はじめに
ディープラーニングにおけるDropoutは単純かつ強力な正則化手法として広く使われていますが、RNNの時間方向に適用するとノイズが蓄積してうまく学習できないため、入出力層にのみ適用するのが常識とされてきました[Zaremba 2014]1。しかし最近の研究でDropoutをベイズ的に解釈することでRNNの時間方向にもDropoutを適用でき、言語モデルのタスクで単一モデルとして最高精度を達成することが示されました[Gal 2016]2 今回は変分Dropoutと呼ばれるこのモデルをTensorFlowで実装したので紹介したいと思います。
Dropoutのベイズ的解釈とRNNへの適用
ニューラルネットワークのパラメータの事後分布を「学習する通常のパラメータ」と「学習しないパラメータ=0」の2つを中心とする混合ガウス分布で近似することによりDropoutと同様のアルゴリズムが得られることがわかっています。Dropoutの解釈として異なるネットワークのアンサンブルを採用した場合と異なり、この解釈ではパラメータを共有するレイヤーは同じユニットをdropする必要があります。RNNでは時間方向で同じパラメータを共有しますから、どのユニットをdropするかを決める0/1の値を取るマスクを異なる時刻で共有することでこの解釈を実装することができます。
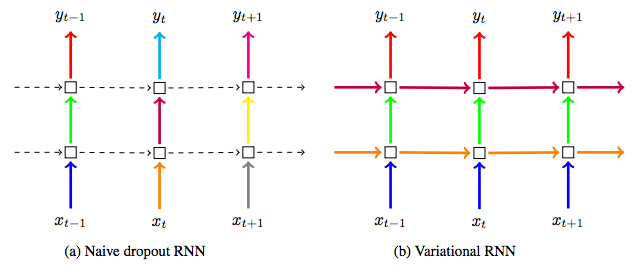
図における異なる色はDropoutのマスクが異なることを表し、点線はDropoutが適用されないことを表しています。従来のDropoutが時間方向への適用を避けて入出力層にのみ適用されるのに対し、変分Dropoutでは時間方向にも適用し毎時刻で同じマスクを共有します。
TensorFlowによる実装
TensorFlow 0.10を使って変分Dropoutを実装しました。TensorFlowのRNNチュートリアルでは[Zaremba 2014]を実装していますから、これをもとに改造していきます。実装するのは論文中のuntied(no MC)です。
import tensorflow as tf
from tensorflow.python.ops.rnn_cell import RNNCell
def get_dropout_mask(keep_prob, shape):
keep_prob = tf.convert_to_tensor(keep_prob)
random_tensor = keep_prob + tf.random_uniform(shape)
binary_tensor = tf.floor(random_tensor)
dropout_mask = tf.inv(keep_prob) * binary_tensor
return dropout_mask
class VariationalDropoutWrapper(RNNCell):
def __init__(self, cell, batch_size, keep_prob):
self._cell = cell
self._output_dropout_mask = get_dropout_mask(keep_prob, [batch_size, cell.output_size])
self._state_dropout_mask = get_dropout_mask(keep_prob, [batch_size, int(cell.state_size / 2)])
@property
def state_size(self):
return self._cell.state_size
@property
def output_size(self):
return self._cell.output_size
def __call__(self, inputs, state, scope=None):
# TODO: suppport non-LSTM cells and state_is_tuple=True
c, h = tf.split(1, 2, state)
h *= self._state_dropout_mask
state = tf.concat(1, [c, h])
output, new_state = self._cell(inputs, state, scope)
output *= self._output_dropout_mask
return output, new_state
このモジュールを使ってチュートリアルのptb_word_lm.pyに以下のパッチを当てれば変分Dropoutが使えるようになります(このスクリプトはTensorFlowのバージョンによって大きく変わるので注意)。
65a66,67
> from variational_dropout_wrapper import VariationalDropoutWrapper, get_dropout_mask
>
99,102c101,107
< if is_training and config.keep_prob < 1:
< lstm_cell = tf.nn.rnn_cell.DropoutWrapper(
< lstm_cell, output_keep_prob=config.keep_prob)
< cell = tf.nn.rnn_cell.MultiRNNCell([lstm_cell] * config.num_layers)
---
>
> # To avoid using same dropout mask in different layers, create new dropout wrapper per layer
> cells = []
> for i in range(config.num_layers):
> with tf.variable_scope("layer" + i):
> cells.append(VariationalDropoutWrapper(lstm_cell, batch_size, keep_prob=config.keep_prob))
> cell = tf.nn.rnn_cell.MultiRNNCell(cells)
112c117,119
< inputs = tf.nn.dropout(inputs, config.keep_prob)
---
> # use same dropout mask across time steps, but keep different masks for samples and units
> dropout_mask = get_dropout_mask(config.keep_prob, [batch_size, size])
> inputs *= tf.expand_dims(dropout_mask, 1)
実験結果
[Zaremba 2014]のmedium設定に従い、PennTreeBankデータセットにおけるLSTM言語モデルの性能を評価しました。Dropoutなしの場合と入出力のみDropoutの場合はZarembaらの論文に記載されているので、全層にDropoutを適用して時刻ごとにマスクを共有しない場合(全層Dropout)と、時刻ごとにマスクを共有する場合(変分Dropout)を新しく実験しました。
| モデル | パープレキシティ |
|---|---|
| Dropoutなし | 114.5 |
| 全層Dropout | 108.4 |
| 入出力のみDropout(Zaremba 2014) | 82.7 |
| 変分Dropout(Gal 2016) | 82.5 |
モデルの性能を表すテストセットパープレキシティ(低いほうが性能が良い)において、変分Dropoutが全層Dropoutよりも大きく勝っていることがわかります。単純に時間方向も含めて全層にDropoutを適用してしまうとノイズが累積して学習できないのに対し、Dropoutをベイズ的に解釈した変分Dropoutでは効果的に学習しながらも過学習を抑制できていると考えられます。
入出力のみDropoutを適用した場合と比べても、わずかながら変分Dropoutのほうが優れていることがわかります。元論文ではさらに重み減衰や層別drop確率などのチューニングで性能を稼いでいますが、RNNの時間方向のパラメータ数は入出力層と比べてかなり少ない(実験設定で6%ほど)のでもともと過学習しにくく、正則化の効果も弱いと考えられます。
おわりに
以前ニューラルかな漢字変換を実装したときにDropoutの重要性を実感していたので、NIPS 2016でGalらのポスター発表を見かけたときには興味をそそられました。実験結果からは追加のチューニングなしで既存手法と大きな差をつけることが難しいことが伺えるものの、理論的な考察からシンプルな手法を提案し既存手法の精度を改善するという論文のお手本のような研究でした。なお今回の実装はgistにて公開しています。
TensorFlow implementation of Variational Dropout