CodeIQ の問題を解く (2)
昨日に引き続き CodeIQ に掲載された問題を解いてみます。
「機械学習基礎」簡単な問題を解いて理解しよう!前篇
http://next.rikunabi.com/tech/docs/ct_s03600.jsp?p=002315
今日は第 2 問を解きます。
クラスタリング
問題
海賊船で催されたPRML読書会は楽しかった。
機械学習の事も少しはわかった気がするし、金貨も沢山貰えた。偽金貨もずいぶん混ざっていたが。
本物とわかった金貨を何枚か貴金属店で売って小金ができた。
貴金属店の店主は海賊船での読書会の話もそこで金貨を貰った事も信じていないようだったが、
そのうち何枚かは百年前に北大西洋で沈没した豪華客船に積まれていた幻の金貨だそうで、店主もほくほくしていた。
これでカーネル多変量解析の本でも買おうかと思っていたN君に、海賊船の船長からメールが届いた。
「太平洋のある島にたどり着いた。島は家から道路から何もかも金でできている。」
もしかしてあの「ジパング」ですか?
「しかし、この島には誰も住んでおらず、あるものといえば金ばかりで食料が全くない。
食用になりそうなのは道端に生えているキノコぐらいだ」
「この島のキノコは見たところ3種類あるようだ。そのうち2種類は毒キノコらしい。
誤って食べた隊員が3日3晩笑い転げたり泣き叫んだりしている。
3種類とも金色なので色では区別がつかない。」
とりあえず死人は出ていないらしい。
「採ってきたキノコと、隊員が食べたキノコのデータを送るから、
食べても大丈夫なキノコを教えてほしい」
キノコの傘の大きさと柄の長さが記されたデータが送られてきた。
このデータをもとに採ってきたキノコをクラスタリングして、隊員が食べた毒キノコの含まれないグループのキノコを船長に教えてあげよう。
データの読み込み
昨日はサポートベクトルマシンを利用しましたが、今日はクラスタリングをします。
○ と × だと扱いづらいので 1 と 0 にあらかじめ変換しておきます。
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 採ってきたキノコ
data = np.genfromtxt('CodeIQ_data.txt', delimiter=' ')
# 隊員が食べたキノコ
eaten = np.genfromtxt('CodeIQ_eaten.txt', delimiter=' ')
データ可視化
まずはデータをプロッティングしてみます。
# 散布図にプロットのための関数
def plot(data, eaten):
# キャンバスを描く
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
# 採ってきたキノコを青で描画する
x1, y1 = np.array([[x[0], x[1]] for x in data]).T
ax.scatter(x1, y1, color='b')
# 食べても大丈夫なキノコを赤で描画する
x2, y2 = np.array([[x[0], x[1]] for x in eaten if x[2] == 1]).T
ax.scatter(x2, y2, color='r')
# 食べてはいけないキノコを緑で描画する
x3, y3 = np.array([[x[0], x[1]] for x in eaten if x[2] == 0]).T
ax.scatter(x3, y3, color='g')
plt.legend(loc='best')
plt.show()
plt.savefig("image.png")
plot(data, eaten)
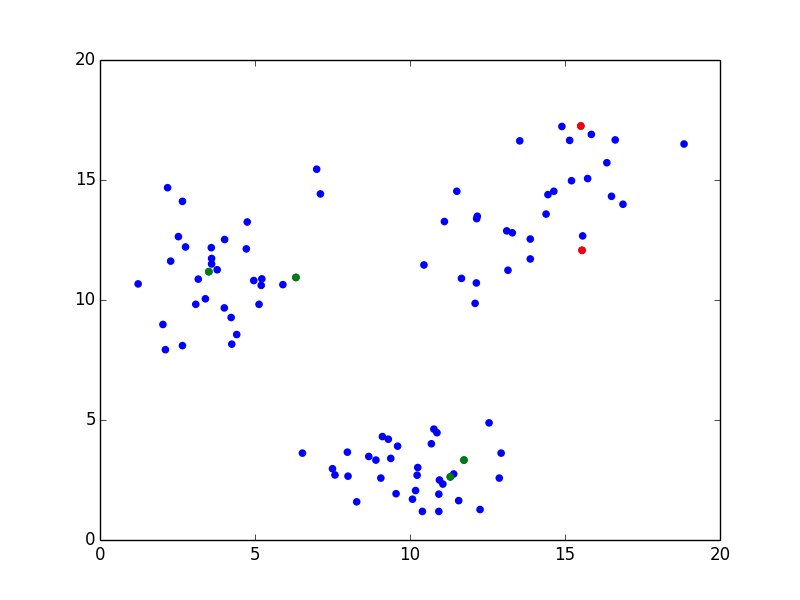
元記事と同じようにプロットができました。
上の図で赤い点が属しているクラスタが食べられるキノコです。
K-Means クラスタリングは k 個のクラスタにデータをわけるアルゴリズムです。今回は 3 つのクラスタに分けますから k=3 となります。
解法
def kmeans(features):
# k=3, ランダマイズを 10 回実施する
kmeans_model = KMeans(n_clusters=3, random_state=10).fit(features)
# ラベルを取り出す
labels = kmeans_model.labels_
return labels
# K-Means クラスタリングをする
labels = kmeans(data)
これで labels に 0,1,2 の 3 つのラベルが帰るわけです。
あとは内容を調べて赤に所属するクラスタを表示すれば OK です。
for label, feature in zip(labels, data):
if label == 0:
print(label, feature)
結果
0 [ 13.54 16.63]
0 [ 15.15 16.65]
0 [ 16.87 13.99]
0 [ 11.11 13.27]
0 [ 16.62 16.67]
0 [ 18.84 16.5 ]
0 [ 15.21 14.97]
0 [ 14.39 13.58]
0 [ 13.88 12.54]
0 [ 13.16 11.24]
0 [ 14.45 14.39]
0 [ 12.15 13.39]
0 [ 13.3 12.8]
0 [ 15.55 12.07]
0 [ 12.1 9.86]
0 [ 14.9 17.23]
0 [ 16.5 14.32]
0 [ 13.88 11.71]
0 [ 15.73 15.06]
0 [ 12.17 13.49]
0 [ 10.45 11.46]
0 [ 11.51 14.53]
0 [ 15.51 17.25]
0 [ 15.85 16.9 ]
0 [ 14.64 14.53]
0 [ 13.12 12.88]
0 [ 11.66 10.9 ]
0 [ 15.57 12.67]
0 [ 16.35 15.72]
0 [ 12.14 10.71]
30 個のキノコをきれいに取り出すことができました。