はじめに
BigQueryのMaterialized view(実体化されたビュー)の ドキュメント には以下のような記載があります。
スマートな調整
ソーステーブルに対するクエリまたはクエリの一部がマテリアライズド ビューへのクエリによって解決できる場合は、BigQuery によってマテリアライズド ビューを使用するようにクエリが書き換えられ(クエリの宛先が変更され)、その結果パフォーマンスと効率が向上します。
なんだかすごそうと思ったので実際に試してみることにしました。
※以下に記載されているクエリを実行するとBigQueryの利用料が発生する可能性がありますのでご注意ください。
検証用テーブルを作成する
COVID-19の公開データセット、 covid19_open_data から、2021-07-01 ~ 2021-07-31 までの新規感染者数を抽出したテーブルを作成します。
my_dataset_001は適当なdatasetに変更してください。
※以下のクエリでは約600MBのデータがクエリ対象になります。
CREATE TABLE
my_dataset_001.sample_data (
location_key STRING
,date DATE
,country_name STRING
,subregion1_name STRING
,new_confirmed INTEGER
)
AS SELECT
location_key
,date
,country_name
,subregion1_name
,new_confirmed
FROM `bigquery-public-data.covid19_open_data.covid19_open_data`
WHERE
country_name = 'Japan' -- 日本の都市に限定
AND subregion1_name IS NOT NULL -- 日本全体の合計のデータを除外
AND date BETWEEN '2021-07-01' AND '2021-07-31'
;
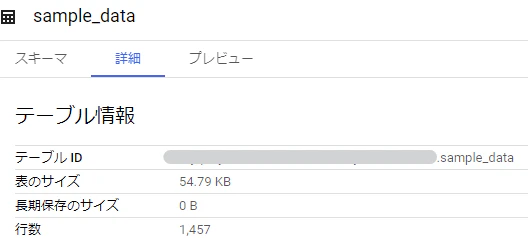
日本の47都道府県の日毎の感染者数のデータ約1,500レコードのテーブルができました。
サイズは55KBくらいありますね。
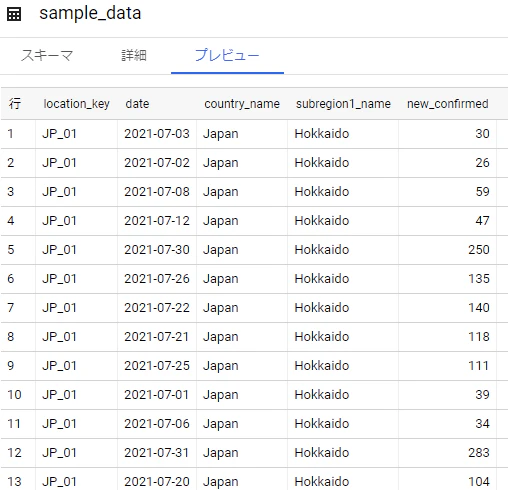
中身はこんな感じ。
普通に集計してみる
都道府県ごとの7月の新規感染者数の合計と、新規感染者数が一番多かった日の新規感染者数を計算してみます。
SELECT
location_key
,country_name
,subregion1_name
,SUM(new_confirmed) AS cumulative_confirmed
,MAX(new_confirmed) AS max_confirmed
FROM
my_dataset_001.sample_data
GROUP BY
location_key
,country_name
,subregion1_name
ORDER BY
location_key
;
結果は以下の通りになりました。
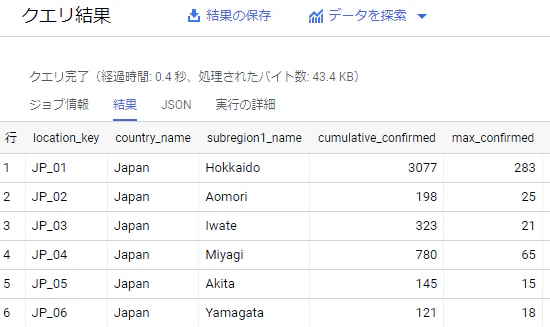
ここで注目するのは 処理されたバイト数: 43.4 KB というところです。
これはソーステーブル( sample_data )のすべての行がスキャンされていることを意味します。
最初に確認したテーブル全体のサイズ(約55KB)より少し少ないのは今回のクエリが date カラムを参照していないからです。
Materialized view を作成する
先ほどの集計のクエリをベースに同じ内容を集計するMaterialized viewを作成します。
CREATE MATERIALIZED table_name VIEW AS と書くだけです。
以下のSQLのSELECT以下は集計クエリとほぼ同じですね( ORDER BY だけ外しています)。
CREATE MATERIALIZED VIEW `my_dataset_001.summarized_sample_data`
AS SELECT
location_key
,country_name
,subregion1_name
,SUM(new_confirmed) AS cumulative_confirmed
,MAX(new_confirmed) AS max_confirmed
FROM
my_dataset_001.sample_data
GROUP BY
location_key
,country_name
,subregion1_name
;
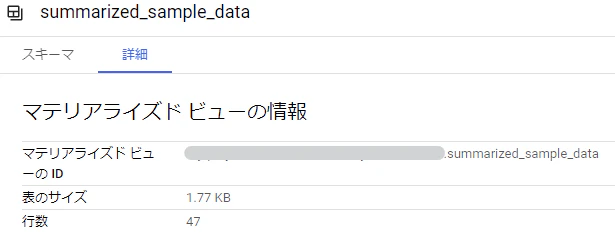
このクエリの結果以下のテーブルが作成されます。
都道府県ごとに集約しているので行数は47行、サイズは 1.77KB になりました。
参照方法は普通のテーブルと同じです。
SELECT
location_key
,country_name
,subregion1_name
,cumulative_confirmed
,max_confirmed
FROM
`my_dataset_001.summarized_sample_data`
ORDER BY
location_key
;

先ほど普通に集計したときと結果は同じですが、処理されたバイト数: 1.8 KB となっていますね。これは Materialized view のすべてのデータが参照されたためです。元のテーブルから集計したときよりも参照されるデータの量を小さくすることができていますね。
Smart tuningを試す
ようやく本題ですが、ここで冒頭の公式ドキュメントをもう一度。
スマートな調整
ソーステーブルに対するクエリまたはクエリの一部がマテリアライズド ビューへのクエリによって解決できる場合は、BigQuery によってマテリアライズド ビューを使用するようにクエリが書き換えられ(クエリの宛先が変更され)、その結果パフォーマンスと効率が向上します。
今回の例ではつまりこういうことです。
sample_data テーブルに対する集計クエリの結果が summarized_sample_data から得られるなら、クエリの参照先が summarized_sample_dataに変更されてパフォーマンスが向上する。
試してみましょう。実行するクエリは最初に普通に集計したときと同じものです。
SELECT
location_key
,country_name
,subregion1_name
,SUM(new_confirmed) AS cumulative_confirmed
,MAX(new_confirmed) AS max_confirmed
FROM
my_dataset_001.sample_data
GROUP BY
location_key
,country_name
,subregion1_name
ORDER BY
location_key
;
結果はこうなります。
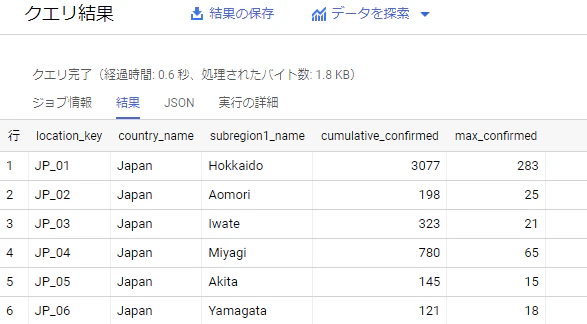
処理されたバイト数: 1.8 KB となおり、これは summarized_sample_data を参照したときと同じですね。
念のため実行の詳細を確認してみます。
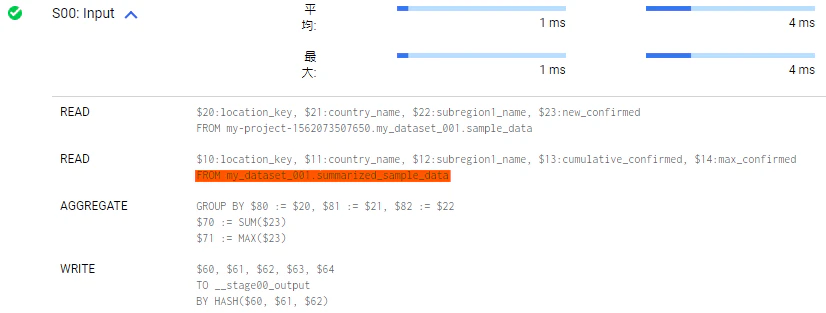
確かに summarized_sample_data、つまり Materialized view が参照されていますね、ドキュメントにそう書いてあるので当たり前なんですけど、すごいなぁ。
ちなみに以下の例のように Materialized view の一部のフィールド(カラム)や行をソーステーブルから参照する場合でも Materialized view が参照されます。
SELECT
subregion1_name
,SUM(new_confirmed) AS cumulative_confirmed
FROM
my_dataset_001.sample_data
GROUP BY
location_key
,subregion1_name
ORDER BY
location_key
;
SELECT
subregion1_name
,SUM(new_confirmed) AS cumulative_confirmed
FROM
my_dataset_001.sample_data
WHERE
subregion1_name = 'Tokyo'
GROUP BY
subregion1_name
;