はじめに
前回の記事 では,multi layer perceptron(MLP)のサンプルコードを走らせてみました.今回は畳み込みニューラルネットワーク(CNN)です.
サンプルコード
データセット・ネットワーク構造
データセットは前回と同じくMNISTの手書き文字データセットを使います($28 \times 28$の画像).
CNNの説明及びネットワーク構造について次の図を作ってみました.
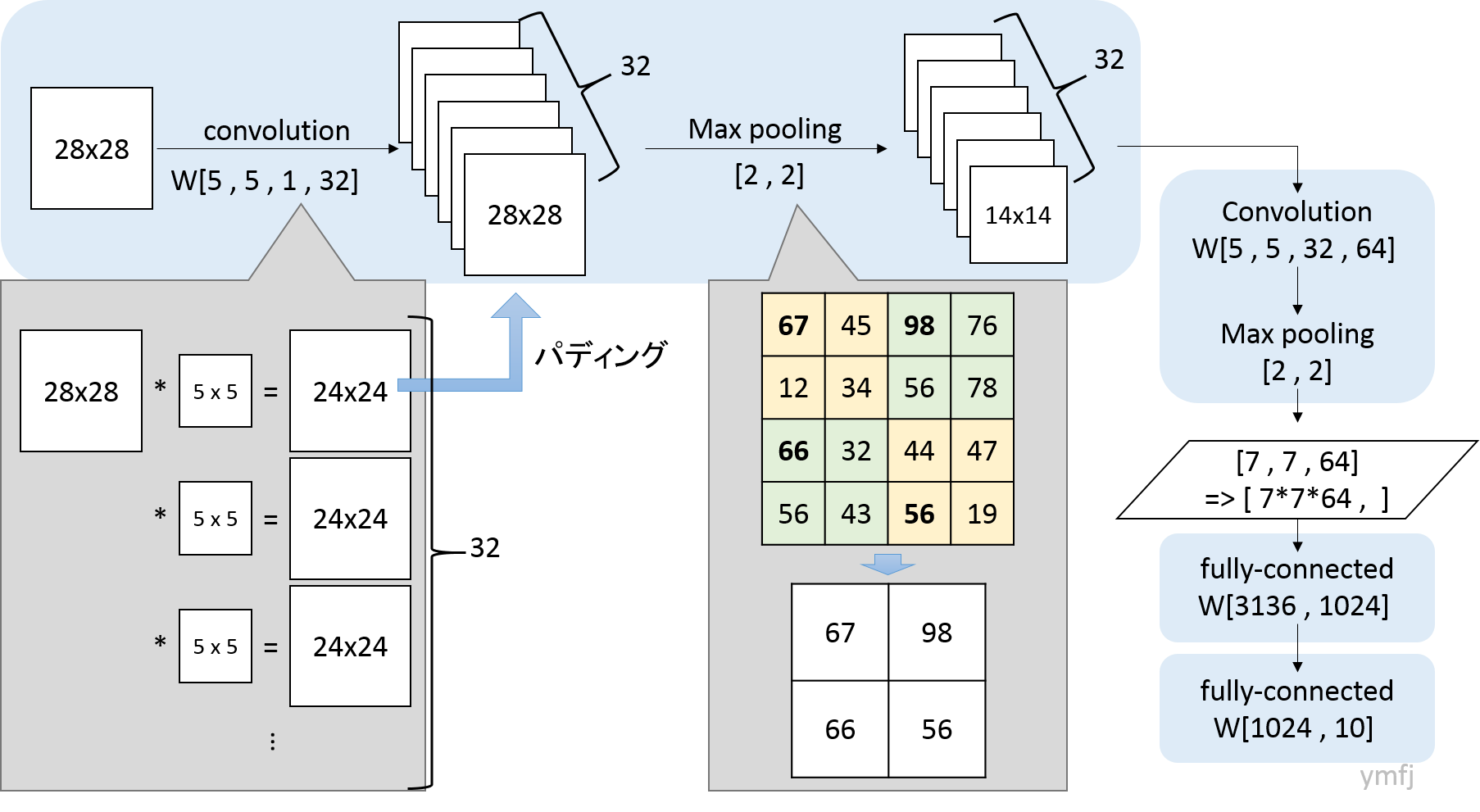
畳み込み層
畳み込みのフィルタサイズは$5 \times 5$で,ゼロパディングをしているので出力画像は入力画像と同じサイズになります.このパディングの操作,いまいち何のためにやっているか(やっていいのか)が説明できませんでした.
- サイズが途中で変わらないので次元の計算が簡単になる?
- 画像端の部分の特徴量抽出ができる?
という感じなのでしょうか?
プーリング
プーリング層ではマックス・プーリングを使いました.プーリングすることで,物体(文字)の位置ずれに強い特徴量抽出が行えるようになります.
ネットワークの記述
chianer
import chainer
import chainer.functions as F
import chainer.links as L
class CNN(chainer.Chain):
def __init__(self):
super(MLP, self).__init__(
conv1=L.Convolution2D(1, 32, 5, pad=2),
conv2=L.Convolution2D(32, 64, 5, pad=2),
l3=L.Linear(7 * 7 * 64, 1024),
l4=L.Linear(1024, 10),
)
def __call__(self, x):
h_conv1 = F.relu(self.conv1(x)) # xは[1,28,28]
h_pool1 = F.max_pooling_2d(h_conv1, 2)
h_conv2 = F.relu(self.conv2(h_pool1))
h_pool2 = F.max_pooling_2d(h_conv2, 2)
h_l3 = F.relu(self.l3(h_pool2))
y = F.relu(self.l4(h_l3))
return y
tensorFLow
import tensorFlow as tf
# input
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1, 28, 28, 1]) #フラットなベクトルを入力としているので2次元の画像に戻します
# conv1
w_conv1 = tf.Variable(tf.random_normal([5, 5, 1, 32], mean=0.0, stddev=0.05))
b_conv1 = tf.Variable(tf.zeros([32]))
h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, w_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
# pool1
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# conv2
w_conv2 = tf.Variable(tf.random_normal([5, 5, 32, 64], mean=0.0, stddev=0.05))
b_conv2 = tf.Variable(tf.zeros([64]))
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, w_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
# pool2
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
# FC3
W3 = tf.Variable(tf.random_normal([(28 / 2 / 2) ** 2 * 64, 1024], mean=0.0, stddev=0.05))
b3 = tf.Variable(tf.zeros([1024]))
h3 = tf.nn.relu(tf.matmul(h_pool2_flat, W3) + b3)
# FC4
W4 = tf.Variable(tf.random_normal([1024, 10], mean=0.0, stddev=0.05))
b4 = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(h3, W4) + b4)
# label
y_ = tf.placeholder(tf.float32, [None, 10])
本来は畳み込み層などはメソッド化するとよいです.今回はスライドにのせるために書き下しました.
おわりに
総じてtensorFlowに比べてchainerの方がシンプルに書けるかなという印象ですね."レイヤー型"の記述だからでしょうか.しかし,まだ私が実装したことのあるネットワーク構造は非常にシンプルなものであるためまだライブラリの違いを実感するレベルにはありません.「chainerはRNNを簡単にかける」という話を聞いたことがあるのでRNNも試してみたいところです.
そう言っておきながらあれですが,個人的にはtensorFlowを使っていこうかなと思っています.理由としては
- tensorBoardやdistributed tensorflowなどの拡張機能
- googleってことで発展性がありそう?
みたいなところです.
tensorBoardは試してみましたが,パラメータ等のビジュアライズは便利そうです.そして肝は分散処理を簡単に(?)行えるdistributed tensorflowです.まだ試してみませんが,TITAN4枚刺しのサーバ複数台の環境が使えるようになる(かもしれない)ので是非試してみたいものです.