こちらは、ハンズラボ Advent Calendar 2018 20日目の記事になります!
はじめに
2018年9月にハンズラボに入社しました@yktakaha4です
配属されたチームにて開発環境の構築にDockerを使っているのですが、
過去触ったことがなかったため当初何が起きてるのか全くわからず、やばいじゃん...😨と思って勉強することにしました
Docker/Kubernetes 実践コンテナ開発入門のDocker周りの章を読んで多少整理がついたので、
何事も実践が一番!ということで、実際にDocker Composeを使って作業環境を作ってみることにしました
どんなものを作るか
世間ではデータ分析の重要性が説かれて久しいですね📈
東急ハンズにおいても、BIツールや各種分析システムが導入されていますが、
時として、個人レベルでちょっとした分析作業をやってみたい/しなければならないということもあるものと思います
遊びだったらいいですが、あまり手作業&ノリでやると、定型作業化したり、案件化した際に他者へ展開するのが辛くなりそうです
そこで、以下のような要件を仮定して、個人向けデータ分析基盤をDockerで作ることに挑戦します✨
- RDBやストレージ、Web等からデータを集めてくる
- データを整形・集計する
- 集計した結果を可視化する
- 思いついたことをパッと試せる
どのように作るか
弊社でも導入しているCacooを使って、図にしてみました
上に書いた要件と対比してひとつずつ見ていきます
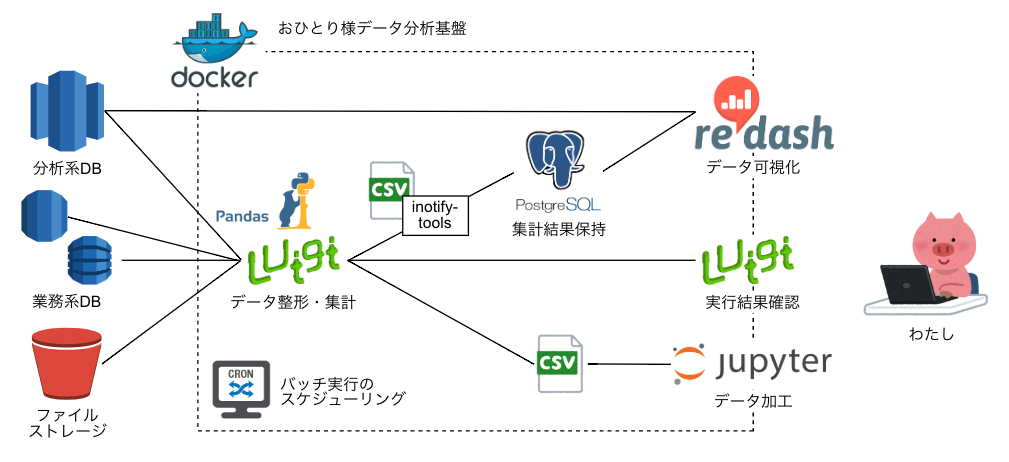
RDBやストレージ、Web等からデータを集めてくる
弊社はAWSを激推ししているので、データは基本AWSの各種サービス(Redshift、RDS、DynamoDB、S3など)に蓄積されています
マスタデータを管理するDBに好き勝手に繋ぎにいくのは避けたいので、データは稼働の低い時間帯にアクセスし、TSVなどのファイルに落としておくのがよさそうです
また、弊社が採用している技術のひとつであるユニケージ開発手法は基本的にファイル文化なのですが、
ユニケージ形式のファイルはSSV(って言うんですね...半角スペース区切り)、ヘッダなし、空値は _ で表現という書式のため、よくあるファイルと同様に扱うにはちょっとした加工が必要になります
# 1:ID 2:商品名 3:価格 4:種別
001 りんご 100 1
002 みかん 50 2
003 きゅうり 80 _
データの鮮度についても、最初はスクリプトを書いて手実行...でよいものと思いますが、
定型化・自動化を見据えてcrontabを使えるようにしておきたいです
データを整形・集計する
ネットで データ分析基盤 で調べると企業レベルの事例の話が沢山出てきますが、
データソースから生データを取ってきて整形・集計...という流れを自動化するのがセオリーのようです
今回は、バッチフレームワークのLuigiを使ってデータパイプラインを構築します。シンプルでいい感じです
データの加工・集計にはデータフレームのライブラリであるPandasを使います
以下のように、元のデータがTSVであってもユニケージ形式であっても、うまいこと扱うことができます
というか大抵のデータ操作はまずできます。すごい...
import pandas as pd
# ユニケージファイルの読み込み
items_unicage = pd.read_csv('./ITEMS', sep=' ', dtype=str, header=None).replace('_', '')
items_unicage.columns = ['id', 'name', 'price', 'type']
# TSVの読み込み
items_tsv = pd.read_csv('./items.tsv', sep='\t', dtype=str)
Pythonを本格的に使い始めたのは入社してからなのですが、
こうした諸々を手軽にやれるのは、舗装された道路を走っているようなものでありがたいですね...
集計した結果を可視化する
データの整形・集計が済んだら、次は可視化です
今回は、これまたシンプルにやりたいことが実現できそうだったので、ダッシュボードツールのRedashを使えるようにします(watarukuraさんに勧めて頂きました)
Redashは基本的にSQLでデータを取り出してグラフ化する...というものなので、
今までの工程で生成してきた各種集計ファイルをプールする集計結果保持用のDB(PostgreSQL)を用意します🐘
また、今までは定型化された分析処理の話ばかりしていましたが、
初期段階では分析用DBにアドホックにクエリを打って、複数のデータを作ってそれを結合するクエリを打って...のような柔軟な操作ができると使い勝手がよさそうです
Redashではそうした要望を実現するためにQuery Resultsという機能がベータ版で提供されていますが、
複雑なクエリだとエラーを吐くケースもありちょっと不審だったので、今回は違う方法で実現します(後述)
思いついたことをパッと試せる
前項で、分析をアドホックに試したいという話がありましたが、
他のツールやライブラリを使ってみるとか、機械学習はどうかとか、分析の手法はいくらでも考えられそうです
データパイプラインに処理を落とし込む前に、ファイルの整形・集計処理のコードを検討するためにも、対話型の環境があると便利でしょう
そうした要件に取り組みやすくなるよう、JupyterLabを導入しておきます
こっちはthimi0412さんに教えてもらいましたが、各種ライブラリを試しつつ&結果を残しつつ作業できるのでだいぶよさげです
パッと試して、それからどうする?
最終的には分析結果を店舗で働いてる業務部門の方々に見せることにもなりそうですが、
その際に話が弾んで、分析の軸を変えてほしいとか、対象のデータを増減させたい...と意見がもらえた時に、柔軟に対処できるとよさそうです
具体的には、以下のようなフローがスムーズに実現できるか、ということになるでしょうか
- 何かしらの方法で元データファイルを作る
- Jupyterでファイルの生成スクリプトを書く
- RedashでSQL書いて、生成した結果表をCSVエクスポートする(標準機能で付いてます)
- S3やネットなどからファイルを落としてくる
-
ユニケージコマンドを駆使して手作業で作る
- 余談ですが、ちょっとしたデータ加工においてユニケージはだいぶ有用です。筆者は特に
yarrが好きです...
- 余談ですが、ちょっとしたデータ加工においてユニケージはだいぶ有用です。筆者は特に
- 元データファイルを集計用DBに取り込む。できるだけ手軽に🤗
- Redashで可視化する
上記の2.について、何かファイルをいじる度にバッチを叩いたり、cronがポーリングしてくれるのを待ったりなどはしたくないので、
inotifywaitを使ってコンテナ内の所定のディレクトリを監視し、ファイルが更新されたら集計用DBにデータをロードするようにします
今回は、こんな定義ファイルをyamlでたくさん用意しておき、処理対象のファイル名とマッチしたら集計用DBにDDLを発行...というLuigiタスクを作って、実行するようにしました
pattern: "/ITEMS$"
format:
encoding: "utf-8"
newline: "\n"
skip: 0
delimiter: " "
doublequote: false
escapechar: ""
skipinitialspace: false
replacers:
- pattern: "^_$"
newvalue: ""
table_name: "items"
ddl: |
drop table if exists {table_name};
create table {table_name} (
item_id varchar(3) not null,
name varchar(255) not null,
price int not null,
item_type varchar(1) not null,
primary key(item_id)
);
format:
encoding: "utf-8"
newline: "\n"
skip: 1
delimiter: ","
doublequote: true
escapechar: "\""
skipinitialspace: false
作ったもの
社内で使っているものをそのまま公開はアレでしたので、今回説明した内容に機能を絞ったものをGithubに公開しました![]()
以下、簡単に解説していきます
初期構築・起動・停止
任意のディレクトリで以下のコマンドを実行してください
~❯ git clone https://github.com/yktakaha4/analysis-docker.git
~❯ cd analysis-docker
# ビルド実行後、Redash用、集計結果保持用のDBをそれぞれ作成
❯ docker-compose build
❯ docker-compose run --rm server create_db
❯ docker-compose run --rm luigi create_db
# 起動・停止(2回目以降は以下のみでOK)
❯ docker-compose up
❯ docker-compose down
Jupyter確認
localhost:25002にアクセスすると、JupyterLabが起動します
data/watch配下を確認すると、サンプルファイルが入っているのが確認できます
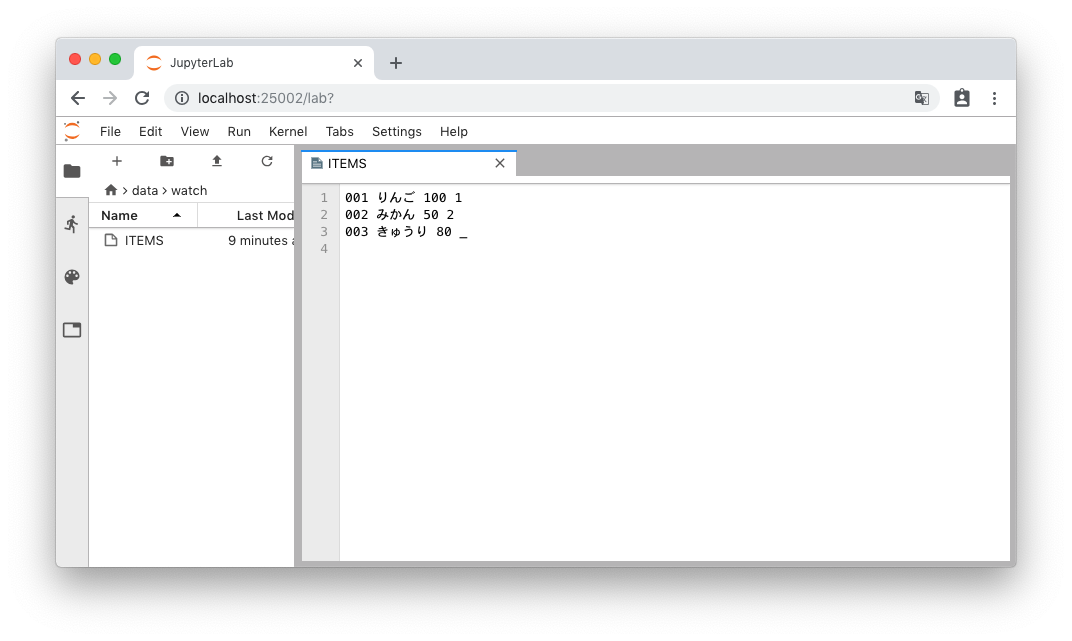
使い方などは話がそれるので割愛
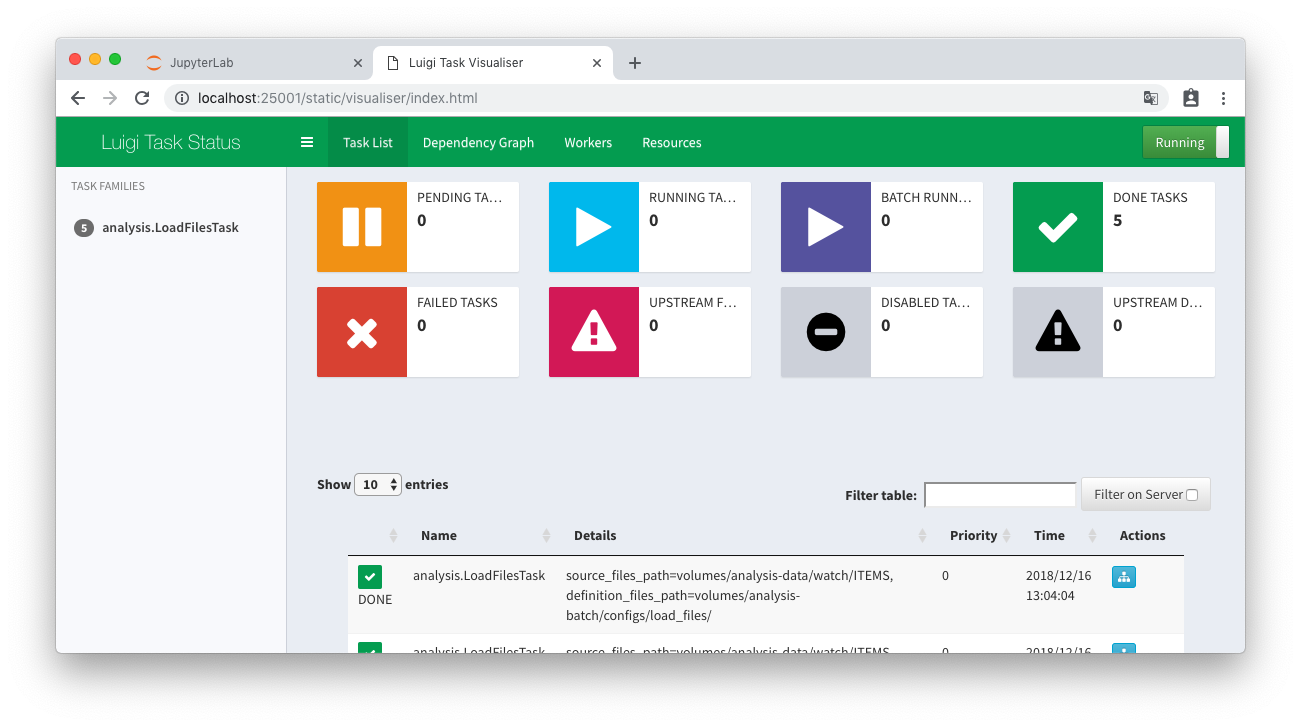
Luigiとinotifywait確認
別のターミナルを立ち上げて、テスト用ファイルを更新してみます
inotifywaitにより更新が検知され、集計DBにデータがロードされます
# 先ほどと同じディレクトリに移動して実行すること
❯ ll volumes/analysis-data/watch/ITEMS
-rw-r--r-- 1 tkhs staff 61B Dec 16 13:00 volumes/analysis-data/watch/ITEMS
❯ touch volumes/analysis-data/watch/ITEMS
# docker-composeを実行した方のターミナルに、タスクの実行ログが表示される
(略)
luigi_1 | ===== Luigi Execution Summary =====
luigi_1 |
luigi_1 | Scheduled 1 tasks of which:
luigi_1 | * 1 ran successfully:
luigi_1 | - 1 analysis.LoadFilesTask(source_files_path=/root/analysis/data/watch/ITEMS, definition_files_path=/root/analysis/batch/configs/load_files)
luigi_1 |
luigi_1 | This progress looks :) because there were no failed tasks or missing dependencies
luigi_1 |
luigi_1 | ===== Luigi Execution Summary =====
(略)
localhost:25001にアクセスすると、タスクの実行結果を確認することができます
Redash確認
最後に、localhost:25000にアクセスしてRedashを起動し、データが正しく登録されたか確認します
初期設定をして...(ローカルアカウントの設定なので、忘れなければ任意のもので多分よいです)
Connect a Data Source > New Data Source > PostgreSQL からデータソースを作成して...
| 名前 | 値 |
|---|---|
| Name | summary(任意) |
| Host | postgres |
| User | postgres |
| Database Name | summary |

summaryのitemsテーブルにクエリを打ってみます
ユニケージ形式だったファイルが正しく読み込めていることが確認できますね!

取得したデータを元に棒グラフを作り、りんごの価格が一番高いことを視覚的に明らかにした瞬間です📊🤔

ファイルを更新後クエリを再実行すれば、直ちにグラフを再生成することもできます
ちょっとしたことではありますが、分析作業を繰り返すうちにきっとジャブのように効いてくるものと思います

docker-compose.ymlについて
コンテナと役割についてまとめてみました
実物としては、こちらやこちらやこちら、こちらなど、既にある実装を パクリ 調べながら読んで内容理解に努めました
| コンテナ名 | 役割 | 備考 |
|---|---|---|
| server、 worker、 redis |
Redashが使うやつです(適当) | http://localhost:25000/ |
| postgres | Redash内部データと集計データ保持を兼ねたDB | |
| luigi | Luigiとinotifywait |
http://localhost:25001/ 複数プロセス実行のためsupervisordを使用 |
| jupyterlab | JupyterLab | http://localhost:25002/ |
動くこと優先で作ったためイケてない部分も色々ありそうなので、使いながらよくしていきたいと思っています
所感
思ったことを箇条書きで...
- 当初は大量のコマンドと定義ファイルの書式、スケールの大きな概要の説明に圧倒されていましたが、1コンテナ≒1プロセスなど、原則が頭に入ってくるとイメージが掴みやすくなったように思います
- まずは、概要の話を読んでから取り組むことをお勧めします
- 情報を上から読んでいってできるようになる、というよりも、実現したい機能を洗い出して、それぞれについてどのようなコンテナがあれば実現可能か考えるのが大事です。DockerHubに既存のものがないか調べるのも重要です
- それにつけても、こうやって一度定義を書いてしまえば誰でも/どこでも環境構築ができて、それが無料で自分でも使うことができるというのは、本当にすごい時代になったなあ...と思います
今後の展望
現時点でまだできてない部分をまとめます
- crontabの導入
- データ分析作業がまだ試行錯誤の段階で定型作業にしたいものがなかったため、後回しにしてたら公開に間に合いませんでした...
- こちらなどを見てもいくつか選択肢がありそうなので、調べつつ近く実装したいと思います
- 環境変数/資格情報の渡し方
- AWSの各種サービスに繋ぎに行くために何かしら渡す必要がありますが、起動時にいい感じに注入する方法が確立できておらず、今回はバッサリはしょりました...
- AWS上での運用
- 特にRedashはアカウント管理ができるということもあり、サーバで運用できるとデータ共有の面でメリットが大きいので、色々調べつつ是非ともチャレンジしたいです!
- データ分析をガンガンやる
- 正直やっとスタートラインに立った、という話なので、環境を作って満足...とならないよう、頑張りたいと思います😇
ハンズラボ Advent Calendar 2018 明日は、弊社ブログでも活躍されている@yuka_jyoteiさんです!