1. はじめに
生成AIは強力ですが、「知らないことには答えられない」「嘘をつくことがある」といった弱点があります。
この問題を解決するために注目されているのが、RAG(Retrieval-Augmented Generation)=検索拡張生成という技術です。
本記事は久しぶりにRAGに触った人間が、復習がてら書いています。そのため、現在のベストプラクティスに完全に準拠しているわけではありませんが、筆者が以前使っていた愛着のある技術やライブラリをあえて選んでいます。
2. RAGとは何か?その仕組みと流れ
RAG(Retrieval-Augmented Generation)は、「検索(Retrieval)」と「生成(Generation)」を組み合わせたAIの仕組みです。本記事では、PDFから抽出したテキストを活用して、ユーザーの質問に応答するチャットボットを構築していきます。
通常の大規模言語モデル(LLM)は、あらかじめ学習された知識の範囲内でしか回答できません。そのため、最新の情報に対応したり、長文の文書を柔軟に扱ったりするのが苦手です。
こうした課題を解決するのがRAGのアプローチです。RAGでは、外部知識を活用しながら、以下の2つのステップでより信頼性の高い回答を生成します。
Retrieval(検索)
ユーザーの質問をベクトル化し、事前にベクトル化された文書(例:PDFから抽出したテキスト)と照らし合わせて、意味的に近いものを検索します。
この段階では、コサイン類似度などを用いた「ベクトル検索」が一般的です。
Generation(生成)
検索で得られた文書(コンテキスト)をもとに、LLMが自然な形で回答を生成します。
必要に応じて、「情報が見つからなければ回答を控える」といった安全な挙動も設定できます。
3. なぜRAGが必要なのか?
LLM(大規模言語モデル)は強力ですが、以下のような限界があります:
- 知識が古い(カットオフ)
- 間違ったことをそれっぽく答える(ハルシネーション)
- 自社のデータには対応できない(カスタマイズ困難)
そこで外部の文書を検索してLLMに渡すという仕組みが求められます。
これがRAGです。
4. RAGの仕組み
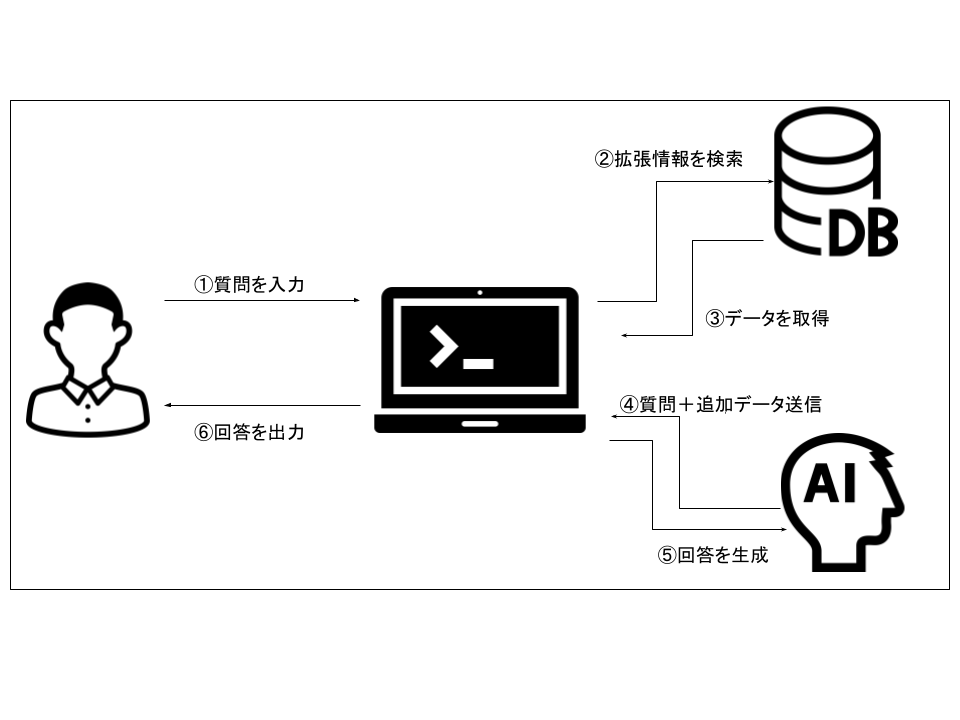
①質問を入力
ユーザーが質問を入力します。
これは自然言語で行われる 例:「この製品の返品ポリシーは?」など。
②拡張情報を検索
システムは、質問に関連する情報をデータベースから検索します。
ベクトル検索などを用いて、意味的に関連のある文書を取得します。
③データを取得
検索結果として得られた関連文書(例:マニュアルの一部やFAQ)が取得されます。このプロセスが「検索(Retrieval)」。
④質問+追加データ送信
ユーザーの元の質問と取得した関連文書をセットでAIモデルに送信します。
⑤回答を生成
AIが受け取った情報を元に、最適な回答を生成します。このプロセスが「生成(Generation)」です。
⑥回答を出力
最後に、生成された回答がユーザーに返され、画面に表示されます。
5. RAGのコード全体
import fitz
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
api_key = "API_Key"
def load_pdf(pdf_path):
doc = fitz.open(pdf_path)
documents = []
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
text = page.get_text("text")
documents.append(Document(page_content=text))
return documents
def create_qa_system(documents):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(
api_key=api_key,
chunk_size=600
)
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 6})
llm = ChatOpenAI(model="gpt-4o", temperature=0, api_key=api_key)
prompt = ChatPromptTemplate.from_messages([
("system", "Answer based on the context: {context}"),
("human", "{input}")
])
question_answer_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(retriever, question_answer_chain)
return qa_chain
def main():
pdf_path = "PDF_Path"
documents = load_pdf(pdf_path)
qa_system = create_qa_system(documents)
print("PDFの質問応答システムが準備できました。質問を入力してください。")
print("終了するには 'quit' または 'exit' と入力してください。")
while True:
query = input("\n質問を入力してください: ")
if query.lower() in ['quit', 'exit']:
print("プログラムを終了します。")
break
result = qa_system.invoke({"input": query})
print("\n回答:", result["answer"])
if __name__ == "__main__":
main()
6. 詳しいコード説明
ライブラリ
import fitz
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
PDF読み込み
fitz(PyMuPDF):PDFファイルを読み込み、各ページからテキストを抽出する
ライブラリベクトルストア
Chroma:文書の埋め込みベクトルを保存し、類似検索を実行するベクトルデータベース
OpenAI統合
OpenAIEmbeddings:テキストを数値ベクトルに変換するOpenAI埋め込みモデル
ChatOpenAI:質問応答を行うOpenAIの大規模言語モデル(GPT-4o等)
テキスト処理
RecursiveCharacterTextSplitter:長い文書を意味的まとまりを保ちながら適切なサイズに分割
コアコンポーネント
Document:テキスト内容とメタデータを格納するLangChainの基本データ形式
ChatPromptTemplate:LLMに送信するプロンプトのテンプレートを定義・作成
チェーン構築
create_stuff_documents_chain:複数文書を統合して質問と共にLLMに送る「文書まとめ係」
create_retrieval_chain:検索→統合→回答を自動処理する「検索+回答係」統合チェーン
使用したライブラリのバージョン
PyMuPDF 1.26.3
langchain 0.3.26
langchain-chroma 0.2.4
langchain-community 0.3.27
langchain-core 0.3.68
langchain-openai 0.3.27
langchain-text-splitters 0.3.8
PDF読み込み関数
def load_pdf(pdf_path):
doc = fitz.open(pdf_path)
documents = []
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
text = page.get_text("text")
documents.append(Document(page_content=text))
return documents
PDFファイルの各ページからテキストを抽出し、LangChainのDocument形式に変換します。
QAシステム構築関数
def create_qa_system(documents):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(
api_key=api_key,
chunk_size=600
)
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 6})
llm = ChatOpenAI(model="gpt-4o", temperature=0, api_key=api_key)
prompt = ChatPromptTemplate.from_messages([
("system", "Answer based on the context: {context}"),
("human", "{input}")
])
question_answer_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(retriever, question_answer_chain)
return qa_chain
- テキスト分割文書:600文字のチャンクに分割
- ベクトル化:OpenAIの埋め込みモデルでテキストをベクトルに変換
- ベクトルストア作成:Chromaデータベースに保存
- 検索器設定:類似度の高い上位6件を検索するように設定
- 言語モデル設定:GPT-4oモデルを使用(temperature=0で決定論的な回答)
- プロンプトテンプレート作成システムメッセージで「コンテキストに基づいて回答」の指示を定義
- QAチェーン構築:「stuff」方式で検索結果を言語モデルに渡し、回答生成パイプラインを構築
「stuff」方式とは→ 検索された複数の文書を1つのコンテキストとして詰め込みLLMに一括で渡す手法。
メイン実行部分
def main():
pdf_path = "PDF_Path"
documents = load_pdf(pdf_path)
qa_system = create_qa_system(documents)
print("PDFの質問応答システムが準備できました。質問を入力してください。")
print("終了するには 'quit' または 'exit' と入力してください。")
while True:
query = input("\n質問を入力してください: ")
if query.lower() in ['quit', 'exit']:
print("プログラムを終了します。")
break
result = qa_system.invoke({"input": query})
print("\n回答:", result["answer"])
- PDFファイルを読み込み、テキストを抽出
- テキストを小さなチャンクに分割
- 各チャンクをベクトル化してデータベースに保存
- ユーザーの質問に対して、関連する6つのチャンクを検索
- 検索結果をGPT-4oに渡して回答を生成
このコードを使用することで、任意のPDFファイルから簡単に質問応答システムを構築できます。RAG(Retrieval-Augmented Generation)アーキテクチャを活用し、大量の文書から適切な情報を検索して回答を生成する仕組みを実装しています!
7. デモ文章
# RAG検証用架空文書コレクション
## 文書 1: ヴェルナ王国の歴史
ヴェルナ王国は紀元前 500 年頃、伝説の王エルディウスによって建国されたとされる。この王国
は現在のヨーロッパ大陸の中央部に位置し、豊富な鉱物資源とクリスタルフラワーと呼ばれる特
殊な植物で知られていた。
12世紀に入ると、第 15代国王アルベルト 3世の統治下で「クリスタル革命」が起こり、魔法技
術と錬金術が飛躍的に発展した。この時期に建設されたソラリス大図書館は、現在でも世界最大
級の魔法書コレクションを誇っている。
1453年のドラゴン戦争では、古代ドラゴンのフレイムウィング族との激しい戦いが 3年間続いた
。最終的に王国軍が勝利し、平和協定「エメラルドの誓い」が締結された。この協定により、ド
ラゴンと人間の共存が実現し、現在に至るまで続いている。
## 文書 2: オービタル・コーポレーションの製品カタログ
オービタル・コーポレーションは 2089 年に設立された宇宙開発企業で、主力製品は量子駆動エン
ジン「ネブラドライブ」である。このエンジンは従来の化学推進システムの 100 倍の効率を持ち
、火星まで 72時間で到達可能である。
同社の宇宙ステーション「オービタル・ハブ 7」は地球軌道上に浮遊し、最大 5000 人の居住者を
収容できる。内部にはハイドロポニック農場、重力制御システム、そして銀河系最大のホログラ
ム・エンターテインメント施設が完備されている。
最新製品の「テレポート・ポッド」は、量子もつれ技術を応用した瞬間移動装置で、地球上の任
意の 2点間を 1秒以内で移動できる。ただし、1日の使用回数は安全上の理由から 3回までに制
限されている。
## 文書 3: 幻想料理研究所の調査報告
幻想料理研究所が発表した最新の調査によると、ミスティック・フルーツと呼ばれる果物が、食
べた人の記憶を一時的に鮮明にする効果があることが判明した。この果物は満月の夜にのみ収穫
でき、フェアリーフォレスト地域でのみ自生している。
また、シャドウ・ペッパーという香辛料は、料理に加えると食べた人を 30分間透明化させる効果
がある。ただし、この効果は食べた人の感情状態に左右され、怒りや悲しみを感じている場合は
効果が現れない。
レインボー・ソルトは 7色に輝く塩で、料理の味を食べた人の好みに自動的に調整する機能を持
つ。この塩は古代の海底遺跡からのみ採取でき、年間生産量は世界で 200グラムに限られている
。
## 文書 4: バイオリズム・シティの都市計画
バイオリズム・シティは 2156年に完成予定の未来都市で、住民の生体リズムに合わせて都市環境
が自動調整される革新的な設計となっている。街の照明は住民の概日リズムに合わせて色温度が
変化し、睡眠の質を向上させる。
交通システムは「フロー・チューブ」と呼ばれる磁気浮上式の透明チューブで構成され、住民は
個人用のポッドに乗って時速 300キロメートルで移動できる。AIシステム「シティ・マインド」
が全ての交通を管理し、渋滞は完全に解消されている。
住宅は「アダプティブ・ハウス」と呼ばれる自己変形建築で、住民のライフスタイルの変化に応
じて間取りが自動的に変更される。また、建物の外壁は光合成機能を持つ特殊な素材で作られて
おり、大気中の二酸化炭素を酸素に変換する。
## 文書 5: 時間研究所の実験記録
時間研究所では、クロノ・クリスタルという特殊な鉱物を使用した時間操作実験が行われている
。実験番号 TC-4471 では、被験者が 10分間の時間を体験するのに実際には 3時間を要する「時
間拡張フィールド」の生成に成功した。
逆時間流動実験では、テンポラル・エンジンを使用して限定的な時間の逆行を実現している。現
在の技術では最大 24時間前まで遡ることができるが、対象物の質量が 1キログラム以下に制限さ
れる。
パラレル・タイムライン観測装置「クロノスコープ」により、別の時間軸での出来事を観測する
ことが可能になった。これまでに47の異なる時間軸が確認されており、その中には恐竜が絶滅し
なかった世界や、重力が現在の半分の世界も含まれている。
適当に生成させた文章でOKです。
8. 実行結果

画像のように追加させた文章の内容である架空のヴェルナ王国について説明されています!
9. 最後に
本記事は、自分自身が久しぶりにRAG構成を一から見直し、「ちゃんと中身を理解しながら動かしたい」という思いで組み立てた内容をまとめたものです。以前使っていたコードを最新版にする段階で思っていたよりも手間取ってしまい焦りましたがとりあえず動くまで直せてよかったです...。
もし同じように「一度ちゃんと自分で動かして理解しなおしたい」と感じている方がいれば、本構成がその一助になれば幸いです。また、最新の動向やコードの改善点などのフィードバックをいただけると嬉しいです。
読んでくださってありがとうございました!