はじめに
昔、『ポケモンをさがせ!』って本ありましたよね?小学生のころ地味に好きでした。
あれを、自動的に見つけ出してくれる方法があれば、それ以上のことはないですよね?『ウォーリーを探せ』もそうですが。
今回はそれを機械学習の技術で実現します。といっても、探し出すのは、大量の画像の中から、あるポケモンに似ているポケモンです。
Bag of Visual Words
皆さんは、Bag of Words(BoW)という技術を御存知でしょうか。自然言語処理をするたびに毎回出てくるアレです。各文章の中で、それぞれの単語が何回出てくるかのベクトルを、OneHotEncodingを使って作成する技術で、自然言語処理の分析をするのに最も基礎的な手法です。詳しく知りたい方は、ネット上にいくらでも転がっているので、その辺の記事か、ゼロつくの自然言語処理編辺りをお読みください。これを画像に応用してしまおうというのが、このBag Of Visual Wordsです。出力結果だけ見たいという殊勝な方は、出力結果の欄から御覧ください(え
画像には単語という概念は存在しないので、Bag of Visual Wordsでは、複数の画像からいくつかの代表的な局所特徴を取り上げ、それを単語のように扱います。この代表的な局所特徴のことを「コードワード」と呼び、コードワードの集合体を「コードブック」と呼びます。
それぞれの画像の中で、各コードワードがどのくらい現れているかをヒストグラムで表したものが特徴量ということになり、これが自然言語処理で言う、各文章のベクトルのようなものですかね。
また、「コードワード」の選び方としては、各画像から抽出された局所特徴群を、k-meansなどでクラスタリングすることにより、いくつかのグループの中での代表的な局所特徴群を探し出す方法がとられます。
最後にこれらを手順化すると、おおむね次のようになります。
1.各画像から、SIFT記述子などの局所特徴を抽出する。
2.すべての画像から抽出してきた局所特徴群から、クラスタリングの手法を使って代表的なもの(コードワード)を選び出す。
3.各画像の中で、それぞれのコードワードがどの程度出現するか調べる(各画像の特徴量)
4.比較したい画像同士の特徴量の距離を調べることで、それらの画像がどの程度似ているか調べることができる。
なんか画像の一部を単語のように扱うって、Vision Transformer(ViT)みたいですね。自然言語処理にヒントを得た画像系の手法は、皆このような発想を取るのでしょうか。画像版のBag of Wordsがあるなら、画像版のtf-idfとかもあっても良くないですか?
実装
実行環境
・Windows10
・Python3
・Google Colaboratory
コード
まず、いつも通り使うライブラリをインポートします。
from keras.datasets import mnist, cifar10
import cv2
import glob
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import ImageGrid
%matplotlib inline
from tqdm import tqdm
import numpy as np
from sklearn.cluster import MiniBatchKMeans
from sklearn.metrics.pairwise import cosine_similarity
Colaboratoryを使う場合は、画像を読み込むためにドライブにマウントします。
from google.colab import drive
drive.mount('/content/drive')
適当に画像を読み込みます。今回はポケモンの画像を使いたいので、kaggleのdatasetからこちらのデータを使いました。ポケモンの種類は809(サンムーンのメルメタルまで。剣盾は入ってないのね。SVは分からんからカンベンしてくれー泣)、画像自体は確認したところ721枚ありました。
# 画像の読み込み
files = glob.glob("/content/drive/MyDrive/MyWorks/img/kaggle_dataset/PokemonImageDataset/images/images/*.png")
imgs = []
for n in tqdm(range(len(files))):
img = cv2.imread(files[n])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
imgs.append(img)
## 表示用グリッド
fig = plt.figure(1, (12., 12.))
grid = ImageGrid(fig, 111,
nrows_ncols=(2, 3),
axes_pad=0.1)
# 最初の数枚を表示
for i in range(6):
grid[i].imshow(imgs[i])
plt.imshow(img)
各画像の局所特徴を取得します。今回はこちらの記事を参考に、OpenCVのakazeという局所特徴を抽出しました。AKAZEは、画像の拡大、縮小、回転、焦点のぼやけ等に対して、SIFTよりも頑強性のあるKAZEをベースに、さらに計算量が減るように改善した特徴量のようです。また、SIFTは特許権が付いており、商用利用にはライセンスが必要ですが、AKAZEはそのような必要はないようです。OpenCVでは他にもいくつかの特徴量を使えるようなので、あとで他のものも試します。記事を書き終わった後に知った記事なのですが、こちらの記事とか参考になります。
https://qiita.com/shu223/items/fa3cf693296e5641f771
# 局所特徴の抽出
akaze = cv2.AKAZE_create()
features = []
for img in tqdm(imgs):
features.extend(akaze.detectAndCompute(img, None)[1])
features
100%|██████████| 721/721 [00:05<00:00, 129.44it/s]
[array([ 33, 95, 15, 4, 128, 153, 48, 237, 190, 151, 79, 143, 131,
97, 255, 255, 1, 0, 0, 0, 0, 0, 112, 0, 0, 2,
0, 28, 197, 136, 62, 118, 155, 221, 182, 219, 187, 13, 68,
183, 239, 103, 19, 237, 15, 252, 1, 30, 0, 7, 224, 0,
254, 126, 240, 231, 231, 243, 255, 255, 63], dtype=uint8),
array([ 37, 253, 79, 6, 193, 223, 60, 84, 155, 254, 141, 249, 255,
127, 81, 200, 157, 121, 64, 12, 128, 0, 240, 126, 153, 51,
35, 250, 255, 140, 127, 148, 9, 36, 186, 254, 234, 95, 127,
153, 250, 3, 253, 103, 68, 223, 255, 255, 252, 31, 255, 209,
138, 6, 255, 255, 255, 27, 86, 0, 37], dtype=uint8),
array([ 64, 253, 5, 0, 0, 114, 129, 118, 155, 216, 129, 243, 251,
127, 240, 94, 0, 0, 0, 0, 0, 16, 129, 8, 34, 68,
68, 32, 254, 127, 64, 213, 89, 69, 232, 238, 8, 112, 119,
1, 186, 3, 220, 165, 12, 95, 240, 29, 60, 131, 255, 255,
239, 255, 255, 255, 7, 0, 48, 230, 7], dtype=uint8),
array([ 97, 253, 77, 4, 0, 153, 176, 100, 159, 248, 11, 255, 255,
127, 0, 195, 17, 0, 0, 8, 0, 0, 240, 92, 17, 34,
0, 16, 255, 15, 117, 21, 81, 68, 248, 255, 136, 240, 127,
17, 250, 3, 252, 255, 8, 255, 255, 159, 255, 255, 255, 255,
79, 128, 239, 159, 0, 12, 2, 240, 1], dtype=uint8),
・
・
・
(以下省略)
続いてコードワードの作成です。今回はクラスタリングに処理が高速なsklearnのMiniBatchKMeansを使っています。(こちらも先程の記事を参考)
# 局所特徴をクラスタリングして、コードワードの作成
visual_words = MiniBatchKMeans(n_clusters=128).fit(features).cluster_centers_
visual_words
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 3 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
array([[ 55.59163987, 190.91639871, 11.1414791 , ..., 110.91639871,
232.30868167, 38.50160772],
[102.11825488, 244.05625718, 14.59357061, ..., 146.56142365,
170.5717566 , 18.81515499],
[ 13.38361045, 29.05463183, 1.28859857, ..., 197.33491686,
209.40380048, 41.22684086],
...,
[ 32.82051282, 207.74871795, 222.01794872, ..., 204.51282051,
205.12051282, 20.91538462],
[ 18.60761905, 240.26285714, 77.75619048, ..., 134.05714286,
238.16761905, 33.24 ],
[ 13.33123028, 162.41324921, 3.56940063, ..., 208.46845426,
234.99369085, 31.34069401]])
続いて、作成したコードワードが、各画像にどの程度表れるかを調べます。
def make_hist(vws, features):
hist = np.zeros(vws.shape[0])
for kp in features:
hist[((vws - kp)**2).sum(axis=1).argmin()] += 1
return hist
hist = make_hist(visual_words, features)
hist
array([107., 270., 277., 306., 170., 102., 162., 139., 136., 222., 151.,
206., 173., 289., 246., 314., 128., 236., 87., 142., 85., 167.,
167., 271., 184., 36., 131., 323., 258., 175., 269., 288., 180.,
213., 252., 131., 154., 263., 186., 99., 184., 179., 163., 237.,
133., 350., 107., 266., 209., 143., 85., 228., 191., 233., 166.,
29., 178., 186., 205., 213., 181., 248., 175., 114., 130., 165.,
221., 301., 281., 146., 252., 133., 67., 200., 60., 231., 142.,
148., 112., 198., 220., 387., 116., 198., 238., 107., 81., 143.,
175., 122., 125., 173., 158., 173., 154., 193., 124., 97., 353.,
204., 220., 120., 296., 467., 319., 270., 84., 207., 144., 160.,
116., 340., 149., 220., 136., 140., 185., 126., 261., 68., 108.,
70., 193., 165., 196., 118., 154., 211.])
ヒストグラムはこんな感じです。
plt.hist(hist, bins=len(hist), rwidth=0.5)
plt.show()
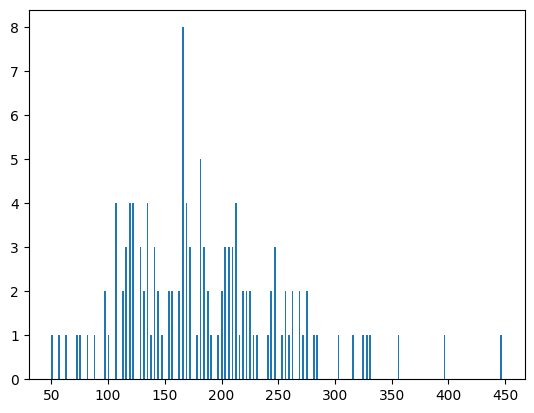
一連の流れはとりあえずこれで以上です。
これをクラス化してみます。
引数でクラスタの数、特徴量の種類、距離を測る計算式を選べるようにしてみました。
class FindNearImages():
def __init__(self, imgs_path, feature_method, n_clusters, metrics):
self.imgs_path = imgs_path # 使う画像のパス
self.feature_method = feature_method # 局所特徴の種類
self.n_clusters = n_clusters # クラスタ数
if self.feature_method == 0:
self.method = cv2.AKAZE_create()
elif self.feature_method == 1:
self.method = cv2.BRISK_create()
elif self.feature_method == 2:
self.method = cv2.SIFT_create()
self.metrics = metrics
self.files = glob.glob(self.imgs_path)
self.imgs = []
for n in tqdm(range(len(self.files))):
img = cv2.imread(self.files[n])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.imgs.append(img)
self.features = []
for img in tqdm(self.imgs):
self.features.extend(self.method.detectAndCompute(img, None)[1])
# 局所特徴の取得
def get_features(self, target_img):
return self.method.detectAndCompute(target_img, None)[1]
# コードワードの選定
def get_visual_words(self):
return MiniBatchKMeans(n_clusters=self.n_clusters).fit(self.features).cluster_centers_
# 調べたい画像内で、各コードワードがどのくらい出現しているか
def make_hist(self, visual_words, target_feature):
hist = np.zeros(visual_words.shape[0])
for feature in target_feature:
hist[((visual_words - feature) ** 2).sum(axis=1).argmin()] += 1
return hist
# 調べたい画像に似ている画像を表示する
def find_nears(self, visual_words, target_hist, n=5, verbose=False):
nears = []
## 表示用グリッド
fig = plt.figure(1, (12., 12.))
plt.title(f'similar_image_top{n}')
grid = ImageGrid(fig, 111,
nrows_ncols=(2, n//2+1),
axes_pad=0.1)
# すべての画像について似ているものリストを作成し、調べたい画像との距離を測る
nears = []
for i, path in tqdm(enumerate(self.imgs)):
# すべての画像について、比較用の似ているものリストを作成する
compare_feature = self.method.detectAndCompute(path, None)[1]
compare_hist = np.zeros(visual_words.shape[0])
for feature in compare_feature:
compare_hist[((visual_words - feature) ** 2).sum(axis=1).argmin()] += 1
# print(target_hist.shape, compare_hist.shape)
if self.metrics == 0: # 普通の距離
nears.append((((compare_hist - target_hist)**2).sum(), compare_hist, path))
elif self.metrics == 1: # カイ二乗カーネル
nears.append(((2 * (target_hist - compare_hist) ** 2).sum() / (target_hist + compare_hist).sum(), compare_hist, path)) # 通常はこの値を1から引くが、今回は距離が遠いほど大きい値にしたいので引かない
elif self.metrics == 2: # コサイン類似度
nears.append(((1 / cosine_similarity(target_hist.reshape(1, -1), compare_hist.reshape(1, -1)).sum()), compare_hist, path)) # 似ているほど値を小さくしたいので、逆数を取る。
nears.sort(key=lambda x:x[0])
nears = nears[:n]
# print('nears:', nears)
# 似ている画像の表示
for i in range(n):
print(nears[i][0])
grid[i].imshow(nears[i][2])
return nears
あとはこれを実行するだけです。
IMGS_PATH = "/content/drive/MyDrive/MyWorks/img/kaggle_dataset/PokemonImageDataset/images/images/*.png"
FEATURE_METHOD = 0
N_CLUSTERS = 128
METRICS = 0
find_near = FindNearImages(IMGS_PATH, FEATURE_METHOD, N_CLUSTERS, METRICS)
target_feature = find_near.get_features(imgs[0])
visual_words = find_near.get_visual_words()
target_hist = find_near.make_hist(visual_words=visual_words, target_feature=target_feature)
print(len(target_feature), visual_words.shape, len(target_hist))
# 似ている上位n位までの画像を出力
nears = find_near.find_nears(visual_words=visual_words, target_hist=target_hist, n=10, verbose=False)
# 調べたい画像と、上位3位までの似ている画像のヒストグラムを描画
fig = plt.figure(1, (12., 12.))
#グラフを描画するsubplot領域を作成。
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
ax1.hist(target_hist, bins=len(target_hist), rwidth=0.5)
ax2.hist(nears[0][1], bins=len(nears[0][1]), rwidth=0.5)
ax3.hist(nears[1][1], bins=len(nears[1][1]), rwidth=0.5)
ax4.hist(nears[2][1], bins=len(nears[2][1]), rwidth=0.5)
出力結果
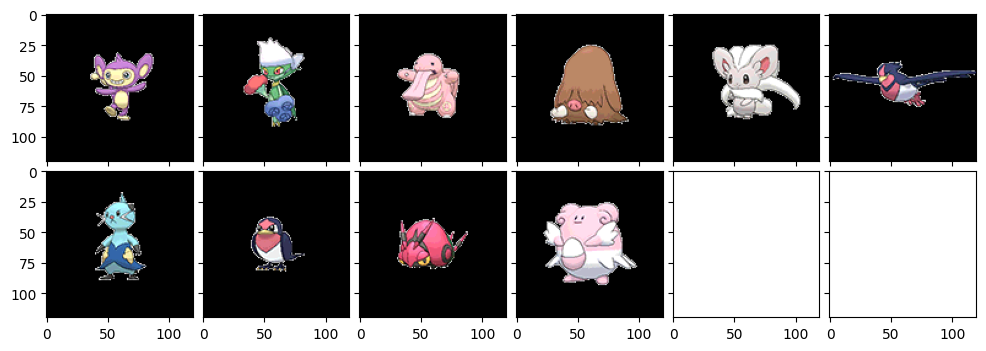
まずは先程のコード通りに出力したのがこちら。同じ画像を入力しても、k-meansの結果がその度に変わるので、レコメンドされる画像が多少変わります。一番左上の画像が、全く同じため最も似ている画像、要するに調べたいと入力したポケモンです。



やはり微妙に変わりますね。ノオーにはゴツイポケモンが似ていると判断されることが多いようです。ホエルオーがやけに強いですね。ドータクンは確かに形が似てるかもな。



チルタリスにはふわふわとしたポケモンが上位に来ているのがポイント高いです。やはりちゃんと特徴を検出できてるんだなーと思います。よくできた手法ですね。おっさんは確かに!色もフワフワ部分も似てる!!お見事!

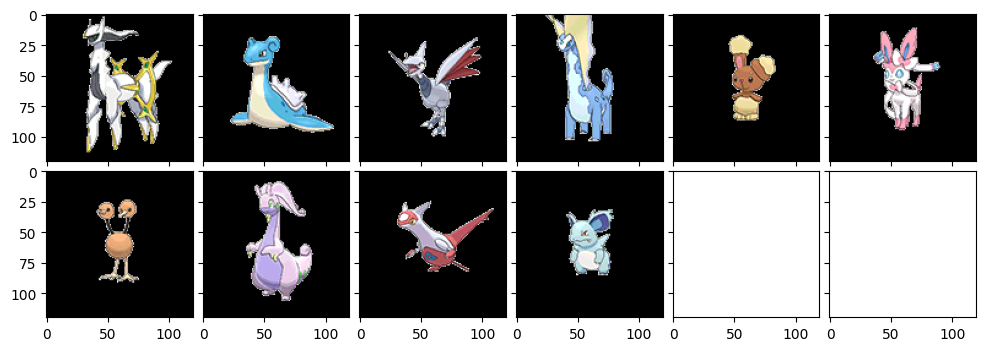
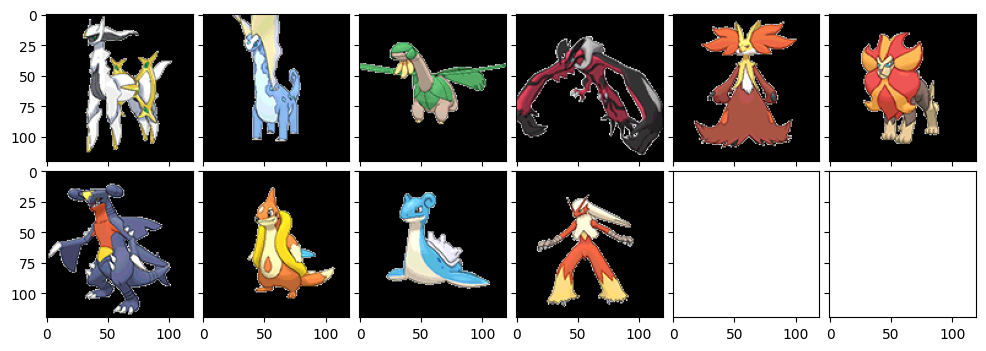
我らが神、アルセウスのご登場です。ミュウツ―やゼクロムなどが降臨するのはさすがっス!クロバットやエアームド、ラティアスは確かに形が似てるのかもです。ニンフィアは...四足歩行だからかな??(苦笑)
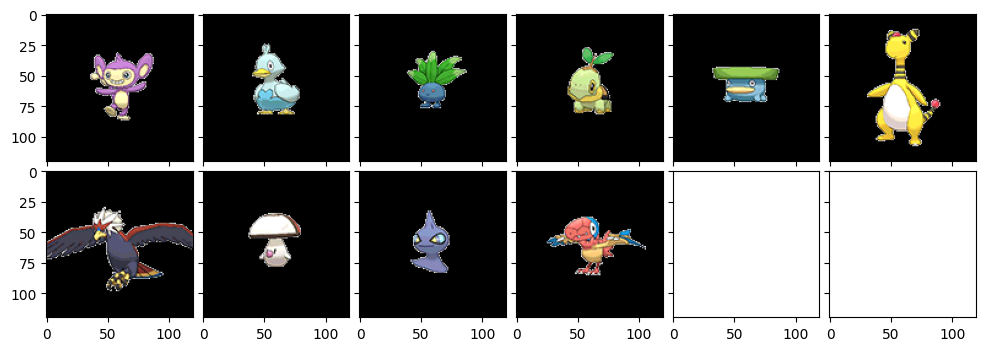
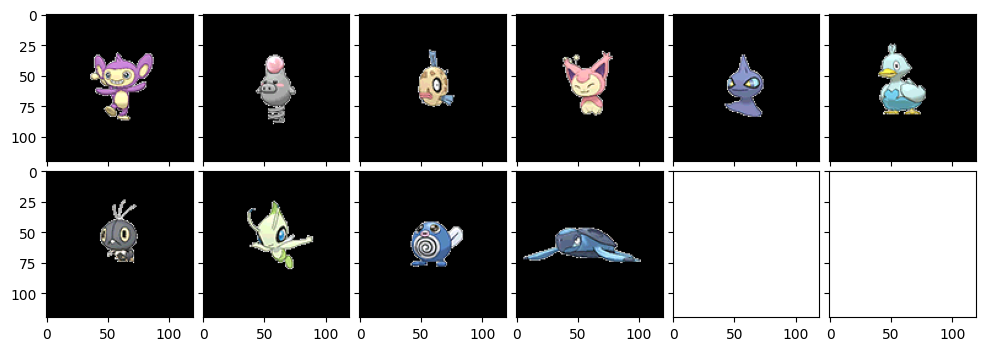
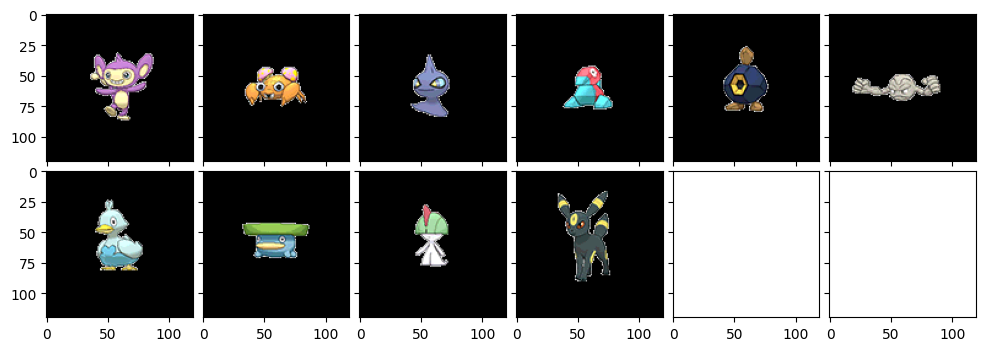
さて今度はめったに活躍機会のないエイ・パムおくんです。小柄なポケモンが出力されていますね~。コアルヒーが結構似てるんですね。
さて今度はクラスター数を32まで下げてみました。
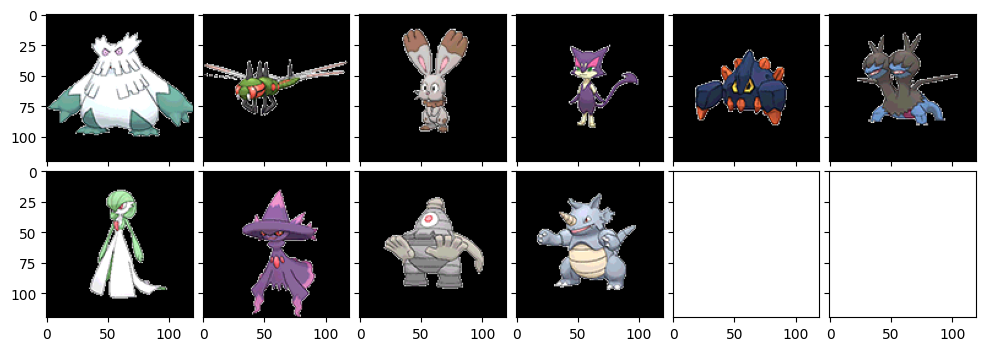
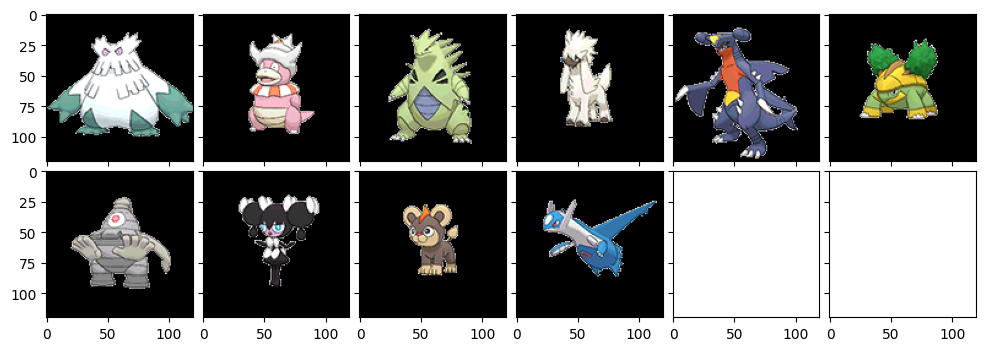

なんか少し毛色が変わりましたね。サイドンとかヤドキングとかバンギラスとか、トゲトゲしているポケモンが多く出てきている印象です。サマヨールとかも確かに似てるかもな。ホウオウとかまで出てきていますね。
エイパムについてもクラスター数32でやってみました。
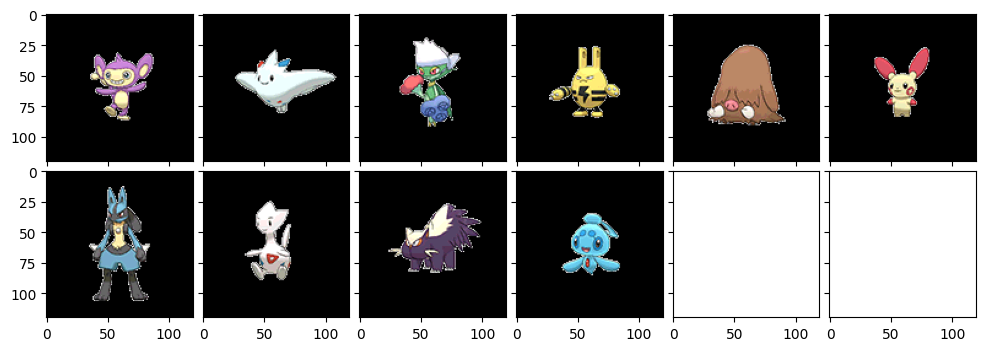
今回も小さめのポケモンが多いですが、進化系もチラホラ出てきています。確かにプラスルとかジュペッタとかカポエラーとか似てるかもな。
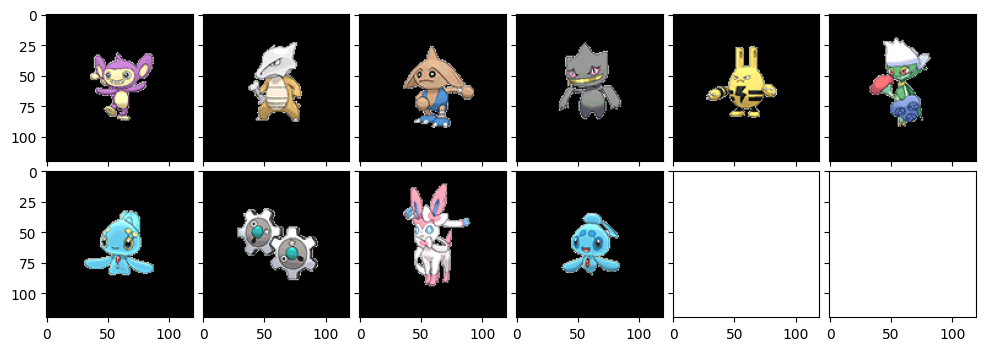
続いては、クラスター数128で、feature_methodを変えることで、抽出する局所特徴の種類を変えてみました。まずはcv2.BRISKというものです。

相変わらずゴツイゴツイ。ローブシンやヨノワールを引っ張り出してきたのはなかなかの功績じゃないですかね~。やはり局所特徴を変えると少し見方も変わるんですかね。
続いて有名なSIFT。

おお?やや小さいポケモンも出てきましたね。手足の向きを重要視している感じでしょうか。ゴツイ系をひたすら出力していたAKAZEくんとはまた違う趣ですね~。ニドクインやヤドラン、ツンベアーなどはたしかにな~という感じがしますが、やっぱり発展的な他の局所特徴と比べると見劣りするかな~?
今度はクラスター数128, feature_methodはデフォルトの0(AKAZE)で、類似度を計算する計算式を変えてみます。まずは、本来BoVWで使うものとされているカーネル関数。サポートベクターマシン(SVM)とかで出てくるヤツでしょうか。本当は最後に1から引く計算式なのですが、距離が遠いと値が大きくなるよう統一したかったので、実装の中では1からは引いていません。

うーん。ゴーリキーやゴローニャなど、こちらも手足の向きでしょうか。普通の距離(ユークリッド距離)の方が良い気もするなぁ~。
続いてコサイン類似度です。こちらも類似度計算では定番ですね。距離が遠いと値が大きくなるようにしたいので、逆数を取りました。



ゴツイポケモンが多いですが、先程とは少しメンツが違いますね~。特にブーバーン、ハピナス、ダストダス、ドータクンは似てますね~。ブーバーンなんで今まで出てこなかったんや・・・。というかダストダスの名前忘れててググりました(笑)
とこんな感じで、クラスター数や局所特徴の種類、距離の計算方法を少し変えるだけでも色々と結果が変わりました。面白いですね~。
最後に、調べたい画像と、上位3画像のヒストグラムも併せて出してみたのがこんな感じです。本当はヒストグラムもクラスの中で描画するようにしたかったのですが、類似画像と重なったりしてしまって、色々調べたけどダメでした(テヘッ
クラスター数: 128, 局所特徴: AKAZE, 距離の計算方法: コサイン類似度
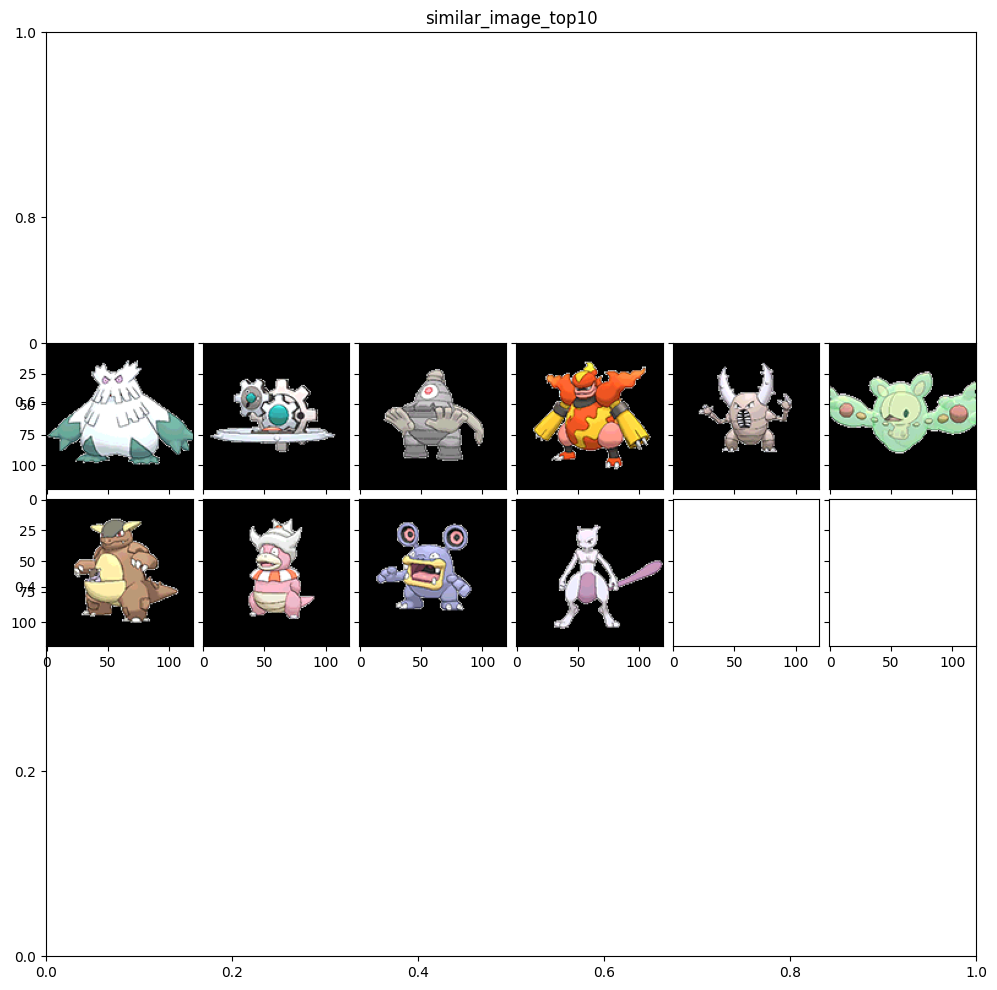
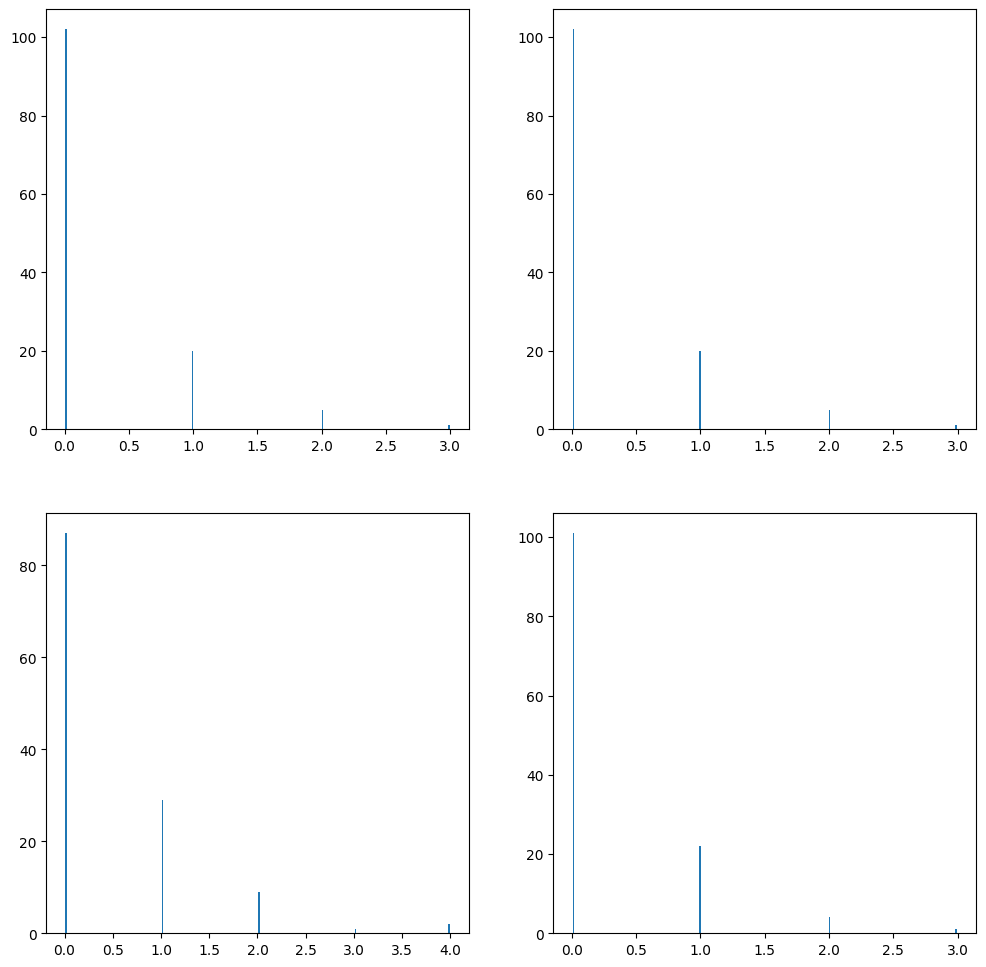
確かに類似度の高い画像はヒストグラムも似ているのですね!
というかガルーラとかランクルスとか似てるなおい!
おわりに
いやーBoWの画像版なんて余裕かと思いきや、難しそうな計算式が出てきたり実装手順が多かったり、クラスを組むまで整理できずコードがごちゃごちゃしたり、意外に苦戦しました。もう内部で計算してくれるライブラリに感謝感謝ですね。深層学習を使わずとも、こうしてレコメンドみたいに類似画像をバンバン出せるのは結構感動しました。しかもポケモンでやったのが良かったな(自画自賛)。これからもこういう深層学習以外の手法もどんどん深入りしていきたいですね~。数学とかできるようになれば自己流の手法も開発できるようになるんかな。
それではまた会う日まで。(♪蛍の光)
参考
・Bag Of Visual Wordsについて
『画像認識』 講談社 著:原田達也
https://blanktar.jp/blog/2016/03/python-visual-words
・matplotlib mpl_toolkits ImageGridについて
https://matplotlib.org/3.1.1/api/_as_gen/mpl_toolkits.axes_grid1.axes_grid.ImageGrid.html
・複数画像の読み込みと表示
https://python-debut.blogspot.com/2019/12/glob.html
・matplotlib 複数のグラフの描画
https://python-academia.com/matplotlib-multiplegraphs/
・matplotlib重ねずに別のグラフを表示する方法
https://teratail.com/questions/167002
・Akazeについて
https://www.pc-koubou.jp/magazine/43855
https://aicam.jp/tech/opencv3/akaze
・特徴量抽出法一覧
https://docs.opencv.org/3.4/d5/d51/group__features2d__main.html