はじめに
この記事はHeroku Advent Calendar 2016 17日目の記事です。遅くなってすみません。。
過去に書いた記事で書けなかった補足の情報を出すかんじでいきます。
Herokuで起こりうるメモリ関連のエラー
Herokuで起こるメモリ関連のエラーはR14とR15エラーの2つがあります。
Herokuにおけるメモリの上限はプランによって制限され、たとえば無料で使える上限のFreeプランだと512MBのメモリしか使えません。
このようにHerokuはプランによってメモリの上限が決まります。
Herokuではメモリの使用量がそのプランの上限を超えると、スワップが発生するようになっています。
プランの上限を超えてスワップが発生するとR14エラーが発生するようになります。R14エラーの状態ではDynoはそのまま動き続けます。
このスワップが元のプランのメモリ上限の200%を超えるとR15エラーが発生し、Dynoが強制終了されます。強制終了されたDynoはその後自動で再起動されますが、メモリ枯渇によりアプリが都度強制終了されるのはつらいので地道な対処をしていきましょう。
エラーを検知しよう
過去に書いた記事でも紹介してるのですが、Herokuでも監視は必要です。
ただ、Herokuの場合EC2の監視等と違ってインスタンスに何かを仕込むことはできません(というかできません)。かわりに、HerokuからDynoのメトリクスの情報をログで受け取ることができます。これはHerokuのlabの機能で提供されており、たとえばアドオンの監視ツールであるLibratoでHerokuのDynoの情報を取得したい場合、
heroku labs:enable log-runtime-metrics --app [APPNAME]
として有効にしてやることで、ログにHerokuのメトリクスの情報が吐かれるようになり、Librato経由で監視できるようになります。
R14/R15エラーが発生したときの対処
基本的にメモリが枯渇するエラーが起きると言うのはだいたいが一度に大きなデータを扱いそれを一気に処理(画面に一覧表示したり、DBにインサートしたり)する場合に発生することが多いです。
公式ドキュメントに書かれていることそのままですが以下のことを試しましょう。
- workerプロセスを1にする
- worker_killerでプロセスを定期的にkillする
- メモリプロファイラを入れてアプリ側でチューニングを行う
以上で対処できない場合には、プランを上げるか別のプラットフォームへアプリケーションを移すことを検討するとよいかもしれません。
workerプロセスを1にする
Herokuではアプリケーションサーバーにはpumaが奨励されています。マルチプロセスで動くサーバーはサーバー起動時にworkerという子プロセスを複数起動し、Webサーバーからのリクエストは親プロセスが受けたものをその子プロセスが処理することになりますが、メモリが十分でない場合はこの子プロセスがいくつも立ち上がっているとサーバーのメモリ消費量が高くなるためプロセス数を1にします。
pumaであれば config/puma.rb に以下のように書いておけば、
# config/puma.rb
workers Integer(ENV['WEB_CONCURRENCY'] || 2)
以下のように環境変数を設定するのみでworker起動数を変更できます。
$ heroku config:set WEB_CONCURRENCY=1
worker_killerでプロセスを定期的にkillする
workerプロセスを1に設定してもメモリが増加し続ける場合、メモリ消費の激しい処理があり、そのルーティングにアクセスが集中することによりR14エラーが出ることがあります。
一度確保されたメモリはrubyではなかなか解放されず、だいたいプロセスが生きている間は保持されるため、メモリ増加量が激しい場合はworker_killerを導入して定期的にメモリを解放するのが手っ取り早い対処方法です。(メモリ周りの細かいチューニングも存在しますが[*1] [*2]、これより先にやれることが結構あるはず。)
worker_killerで有名なのはunicorn-worker-killerだと思います。pumaでもpuma_worker_killerが用意されていて、こちらを使うことができます。
worker_killerで間違ってはいけないのが、あくまでworker_killerによる対処は一時的対応ということです。worker_killerはたしかにメモリ消費を抑える効果があるのですが、定期的にメモリを解放するという処理を行うだけなので、実際のメモリ消費が発生する原因への対処にはなっていないのです。
メモリプロファイラを入れてアプリ側でチューニングを行う
worker_killerなどの応急処置が完了したら根本的な原因を探りに行きましょう。
根本的な原因を探るためにはどこでどんな処理が起きているから重い(挙げ句の果てに落ちる)ということを突き止める必要があります。実はこれが結構メモリ増加量で読むことは難しく、メジャーなパフォーマンス監視ツールであるNewRelicでもどのアクションでどれくらいメモリが消費されたかまで細かくみることはできません。(概要のデータは全然みれます。)
そこで導入するのがScoutというAdd-onです。このツールは2016年9月ごろまではベータ版として公開されていたため無料で利用できたのですが、現在は本番で使うとなると$39/mon以上のコストがかかってしまいます。
Heroku Add-on以外のメモリプロファイリングのサービスだと、Skylight.ioというサービスがあります。Scoutのほうは65,000トランザクションで$39/monなのに対し、Skylight.ioでは1,000,000リクエストまでは$20/monで提供しているようなのでこちらの方が安い可能性もあります。(一概に断定できるものではなく、モニタリング対象や、モニタリング期間等も比較の上で、利用してください。)
Heroku Add-onとしてのでの利用はできませんが検討してみてもよいかもしれません。
Scoutの場合は以下のような画面でメモリ消費を確認することができます。
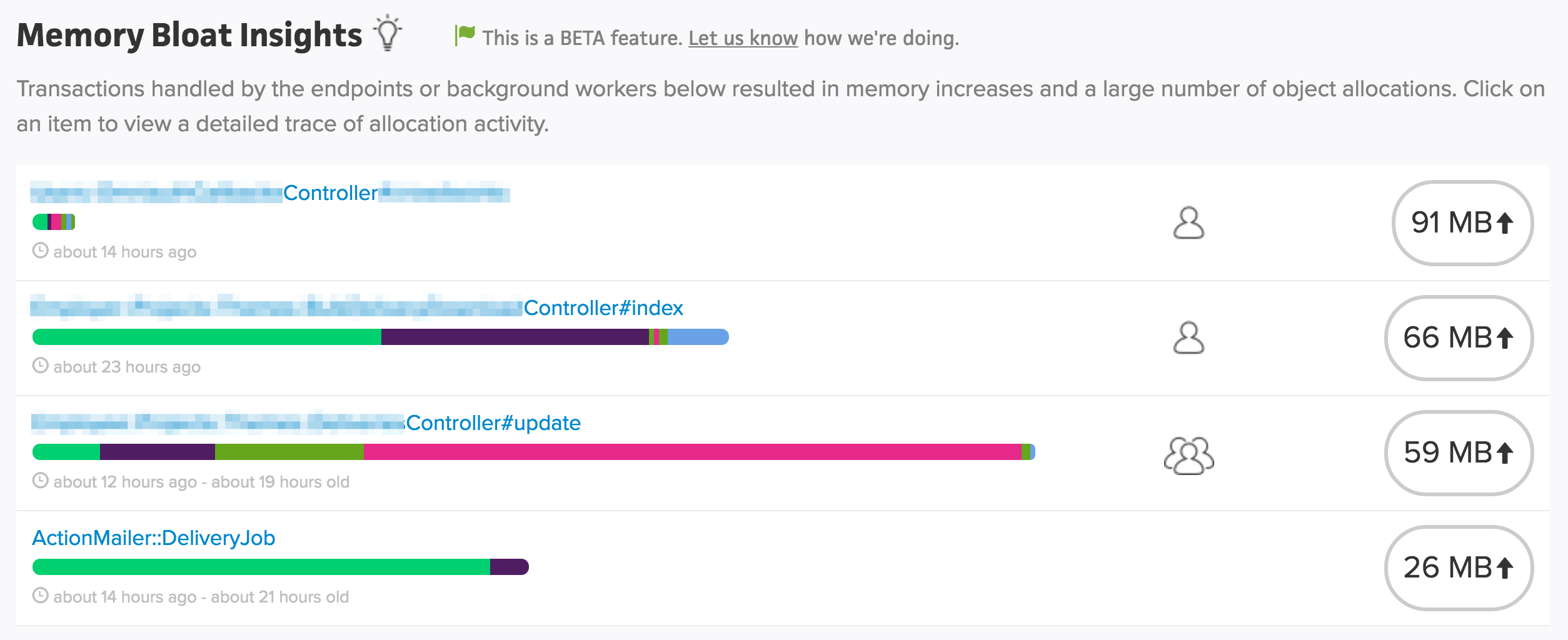
それぞれの中身をみてみると、
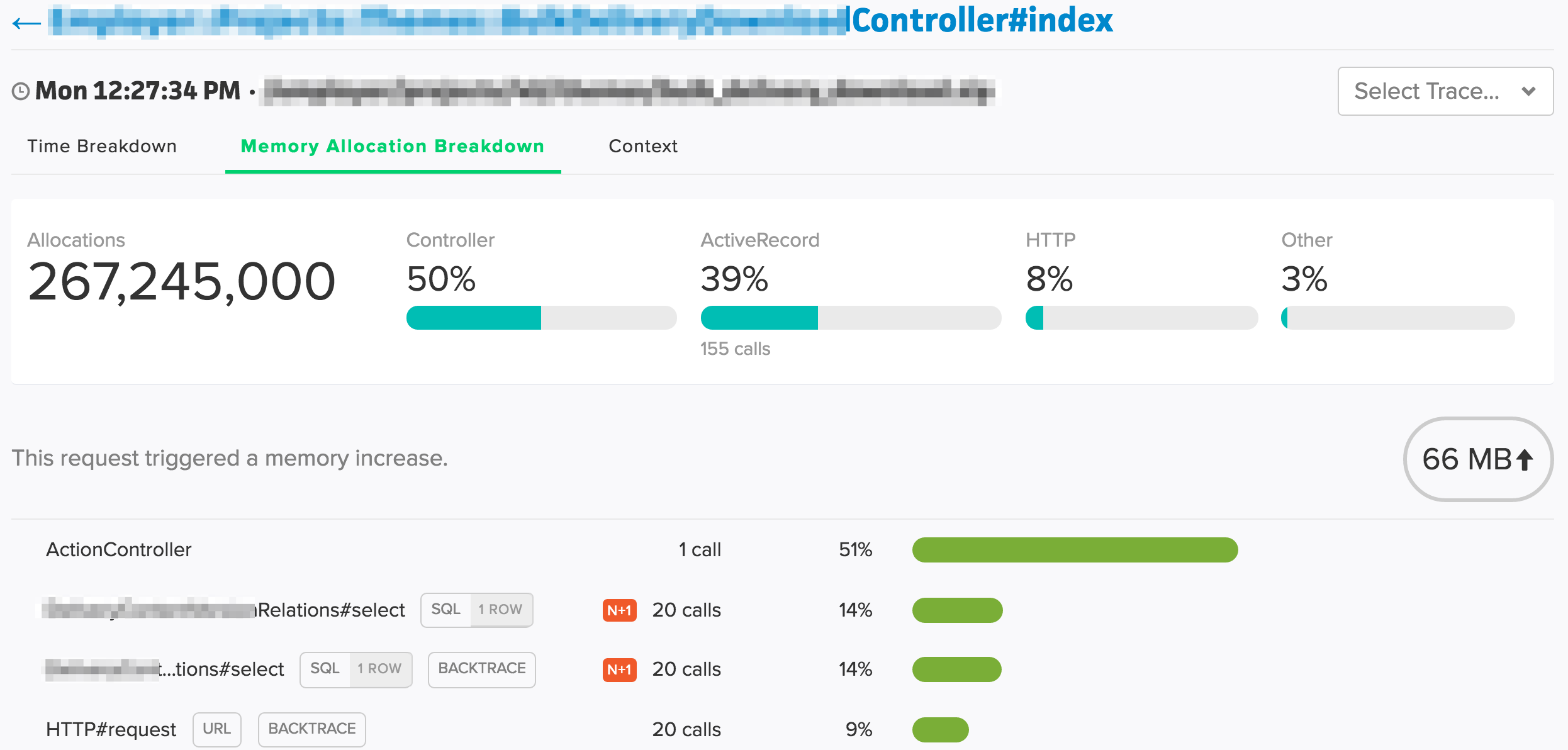
このような形で、どの処理に時間がかかっているかがわかります。このときにモデルでN+1が発生していればモデル側で取得方法を工夫して問題の解消をすればよいですし、ビューのレンダリングに負荷がかかっている場合はページャをいれて取得対象の件数を絞るとか、レンダリング時に無駄な処理をしていないかなどをチェックすることになるかと思います。
さいごに
Herokuのメモリ制約はプランが小さいと結構厳しかったりするのですが、うまくアプリケーションのチューニングを行うことでインフラ側の細かいことまで考えなくてもパフォーマンスが改善するケースもあるかと思います。(普通のアプリであればパフォーマンス問題はだいたいアプリ側起因のはず)
きちんとモニタリングしていけば全然恐れることはなくそれなりの規模のアプリケーションを動かすことができますのでまだやってない方は試してみてください。