著者 Rupal Shah
最終更新日 2022年2月14日
警告
本記事はTeradata CorporationのサイトGetting Startedに掲載された内容を抄訳したものです。掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。正確な内容については、原本をご参照下さい。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
概要
Azure Machine Learning (ML) Studioは、データに対する予測分析ソリューションの構築、テスト、およびデプロイに使用できる、ドラッグ&ドロップ可能なコラボレーションツールです。ML Studioは、Azure Blob Storageからデータを取得することができます。このスタートガイドでは、ML Studio に組み込まれた Jupter Notebook 機能を使用して Teradata Vantage データセットを Blob Storage にコピーする方法を説明します。このデータは、ML Studio で機械学習モデルを構築、学習し、本番環境にデプロイするために使用することができます。

前提条件
・Teradata Vantageインスタンスにアクセスできること。
メモ!
Vantageの新しいインスタンスが必要な場合は、Google Cloud、Azure、AWSのクラウドにVantage Expressという無料版をインストールすることができます。また、VMware、VirtualBox、またはUTMを使用して、ローカルマシン上でVantage Expressを実行することもできます。
・Azureサブスクリプションまたは無料アカウント作成
・Azure ML Studioワークスペース
・(オプション)AdventureWorks DW 2016データベースのダウンロード(「モデルのトレーニング」セクションなど)
○「vTargetMail」テーブルをSQL ServerからTeradata Vantageにリストアおよびコピーします。
手順
初期設定
・ML Studioのワークスペースを作成する際に、ストレージアカウントを新規に作成する必要があります。ただし、現在利用可能なロケーションにストレージアカウントが存在し、このスタートガイドでWebサービスプランのDEVTEST Standardを選択した場合は、この限りではありません。Azureポータルにログオンし、ストレージアカウントを開き、コンテナが存在しない場合は、コンテナを作成します。

・ストレージのアカウント名とキーをメモ帳にコピーし、Python3 NotebookでAzure Blob Storageアカウントにアクセスするために使用します。

・最後に、Configuration プロパティを開き、'Secure transfer required' を Disabled に設定し、ML Studio Import Data モジュールが blob ストレージアカウントにアクセスできるようにします。

データのロード
ML Studioにデータを取り込むために、まずはTeradata VantageからAzure Blob Storageにデータをロードする必要があります。ML Jupyter Notebookを作成し、Teradataに接続するためのPythonパッケージをインストールし、Azure Blob Storageにデータを保存することにします。
Azureポータルにログインし、ML Studioワークスペースに移動して、Machine Learning Studioを起動してサインインします。
① 以下の画面が表示されるので、Notebooksをクリックし、正しいリージョン/ワークスペースにいることを確認し、Notebook Newをクリックします。

② Python3を選択し、ノートブックのインスタンスに名前を付けます。
③ jupyter notebookインスタンスに、Teradata Vantage Python package for Advanced Analyticsをインストールします。
pip install teradataml
メモ!
Microsoft Azure ML StudioとTeradata Vantage Pythonパッケージの間の検証は行われていません。
④ Microsoft Azure Storage Blob Client Library for Pythonをインストールします。
!pip install azure-storage-blob
⑤ 以下のライブラリをインポートしてください。
import teradataml as tdml
from teradataml import create_context, get_context, remove_context
from teradataml.dataframe.dataframe import DataFrame
import pandas as pd
from azure.storage.blob import (BlockBlobService)
⑥ コマンドを使用してTeradataに接続します。
create_context(host = '<hostname>', username = '<database user name>', password = '<password>')
⑦ Teradata Python DataFrameモジュールを使用してデータを取得する。
train_data = DataFrame.from_table("<table_name>")
⑧ Teradata DataFrameをPanda DataFrameに変換します。
trainDF = train_data.to_pandas()
⑨ データをCSVに変換する。
trainDF = trainDF.to_csv(head=True,index=False)
⑩ Azue Blob Storageのアカウント名、キー、コンテナ名に変数を割り当てる。
accountName="<account_name>"
accountKey="<account_key>"
containerName="mldata"
⑪ Azure Blob Storageにファイルをアップロードします。
blobService = BlockBlobService(account_name=accountName, account_key=accountKey)
blobService.create_blob_from_text(containerNAme, 'vTargetMail.csv', trainDF)
⑫ Azureポータルにログインし、BLOBストレージアカウントを開いてアップロードされたファイルを確認します。

モデルの学習
既存のAnalyze data with Azure Machine Learningの記事を使って、Azure Blob Storageのデータに基づいて予測型機械学習モデルを構築します。顧客が自転車を購入する可能性があるかどうかを予測することで、自転車店であるアドベンチャーワークスのためのターゲットマーケティングキャンペーンを構築する予定です。
データのインポート
データは、上のセクションでコピーした vTargetMail.csv という Azure Blob Storage ファイルにあります。
1.. Azure Machine Learning studioにサインインし、Experimentsをクリックします。2.. 画面左下の「+NEW」をクリックし、「Blank Experiment」を選択します。3.. 実験の名前を入力します。Targeted Marketing」と入力します。4.. モジュールペインの Data Input and output の下にある Import data module をキャンバスにドラッグする。5.. Properties] ペインで、Azure Blob Storage の詳細 (アカウント名、キー、コンテナ名) を指定します。
experiment キャンバスの下にある Run をクリックして、実験を実行します。
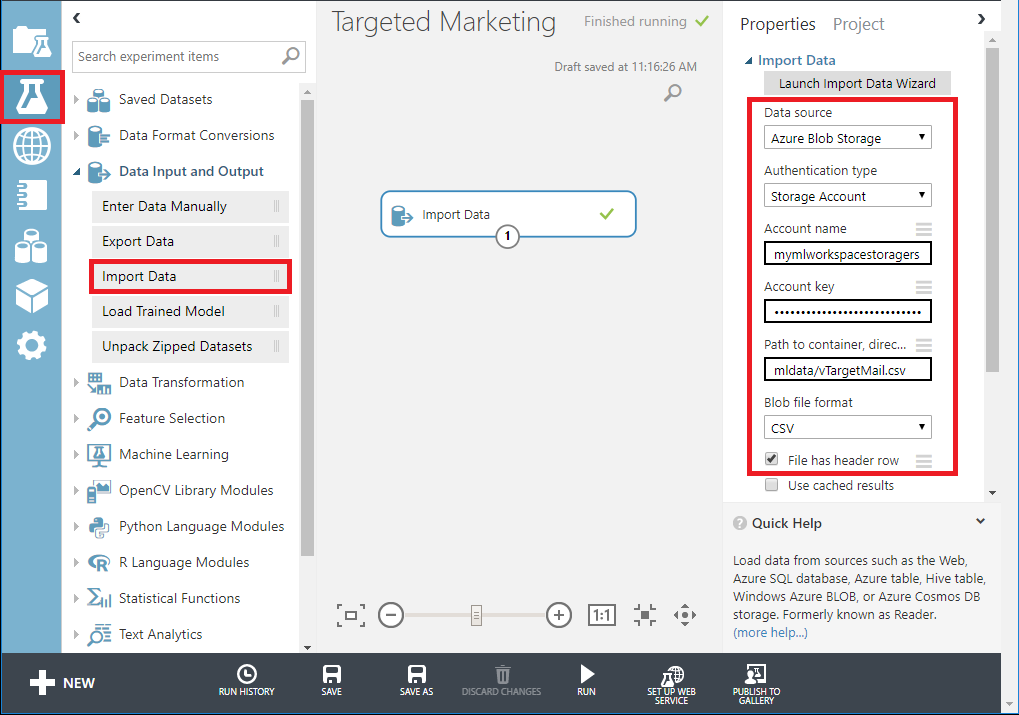
実験が正常に終了したら、Import Data モジュールの下部にある出力ポートをクリックし、Visualize を選択してインポートしたデータを確認します。

データのクリーンアップ
データをきれいにするには、モデルに関係のない列をいくつか削除する。これを行うには
① Data Transformation < Manipulation の下にある Select Columns in Dataset モジュールをキャンバスにドラッグします。このモジュールをImport Dataモジュールに接続します。
② プロパティペインのLaunch column selectorをクリックし、ドロップする列を指定します。

③ 2つのカラムを除外する。CustomerAlternateKey と GeographyKey の 2 つのカラムを除外します。

モデルの構築
80%は機械学習モデルの学習用、20%はモデルのテスト用としてデータを80対20に分割する。この2値分類問題には、「2クラス」アルゴリズムを使用します。
① SplitDataモジュールをキャンバスにドラッグし、「Select Columns in DataSet」で接続します。
② プロパティペインで、「Fraction of rows in the first output dataset」に「0.8」を入力します。

③ Two-Class Boosted Decision Treeモジュールを検索し、キャンバスにドラッグします。
④ Train Modelモジュールを検索してキャンバスにドラッグし、Two-Class Boosted Decision Tree(MLアルゴリズム)モジュールとSplit Data(アルゴリズムを学習させるデータ)モジュールに接続して入力を指定します。

⑤ 次に、[プロパティ] ペインで [列セレクタを起動] をクリックします。予測する列として、BikeBuyer 列を選択します。

モデルを評価する
次に、このモデルがテストデータでどのように動作するかをテストします。選択したアルゴリズムと異なるアルゴリズムを比較し、どちらがより良いパフォーマンスを示すかを確認します。
① Score Model モジュールをキャンバスにドラッグし、Train Model および Split Data モジュールに接続します。
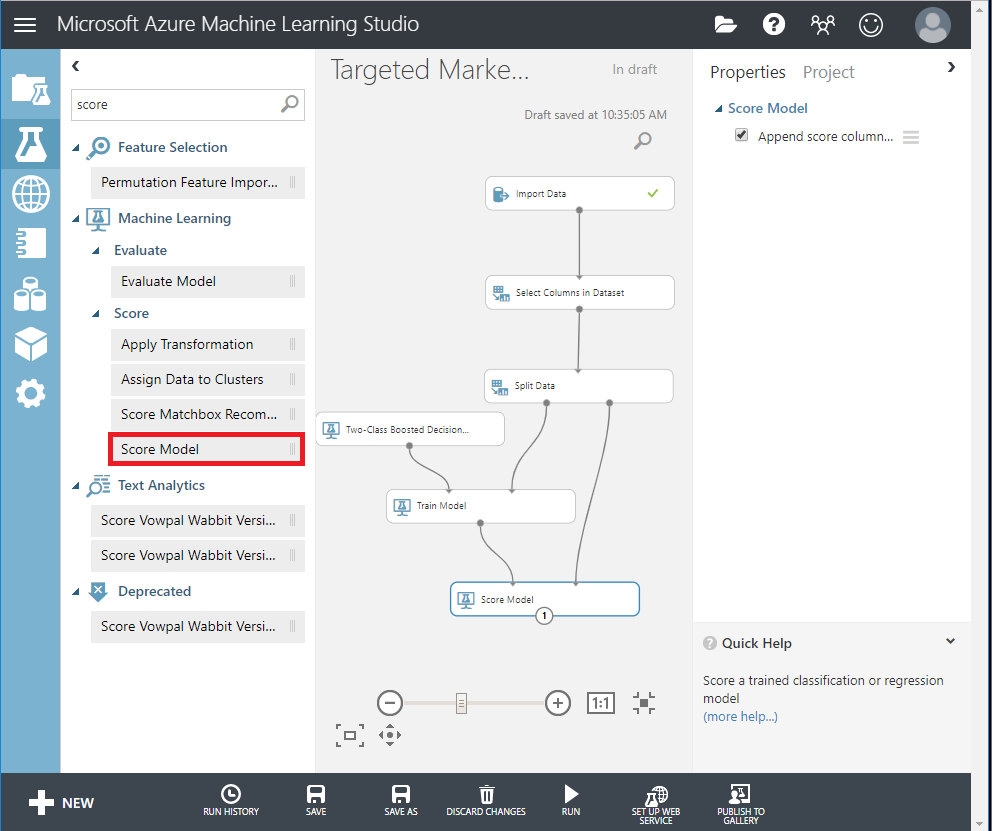
② Two-Class Bayes Point Machineを検索し、実験キャンバスにドラッグします。このアルゴリズムが、Two-Class Boosted Decision Treeと比較して、どのようなパフォーマンスを示すかを比較します。
③ Train Model と Score Model モジュールをコピーして、キャンバスに貼り付けます。
④ Evaluate Model モジュールを検索して、キャンバスにドラッグし、2つのアルゴリズムを比較します。
⑤ 実験を実行します。

⑥ Evaluate Model モジュールの下部にある出力ポートをクリックし、Visualize をクリックします。

提供される指標は、ROC曲線、精度-再現性ダイアグラム、リフトカーブである。これらの指標を見ると、最初のモデルが2番目のモデルよりも良い性能を発揮していることがわかります。最初のモデルが何を予測したかを見るには、スコア・モデルの出力ポートをクリックし、可視化をクリックします。

テストデータセットに2つのカラムが追加されているのがわかります。1. スコアリングされた確率:顧客がバイクの購入者である可能性。2. 2. スコアされたラベル:モデルによって行われた分類 - 自転車の購入者(1)またはそうでない(0)。このラベリングのための確率の閾値は50%に設定されており、調整することが可能です。
BikeBuyer列(実際)とScored Labels列(予測)を比較すると、モデルがどの程度うまく機能したかが分かります。次のステップとして、このモデルを使用して新規顧客の予測を行い、このモデルをWebサービスとして公開したり、SQL Data Warehouseに結果を書き戻したりすることが可能です。
さらに詳しく
・予測型機械学習モデルの構築の詳細については、Introduction to Machine Learning on Azureを参照してください。
・大規模なデータセットのコピーには、Teradata Parallel Transporterのロード/アンロード・オペレーターとAzure Blob Storageの間のインターフェイスであるTeradata Access Module for Azureの利用を検討してください。