この記事はPostgreSQL Advent Calendar 2021の18日目の記事です。
この記事ではスプレッドシート等では非常に扱いやすいピボットテーブルを、DBレイヤで頑張った場合SQL的にどこまで扱いやすくできるか?を試した結果を紹介します。
やりたいこと
以下のようなデータから、
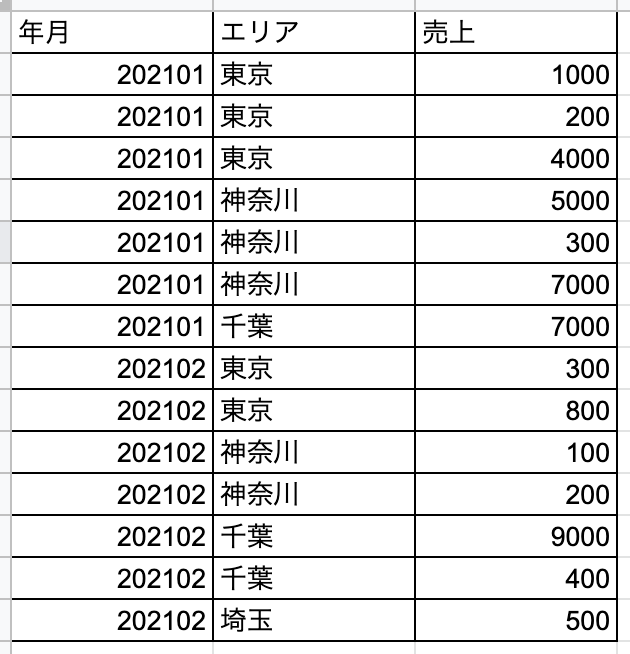
こんなピボットを行いたいとします。

データの用意
create table area_sales
(
ym TEXT,
area TEXT,
amount NUMERIC
);
insert into area_sales(ym, area, amount) values ('202101', '東京', 1000);
insert into area_sales(ym, area, amount) values ('202101', '東京', 200);
insert into area_sales(ym, area, amount) values ('202101', '東京', 4000);
insert into area_sales(ym, area, amount) values ('202101', '神奈川', 5000);
insert into area_sales(ym, area, amount) values ('202101', '神奈川', 300);
insert into area_sales(ym, area, amount) values ('202101', '神奈川', 7000);
insert into area_sales(ym, area, amount) values ('202101', '千葉', 7000);
insert into area_sales(ym, area, amount) values ('202102', '東京', 300);
insert into area_sales(ym, area, amount) values ('202102', '東京', 800);
insert into area_sales(ym, area, amount) values ('202102', '神奈川', 100);
insert into area_sales(ym, area, amount) values ('202102', '神奈川', 200);
insert into area_sales(ym, area, amount) values ('202102', '千葉', 9000);
insert into area_sales(ym, area, amount) values ('202102', '千葉', 400);
insert into area_sales(ym, area, amount) values ('202102', '埼玉', 500);
普通にSQLで解決する場合
select ym,
sum(case when area = '東京' then amount end) as 東京,
sum(case when area = '千葉' then amount end) as 千葉,
sum(case when area = '神奈川' then amount end) as 神奈川,
sum(case when area = '埼玉' then amount end) as 埼玉
from area_sales
group by ym
order by ym
;
↓
| ym | 東京 | 千葉 | 神奈川 | 埼玉 |
|---|---|---|---|---|
| 202101 | 5200 | 7000 | 12300 | NULL |
| 202102 | 1100 | 9400 | 300 | 500 |
となり、欲しい形式でピボットができました。
ポイント
- ピボットの列指定について、caseで条件絞り込みを行い、集計対象(今回はamount)を指定
- ピボット時の集計について集計関数(今回はsum)を指定
一方で、これくらいのデータ量であれば、列をcaseで列挙可能ですがもっと大きなデータで縦横を可変的に扱うのは難しいですね。
拡張機能を利用する場合
拡張機能のtablefuncにcrosstab関数というピボットを行うための関数が用意されているのでこれを利用してみます。
先に拡張機能を有効にしておきます。
create extension if not exists tablefunc;
tablefuncについての詳細はマニュアルを参照してください。
https://www.postgresql.jp/document/12/html/tablefunc.html
いくつかの関数がありますが、第一引数で元となるテーブルを指定、第二引数でピボットしたい元の値列を指定する関数を利用します。
select *
from crosstab(
'select * from area_sales order by 1',
'select distinct area from area_sales order by area desc'
) as (
ym TEXT,
東京 numeric,
千葉 numeric,
神奈川 numeric,
埼玉 numeric
);
↓
| ym | 東京 | 千葉 | 神奈川 | 埼玉 |
|---|---|---|---|---|
| 202101 | 4000 | 7000 | 7000 | NULL |
| 202102 | 800 | 400 | 200 | 500 |
おや、期待した数値になっていません。
どうやら第一引数で指定した元テーブルの各カテゴリの最後の値が取得されているようです。
SUMなどの集計をしたい場合はGROUP BYしたクエリを第一引数に指定する必要がありました。
select *
from crosstab(
'select ym, area, sum(amount) from area_sales group by ym ,area order by 1',
'select distinct area from area_sales order by area desc'
) as (
ym TEXT,
東京 numeric,
千葉 numeric,
神奈川 numeric,
埼玉 numeric
);
↓
| ym | 東京 | 千葉 | 神奈川 | 埼玉 |
|---|---|---|---|---|
| 202101 | 5200 | 7000 | 12300 | NULL |
| 202102 | 1100 | 9400 | 300 | 500 |
これで期待する結果が得られました。
crosstab関数は戻り値がsetof recordなので、ASで列定義リストを指定する必要がありこれが厄介です。
もともと一つのカラムに入っていたデータを横に展開させるだけなので型定義などはよしなにできないものかと思いますがこれはできません。
crosstabviewメタコマンド
PostgreSQLにはcrosstab関数に加えて同様の機能を提供するcrosstabviewメタコマンドがあります。
こちらはpsqlで実行したときのみで利用できます。
# select ym, area, sum(amount) from area_sales group by ym ,area order by 1 \crosstabview
ym | 東京 | 神奈川 | 千葉 | 埼玉
--------+------+--------+------+------
202101 | 5200 | 12300 | 7000 |
202102 | 1100 | 300 | 9400 | 500
(2 行)
このような形で、型定義リストを指定しなくても入力から戻り値を推定して出力してくれます。
psqlはそこまで普段使いするものでもないので惜しいかんじがあります。
まとめ
いくつかの方法を試しましたがピボットテーブルをDBレイヤで行わなくてはいけない場合、普通にSQLで頑張るのが一番わかりやすいと思われます。