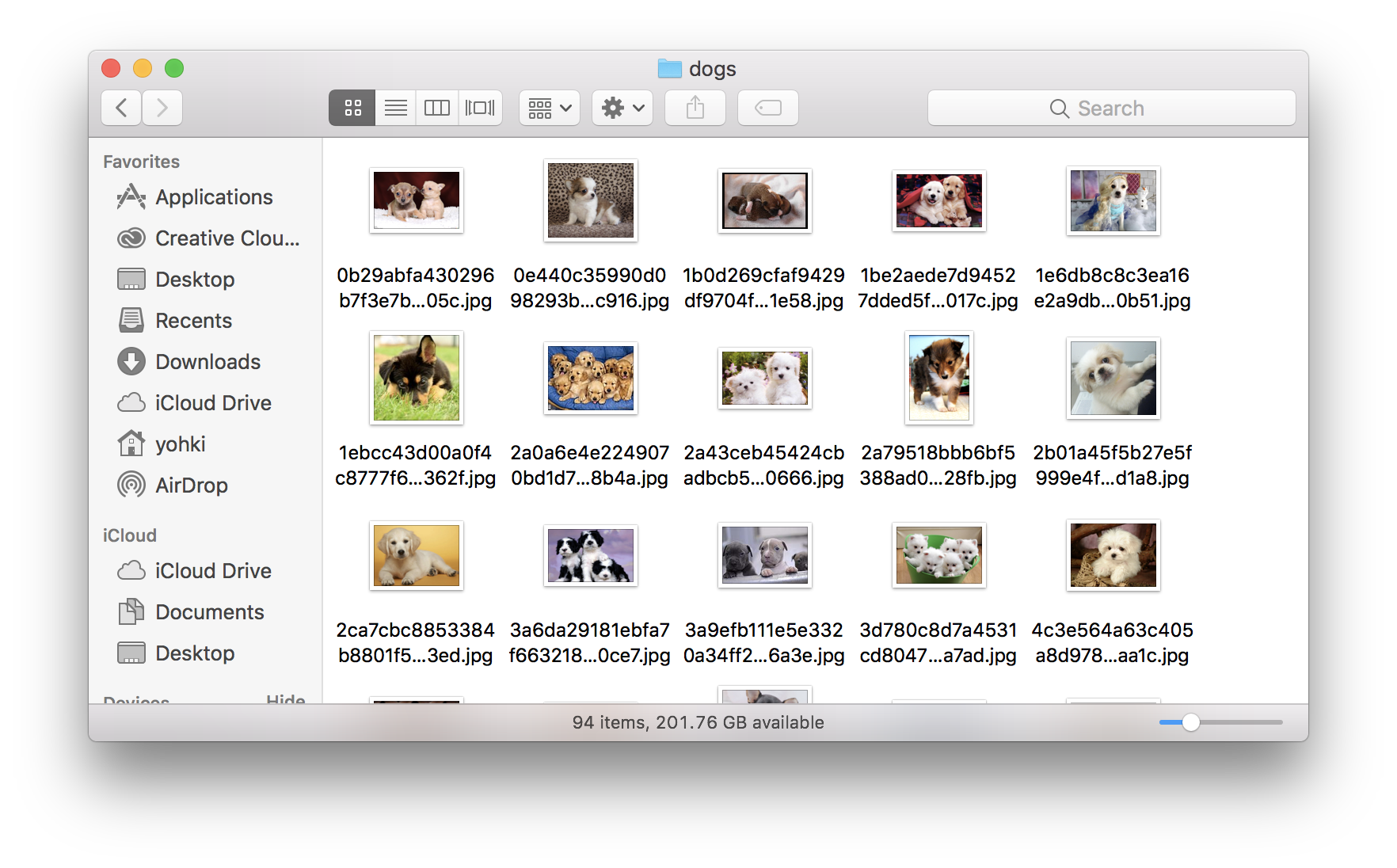
モデルの作成 (Turi Create)
画像がたくさん集まったところで、それらを使ってモデルを作成します。
まず、Python 2.7環境でturicreateをインストールします。
$ pip install -U turicreate
あとはサンプルコードほぼそのまんまです。
import turicreate as tc
# 画像の読み込み
data = tc.image_analysis.load_images('train', with_path=True)
# 画像のパスに'dog'が含まれる画像は'dog'、そうでなければ'cat'とラベリング
data['label'] = data['path'].apply(lambda path: 'dog' if 'dog' in path else 'cat')
# データを保存
data.save('cats-dogs.sframe')
# 学習用と検証用にデータを分割
train_data, test_data = data.random_split(0.8)
# 画像分類モデルを作成
model = tc.image_classifier.create(train_data, target='label')
# テストデータを使って検証
predictions = model.predict(test_data)
# 評価結果を出力
metrics = model.evaluate(test_data)
print(metrics['accuracy'])
# モデルを保存
model.save('mymodel.model')
# Core ML用モデルを書き出し
model.export_coreml('MyCustomImageClassifier.mlmodel')
このPythonスクリプトと同じ階層にtrain/cats, train/dogsディレクトリを作成し、その中に先ほど収集した画像を置いておきます。その状態で
$ python model.py
とスクリプトを実行するだけです。うまく行けばMyCustomImageClassifier.mlmodelという名前のファイルができているはずです。

アプリケーションへの組み込みと呼び出し (Core ML / Vision Framework)
最後のステップとして、出来上がったmlmodelをアプリケーションに組み込みます。
入力画像に対して認識器をかけるのは、CoreMLを直接触るとそれなりに面倒ですが、Vision Frameworkを使うとあっさり実現できます。
今回はこちらで使われていたサンプルコードを使用させていただきました。
既存モデルの削除
まずプロジェクトファイルをXcodeで開き、既存の学習モデル (Resnet50.mlmodel) を削除します。
mlmodelの追加
次に作成したばかりのMyCustomImageClassifier.mlmodelをドラッグ&ドロップして追加します。モデルを選択すると、中央のペインにモデルの種類やサイズだけでなく、対応するSwiftのクラス (MyCustomImageClassifier) が自動的に生成されていることや、カラー画像を入力として、分類結果のラベル名と信頼度が得られることなどが表示されます。

Swiftコードの修正
ViewController.swiftを修正します。モデルクラスを初期化しているところを書き換えるだけです。
// CoreMLのモデルクラスの初期化
guard let model = try? VNCoreMLModel(for: Resnet50().model) else { return }
を
// CoreMLのモデルクラスの初期化
guard let model = try? VNCoreMLModel(for: MyCustomImageClassifier().model) else { return }
にするだけです。かんたん!
実行結果
それぞれ100枚しか使ってないですが、それなりに動いているように見えます。

おわりに
私自身はiOSもPythonも素人に毛が生えたようなレベルですが、Turi Createと先人の知恵を使わせていただくことで簡単にオリジナルの画像認識エンジンを組み込むことができました。細かいチューニングになるとまた闇が深い感じもしますが、簡単な用途であればアプリへの組み込みも難しくなさそうです。
それではみなさま、よいお年を!