TL;DR
自作のReplay Bufferライブラリcpprb を使って、DQNを実装してみた。
高い自由度と効率性を兼ね備えている(つもりな)のでおすすめ。
1. 背景と経緯
Open AI/Baselines や Ray/RLlib のような、強化学習一式の環境を利用すると、ちょっとしたコードで様々なアルゴリズムを試してみることができる。
例えば、Open AI/Baselinesで、AtariのPongをDQNで学習させるには以下のコマンドを実行するだけで良いと公式READMEに記載されている。
python -m baselines.run --alg=deepq --env=PongNoFrameskip-v4 --num_timesteps=1e6
一方、既存のアルゴリズムをテストするのは簡単だけれども、研究者やライブラリ開発者が新しい独自アルゴリズムを作ろうとした際に、どこから手をつけていいのか大きすぎて大変だと思う。
強化学習の研究をしている友人もTensorFlowなどの深層学習のライブラリは利用するものも、他の部分は独自に実装してた(ようであった)。
そんな2018年の暮れ頃、その友人から「Cythonって興味ある? Pythonで実装しているReplay Bufferが、(状況によっては)深層学習の学習部分なみに遅くて、Cythonでスピードアップを図りたいんだけど」(記憶)と誘われて実装始めたのが cpprb である。
(その友人は、cpprbとTensorFlow 2.x を利用して、tf2rlという強化学習ライブラリを公開していて、こちらも超おすすめ!)
2. 特徴
そんな背景もあって実装はじめた cpprb なので、高い自由度と効率性に主眼をおいて開発している。
2.1 高い自由度
バッファに保存する変数名・サイズ・型を dict 形式で指定することで自由に決めることができる。
例えば、極端な例だが、 next_next_obs, previous_act, secondary_reward なんてものも保存することができる。
import numpy as np
from cpprb import ReplayBuffer
buffer_size = 1024
# shape と dtype を変数ごとに指定できる。デフォルトは、{"shape":1,"dtype": np.float32}
rb = ReplayBuffer(buffer_size,
{"obs": {"shape": (3,3)},
"act": {"shape": 3, "dtype": np.int},
"rew": {},
"done": {},
"next_obs": {"shape": (3,3)},
"next_next_obs": {"shape": (3,3)},
"previous_act": {"shape": 3, "dtype": np.int},
"secondary_reward": {}})
# Key-Value 形式で指定する (初期化時に指定した変数が不足していると `KeyError`)
rb.add(obs=np.zeros(shape=(3,3)),
act=np.ones(3,dtype=np.int),
rew=0.5,
done=0,
next_obs=np.zeros(shape=(3,3)),
next_next_obs=np.ones(shape=(3,3)),
previous_act=np.ones(3,dtype=np.int),
secondary_reward=0.3)
2.2 効率性
Prioritized Experience Replayの遅さの原因であるSegment TreeをCython経由で、C++実装しているため、かなり早い。
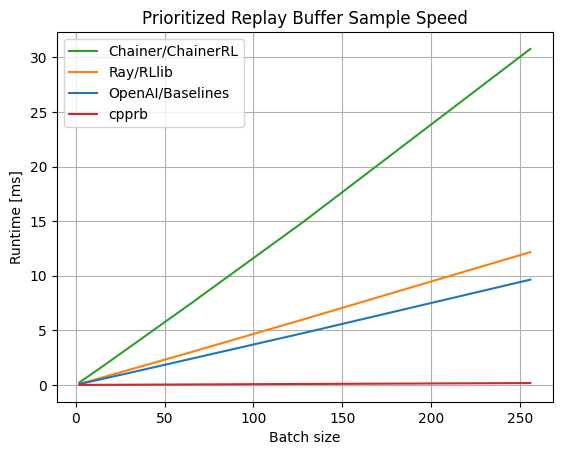
ベンチマークを見る限り速度で圧勝している。(2020年4月現在。最新版はプロジェクトサイトへ)
注意: 強化学習全体では、Segment Treeの速度だけではなくて、うまく探索を並列化させるなどの対策が重要
3. インストール
(情報が古くなってるかもしれないので、最新のインストール方法も参照)
3.1 バイナリインストール
PyPIに公開しているので、pip(や類似のツール)を用いてインストールすることができる。
Windows/Linux向けには、wheel形式のバイナリを配布しているので、多くの場合は何も考えずに以下のコマンドでインストールすることができる。
(注: venv やdocker等仮想環境の利用を推奨。)
pip install cpprb
注: macOSは標準の開発ツールチェインの一部になっている clang が、 C++17 の機能の std::shared_ptr の配列型への特殊化を未実装のためコンパイルできずバイナリを配布できていない。
3.2 ソースからインストール
ソースコードから各自ビルドする必要がある。ビルドには以下が必要である。
- GCC >= 7.2(?)
環境変数 CC と CXX に g++ を指定してビルドを実行する必要がある。
3. DQN実装
(2020年7月26日: cpprbのバージョンアップ及び、gnwrapperの利用によりコードを修正)
Google Colab 上で動作するDQNを書いてみた
まずは、必要なライブラリをインストール
!apt update > /dev/null 2>&1
!apt install -y xvfb > /dev/null
!pip install gym gym-notebook-wrapper cpprb["all"] tensorflow > /dev/null
%load_ext tensorboard
# Standard Library
import os
import datetime
# 3rd Party
import gym
import numpy as np
from scipy.special import softmax
import tensorflow as tf
from tensorflow.keras.models import Sequential,clone_model
from tensorflow.keras.layers import InputLayer,Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping,TensorBoard
from tensorflow.summary import create_file_writer
from tqdm.notebook import tqdm
from cpprb import create_buffer
import gnwrapper
%load_ext tensorboard
%tensorboard --logdir logs
gamma = 0.99
batch_size = 1024
buffer_size = int(1e6)
N_iteration = 12000
per_train = 10
prioritized = True
egreedy = False
loss = "huber_loss"
# loss = "mean_squared_error"
env_name = 'CartPole-v1' # reward = 1
# env_name = 'MountainCar-v0' # reward = -1
# env_name = 'Acrobot-v1' # reward = -1
JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST')
dir_name = datetime.datetime.now(JST).strftime(f"%Y%m%d-%H%M%S-{env_name}")
logdir = os.path.join("logs", dir_name)
writer = create_file_writer(logdir + "/metrics")
writer.set_as_default()
env = gym.make(env_name)
env = gnwrapper.Monitor(env,logdir + "/video/")
observation = env.reset()
model = Sequential([InputLayer(input_shape=(observation.shape)), # 4 for CartPole
Dense(64,activation='relu'),
Dense(64,activation='relu'),
Dense(env.action_space.n)]) # 2 for CartPole
target_model = clone_model(model)
optimizer = Adam()
model.compile(loss = loss,
optimizer = optimizer,
metrics=['accuracy'])
Nstep = {"size":4, "gamma": gamma, "rew":"rew", "next": "next_obs"}
rb = create_buffer(buffer_size,
{"obs":{"shape": observation.shape},
"act":{"shape": 1,"dtype": np.ubyte},
"rew": {},
"next_obs": {"shape": observation.shape},
"done": {}},
prioritized = prioritized,
Nstep=Nstep)
action_index = np.arange(env.action_space.n).reshape(1,-1)
n_episode = 0
observation = env.reset()
sum_reward = 0.0
for total_step in tqdm(range(N_iteration)):
actions = softmax(np.ravel(model.predict(observation.reshape(1,-1),batch_size=1)))
actions = actions / actions.sum()
if egreedy:
if np.random.rand() < 0.1:
action = env.action_space.sample()
else:
action = np.argmax(actions)
else:
action = np.random.choice(actions.shape[0],p=actions)
next_observation, reward, done, info = env.step(action)
sum_reward += reward
rb.add(obs=observation,
act=action,
rew=reward,
next_obs=next_observation,
done=done)
observation = next_observation
if rb.get_stored_size() == 0:
continue
sample = rb.sample(batch_size)
Q_pred = model.predict(sample["obs"])
Q_true = sample['rew'] + gamma*(sample["discounts"] if Nstep else 1)*(1.0 - sample["done"])*target_model.predict(sample['next_obs']).max(axis=1,keepdims=True)
target = tf.where(tf.one_hot(tf.cast(tf.reshape(sample["act"],[-1]),dtype=tf.int32),env.action_space.n,True,False),
tf.broadcast_to(Q_true,[batch_size,env.action_space.n]),
Q_pred)
if prioritized:
TD = np.square(target - Q_pred).sum(axis=1)
rb.update_priorities(sample["indexes"],TD)
weights = sample["weights"] if prioritized else None
model.fit(x=sample['obs'],
y=target,
batch_size=batch_size,
sample_weight=weights,
verbose = 0)
if total_step % per_train == 0:
target_model.set_weights(model.get_weights())
tf.summary.scalar("step reward",data=reward,step=total_step)
tf.summary.scalar("episode vs total step",data=n_episode,step=total_step)
if bool(done):
tf.summary.scalar("episode reward vs episode",data=sum_reward,step=n_episode)
tf.summary.scalar("episode reward vs total step",data=sum_reward,step=total_step)
observation = env.reset()
rb.on_episode_end()
n_episode += 1
sum_reward = 0.0
env.display()
4. 結果
rewardの結果(x軸:エピソード・y軸:エピソード報酬)。

6. まとめ
強化学習向けReplay Bufferを提供する自作ライブラリ cpprb を利用して、DQNを実装した。
cpprb は高い自由度と効率性を重視して開発している。
興味を持ってくれた人は、試してみて issueやマージリクエストをぜひ。(英語が好ましいけど、日本語でもOK)