再帰型ニューラルネット ワークの概念
RNNの重み
1.入力から現在の中間層を定義する際にかけられる重み(W_IN)
2.中間層から出力を定義する際にかけられる重み(W_out)
3.中間層から中間層の重み(W)

weight_init_stdを1→0.5

learning_ratを0.1→0.5
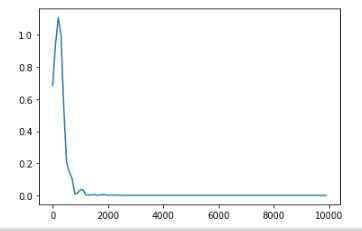
hidden_layer_sizeを16→30
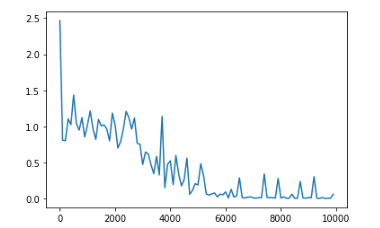
・重みの初期化方法を変更
Xavier

He
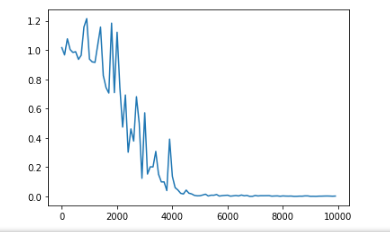
ReLU関数
→勾配が激しい

・BPTT
→RNNにおいてのパラメーターの調整方法の1つ
・ビジネス事例
→GPU周り等のインフラ(AWSやGoogle Cloud)
→スマートミラー(鏡とコミュニケーションが取れる。化粧の仕方)
→肌の異常検知
→ニキビができる箇所と推測される原因を組み合わせて、
おすすめレシピやサプリメントの提案もできるのではないか
→筋トレやセルフエステに使用できるのではないか。
(本来のフォームとは異なるフォームを以上として判断するなど)
LSTM
時系列をさかのぼるほど勾配が消失していく。
構造自体を変えて解決したものがLSTM
・勾配消失問題とは
→誤差逆伝番法が下位層に進むにつれ、勾配が緩やかになり、
収束しなくなる
・勾配爆発
→かけあわされていき、指数関数的に大きくなっていく
・クリッピング
gradient*rareが返される
・CEC
→勾配爆発の解決法として、勾配が1であれば解決できる
→時系列データの学習特性が無い、重みが一律化してしまう
・忘却ゲートとは
→キャッシュのようなもの
・セルの状態を更新
input_gate*a+forget_gate
→新しいセルの状態は、計算されたセルの入力と1ステップ前のセルの状態に入力ゲート、忘却ゲートをかけて足し合わせたもの
GRU
・LSTMではパラメーター数が多く計算負荷が高くなる
→GRUではパラメーターを大幅削減し精度は同等またはそれ以上
・GRUの新しい中間状態
→(1-z)h+zh_bar
・LSTMとGRUの違い
→LSTMのほうがパラメーター数が多い
→両方使用してみて、向いているほうを使う
GRUは、LSTMよりもゲートが1つ少なく、入力ゲート、出力ゲート、忘却ゲートの代わりに更新ゲートがある
更新ゲートは最後の状態からどれだけの情報を保持し、前の層からどれだけの情報を取り込むかを決定する
更新ゲートはLSTMの忘却ゲートのように機能するが、位置付けが異なり、出力ゲートはない
GRUの方が高速で簡単に実行できるが、表現力を必要とする場合は向かない
双方向RNN (BidirectionalRNN)
→過去の情報だけでなく、未来の情報を加味する
→入力層、中間層においては順方向(過去から未来)の部分は通常のRNNと同じ
出力層においては逆方向(未来から過去)の部分と統合される
双方向RNNでは順方向と逆方向に伝番した時の中間層表現を合わせたものが特徴量となる
→np.concatenate([h_f,h_b[::-1]], axis=1)
Seq2Seq
機械翻訳などのモデルに使われる
一問一答しかできない
・Encode RNN
→ユーザーがインプットしたテキストデータを単語等のトークンに区切って渡す
最後のベクトルを入れたとき、final stateとしてとっておく
final stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなり、これがデコーダーに渡される
・Decodee RNN
→システムがアウトプットしたデータを単語等のトークンごとに生成する構造
→次にくる単語を予測して、渡していく
→ベクトルを言語化していく
単語はベクトルであり、単語埋め込みにより別の特徴量に変換する
→E.dot(w)
HRED・・・同じ回答になる
VHRED・・・文脈に沿いつつ、ランダムな回答
VAE
→自己符号化器の潜在変数に、確率分布を導入したもの
Word2vec
学習データからボキャブラリを作成
one-hotベクトル
→合っている場合は1、違う場合は0
・ポイント
ボキャブラリ×任意の単語ベクトル次元で重み行列が誕生するため、
次元を減らした状態でも単語を意味がある値として算出できる
・CBOW
→コンテキスト(周囲の単語)からターゲットの単語を予測
コンテキストを入力値としてターゲットとする単語の事後確率が最大になるよう学習する
予測した出力結果(確率)と正解値の差をみて、誤差が小さくなるよう重みを更新することで学習を行う
・skip-gram
→中央の単語からコンテキスト(周囲の単語)を予測する
Attention Mechanism
「入力と出力のどの単語が関連しているのか」の関連度を学習
重要度や関連度の学習により、長い文章への対応も可能となった
ネットワークは翻訳前後の単語の対応関係を学習し、単語列の出力時に対応する入力の単語を引っ張ってくることで長い文書でも翻訳の精度をあげる