著者 Adam Tworkiewicz
最終更新日 2021年9月12日
警告
本記事はTeradata CorporationのサイトGetting Startedに掲載された内容を抄訳したものです。掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。正確な内容については、原本をご参照下さい。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
概要
機械学習モデルのアイデアを素早く検証したい場合があります。
・モデルの種類は決まっているますがまだMLパイプラインで運用する気はない。
・思い描いた関係が存在するかどうかをテストしたい。
・本番環境であっても、MLopsで常に再学習する必要がない。
そのような場合は、Vantageアナリティクス・ライブラリとそれがサポートする複数のMLモデルタイプを使用することができます。
前提条件
Teradata Vantageインスタンスにアクセスする必要があります。
Vantageの新しいインスタンスが必要な場合は、Google Cloud、Azure、AWSのクラウドにVantage Expressという無料版をデプロイメントすることができます。また、VMware、VirtualBox、またはUTMを使用して、ローカルマシン上でVantage Expressを実行することもできます。
Vantageアナリティクス・ライブラリのインストール
Vantageで機械学習をサポートするには、Vantageアナリティクス・ライブラリが必要です。このセクションでは、VantageにVantageアナリティクス・ライブラリをインストールし、いくつかのサンプルデータをロードします。
① Vantageアナリティクス・ライブラリはrpmファイルとして配布されます。Teradata Downloads にアクセスし、Vantageアナリティクス・ライブラリのrpmをローカルマシンにダウンロードします。
② そのファイルをVantageインストールにアップロードします。Vantage Express をローカルで実行する場合、多くの方法があります。
□VirtualBox on Vantage Expressをインストールした場合、ファイルをVMのデスクトップにドラッグ&ドロップすることができます。また、ポート4422に接続してscpを使用することもできます。
scp -P 4422 ~/Downloads/VAL-2.0.0.3-1.x86_64.rpm root@localhost:/root/Desktop
□VMwareを使用していてドラッグ&ドロップが有効になっている場合は、ファイルを仮想マシンのデスクトップにドラッグ&ドロップすることができるはずです。
□VantageノードにSSHでアクセスできる場合は、scpコマンドを使ってバイナリをアップロードすることができます。
scp ~/Downloads/VAL-2.0.0.3-1.x86_64.rpm root@vantage.server.name:/tmp/
③ ここでVantageアナリティクス・ライブラリの関数とプロシージャがインストールされる新しいデータベースを作成します。Vantageアナリティクス・ライブラリをSYSLIBなどのグローバルな場所にインストールすることもできますが、特定のデータベースにインストールすることで何か問題が発生した場合にやり直すことが容易になります。VALというデータベースを作成し、ユーザーに適切なパーミッションを与えましょう。
データベース名とユーザーIDを利用している環境に合わせてください。
CREATE DATABASE val
AS PERMANENT = 60e6, -- 60MB
SPOOL = 120e6; -- 120MB
GRANT CREATE FUNCTION ON val to dbc;
GRANT ALTER FUNCTION ON val to dbc;
GRANT EXECUTE PROCEDURE on SQLJ.REMOVE_JAR to dbc;
GRANT EXECUTE PROCEDURE on SQLJ.INSTALL_JAR to dbc;
GRANT EXECUTE PROCEDURE on SQLJ.REPLACE_JAR to dbc;
GRANT CREATE EXTERNAL PROCEDURE ON val to dbc;
④ 仮想マシンでターミナルを開きインストール作業を開始します。必要に応じてrpmのパスを変更してください。
rpm -Uvh --nodeps ~/Desktop/VAL-2.0.0.3-1.x86_64.rpm
⑤ インストールウィザードは、ホスト名、ユーザID、およびパスワードの入力を要求します。Vantage Expressの仮想マシン上でインストールを実行する場合、値は次のとおりです。
□ホスト名:localhost
□ユーザID:dbc
□パスワード:dbc
□アカウント文字列:空白のまま、ENTERキーを押します。
□BTEQまたはFASTLOADコマンド:空白のまま、ENTERキーを押します。
⑥ ウィザードはVantageアナリティクス・ライブラリのどの部分をインストールするかを選択するよう求めます。まず、td_analyzeプロシージャ、つまりオプション1のインストールから始めたいと思います。オプション1を選択するとスクリプトはtd_analyzeがインストールされるデータベース名の入力を要求します。valを入力し、ENTERキーを押します。
⑦ ウィザードの途中でオプション5、すなわちTutorial Tablesをインストールします。これらは、サンプルモデルを構築するために使用するデータを含むサンプルテーブルです。
サンプルデータ
VAL とサンプルテーブルがロードされたので、データを調査してみましょう。これは架空のデータセットで、銀行の顧客 (1,000行程度)、口座 (10,000行程度)、取引 (100,000行程度) からなっています。これらは互いに次のような関係になっています。
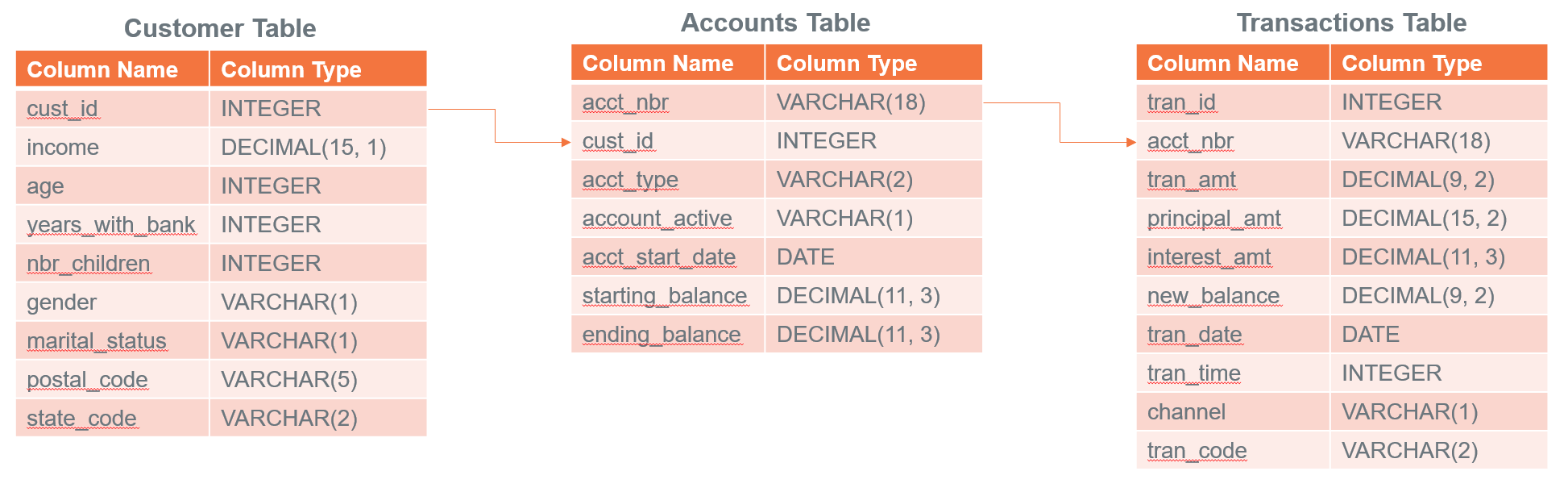
ここからは表中のクレジットカードに関連しないすべての変数に基づいて銀行の顧客がクレジットカードで持っている毎月の平均残高を予測するモデルを構築できるかどうかを試します。
線形回帰モデルを作成する
まずは、上記の3つのテーブルを結合したワイドテーブル(Analytic Data Set、ADS)を作成しましょう。
以下のクエリーの実行にはVantageアナリティクス・ライブラリがインストールされているDatabaseのCREATE TABLE権限を持っている必要があります。
-- Switch to val database.
DATABASE val;
-- Create the ADS.
CREATE TABLE VAL_ADS AS (
SELECT
T1.cust_id AS cust_id
,MIN(T1.income) AS tot_income
,MIN(T1.age) AS tot_age
,MIN(T1.years_with_bank) AS tot_cust_years
,MIN(T1.nbr_children) AS tot_children
,CASE WHEN MIN(T1.marital_status) = 1 THEN 1 ELSE 0 END AS single_ind
,CASE WHEN MIN(T1.gender) = 'F' THEN 1 ELSE 0 END AS female_ind
,CASE WHEN MIN(T1.marital_status) = 2 THEN 1 ELSE 0 END AS married_ind
,CASE WHEN MIN(T1.marital_status) = 3 THEN 1 ELSE 0 END AS separated_ind
,MAX(CASE WHEN T1.state_code = 'CA' THEN 1 ELSE 0 END) AS ca_resident_ind
,MAX(CASE WHEN T1.state_code = 'NY' THEN 1 ELSE 0 END) AS ny_resident_ind
,MAX(CASE WHEN T1.state_code = 'TX' THEN 1 ELSE 0 END) AS tx_resident_ind
,MAX(CASE WHEN T1.state_code = 'IL' THEN 1 ELSE 0 END) AS il_resident_ind
,MAX(CASE WHEN T1.state_code = 'AZ' THEN 1 ELSE 0 END) AS az_resident_ind
,MAX(CASE WHEN T1.state_code = 'OH' THEN 1 ELSE 0 END) AS oh_resident_ind
,MAX(CASE WHEN T2.acct_type = 'CK' THEN 1 ELSE 0 END) AS ck_acct_ind
,MAX(CASE WHEN T2.acct_type = 'SV' THEN 1 ELSE 0 END) AS sv_acct_ind
,MAX(CASE WHEN T2.acct_type = 'CC' THEN 1 ELSE 0 END) AS cc_acct_ind
,AVG(CASE WHEN T2.acct_type = 'CK' THEN T2.starting_balance+T2.ending_balance ELSE 0 END) AS ck_avg_bal
,AVG(CASE WHEN T2.acct_type = 'SV' THEN T2.starting_balance+T2.ending_balance ELSE 0 END) AS sv_avg_bal
,AVG(CASE WHEN T2.acct_type = 'CC' THEN T2.starting_balance+T2.ending_balance ELSE 0 END) AS cc_avg_bal
,AVG(CASE WHEN T2.acct_type = 'CK' THEN T3.principal_amt+T3.interest_amt ELSE 0 END) AS ck_avg_tran_amt
,AVG(CASE WHEN T2.acct_type = 'SV' THEN T3.principal_amt+T3.interest_amt ELSE 0 END) AS sv_avg_tran_amt
,AVG(CASE WHEN T2.acct_type = 'CC' THEN T3.principal_amt+T3.interest_amt ELSE 0 END) AS cc_avg_tran_amt
,COUNT(CASE WHEN ((EXTRACT(MONTH FROM T3.tran_date) + 2) / 3) = 1 THEN T3.tran_id ELSE NULL END) AS q1_trans_cnt
,COUNT(CASE WHEN ((EXTRACT(MONTH FROM T3.tran_date) + 2) / 3) = 2 THEN T3.tran_id ELSE NULL END) AS q2_trans_cnt
,COUNT(CASE WHEN ((EXTRACT(MONTH FROM T3.tran_date) + 2) / 3) = 3 THEN T3.tran_id ELSE NULL END) AS q3_trans_cnt
,COUNT(CASE WHEN ((EXTRACT(MONTH FROM T3.tran_date) + 2) / 3) = 4 THEN T3.tran_id ELSE NULL END) AS q4_trans_cnt
FROM Customer AS T1
LEFT OUTER JOIN Accounts AS T2
ON T1.cust_id = T2.cust_id
LEFT OUTER JOIN Transactions AS T3
ON T2.acct_nbr = T3.acct_nbr
GROUP BY T1.cust_id) WITH DATA UNIQUE PRIMARY INDEX (cust_id);
データセットからパラメータを取得して、クレジットカードの月次残高を予測する線形回帰モデルを構築します。
td_analyze を呼び出して、線形モデルを作成します。入力はテーブル VAL_ADS にあり、複数の列で構成されています。従属変数はcc_avg_balです。モデルは、LINEAR_REGRESSION_DEMOというテーブルとしてvalデータベースに書き込まれます。
call td_analyze('linear',
'database=val;
tablename=VAL_ADS;
columns=tot_age,tot_income,tot_cust_years,tot_children,single_ind,female_ind,married_ind,separated_ind,ck_acct_ind,sv_acct_ind,sv_avg_bal,ck_avg_bal,ca_resident_ind,ny_resident_ind,tx_resident_ind,il_resident_ind,az_resident_ind,oh_resident_ind;
dependent=cc_avg_bal;
outputdatabase=val;
outputtablename=linear_regression_demo');
このプロシージャではいくつかの出力テーブルが作成されます。この時点でテーブルの中身を確認する必要はありません。それでは新しく作成されたモデルを使ってどのようにスコアリングを行うかを見てみましょう。
スコアリング
このモデルを使って、予測を行い、スコアを評価しましょう。これを行うには、linearscoreパラメータを指定してtd_analyzeを呼び出します。
入力テーブル(VAL_ADS)、モデルテーブル(prefix linear_regression_demo)を指定し、valデータベースのターゲットテーブル(linear_regression_score)を作成しています。
call td_analyze('linearscore',
'database=val;
tablename=VAL_ADS;
modeldatabase=val;
modeltablename=linear_regression_demo;
outputdatabase=val;
outputtablename=linear_regression_score;
predicted=estimate;
retain=cc_avg_bal;
scoringmethod=scoreandevaluate;');
その結果、実際のバランス、予測されたバランス、そしてこの2つの差を含む linear_regression_score テーブルが得られます。
結果のサンプルを見てみましょう。
SELECT * FROM linear_regression_score SAMPLE 10;
このクエリーで結果が得られるでしょう。
| cust_id | cc_avg_bal | estimate | Residual |
|---|---|---|---|
| 1362498 | 0.0 | 284.7057772484358 | -284.7057772484358 |
| 1362828 | 1184.35 | 463.74177458594215 | 720.6082254140578 |
| 1362839 | 2933.135802469136 | 982.9240031182255 | 1950.2117993509103 |
| 1362986 | 500.9148148148148 | 881.4116539412856 | -380.4968391264708 |
| 1362511 | 235.85941489361701 | 294.35369563202846 | -58.494280738411426 |
| 1363134 | 0.0 | 430.27950420065997 | -430.27950420065997 |
| 1363481 | 0.0 | 411.2359958542745 | -411.2359958542745 |
| 1362644 | 209.3304347826087 | 279.75770904482033 | -70.42727426221163 |
| 1363141 | 0.0 | 550.1681921045503 | -550.1681921045503 |
| 1363290 | 0.0 | 120.35348558871233 | -120.35348558871233 |
まとめ
今回のクイックスタートでは、SQLで機械学習モデルを作成する方法について学びました。方法としては、Vantageアナリティクス・ライブラリを使用しました。線形回帰モデルを構築しそのモデルを使用して予測を実行することがSQLのみで行うことができました。
#さらに詳しく
・Vantage Analytics Library User Guide