著者 Wenjie Tehan
最終更新日 2022年2月14日
警告
本記事はGetting Startedに掲載された内容を抄訳したものです。掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。正確な内容については、原本をご参照下さい。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
概要
このハウツーでは、SalesforceとTeradata Vantageの間でデータを移行するプロセスについて説明します。2つのユースケースを含みます。
① Salesforceから顧客情報を取得し、Vantageから注文および出荷情報と組み合わせて、分析的な洞察を得ます。
② Vantage の newleads テーブルを Salesforce のデータで更新し、AppFlow を使用して新しいリードを Salesforce に追加します。
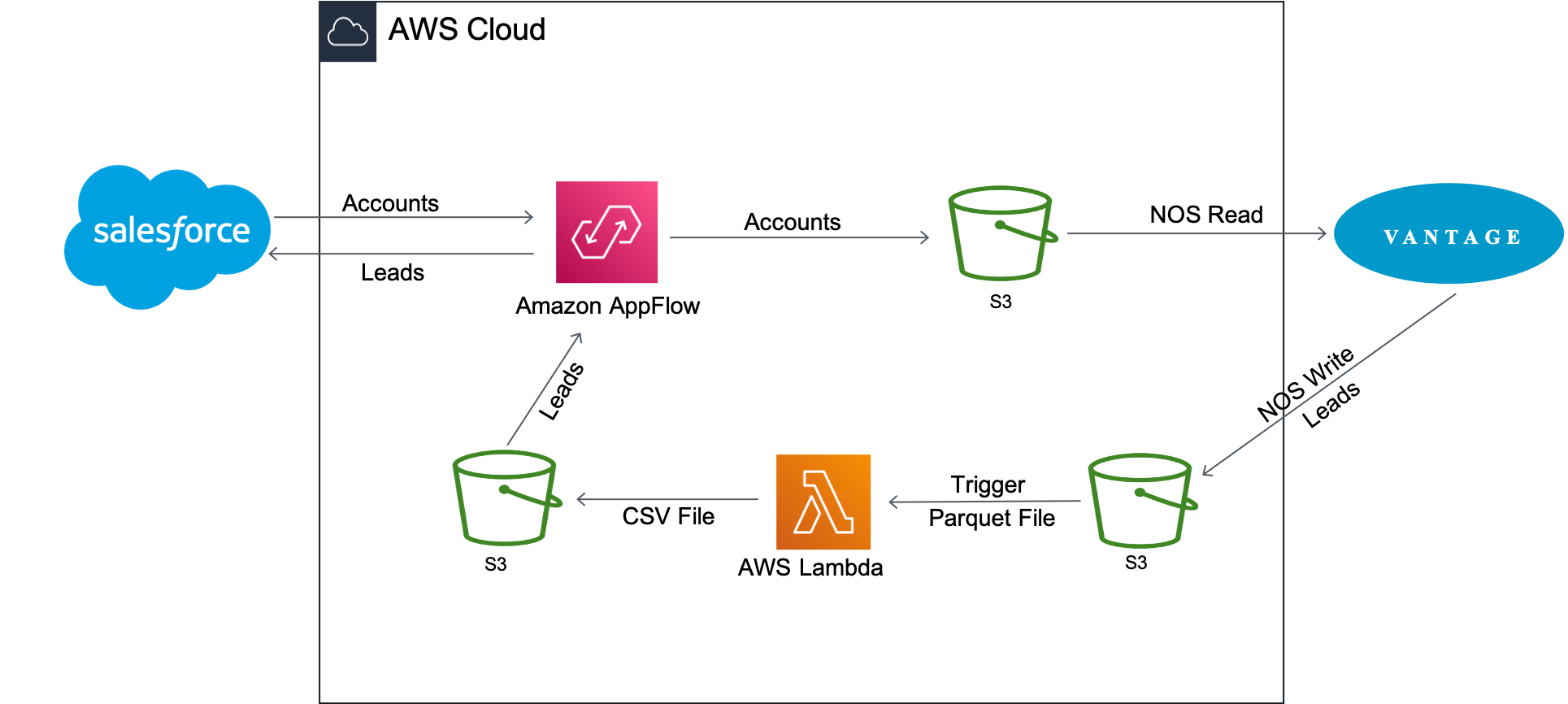
Amazon AppFlowは、SalesforceからAmazon S3に顧客アカウントデータを転送します。その後、Vantage は Native Object Store (NOS) の読み込み機能を使用して、Amazon S3 のデータと Vantage のデータを 1 回のクエリで結合します。
アカウント情報は、Vantage 上の newleads テーブルの更新に使用されます。テーブルが更新されると、VantageはNOS WriteでAmazon S3バケットに書き戻す。新しいリードデータファイルの到着時にLambda関数が起動し、データファイルをParquet形式からCSV形式に変換し、AppFlowは新しいリードをSalesforceに挿入し直します。
Amazon AppFlowについて
Amazon AppFlowは、Salesforce、Marketo、Slack、ServiceNowなどのSaaSアプリケーションと、Amazon S3やAmazon RedshiftなどのAWSサービス間で安全にデータを転送できる、フルマネージド型の統合サービスです。AppFlowは、移動中のデータを自動的に暗号化し、AWS PrivateLinkと統合されたSaaSアプリケーションの公衆インターネット上でのデータの流れを制限することができ、セキュリティ脅威への露出を減らすことができます。
本日現在、Amazon AppFlowは16のソースから選択でき、4つの宛先にデータを送信することができます。
Teradata Vantageについて
Teradata Vantageは、エンタープライズ分析のためのマルチクラウド対応データプラットフォームであり、データに関する課題を最初から最後まで解決します。
Vantageにより、企業は小規模から始めてコンピュートやストレージを弾力的に拡張し、使用した分だけ支払い、低コストのオブジェクトストアを活用し、分析ワークロードを統合することができます。Vantageは、R、Python、Teradata Studio、その他あらゆるSQLベースのツールをサポートします。
Vantageは、記述的分析、予測的分析、処方的分析、自律的意思決定、ML機能、可視化ツールを統合したプラットフォームで、データがどこにあっても、リアルタイムのビジネスインテリジェンスを大規模に発掘することができます。
Teradata Vantage Native Object Store(NOS)は、Amazon S3などの外部オブジェクトストアにあるデータを、標準SQLを使用して探索することが可能です。NOSを使用するために、特別なオブジェクトストレージ側の計算インフラは必要ありません。Amazon S3のバケットにあるデータを探索するには、バケットを指すNOSテーブル定義を作成するだけでよいのです。NOSを使用すると、Amazon S3からデータを迅速にインポートしたり、Vantageデータベースの他のテーブルと結合したりすることもできます。
前提条件
Amazon AppFlowサービスおよびTeradata Vantageに精通していることが前提です。
以下のアカウントとシステムが必要です。
・Teradata Vantageインスタンスへのアクセス。
メモ!
Vantageの新しいインスタンスが必要な場合は、Google Cloud、Azure、AWSのクラウドにVantage Expressという無料版をインストールすることができます。また、VMware、VirtualBox、またはUTMを使用して、ローカルマシン上でVantage Expressを実行することもできます。
・フローの作成と実行が可能なロールを持つAWSアカウント。
・Salesforce データを保存するための Amazon S3 バケット (例: ptctsoutput)
・生の Vantage データ (Parquet ファイル) を保存する Amazon S3 バケット (例: vantageparquet)。このバケットには、Amazon AppFlowのアクセスを許可するポリシーが必要です。
・変換された Vantage データ (CSV ファイル) を保存する Amazon S3 バケット (例: vantagecsv)
・以下の要件を満たすSalesforceアカウント。
○ お客様の Salesforce アカウントで、API アクセスを有効にする必要があります。Enterprise、Unlimited、Developer、および Performance エディションでは、API アクセスはデフォルトで有効になっています。
○ Salesforce アカウントで、接続アプリのインストールが許可されている必要があります。これが無効になっている場合は、Salesforce 管理者にお問い合わせください。Amazon AppFlow で Salesforce 接続を作成した後、「Amazon AppFlow Embedded Login App」という名前の接続アプリが Salesforce アカウントにインストールされていることを確認します。
○ Amazon AppFlow Embedded Login App」のリフレッシュトークンポリシーは、「Refresh token is valid until revoked」に設定されている必要があります。そうでない場合、リフレッシュトークンの有効期限が切れるとフローが失敗します。
○ イベント駆動型のフロートリガーを使用するには、SalesforceのChange Data Captureを有効にする必要があります。セットアップから、クイック検索に「Change Data Capture」と入力します。
○ Salesforce アプリが IP アドレスの制限を実施している場合、Amazon AppFlow で使用するアドレスをホワイトリストに登録する必要があります。詳細については、Amazon Web Services General Reference の https://docs.aws.amazon.com/general/latest/gr/aws-ip-ranges.html[AWS IP address ranges] を参照してください。
○ Salesforce のレコードを 100 万件以上転送する場合、Salesforce の複合フィールドを選択することはできません。Amazon AppFlow は転送に Salesforce Bulk API を使用するため、複合フィールドの転送は許可されません。
○ AWS PrivateLinkを使用してプライベート接続を作成するには、Salesforceアカウントで「メタデータの管理」と「外部接続の管理」の両方のユーザー権限を有効にする必要があります。プライベート接続は現在、us-east-1 および us-west-2 の AWS リージョンで利用可能です。
○ 履歴オブジェクトなど、更新できないSalesforceオブジェクトがあります。これらのオブジェクトについて、Amazon AppFlowは、スケジュールトリガー型のフローの増分エクスポート(「新しいデータのみを転送」オプション)をサポートしません。代わりに、「すべてのデータを転送する」オプションを選択し、適切なフィルタを選択して転送するレコードを制限することができます。
手順
前提条件を満たした上で、以下の手順で行います。
① SalesforceからAmazon S3へのフローを作成する
② NOSを使用してデータを探索する
③ NOS を使用して Vantage データを Amazon S3 にエクスポートします。
④ Amazon S3からSalesforceへのフローを作成する
SalesforceからAmazon S3へのフローを作成する
このステップでは、Amazon AppFlowを使用してフローを作成します。この例では、Salesforceの開発者アカウントを使用してSalesforceに接続します。
AppFlowコンソールにアクセスし、AWSログイン認証でサインインし、Create flowをクリックします。正しいリージョンにいること、Salesforceのデータを保存するためのバケットが作成されていることを確認します。
ステップ1:フローの詳細を指定する
このステップでは、フローの基本情報を提供します。
フロー名(例:salesforce)と フローの説明(オプション) を入力し、暗号化設定のカスタマイズ(詳細) のチェックを外したままにします。次へをクリックします。
ステップ2:フローを設定する
このステップでは、フローのソースとデスティネーションに関する情報を提供します。この例では、ソースとしてSalesforceを、デスティネーションとしてAmazon S3を使用します。
・Source nameでSalesforceを選択し、Choose Salesforce connectionでCreate new connectionを選択します。
・Salesforce 環境とデータの暗号化には、デフォルトを使用します。接続に名前(例:salesforce)を付けて、[続行]をクリックします。
・salesforceのログイン画面で、UsernameとPasswordを入力します。ログインをクリックします。
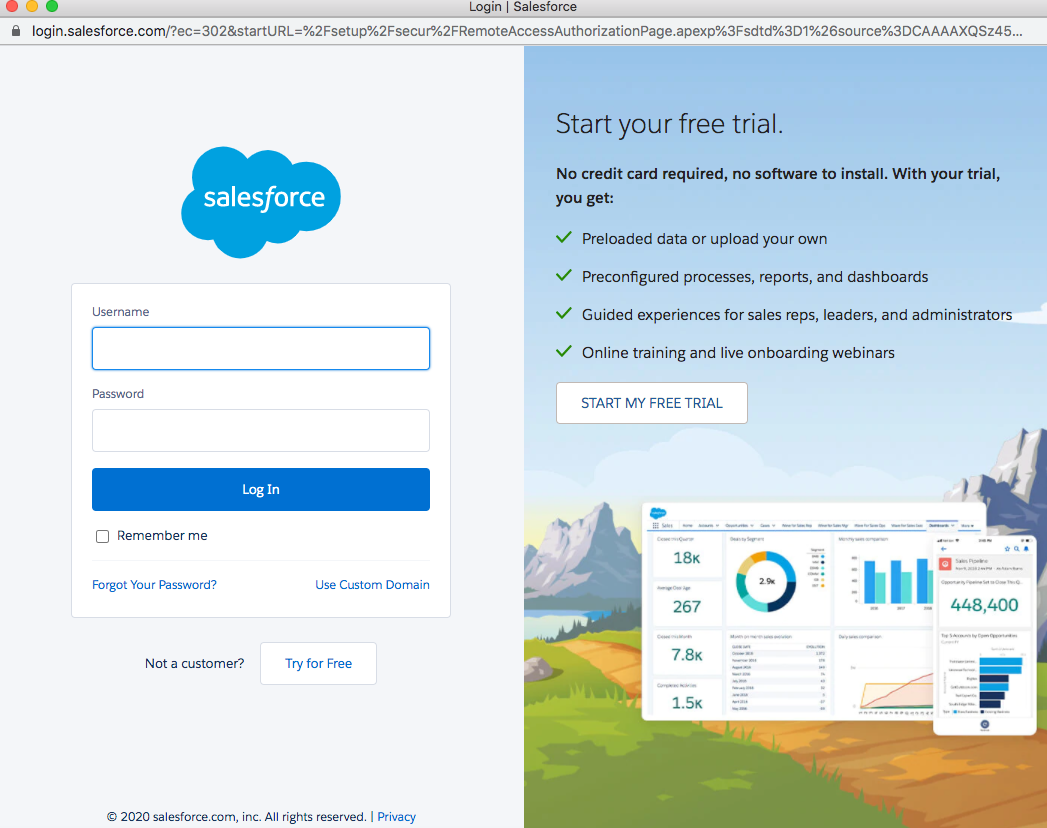
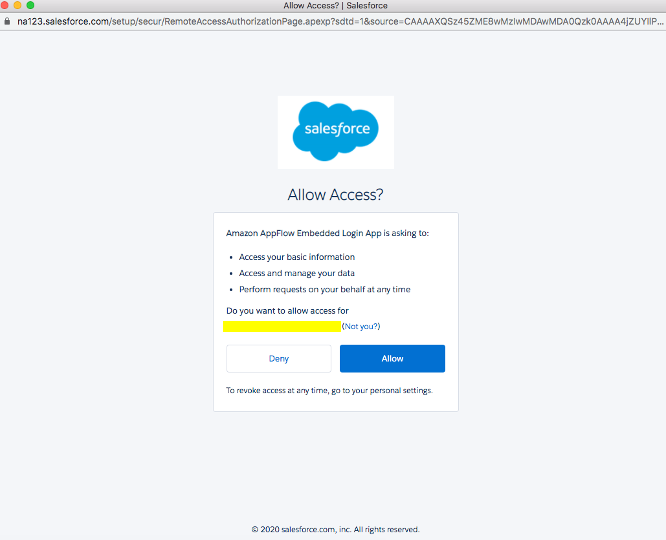
・許可をクリックして、AppFlowによるSalesforceのデータおよび情報へのアクセスを許可します。
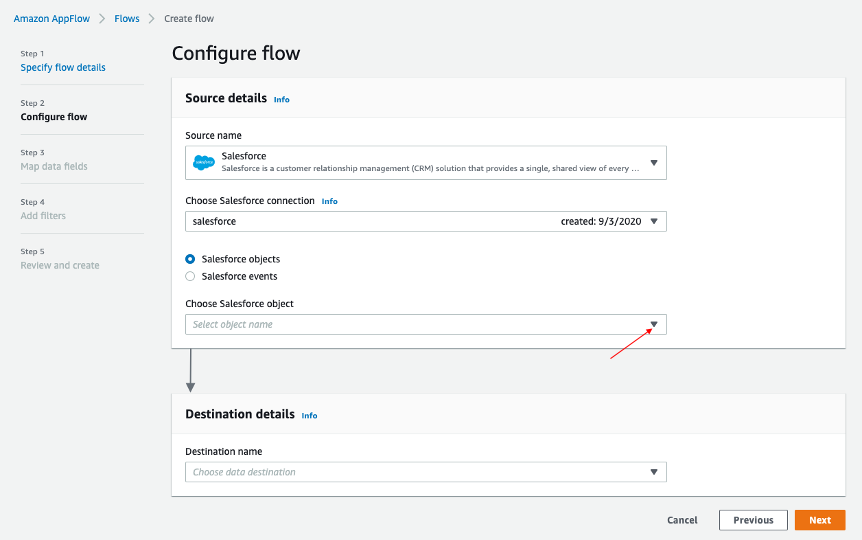
・AppFlowのConfigureフローウィンドウに戻り、Salesforceオブジェクトを使用し、SalesforceオブジェクトとしてAccountを選択します。
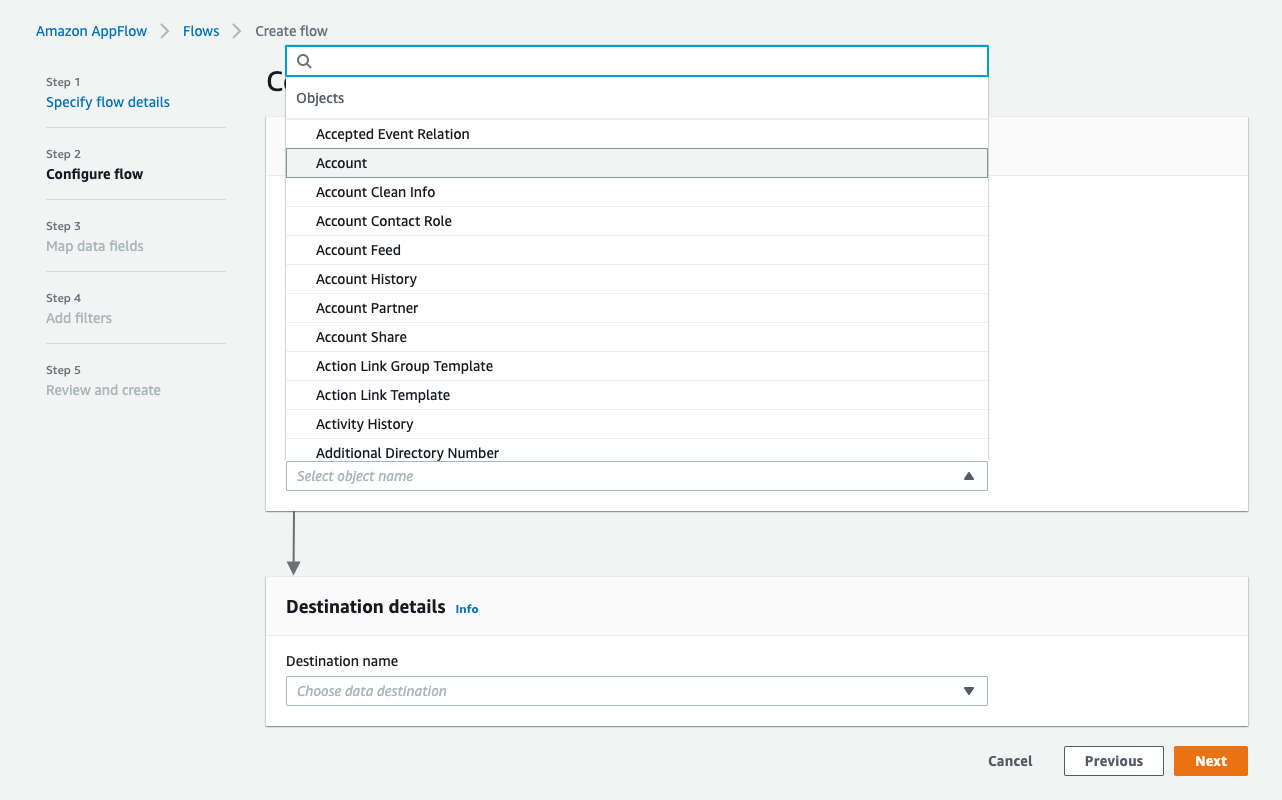
・Destination nameとしてAmazon S3を使用します。先ほど作成した、データを保存するバケットを選ぶ(例:ptctsoutput)
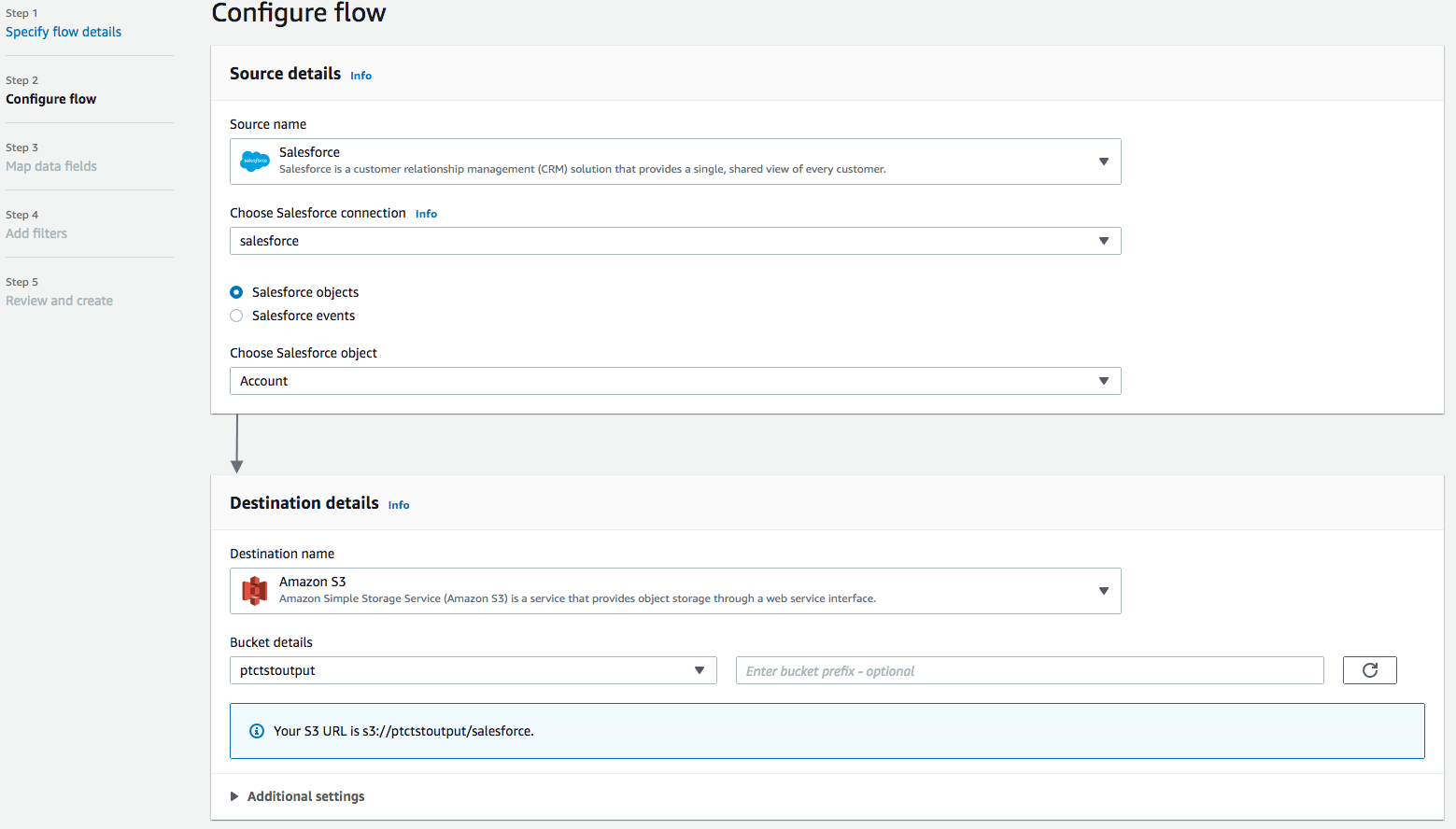
・フロートリガーを「オンデマンドで実行」にします。Nextをクリックします。
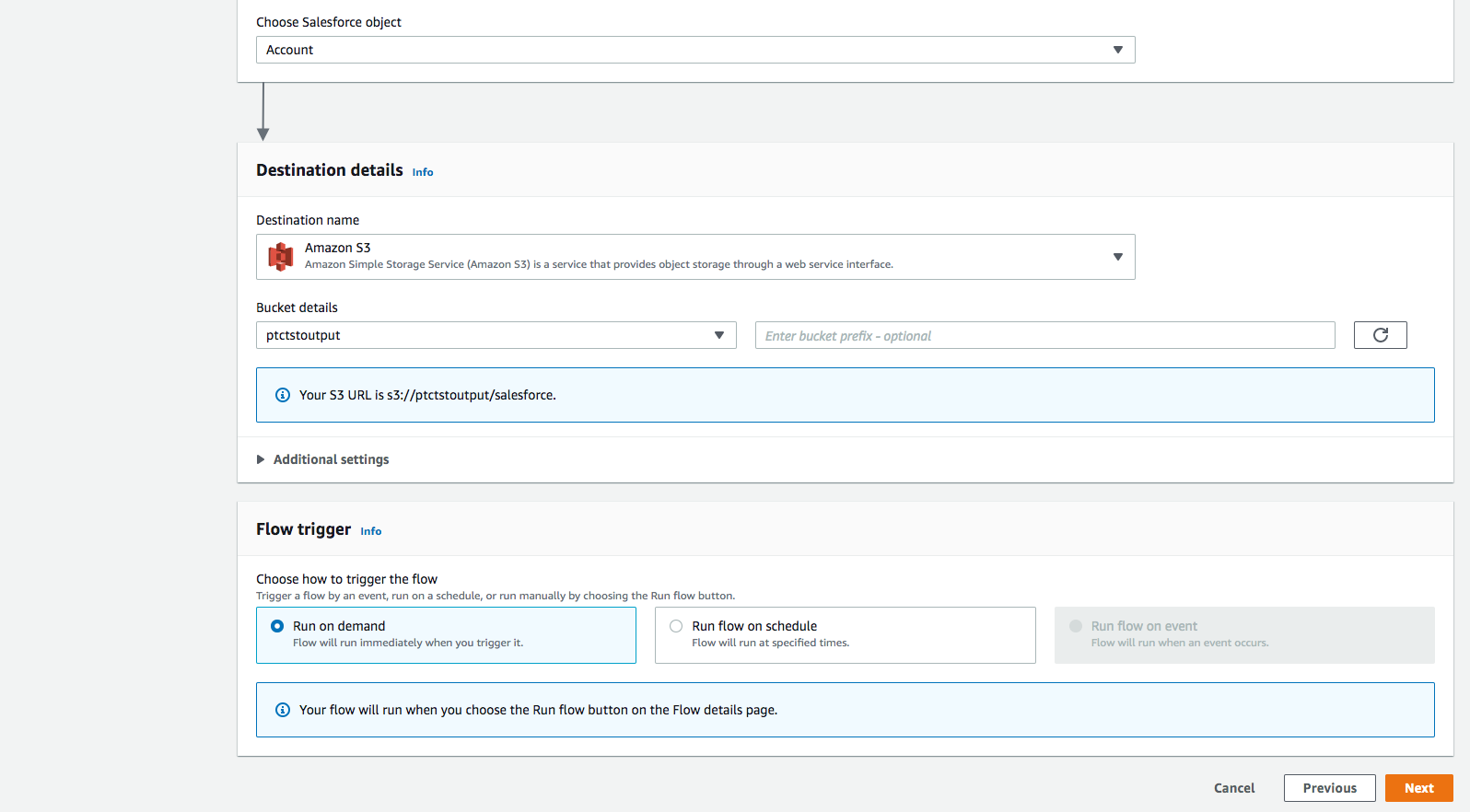
ステップ3:データフィールドのマッピング
このステップでは、データがソースからデスティネーションに転送される方法を決定します。
・マッピング方法として、手動でフィールドをマッピングするを使用する。
・簡単のため、送信元から送信先へのマッピングは、すべてのフィールドを直接マッピングするを選択します。
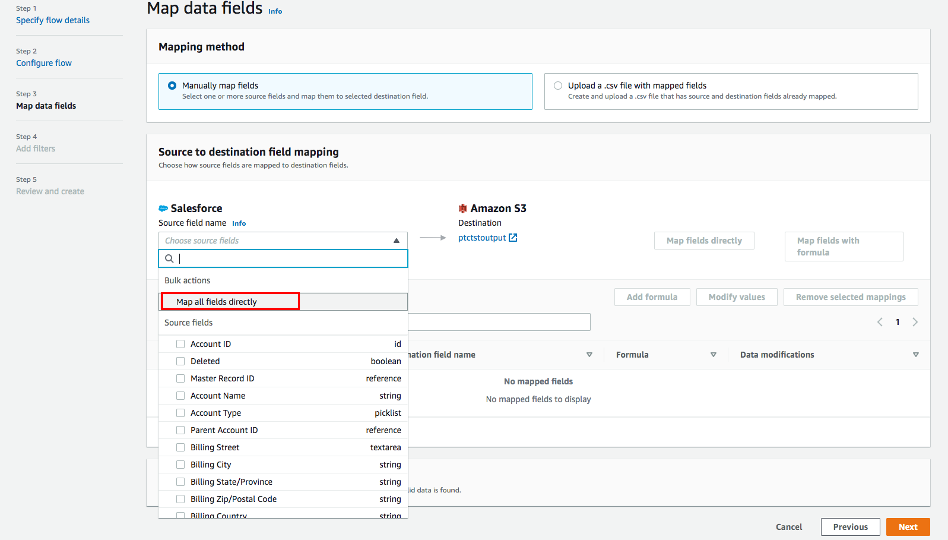
「すべてのフィールドを直接マッピングする」をクリックすると、すべてのフィールドが「マッピングされたフィールド」の下に表示されます。式の追加(連結)、値の修正(フィールド値のマスクまたは切り捨て)、選択したマッピングの削除を行いたいフィールドのチェックボックスをクリックします。
この例では、チェックボックスはチェックされません。
・バリデーションでは、「請求先住所」が含まれていないレコードを無視する条件を追加します(オプション)。**[次へ]**をクリックします。
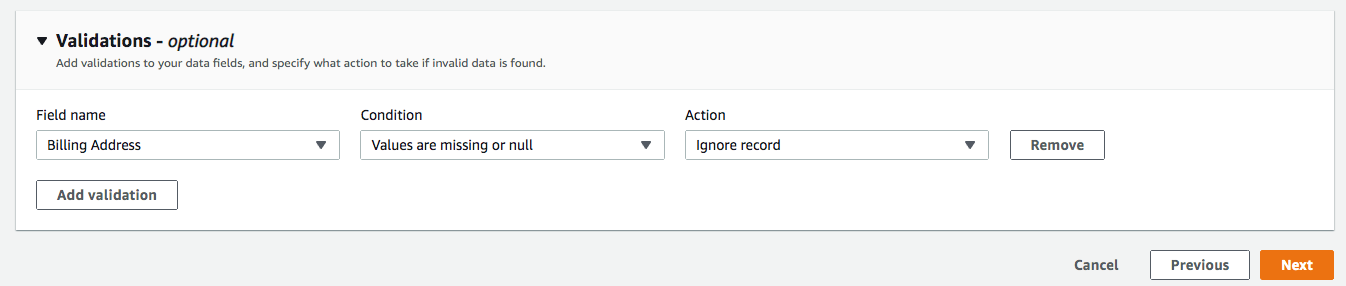
ステップ4:フィルタの追加
転送するレコードを決定するためのフィルタを指定することができます。この例では、削除されたレコードをフィルタリングする条件を追加します(オプション)。[次へ]をクリックします
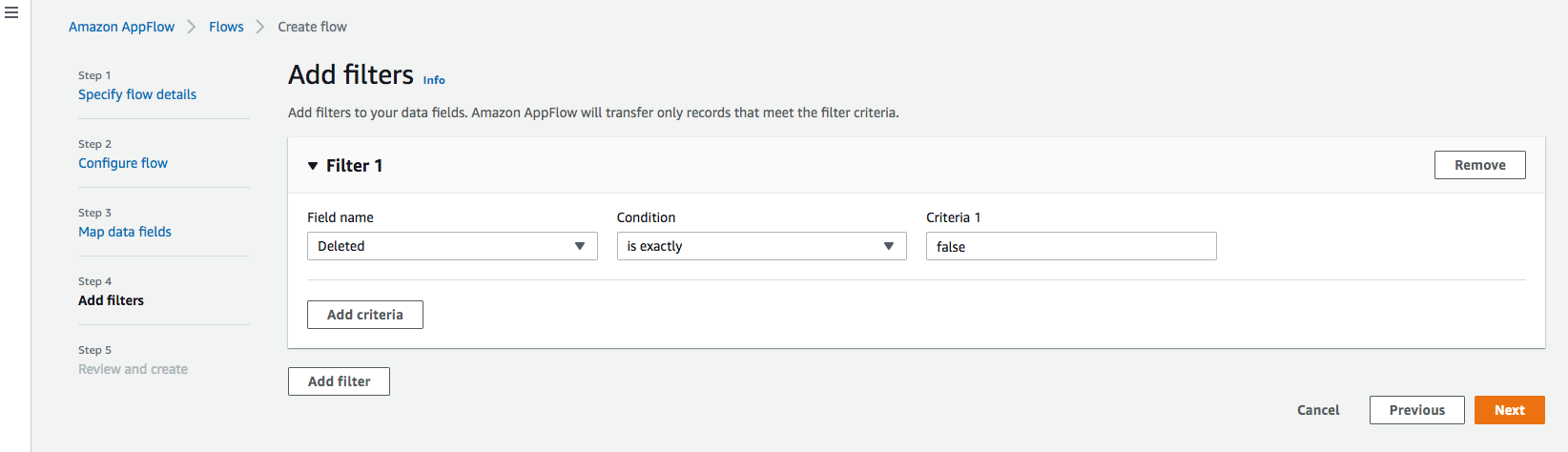
ステップ5. レビューと作成
入力した情報をすべて確認します。必要であれば修正します。[フローの作成]をクリックします。
フローが作成されると、フロー情報とともにフロー作成成功のメッセージが表示されます。
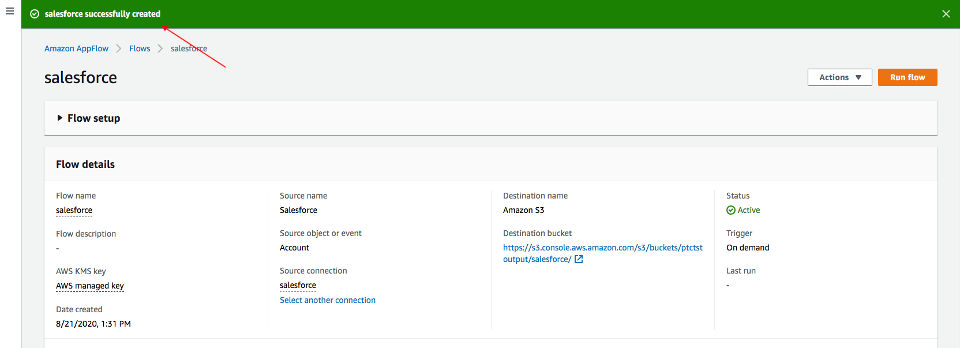
フローの実行
右上のRun flowをクリックします。
フローの実行が完了すると、実行が成功したことを示すメッセージが表示されます。
メッセージの例

バケツのリンクをクリックすると、データが表示されます。Salesforce のデータは JSON 形式になります。
データファイルのプロパティを変更する
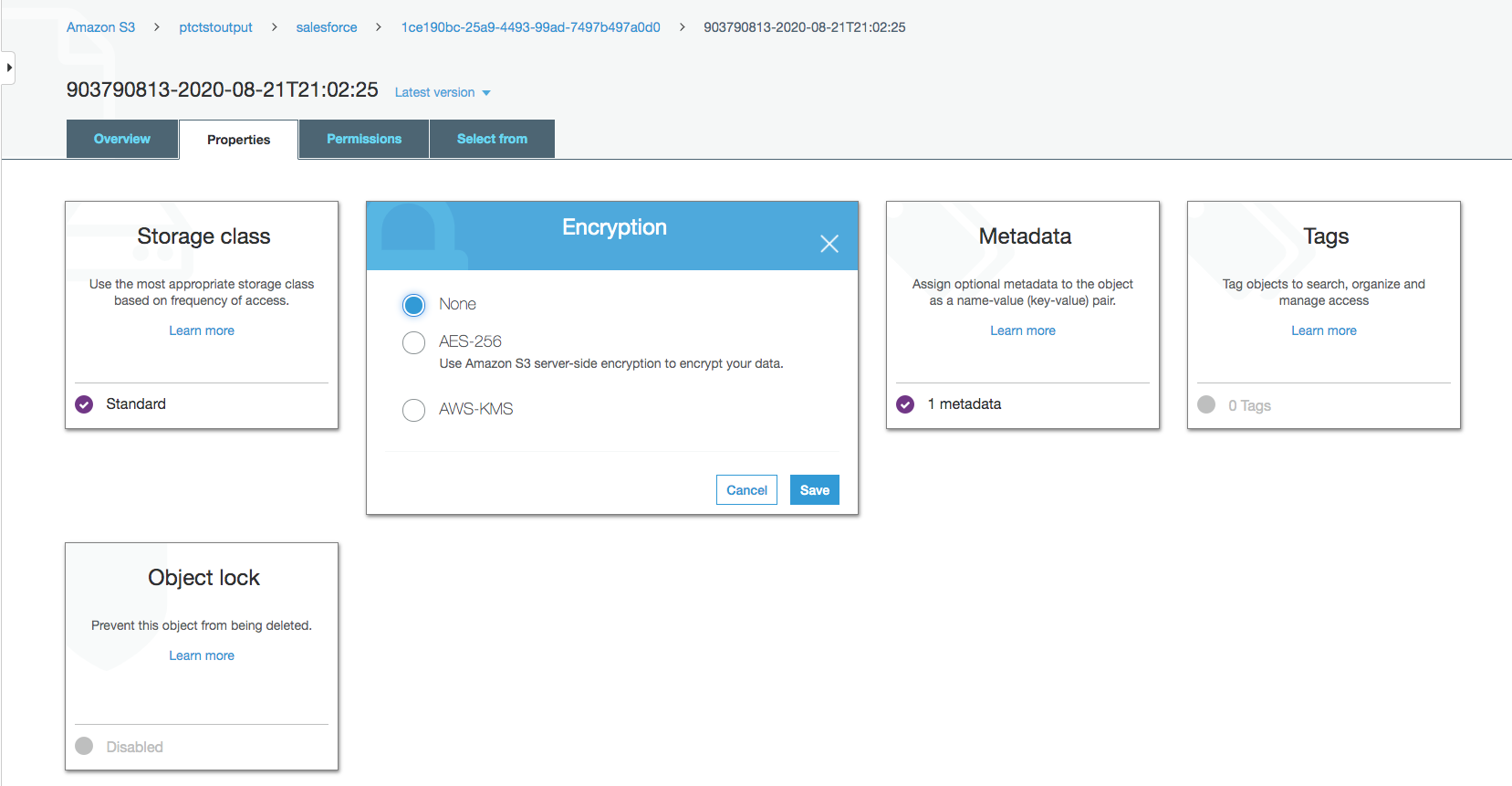
デフォルトでは、Salesforceのデータは暗号化されています。NOSがアクセスするためには、暗号化を解除する必要があります。
Amazon S3バケット内のデータファイルをクリックし、「プロパティ」タブをクリックします。
Encryption から AWS-KMS をクリックし、AWS-KMS encryption から None に変更します。[保存]をクリックします。
NOSを使ったデータの探索
Native Object Storeには、Amazon S3内のデータを探索・分析するための機能が組み込まれています。ここでは、NOSのよく使われる機能をいくつか列挙します。
外部テーブルの作成
外部テーブルを使用すると、Vantage Advanced SQL Engine 内で外部データを簡単に参照できるようになり、構造化されたリレーショナル形式でデータを利用できるようになります。
外部テーブルを作成するには、まず認証情報を使用してTeradata Vantageシステムにログインします。Amazon S3バケットにアクセスするためのアクセスキーを持つAUTHORIZATIONオブジェクトを作成します。Authorizationオブジェクトは、誰がAmazon S3データにアクセスするために外部テーブルの使用を許可されるかの制御を確立することで、セキュリティを強化します。
CREATE AUTHORIZATION DefAuth_S3
AS DEFINER TRUSTED
USER 'A*****************' /* AccessKeyId */
PASSWORD '********'; /* SecretAccessKey */
「USER "はAWSアカウントのAccessKeyId、"PASSWORD "はSecretAccessKeyです。
Amazon S3上のJSONファイルに対して、以下のコマンドで外部テーブルを作成します。
CREATE MULTISET FOREIGN TABLE salesforce,
EXTERNAL SECURITY DEFINER TRUSTED DefAuth_S3
(
Location VARCHAR(2048) CHARACTER SET UNICODE CASESPECIFIC,
Payload JSON(8388096) INLINE LENGTH 32000 CHARACTER SET UNICODE
)
USING
(
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/salesforce/1ce190bc-25a9-4493-99ad-7497b497a0d0/903790813-2020-08-21T21:02:25')
);
最低限、外部テーブルの定義には、テーブル名と、オブジェクトストアのデータを指すLocation句(黄色でハイライトされています)を含める必要があります。ロケーションは、Amazonでは "バケット "と呼ばれるトップレベルの単一名が必要です。
ファイル名の末尾に標準的な拡張子(.json, .csv, .parquet)がない場合、データファイルの種類を示すために、LocationとPayload列の定義も必要です(ターコイズ色でハイライトされている)。
外部テーブルは常にNo Primary Index (NoPI)テーブルとして定義される。
外部テーブルが作成されると、外部テーブル上で "Select "を実行することにより、Amazon S3データセットの内容を照会することができます。
SELECT * FROM salesforce;
SELECT payload.* FROM salesforce;
外部テーブルには、2つのカラムしか含まれていません。LocationとPayloadです。Locationは、オブジェクトストアシステム内のアドレスです。データ自体はpayloadカラムで表され、外部テーブルの各レコード内のpayload値は、単一のJSONオブジェクトとそのすべての名前-値ペアを表します。
SELECT * FROM salesforce;」からの出力例。
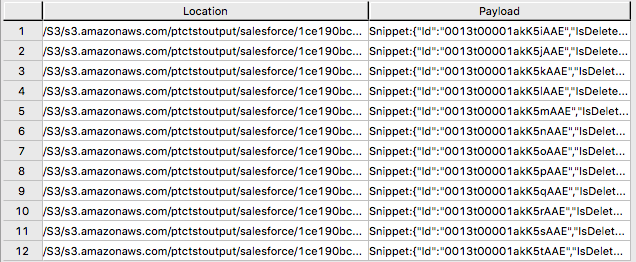
サンプル出力形式「SELECT payload.* FROM salesforce;」。

JSON_KEYS テーブル演算子
JSONデータには、レコードごとに異なる属性が含まれることがあります。データストアに含まれる可能性のある属性の完全なリストを決定するには、JSON_KEYSを使用します。
|SELECT DISTINCT * FROM JSON_KEYS (ON (SELECT payload FROM salesforce)) AS j;
このSQLの結果はとても大きいので一部のみの結果を示します。

ビューの作成
ビューは、ペイロード属性に関連する名前を単純化し、オブジェクトストアのデータに対して実行可能なSQLを簡単にコーディングできるようにし、外部テーブルのLocation参照を隠して通常の列のように見えるようにすることができます。
以下は、上記の JSON_KEYS テーブル演算子から検出された属性を使用したビュー作成文のサンプルです。
REPLACE VIEW salesforceView AS (
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS VARCHAR(10)) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.LastActivityDate AS VARCHAR(50)) Last_Activity_Date
FROM salesforce
);
SELECT * FROM salesforceView;
部分的に出力

READ_NOSテーブル演算子
READ_NOSテーブル演算子は、最初に外部テーブルを定義せずにデータの一部をサンプリングして調査したり、Location句で指定したすべてのオブジェクトに関連するキーのリストを表示するために使用できます。
SELECT top 5 payload.*
FROM READ_NOS (
ON (SELECT CAST(NULL AS JSON CHARACTER SET Unicode))
USING
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/salesforce/1ce190bc-25a9-4493-99ad-7497b497a0d0/903790813-2020-08-21T21:02:25')
ACCESS_ID ('A**********') /* AccessKeyId */
ACCESS_KEY ('***********') /* SecretAccessKey */
) AS D
GROUP BY 1;
出力します

Amazon S3 データとデータベース内テーブルの結合
外部テーブルを Vantage 内のテーブルと結合して、さらに分析することができます。例えば、注文と配送の情報は、VantageのOrders、Order_Items、Shipping_Addressの3つのテーブルに格納されています。
Orders の DDL
CREATE TABLE Orders (
Order_ID INT NOT NULL,
Customer_ID VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC,
Order_Status INT,
-- Order status: 1 = Pending; 2 = Processing; 3 = Rejected; 4 = Completed
Order_Date DATE NOT NULL,
Required_Date DATE NOT NULL,
Shipped_Date DATE,
Store_ID INT NOT NULL,
Staff_ID INT NOT NULL
) Primary Index (Order_ID);
Order_ItemsのDDL
CREATE TABLE Order_Items(
Order_ID INT NOT NULL,
Item_ID INT,
Product_ID INT NOT NULL,
Quantity INT NOT NULL,
List_Price DECIMAL (10, 2) NOT NULL,
Discount DECIMAL (4, 2) NOT NULL DEFAULT 0
) Primary Index (Order_ID, Item_ID);
Shipping_AddressのDDLです。
CREATE TABLE Shipping_Address (
Customer_ID VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC NOT NULL,
Street VARCHAR(100) CHARACTER SET LATIN CASESPECIFIC,
City VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC,
State VARCHAR(15) CHARACTER SET LATIN CASESPECIFIC,
Postal_Code VARCHAR(10) CHARACTER SET LATIN CASESPECIFIC,
Country VARCHAR(20) CHARACTER SET LATIN CASESPECIFIC
) Primary Index (Customer_ID);
また、テーブルには以下のデータがあります。
オーダー

オーダー_アイテム

Shipping_Address

データベースのOrders, Order_Items, Shipping_Address テーブルにsalesforceの外部テーブルを結合することで、顧客の注文情報を顧客の配送情報とともに取得することができます。
SELECT
s.payload.Id as Customer_ID,
s.payload."Name" as Customer_Name,
s.payload.AccountNumber as Acct_Number,
o.Order_ID as Order_ID,
o.Order_Status as Order_Status,
o.Order_Date as Order_Date,
oi.Item_ID as Item_ID,
oi.Product_ID as Product_ID,
sa.Street as Shipping_Street,
sa.City as Shipping_City,
sa.State as Shipping_State,
sa.Postal_Code as Shipping_Postal_Code,
sa.Country as Shipping_Country
FROM
salesforce s, Orders o, Order_Items oi, Shipping_Address sa
WHERE
s.payload.Id = o.Customer_ID
AND o.Customer_ID = sa.Customer_ID
AND o.Order_ID = oi.Order_ID
ORDER BY 1;
結果

Amazon S3 データを Vantage にインポートする
Amazon S3データの永続的なコピーを持つことは、同じデータへの反復的なアクセスが予想される場合に便利です。NOSの外部テーブルでは、自動的にAmazon S3データの永続的なコピーを作成しません。データベースにデータを取り込むためのいくつかのアプローチについて、以下に説明します。
CREATE TABLE AS ... WITH DATA "ステートメントは、ソーステーブルとして機能する外部テーブル定義で使用することができます。このアプローチでは、外部テーブルのペイロードのうち、ターゲットテーブルに含めたい属性と、リレーショナルテーブルのカラムの名前を選択的に選択することができます。
CREATE TABLE salesforceVantage AS (
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS INT) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload.LastActivityDate AS DATE) Last_Activity_Date
FROM salesforce)
WITH DATA
NO PRIMARY INDEX;
・ SELECT * * FROM salesforceVantage ; 部分的な結果。

外部テーブルを使用する代わりに、READ_NOS テーブル演算子を使用することができます。このテーブル演算子により、最初に外部テーブルを構築することなく、オブジェクトストアから直接データにアクセスすることができます。READ_NOSをCREATE TABLE AS句と組み合わせて、データベース内にデータの永続的なバージョンを構築することができます。
CREATE TABLE salesforceReadNOS AS (
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS INT) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload.LastActivityDate AS DATE) Last_Activity_Date
FROM READ_NOS (
ON (SELECT CAST(NULL AS JSON CHARACTER SET Unicode))
USING
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/salesforce/1ce190bc-25a9-4493-99ad-7497b497a0d0/903790813-2020-08-21T21:02:25')
ACCESS_ID ('A**********') /* AccessKeyId */
ACCESS_KEY ('***********') /* SecretAccessKey */
) AS D
) WITH DATA;
salesforceReadNOSテーブルの結果
SELECT * FROM salesforceReadNOS;

Amazon S3データをリレーショナルテーブルに配置するもう一つの方法は、"INSERT SELECT "です。このアプローチでは、外部テーブルがソーステーブルであり、新しく作成されたパーマネントテーブルが挿入されるテーブルとなります。上記のREAD_NOSの例とは逆に、この方法ではパーマネントテーブルを事前に作成する必要があります。
INSERT SELECT方式の利点の1つは、ターゲット・テーブルの属性を変更できることです。例えば、ターゲットテーブルをMULTISETにするかしないかを指定したり、別のプライマリインデックスを選択したりすることができます。
CREATE TABLE salesforcePerm, FALLBACK ,
NO BEFORE JOURNAL,
NO AFTER JOURNAL,
CHECKSUM = DEFAULT,
DEFAULT MERGEBLOCKRATIO,
MAP = TD_MAP1
(
Customer_Id VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Customer_Name VARCHAR(100) CHARACTER SET LATIN NOT CASESPECIFIC,
Acct_Number VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_Street VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_City VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_State VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_Post_Code VARCHAR(5) CHARACTER SET LATIN NOT CASESPECIFIC,
Billing_Country VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Phone VARCHAR(15) CHARACTER SET LATIN NOT CASESPECIFIC,
Fax VARCHAR(15) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_Street VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_City VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_State VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_Post_Code VARCHAR(5) CHARACTER SET LATIN NOT CASESPECIFIC,
Shipping_Country VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Industry VARCHAR(50) CHARACTER SET LATIN NOT CASESPECIFIC,
Description VARCHAR(200) CHARACTER SET LATIN NOT CASESPECIFIC,
Num_Of_Employee INT,
Priority VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Rating VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
SLA VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Customer_Type VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Customer_Website VARCHAR(100) CHARACTER SET LATIN NOT CASESPECIFIC,
Annual_Revenue VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Last_Activity_Date DATE
) PRIMARY INDEX (Customer_ID);
INSERT INTO salesforcePerm
SELECT
CAST(payload.Id AS VARCHAR(20)) Customer_ID,
CAST(payload."Name" AS VARCHAR(100)) Customer_Name,
CAST(payload.AccountNumber AS VARCHAR(10)) Acct_Number,
CAST(payload.BillingStreet AS VARCHAR(20)) Billing_Street,
CAST(payload.BillingCity AS VARCHAR(20)) Billing_City,
CAST(payload.BillingState AS VARCHAR(10)) Billing_State,
CAST(payload.BillingPostalCode AS VARCHAR(5)) Billing_Post_Code,
CAST(payload.BillingCountry AS VARCHAR(20)) Billing_Country,
CAST(payload.Phone AS VARCHAR(15)) Phone,
CAST(payload.Fax AS VARCHAR(15)) Fax,
CAST(payload.ShippingStreet AS VARCHAR(20)) Shipping_Street,
CAST(payload.ShippingCity AS VARCHAR(20)) Shipping_City,
CAST(payload.ShippingState AS VARCHAR(10)) Shipping_State,
CAST(payload.ShippingPostalCode AS VARCHAR(5)) Shipping_Post_Code,
CAST(payload.ShippingCountry AS VARCHAR(20)) Shipping_Country,
CAST(payload.Industry AS VARCHAR(50)) Industry,
CAST(payload.Description AS VARCHAR(200)) Description,
CAST(payload.NumberOfEmployees AS INT) Num_Of_Employee,
CAST(payload.CustomerPriority__c AS VARCHAR(10)) Priority,
CAST(payload.Rating AS VARCHAR(10)) Rating,
CAST(payload.SLA__c AS VARCHAR(10)) SLA,
CAST(payload."Type" AS VARCHAR(20)) Customer_Type,
CAST(payload.Website AS VARCHAR(100)) Customer_Website,
CAST(payload.AnnualRevenue AS VARCHAR(10)) Annual_Revenue,
CAST(payload.LastActivityDate AS DATE) Last_Activity_Date
FROM salesforce;
SELECT * FROM salesforcePerm;
サンプル結果です。

NOS を使用して Vantage データを Amazon S3 にエクスポートする
Vantageシステムで1行のnewleadsテーブルを持っています。

このリードには住所情報がないことに注意してください。Salesforceから取得したアカウント情報を使って、newleadsテーブルを更新してみましょう。
UPDATE nl
FROM
newleads AS nl,
salesforceReadNOS AS srn
SET
Street = srn.Billing_Street,
City = srn.Billing_City,
State = srn.Billing_State,
Post_Code = srn.Billing_Post_Code,
Country = srn.Billing_Country
WHERE Account_ID = srn.Acct_Number;
これで、新しいリードにアドレス情報が付与されました。

WRITE_NOSを使用して、新しいリード情報をS3バケットに書き込む。
SELECT * FROM WRITE_NOS (
ON (
SELECT
Account_ID,
Last_Name,
First_Name,
Company,
Cust_Title,
Email,
Status,
Owner_ID,
Street,
City,
State,
Post_Code,
Country
FROM newleads
)
USING
LOCATION ('/s3/vantageparquet.s3.amazonaws.com/')
AUTHORIZATION ('{"Access_ID":"A*****","Access_Key":"*****"}')
COMPRESSION ('SNAPPY')
NAMING ('DISCRETE')
INCLUDE_ORDERING ('FALSE')
STOREDAS ('CSV')
) AS d;
Access_IDはAccessKeyID、Access_KeyはBucketに対するSecretAccessKeyです。
Amazon S3からSalesforceへのフローを作成する
ステップ1を繰り返し、ソースにAmazon S3、デスティネーションにSalesforceを使用したフローを作成します。
ステップ1. フローの詳細を指定する
このステップでは、フローの基本情報を提供します。
フロー名(例:vantage2sf)およびフローの説明(オプション) を入力し、暗号化設定のカスタマイズ(詳細) のチェックは外したままにします。[次へ]をクリックします。
ステップ2. フローを構成する
このステップでは、フローの送信元と送信先に関する情報を提供します。この例では、ソースとしてAmazon S3を使用し、デスティネーションとしてSalesforceを使用する予定です。
・Sourceの詳細は、Amazon S3を選択し、CSVファイルを書き込んだバケットを選択します(例:vantagecsv)。
・Destinationの詳細は、Salesforceを選択し、Choose Salesforce connectionのドロップダウンリストでStep1で作成した接続を使用し、LeadはChoose Salesforce objectを選択します。
・エラー処理には、デフォルトの[Stop the current flow run]を使用します。
・フロートリガーはRun on demandです。[Next]をクリックします。
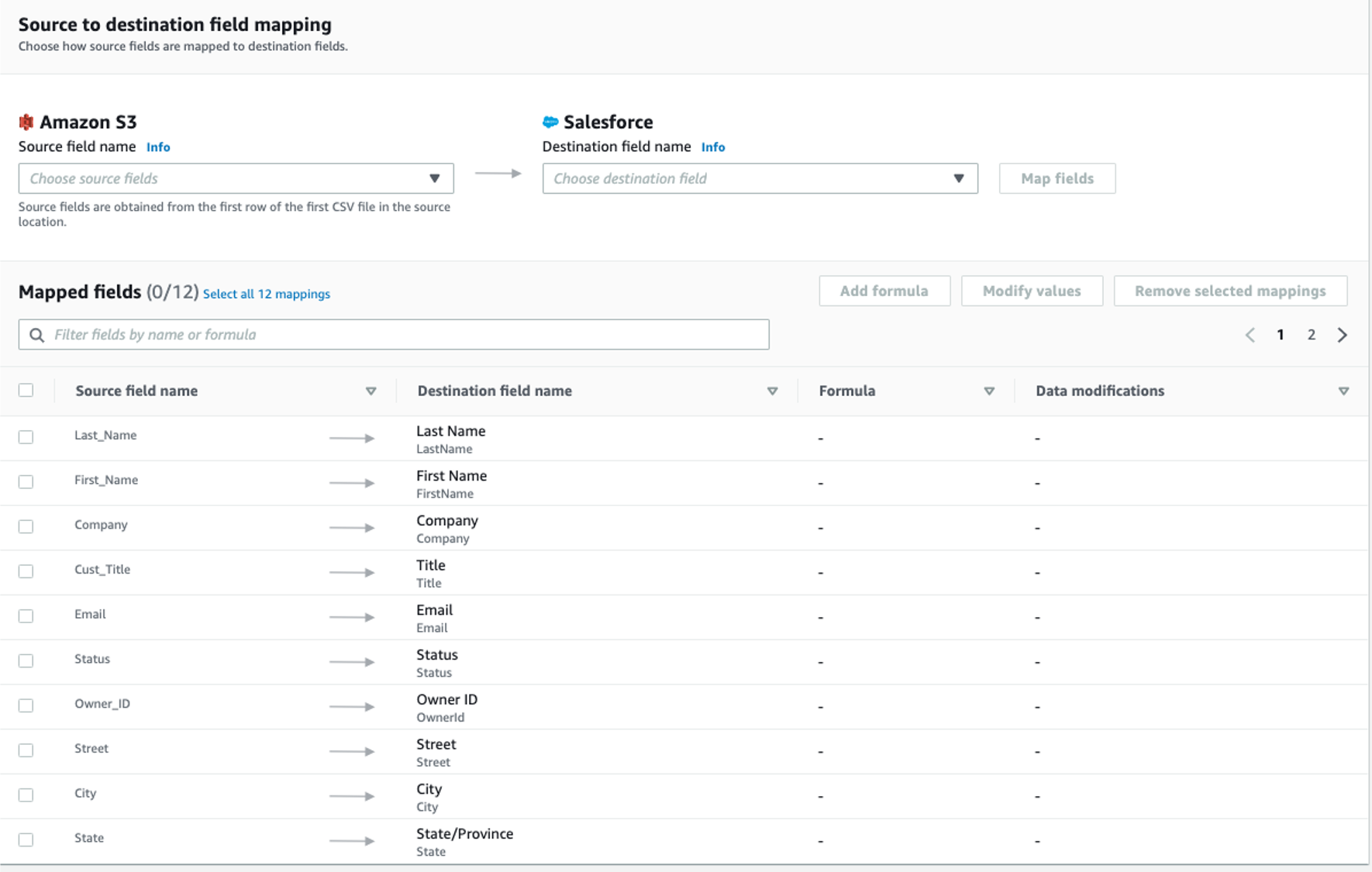
ステップ3. データフィールドをマッピングする
このステップでは、ソースからデスティネーションへのデータ転送の方法を決定します。
・マッピング方法として、手動でフィールドをマッピングするを使用する
・宛先レコードの優先順位として[新しいレコードを挿入する](デフォルト)を使用します。
・送信元と送信先のマッピングには、次のマッピングを使用します。
・[次へ」をクリックします。
ステップ4.フィルターを追加する
転送するレコードを決定するためのフィルタを指定することができます。この例では、フィルターは追加されません。[次へ」をクリックします。
ステップ5. レビューと作成
今入力したすべての情報を確認します。必要であれば修正します。[フローの作成]をクリックします。
フローが作成されると、フロー情報とともにフロー作成成功のメッセージが表示されます。
フローの実行
右上の[フローの実行]をクリックします。
フローの実行が完了すると、実行に成功したことを示すメッセージが表示されます。
メッセージの例

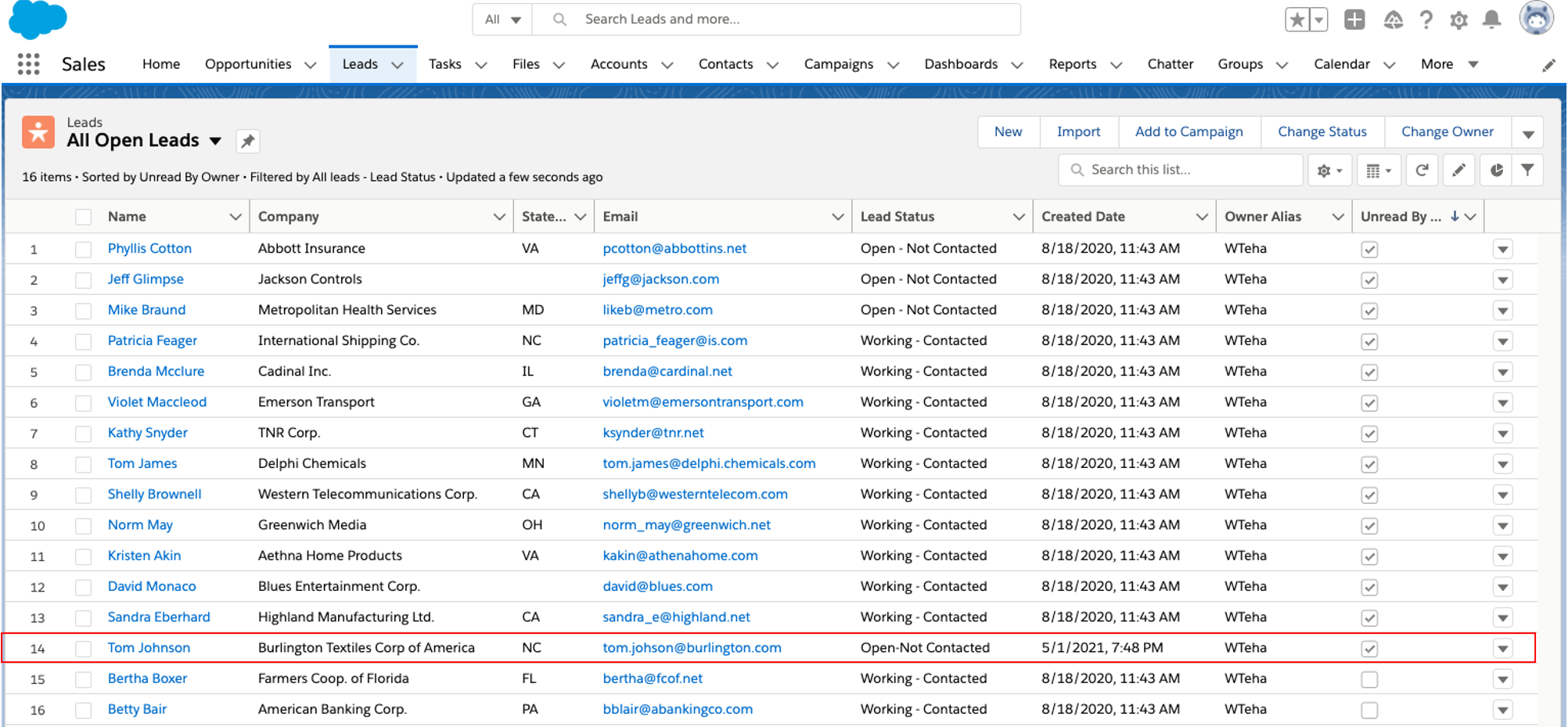
Salesforceのページを参照すると、新しいリードTom Johnsonが追加されています。
クリーンアップ (オプション)
Salesforceのデータ処理が完了したら、使用したリソースがAWSアカウント(AppFlow、Amazon S3、Vantage、VMなど)に請求されないように、以下の手順を実行します。
① AppFlowです。
○フローに作成した「コネクション」を削除する。
○フローを削除する。
② Amazon S3バケットとファイル
○Vantage データファイルが保存されている Amazon S3 バケットに移動し、ファイルを削除します。
○バケットを保持する必要がない場合は、バケットを削除します。
③ Teradata Vantageインスタンス
○不要になったインスタンスを停止/終了します。