CVPR 2018 Tutorial on GANsにおけるPart1 Phillip IsolaのパートのYoutube動画の読解メモ。Youtubeの音声が荒れまくっているので基本的には資料とYoutubeの自動字幕でうまくいっている部分を読みながら追ったメモとなります。また、なるべくさらに正確な情報を得るためのリンクも添付しています。
記述に誤り等ありましたらご教授頂けますと幸いです。
出典
チュートリアルホームページ
発表資料
発表者
Phillip Isola, MIT
概要
Phillip Isolaは"Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2016). Image-to-image translation with conditional adversarial networks. arXiv: 161107004."の著者。
本論文はL1距離誤差とconditional GANを組み合わせた最適化にPatchGAN, U-Netなどのテクニックを盛り込んだもので地図やエッジ画像、セグメンテーション画像から実写を生成するタスクにおいて高精細でリアルな画像を生成することに成功している。
本発表においてはImage to Image translationタスクにおいて上記論文で使われた技術要素の詳細を説明するとともに、その後のさらに発展的な最近の研究についても網羅的に解説している。
内容
Image-to-Image Translationとは
まず、Image-to-Image Translationの研究例(図1)。

物体領域ラベリング、エッジ検出、景色変換、絵画風にスタイルを変換などがある。
Image-to-Image Translationの基本的なフレームワークは図2に示した通り。入力画像をx, 出力画像をy, xをyに変換する関数をFとするとF(x)とy間の誤差Lの期待値を最小にするような関数Fを求めることである。
 図2
図2
従来の誤差関数
この問題で重要なのが誤差関数Lをどう設計するかである。例えば白黒写真をカラー化するタスクではF(x)で推定した画素の色と対応する画素の正解の色の差をab色空間での距離としてしまうとうまくいかない。(彩度の乏しいものに収束してしまう。※ここスライドを見て勝手に推測しただけなのでちょっと怪しい)そこで、Color distribution cross-entropy loss with colorfulness enhancing termという誤差を導入[Zhang, Isola, Efros, ECCV 2016]。詳しくは読んでいないが単語から察するに推定画像の色分布と正解画像の色分布の分布間の差を最小化する。
同様に画像を高解像度化するタスクにおいてもDeep feature covariance
matching objectiveという誤差を導入[Johnson, Alahi, Li, ECCV 2016]。
でもこうしていろいろ考えて導入した誤差関数については課題ごとに考えている。さまざまな課題に共通して使用できるuniversalな誤差関数があればうれしい。(図3)
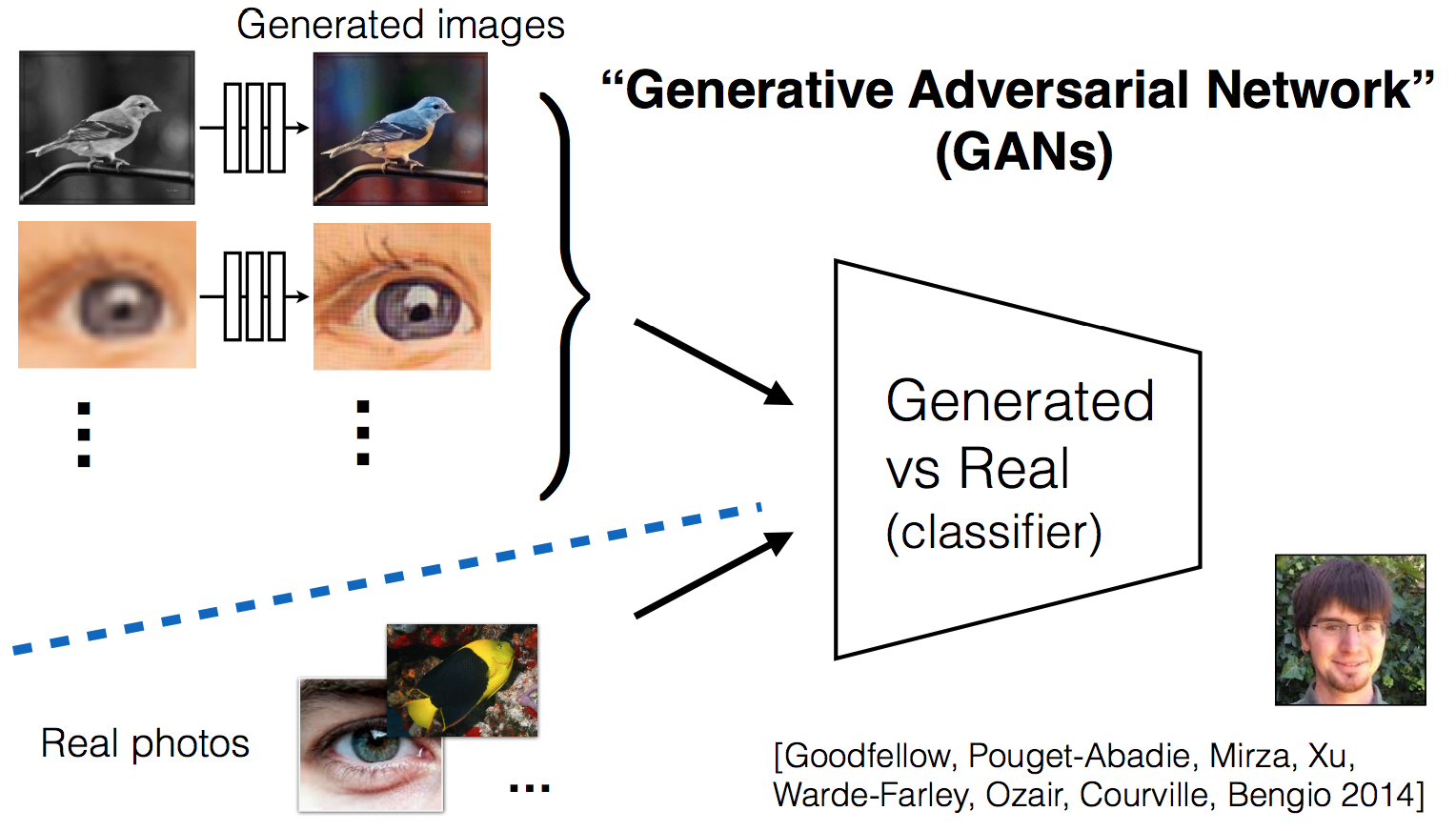 図3
図3
Conditional GAN
そんな中で世に出てきたGAN[Goodfellow, Pouget-Abadie, Mirza, Xu,
Warde-Farley, Ozair, Courville, Bengio 2014]を導入することでこの要望をある程度解決した。
Image-to-Image translationでは特にConditional GAN[Mirza et al. 2014] [Reed et al. 2016][Ledig et al. 2017][Isola et al. 2017][…]が有効である。
元々の単なるGANとconditional GANとの違いはGANのdiscriminatorはgeneratorが生成した画像に対してrealかfakeしか推定しなかった(図4)。この方法だとgeneratorが本物っぽくはあるが元の画像とは全然違う内容の写真を生成するように学習し得てしまうという課題がある。
これを防ぐ為にConditional GANではdiscriminatorに学習させる内容を修正。realかfakeを判定するのではなくて、generatorの生成した画像と正解画像のペアを入力として正解画像のペアか否かを判定できるよう学習させる(図5)。こうすることで正解画像に近づけるような拘束を課すことができる。この手法を使って画像のカラー化と衛星画像の地図化という従来なら同じ誤差関数ではうまくいかなかった二つの変換タスクをConditional GANという同じアルゴリズムで解くことに成功した。
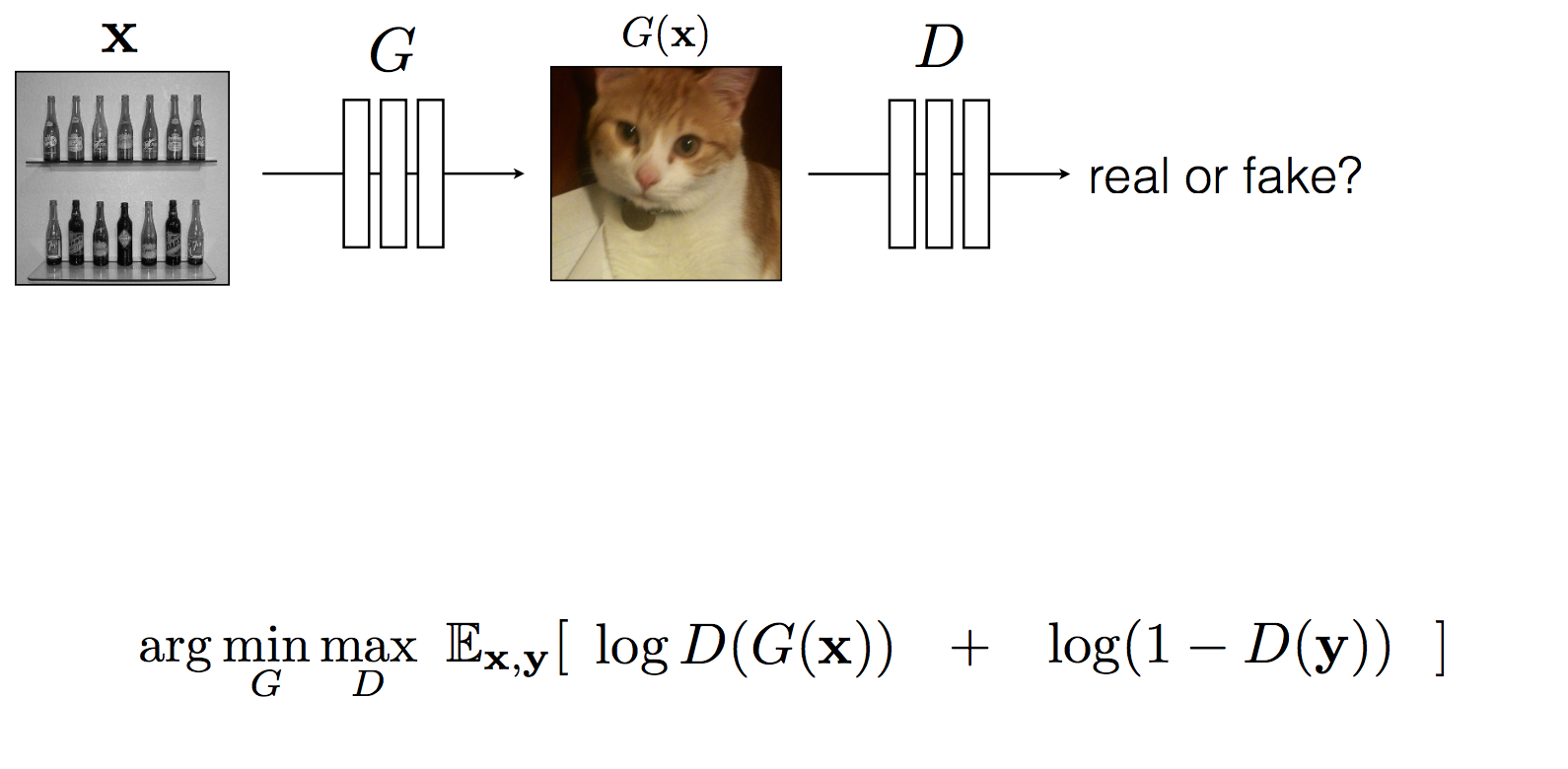 図4 元々のGAN
図4 元々のGAN
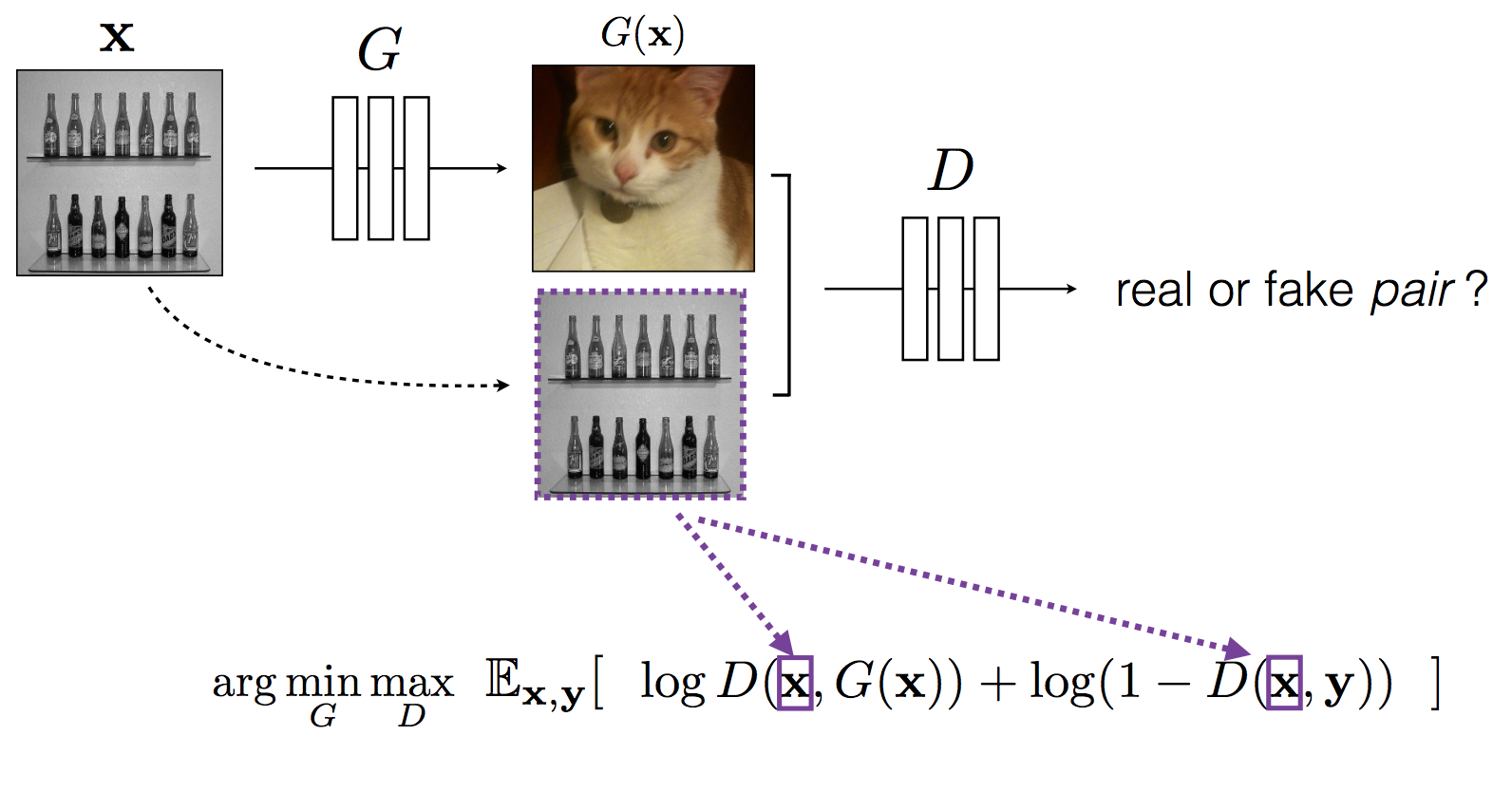 図5 Conditional GAN
図5 Conditional GAN
※なお、上記アルゴリズムの説明は発表者のスライドがとても分かりやすいです。というか全般的にこの発表者のスライドはかなり噛み砕いて説明してくれています。
Image-to-Image translationの二つの残課題
なお、残るImage-to-Image translationの難問が「outputが高次元で構造的なものの場合(例えば高解像度化においては対象物の幾何的・空間的な整合性を維持している必要があるがこういうことを構造的と表現していると思われる)」と「妥当な解が複数あるとき」である。(図6)
 図6
図6
outputが高次元で構造的なものの場合
まず前者、outputが高次元で構造的なものの場合の問題へのアプローチを説明する。
この問題はそもそも出力する画像の画素をそれぞれ独立するものとして扱っているのが問題(図7左)と言える。かといって全ての画素ペア同士の関係を考慮するとモデルが複雑になる(図7右)。
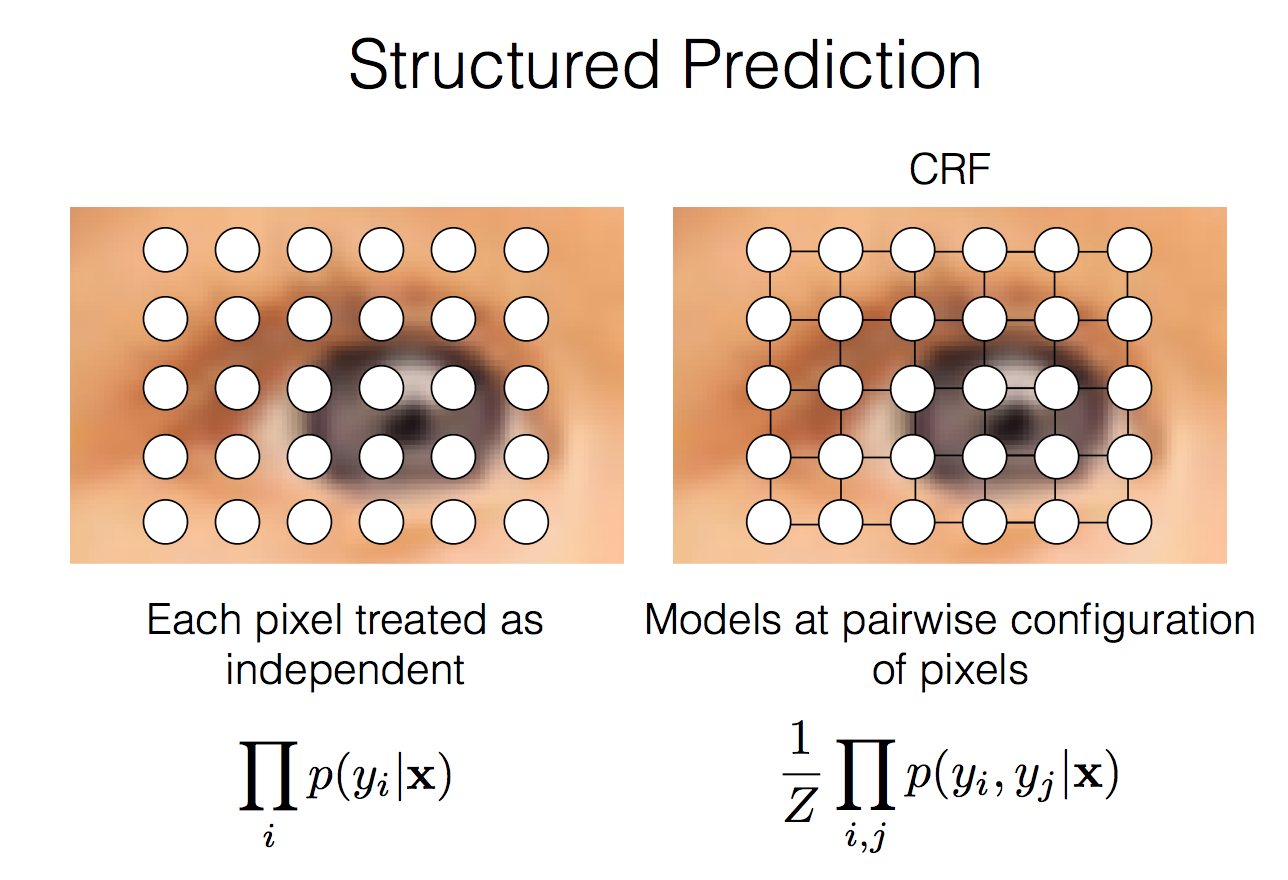 図7
図7
Percptual Loss
そこで最近行われていたのがpercptual lossという誤差関数でdiscriminatorを学習させる手法。(図8)perceptual lossとはdiscriminatorが生成画像と正解画像をそれぞれdiscriminateする際に中間層の出力結果も同じであるべきだという観点を取り入れた誤差関数。中間層出力には高次の特徴が表されているはずだという考えから。
参考) https://github.com/arXivTimes/arXivTimes/issues/344
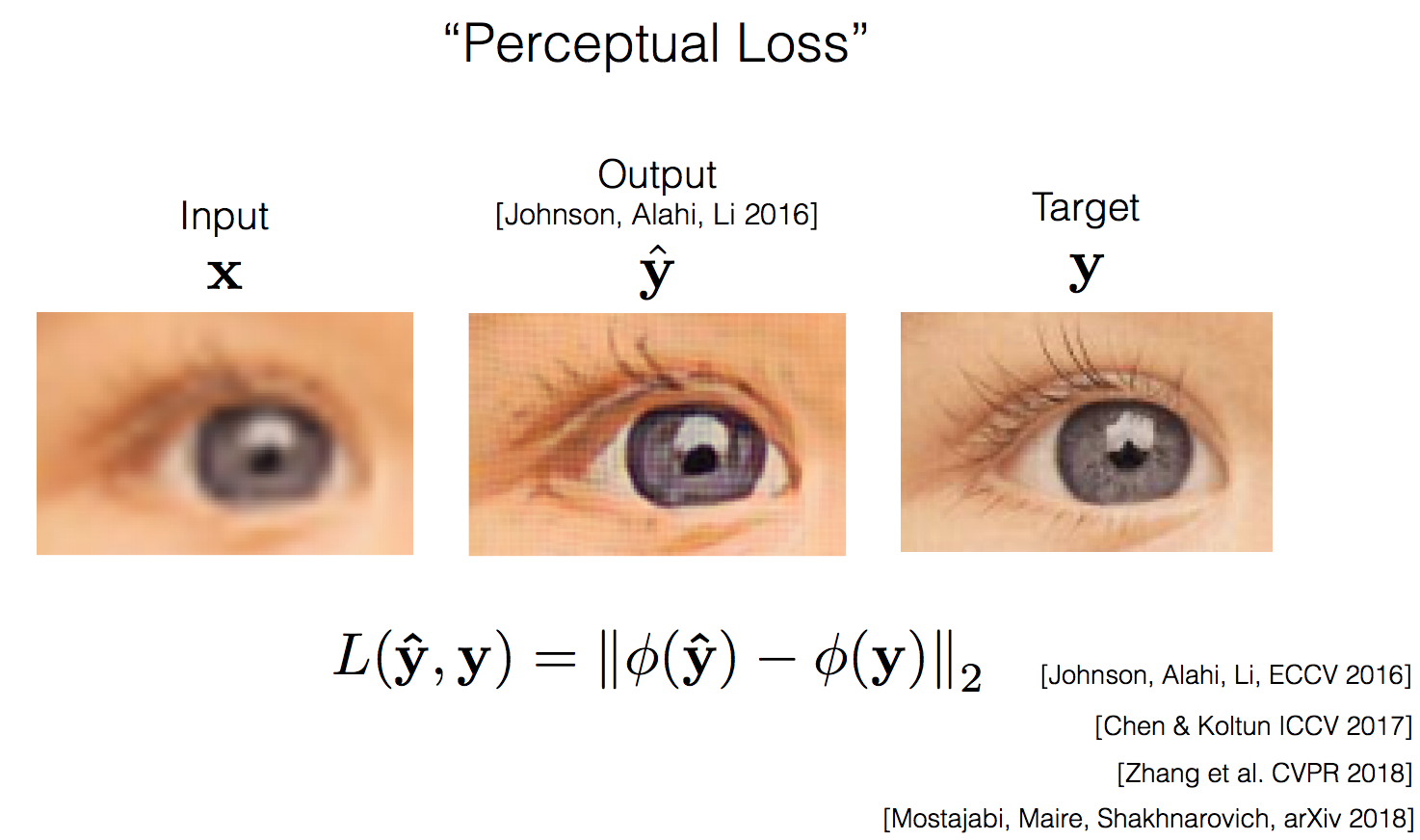 図8
図8
Patch Discriminator
もう一つのアプローチがGANにうまく画素間の関係に関する情報を取り入れること。このアプローチを実現する手法としてpatch discriminatorがある(図9)。
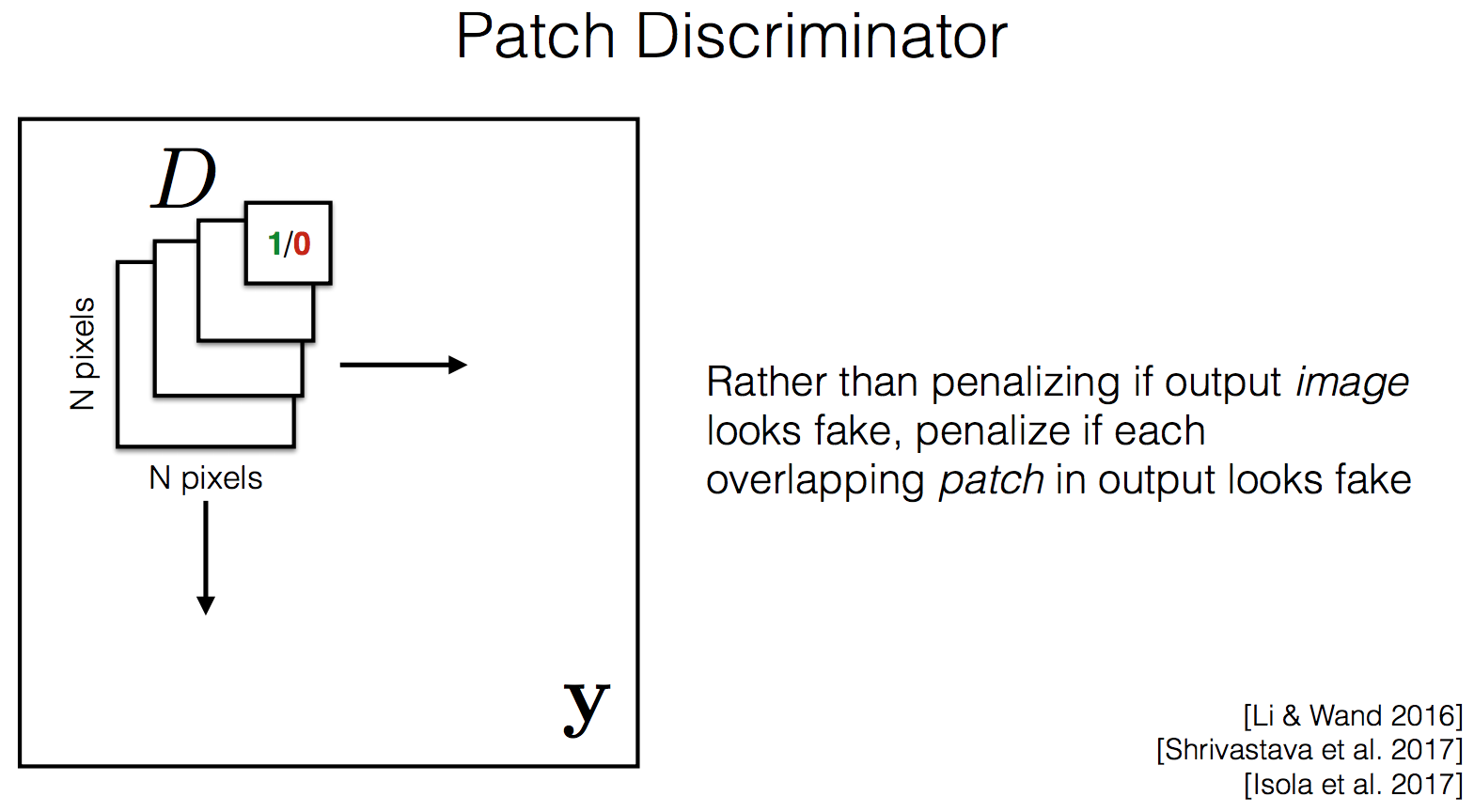 図9
図9
図9を見てわかるようにdiscriminatorを複数用意してそれぞれが大きさの異なる複数種類のパッチに対してrealかfakeかを推定できるように学習させる。全てのパッチサイズにおいてdiscriminatorが正しく推定できるようにすることで画素間の関係についても考慮している効果を出すことができるのだと思われる。
図10-13にpatch discriminatorのpatchサイズ別のサンプル出力画像を示す。
 図10
図10
 図11
図11
 図12
図12
 図13
図13
ここまでをまとめると「outputが高次元で構造的なものの場合(例えば高解像度化においては対象物の幾何的・空間的な整合性を維持している必要があるがこういうことを構造的と表現していると思われる)」という課題に対してはGANにおけるDiscriminatorを賢くすることが各アプローチの共通点と言える。
妥当な解が複数あるとき
次に後者の課題「妥当な解が複数あるとき」へのアプローチを説明する。
この問題は要求される推定結果が一つに定まらないケースであり、例えば白黒画像のカラー化タスクなどが代表的な例である。カラー化においては必ずしも一つのカラー化例だけが妥当な正解ではなく、妥当とされる正解は幾つか存在する。この様子を下図14の青線$p(y|x)$のように表す。
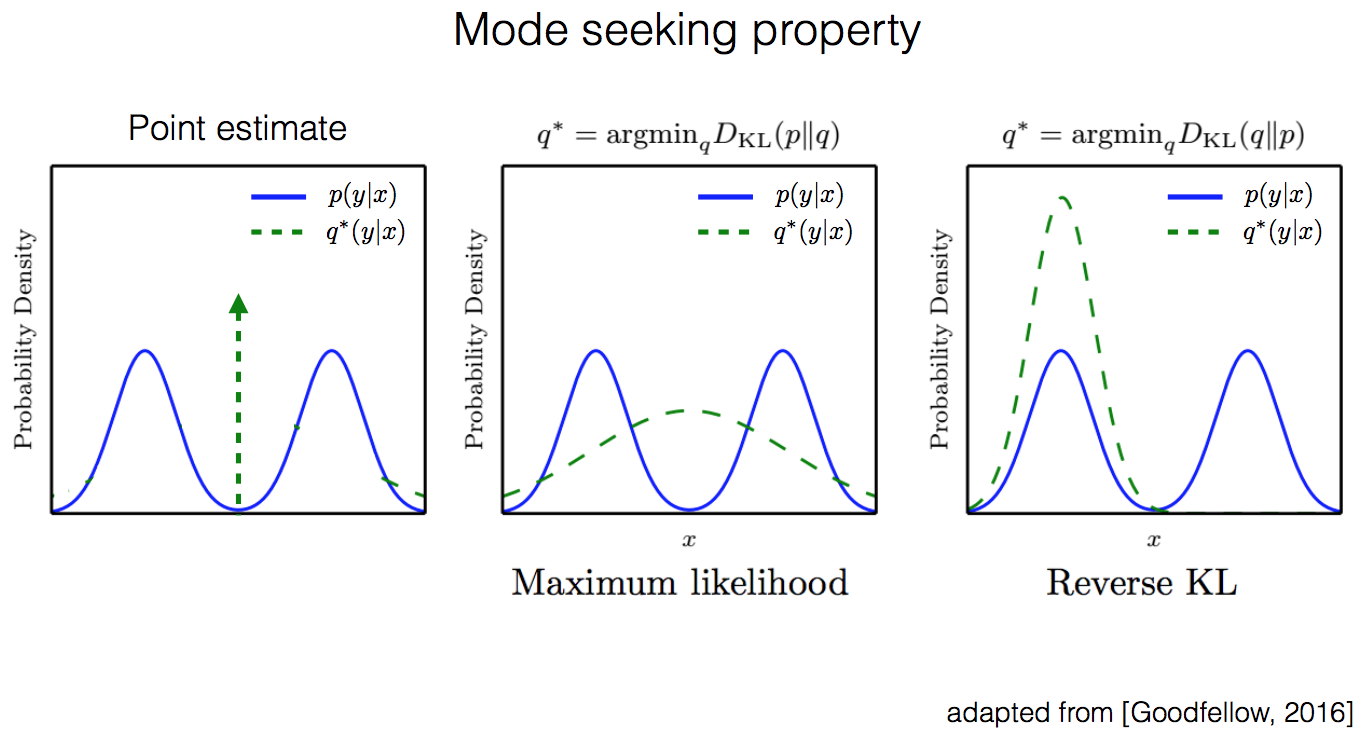 図14
図14
Reverse KL
このようなケースにおいては推定分布$q(y|x)$として望ましいのは図14の真ん中の図の緑線のような全体を覆うような分布よりも右の図のような$p(y|x)$の一部によくフィットする分布と考えられる。このような推定を実現する方法としてReverse KLを誤差関数として用いる最適化があり、うまく使うとかなり良い結果が得られる。
 図15
図15
上図15は地図から衛星画像を生成するタスクにおいてReverse KLを誤差関数に学習させた結果思われる。OutputはGroundtruthと全然違うもののそれらしい推定をしていると言える。もちろんこのタスクにおいては地図から衛星画像を復元するための十分な情報はないのでこれはこれで望ましい解の一つと言える。
 図16
図16
一方で上図16はL1 normを誤差関数として学習した場合である。これは図14の真ん中に相当するものであり、結果は正解から大きく外れてもいないが、全体的にぼやけており望ましい品質とは言えない。
このように「妥当な解が複数あるとき」へのアプローチとしては妥当な解を表す分布の全部を中途半端にフィットするのではなくて、一部に良くフィットさせることができる誤差関数を用いるということが考えられる。
BicycleGAN
そしてこの場合は推定した分布は妥当ではあるものの必ずしも正解とは一致しないという性質を持つ。これは仕方ないことではあるが、妥当な仮説は一つではなく複数欲しいという要望がある。この要望への回答として複数の妥当性のありそうな仮説を提示する手法が提案されている。
複数の妥当性のありそうな仮説を提示する手法としてまず行われたのがgeneratorにノイズをランダムに抽出して変化させれば様々な出力が得られるのではないかということ。しかしこの方法だと意図通りに出力に多様性を持たせられないことが多く、この問題は"mode cllapse"と呼ばれていた。
BicycleGAN[Zhu2017]ではこの問題に対して多様性を保持しつつとリアリティを両立させるようなGANを設計している。
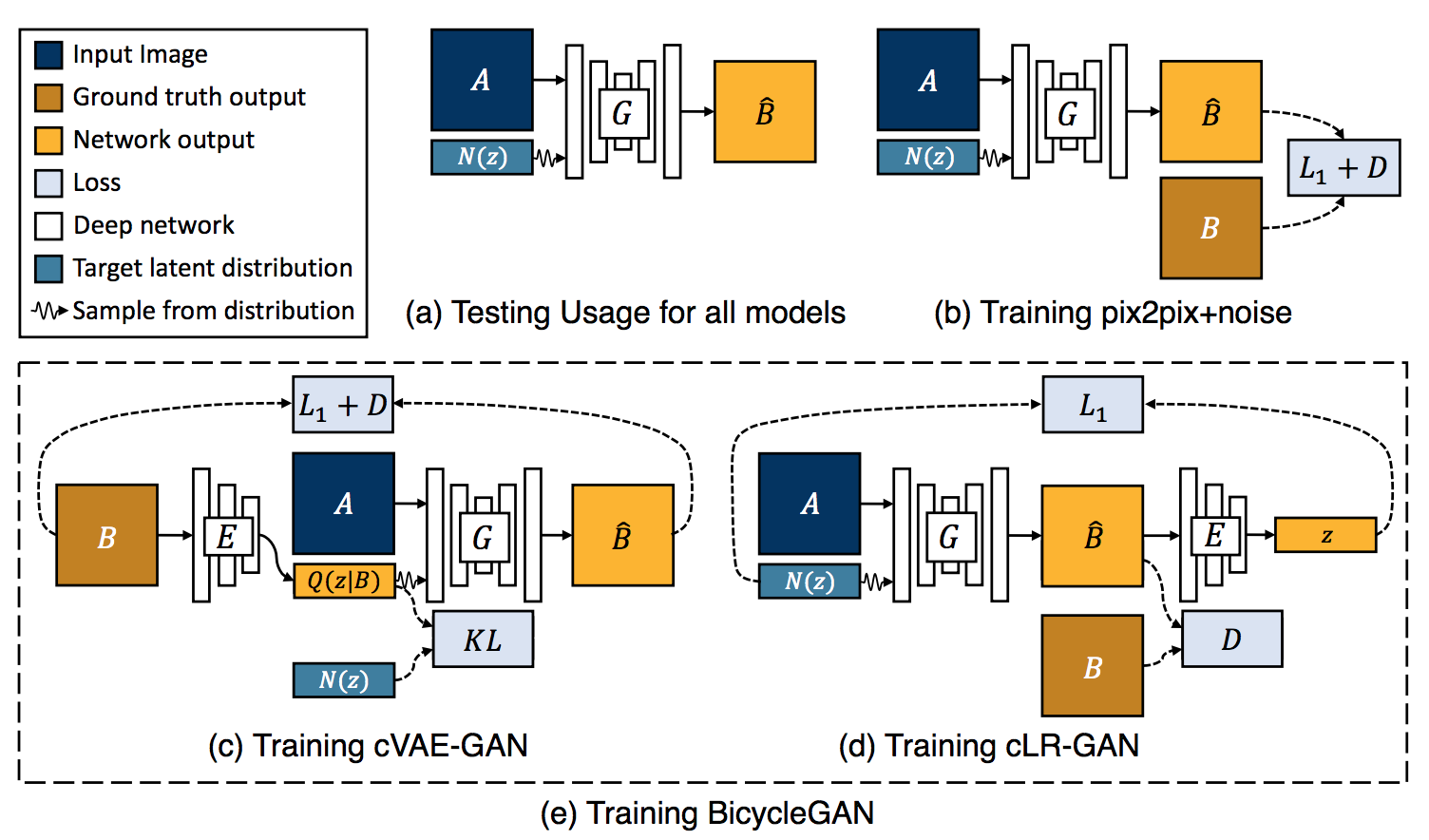 図17
図17
具体的にはcVAE-GANとcLR-GANのハイブリッド手法。(図17)完全に理解していないので詳細は著者のページを読んで確認して欲しいがcVAE-GANではlatent spaceでの多様性を確保するための学習でcLR-GANはlatent spaceにおけるあるコードから画像を生成するときのリアリティを学習する役割を担っているように見受けられる(要確認!)。これによって多様性とリアリティを両立させることに成功した手法である。