HDP3の環境でSparkからHiveテーブルにアクセスする方法をご紹介します。
HDP以前のバージョンはSpark HiveContext/SparkSession を使ってHiveテーブルにアクセスしていますが、HDP3はHortonworksが開発したHive Warehouse Connector(HWC)を使ってアクセスすることができます。
以下の図の通り、HDP3でSparkとHiveそれぞれMetadataを持っています。お互いへのアクセスはHWC経由になります。
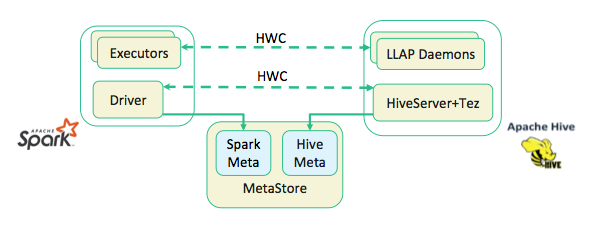
Hive Warehouse Connector
Hive LLAPを使ってSparkのDataFrameをHiveテーブルにWrite, HiveテーブルデータをDataFrameにReadするためのライブラリになっています。
Hive LLAPを有効にする必要があります。
HWCは以下のアプリケーションをサポートしています。
- Spark-shell
- Pyspark
- Spark-submit
使い方としてはこちらをご参照ください。
HiveWarehouseSession API operations
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.0.1/integrating-hive/content/hive_hivewarehousesession_api_operations.html
HWC使うための設定
設定手順は以下のリンクに詳しく書いてあります。
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.0.1/integrating-hive/content/hive_configure_a_spark_hive_connection.html
基本的にAmbariでCustom spark-2-defaultsに以下のプロパティを設定する
| Property | Description | Comments |
|---|---|---|
| spark.sql.hive.hiveserver2.jdbc.url | URL for HiveServer2 Interactive | In Ambari, copy the value from Services > Hive > Summary > HIVESERVER2 INTERACTIVE JDBC URL. |
| spark.datasource.hive.warehouse.metastoreUri | URI for metastore | Copy the value from hive.metastore.uris. For example, thrift://mycluster-1.com:9083. |
| spark.datasource.hive.warehouse.load.staging.dir | HDFS temp directory for batch writes to Hive | For example, /tmp. |
| spark.hadoop.hive.llap.daemon.service.hosts | Application name for LLAP service | Copy value from Advanced hive-interactive-site > hive.llap.daemon.service.hosts. |
| spark.hadoop.hive.zookeeper.quorum | Zookeeper hosts used by LLAP | Copy value from Advanced hive-sitehive.zookeeper.quorum. |
実際の設定画面です
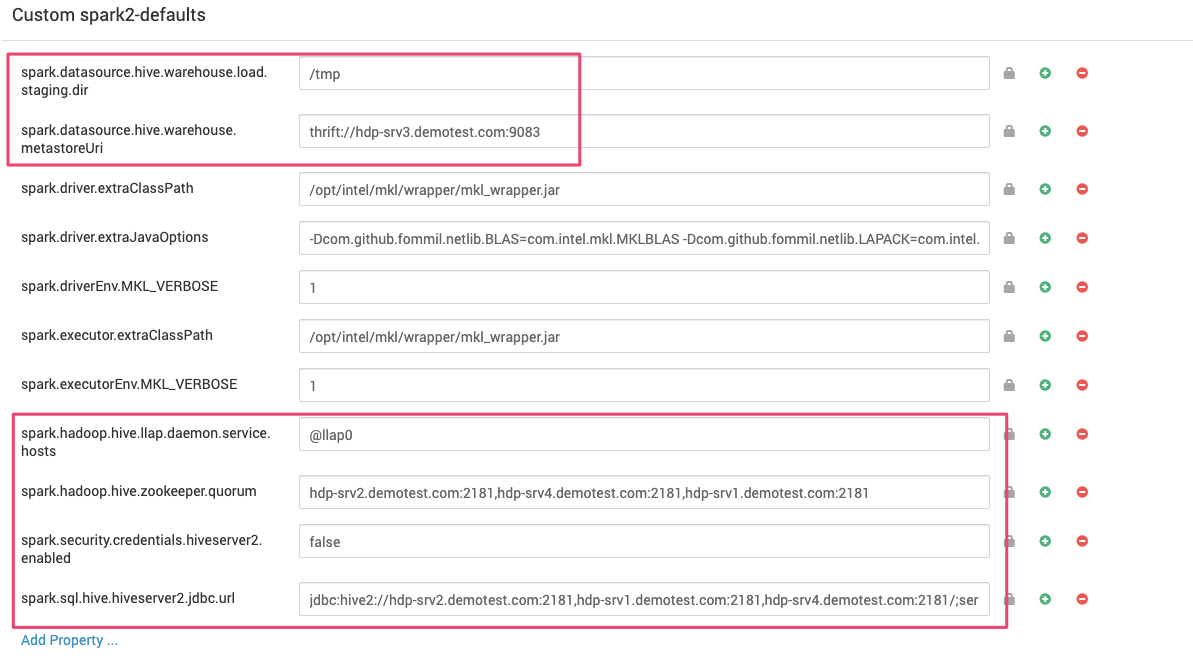
で、注意する必要があるのが、spark.sql.hive.hiveserver2.jdbc.urlです。
手順で直接Ambari上のHIVESERVER2 INTERACTIVE JDBC URLをコピーするってかいてありますが、実行時にPermission Errorのエラーが表示される場合があります。
例えばPysparkの場合
pyspark --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-1.0.0.3.1.0.0-78.jar --py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-1.0.0.3.1.0.0-78.zip
Error
py4j.protocol.Py4JJavaError: An error occurred while calling o72.executeQuery.
: java.lang.RuntimeException: java.io.IOException: shadehive.org.apache.hive.service.cli.HiveSQLException: java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to compile query: org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAccessControlException: Permission denied: user [anonymous] does not have [USE] privilege on [default]
at com.hortonworks.spark.sql.hive.llap.HiveWarehouseDataSourceReader.readSchema(HiveWarehouseDataSourceReader.java:130)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation$.apply(DataSourceV2Relation.scala:56)
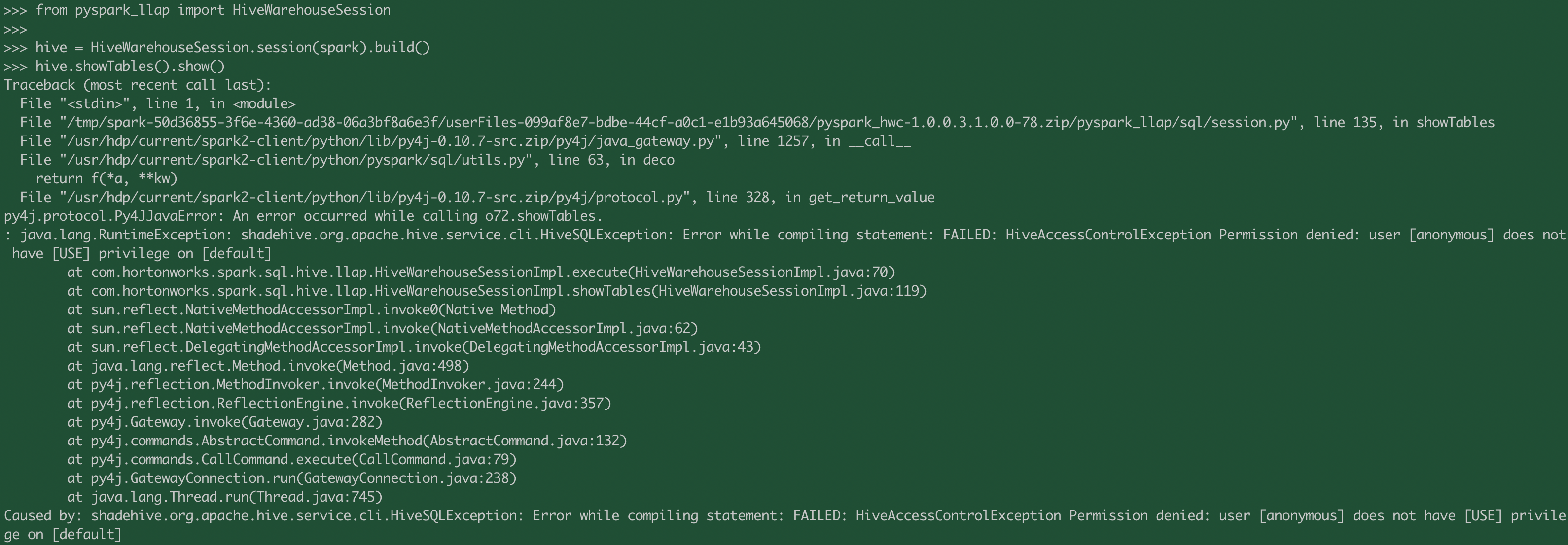
解決策2つがあります。
1, HIVESERVER2 INTERACTIVE JDBC URLの後ろにユーザーを指定する。例えばuser=hive
jdbc:hive2://hdp-srv2.demotest.com:2181,hdp-srv1.demotest.com:2181,hdp-srv4.demotest.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive;user=hive
2, コードの中にHiveWarehouseSession作成時にユーザーを指定する。例:.userPassword('hive','hive')
ソースコードからヒントを得ました。
https://github.com/hortonworks/hive-warehouse-connector/blob/HDP-3.1.0.158/python/pyspark_llap/sql/session.py
from pyspark_llap import HiveWarehouseSession
hive = HiveWarehouseSession.session(spark).userPassword('hive','hive').build()
hive.setDatabase("default")
hive.executeQuery("select * from test_table").show()
hive.showTables().show()
hive.showDatabases().show()
Zeppelin Spark Interpreterから接続する際の設定
ZeppelinからHiveにアクセスする場合もZeppelin側での設定が必要です。
詳細の設定はこちら
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.0.1/integrating-hive/content/hive_zeppelin_configuration_hivewarehouseconnector.html
設定例

ただし、実際にコード実行したら、以下のように pyspark_llapモジュールが見つかりません というエラーが出力されます。
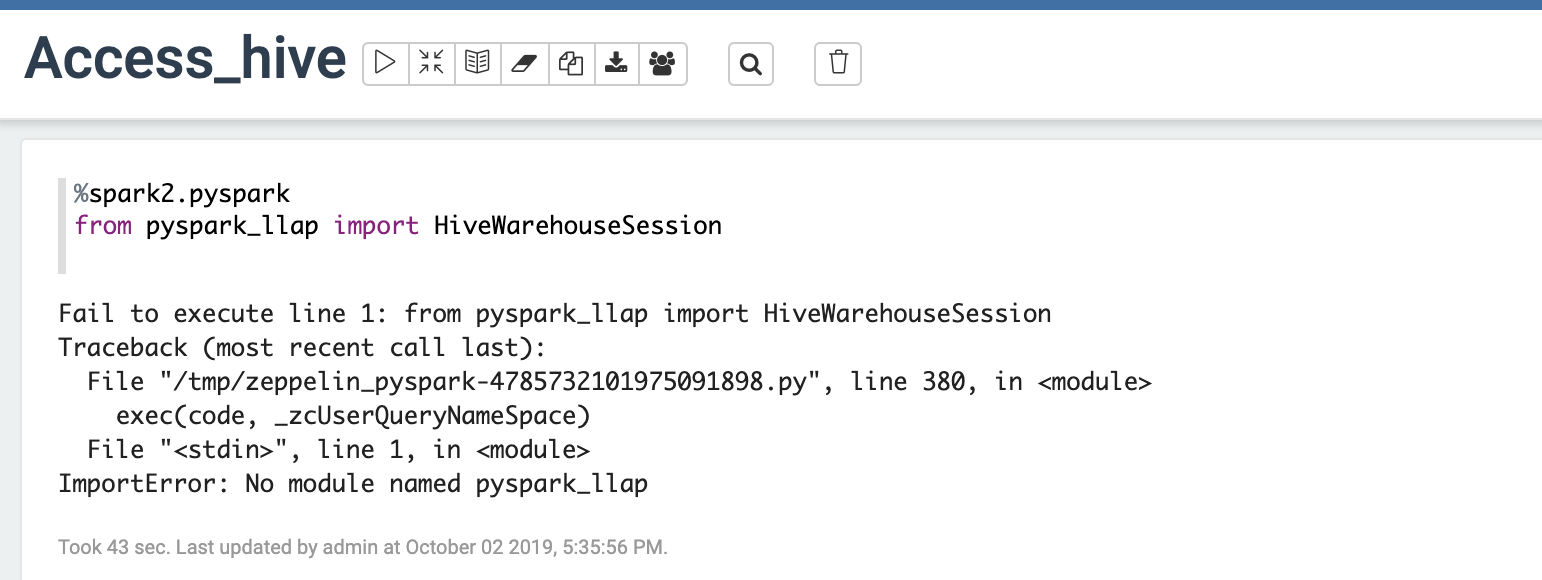
調べたところ、Zeppelin側でspark.submit.pyfilesの設定がうまく動作しないバグがあるらしい。
回避策として、コートの中に直接モジュールファイルをインポートする。
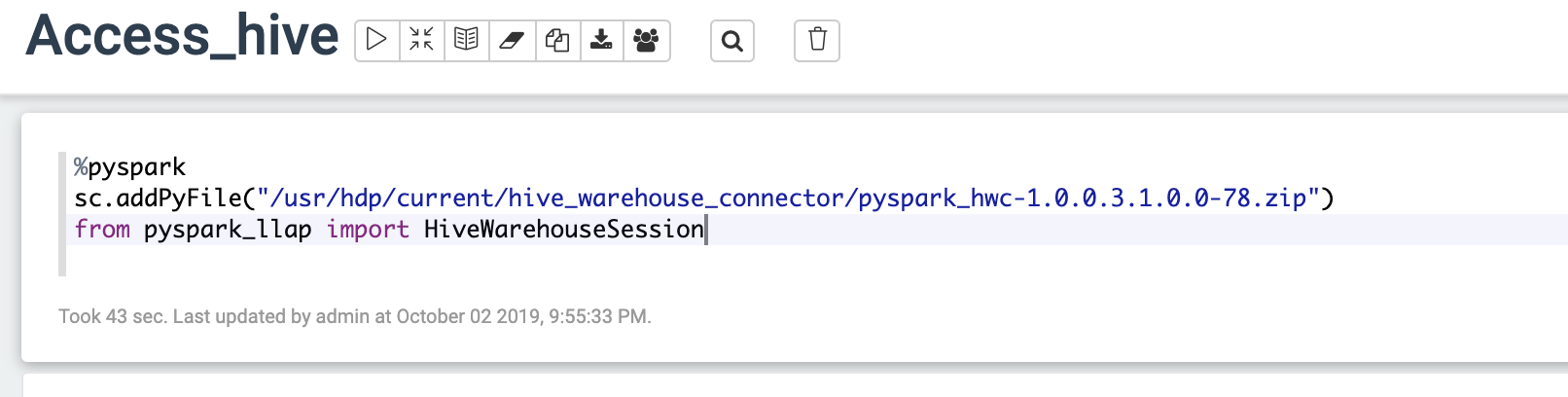
これでspark-shell, pyspark, zeppelinから使えるようになります。