いままで R の基本的なデータプロッティングやファイル入出力方法、クリップボードからのデータ取り込み方法、Python からの R 呼び出し方法などを紹介してきました。今日はチュートリアルとして、あらためて R の基本的な文法や使い方そして処理の流れを解説していきたいと思います。
R での処理の流れ
R でデータを処理する流れは主に次の通りです。
- データを用意する
- 計算をする
- レポーティングする
データを用意する
処理対象のデータが無ければ何もできません。 R では他のプログラミング言語と同じように変数にデータを格納します。
変数の定義と利用
# x に 10 を格納する
x <- 10
# 変数を呼ぶと格納された値が返る
x
# => 10
x * 2
# => 20
ベクトル空間
線形代数では n 個の数を直線に並べた形を n 次元数ベクトルと言います。また実数を成分とする n 次元数ベクトルの全体を実数体上の n 次元数ベクトル空間といい、次のように書きます。
R^n
数ベクトルについては、結合法則、交換法則、実数倍の加法性、実数の加法と実数倍の加法といった定理が公式として成り立ちます。ベクトルを定数倍する操作をスカラー乗法と言います。
- 加法 : 集合 V の任意の 2 つの要素 a,b について、これらの和と呼ばれる V の要素 a + b が決まる
- 実数倍 : 集合 V の任意の要素 a と実数 c について a の c 倍と呼ばれる V の要素 ca が決まる
vec <- c(10, 20, 30)
vec
# => [1] 10 20 30
# スカラー乗法
vec * 2
# => [1] 20 40 60
# ベクトル成分の参照
vec[1]
# => [1] 10
行列
数ベクトル空間の間の一次写像を具体的に表すものを行列と言います。
mat <- matrix(c(10, 20, 30, 40, 50, 60), 2, 3)
mat
# => [,1] [,2] [,3]
# [1,] 10 30 50
# [2,] 20 40 60
# 行列成分の参照
mat[1,1]
# => [1] 10
# 行
mat[1,]
# => [1] 10 30 50
# 列
mat[,2]
# => [1] 30 40
上の例では 3 x 2 行列を作っています。
このように m x n 行列を作るには matrix 関数を使います。
線形代数で言うような基本変形や結合法則、転置なども適用できます。
ちなみにベクトル空間 V のベクトル u_1, u_2, ... u_n があって V のどのベクトル x も
x = x_1u_1 + x_2u_2 + ... + x_nu_n
と表されるとき u_1, u_2 ... u_n は V の生成系であると言います。これらが一次独立であり V を生成するとき、これらはベクトル空間 V の基底であると言います。
なお m x n 行列はプログラミング言語の用語ではデータフレームとも言います。
計算をする
関数に引数を与えることで、その関数の戻り値を得られます。
関数を利用する
たとえば統計量を得る関数のような主要な数学関数はほとんどのものが揃っています。
| 関数 | 説明 |
|---|---|
| sum | 合計 |
| mean | 平均 |
| sd | 標準偏差 |
sum(vec)
# => [1] 60
sum(mat)
# => [1] 210
関数を定義する
ビルトインでも関数は用意されていますが、関数は自分で定義可能です。
# 不偏分散を求める関数 varp を定義してみる
varp <- function(x) {
result <- var(x) * (length(x) - 1) / length(x)
return (result)
}
# varp を使ってみる
varp(vec)
# => [1] 66.66667
varp(mat[1,])
# => [1] 266.6667
varp(mat[,1])
# => [1] 25
このように R では無名関数を変数に代入することで関数を定義できます。上の例では次のような不偏分散を求める式を定義した無名関数を varp という変数に代入しているのと同じです。すべてが無名関数だと考えればわかりやすいですね。
function(x) { var(x) * (length(x) -1) / length(x) }
クロージャ
無名関数を利用すればクロージャを作ることもできます。
# クロージャの内部で x を増加
func <- function() {
x <- 0
function() {
x <<- x + 1
return (x)
}
}
# クロージャの外部で x を定義
x <- 10
closure <- func()
print(x)
# => [1] 10
print(closure())
# => [1] 1
print(closure())
# => [1] 2
print(closure())
# => [1] 3
# 外部の x は変化していない
print(x)
# => [1] 10
レポーティングする
ファイルの入出力をする
read.csv などの関数で読み込んだ CSV ファイルはデータフレームとして扱えます。反対にデータフレームを write.csv 関数で CSV ファイルに出力することもできます。このあたりは以前に R でのファイル入出力の方法で説明した通りです。
プロッティングする
これも以前にR の基本的なデータプロッティングで説明した通りです。
# プロッティングする関数を定義しておく
img <- function(x) {
png("image.png", width = 480, height = 480, pointsize = 12, bg = "white", res = NA)
plot(x, y)
dev.off()
}
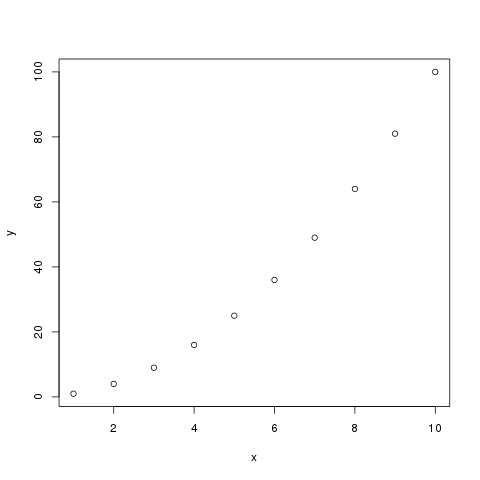
x = 1:10
x
# => [1] 1 2 3 4 5 6 7 8 9 10
y = x^2
y
# => [1] 1 4 9 16 25 36 49 64 81 100
# プロッティングする
img(x, y)
パッケージを使う
install.packages(パッケージ名) することによりパッケージを利用することができます。
# ミラーを指定する (この例では統計数理研究所を指定)
options(repos="http://cran.ism.ac.jp")
# パッケージをインストールする
install.packages('ggplot2')
# インストール済みパッケージの一覧を見る
library()
GNU/Linux の場合、管理者があれば /usr/local/lib/R/site-library に、書き込み権限が無ければホームディレクトリにインストールされます。どのようなパッケージがインストール済みかは library() とすると参照できます。
オススメのパッケージ
以前にもよく使う R のパッケージ一覧で紹介しましたが、データサイエンティストを目指すなら知っておきたいRパッケージ10個+αという記事も参考になりますのであわせて紹介します。一部筆者の独断でパッケージを増減しています。
| パッケージ名 | 説明 |
|---|---|
| randomForest | ランダムフォレスト、強力な汎用予測モデル |
| plyr | データ集約 |
| reshape2 | データ加工 |
| forecast | 時系列予測 |
| stringr | 文字列操作 |
| lubridate | 日付操作 |
| sqldf | SQL ライクなデータ操作 |
| ggplot2 | 高度なプロッティング |
| qcc | 品質管理 |
| party | 決定木が綺麗に描ける |
| gbm | randomForest より汎用性の高い強力な予測モデル |
| survival | 生存分析 |
| caTools,Epi | 予測モデルの性能評価に必要な ROC 曲線が描ける、 AUC を計算できる |
| XLConnect | エクセルのデータを読み込める、Rオブジェクトをエクセルに保存できる |
| DMwR | "Data Mining with R" の著者が作った強力なデータマイニンングパッケージ |
またこちらの R パッケージ一覧も参考になるでしょう。こちらはパッケージ名の掲載は省略します。
CRAN ミラーのパッケージを探る
CRAN には R のパッケージが数千あり、全世界にミラーされています。日本でも筑波大学や統計数理研究所、会津大学、東京大学、兵庫教育大学のミラーが存在します。
CRAN のパッケージリストは次の Wiki を参照すると良いでしょう。
http://www.okada.jp.org/RWiki/?CRAN%A5%D1%A5%C3%A5%B1%A1%BC%A5%B8%A5%EA%A5%B9%A5%C8
また R のための検索エンジンもあります。
http://seekr.jp/
どこのミラーを使ったら良いかについてはCRAN のミラーはどこが速いか調べた記事もあるので参考にすると良いでしょう。
車輪の再発明を避け、これらを利用して適宜必要なライブラリを利用すると良いでしょう。
実践例
重回帰分析
毎度おなじみ青木先生のページの内容にしたがって重回帰分析をしてみます。あらかじめソースコードを UTF-8 でファイルに保存しておきます。
# ソースコードを読み込む
source("mreg.R")
# データを作る
dat <- matrix(c(
1.2, 1.9, 0.9,
1.6, 2.7, 1.3,
3.5, 3.7, 2.0,
4.0, 3.1, 1.8,
5.6, 3.5, 2.2,
5.7, 7.5, 3.5,
6.7, 1.2, 1.9,
7.5, 3.7, 2.7,
8.5, 0.6, 2.1,
9.7, 5.1, 3.6
), byrow=TRUE, nc=3)
# データの中身を確認する
dat
# => [,1] [,2] [,3]
# [1,] 1.2 1.9 0.9
# [2,] 1.6 2.7 1.3
# [3,] 3.5 3.7 2.0
# [4,] 4.0 3.1 1.8
# [5,] 5.6 3.5 2.2
# [6,] 5.7 7.5 3.5
# [7,] 6.7 1.2 1.9
# [8,] 7.5 3.7 2.7
# [9,] 8.5 0.6 2.1
# [10,] 9.7 5.1 3.6
# 関数を呼び出す
mreg(dat)
# => 偏回帰係数 標準誤差 t 値 P 値 標準化偏回帰係数 トレランス
# Var1 0.20462 0.0075643 27.0506 2.4192e-08 0.67067 0.98358
# Var2 0.28663 0.0108015 26.5365 2.7638e-08 0.65793 0.98358
# 定数項 0.14918 0.0545063 2.7368 2.9050e-02
# 回帰の分散分析表
# 平方和 自由度 平均平方 F 値 P 値
# 回帰 6.671644 2 3.3358218 823.48 4.9319e-09
# 残差 0.028356 7 0.0040509
# 全体 6.700000 9 0.7444444
# 重相関係数 = 0.99788
# 重相関係数の二乗 = 0.99577
# 自由度調整済重相関係数の二乗 = 0.99456
# 対数尤度 = 15.13807
# AIC = -22.27614
まとめ
R の基本的な文法や使い方を一通り説明しました。あとは必要に応じて様々なパッケージを利用したり、先人の書いたソースコードなどを参考に、データ分析の数式を R のコードに落としてどんどん使っていきましょう。