はじめに
Kaggleの登竜門、タイタニックコンペ。
特徴量エンジニアリングを試したり、ハイパーパラメータを調整したり、新しいモデルを使ってみたりと、試行錯誤を繰り返しているうちに、こんな経験はありませんか?
- 「
Ageの欠損値を平均で埋めた時と、中央値で埋めた時、どっちがスコア良かったっけ?」 - 「
n_estimatorsを100から200に増やしたNotebookはどれだ?」 - 「たくさん作った
submission.csv、どれがベストスコアのモデルから出力したものか分からない…」
そんな「実験カオス」状態をスマートに解決するのが、今回紹介するMLflowです!
この記事では、タイタニックのデータセットを使い、MLflowで実験管理を行う具体的な手順を、分かりやすく解説します。
MLflowとは?
MLflowは、機械学習のライフサイクル全体を管理するためのオープンソースプラットフォームです。その中核機能である「MLflow Tracking」を使うと、Jupyter Notebook上で行う実験の情報を簡単に記録・比較できます。
-
Parameters:
max_depthやn_estimatorsなどのハイパーパラメータ -
Metrics:
AccuracyやAUCなどの評価指標 - Artifacts: 学習済みモデル、特徴量の重要度プロットなど
- Dataset / Version: 使用したデータとコードのバージョン(再現性担保のため)
これらを一元管理することで、「どの試行が」「どんな結果だったのか」が一目瞭然になります。
準備:検証環境とライブラリのインストール
本記事のコードは、以下の環境で動作確認を行っています。
- Python: 3.11
- MLflow: 3.x
まずは、必要なライブラリをインストールします。また、Kaggleのタイタニックコンペのページ からデータセット(train.csv)をダウンロードし、Jupyter Notebookと同じディレクトリに配置してください。
pip install mlflow scikit-learn pandas
実践:タイタニックのデータで実験管理
それでは、実際にJupyter Notebook上でMLflowを使ってみましょう。
今回は、RandomForestClassifierのハイパーパラメータn_estimatorsとmax_depthを変えながら、精度がどう変化するかを記録していきます。
1. ライブラリのインポートとデータ読み込み
import pandas as pd
import mlflow
import mlflow.sklearn
import mlflow.data # データセット記録用
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# データの読み込み
train_df = pd.read_csv("train.csv")
2. 簡単な前処理
記事の主題はMLflowなので、前処理はシンプルに済ませます。
Sexを数値に変換し、Ageの欠損値を中央値で補完します。(※近年のPandasの推奨に合わせ、inplace=Trueは使用せずに記述します)
# 特徴量とターゲットの選択
features = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]
target = "Survived"
# Sexを数値に変換
train_df["Sex"] = train_df["Sex"].map({"male": 0, "female": 1})
# Ageの欠損値を中央値で補完
train_df["Age"] = train_df["Age"].fillna(train_df["Age"].median())
# 不要な行(特徴量に欠損がある場合)を削除
train_df = train_df.dropna(subset=features)
X = train_df[features]
y = train_df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
3. MLflowで実験を実行・記録
with mlflow.start_run():ブロックを使い、ハイパーパラメータを変えながら実験をループ実行します。
ここでは、後から画面で見たときに分かりやすいよう、「実験名」「説明」「データセット」「コードのバージョン」を記録する書き方をご紹介します。
# 試したいハイパーパラメータのリスト
n_estimators_list = [50, 100, 200]
max_depth_list = [5, 10, 15]
# 実験のバージョン管理用(Notebookを更新するたびに手動で変えると便利です)
CODE_VERSION = "v1.0.0"
for n_estimators in n_estimators_list:
for max_depth in max_depth_list:
# 1. 一覧でパッと見でわかる実験名(Run Name)にする(※文字化け防止のため英数字推奨)
my_run_name = f"rf_n{n_estimators}_d{max_depth}"
with mlflow.start_run(run_name=my_run_name):
# 2. Description(説明)にメモを残す
description_text = f"model: RandomForest, n_estimators: {n_estimators}, max_depth: {max_depth}"
mlflow.set_tag("mlflow.note.content", description_text)
# 3. Dataset(データセット)の記録
# 今回使ったX_trainのスキーマ(構造)を記録しておく
dataset = mlflow.data.from_pandas(X_train, source="train.csv", name="titanic_train_data")
mlflow.log_input(dataset, context="training")
# 4. Version(バージョン)の記録
mlflow.set_tag("code_version", CODE_VERSION)
# 5. パラメータを辞書型で一括記録
params = {
"n_estimators": n_estimators,
"max_depth": max_depth
}
mlflow.log_params(params)
# モデルの学習
model = RandomForestClassifier(**params, random_state=42)
model.fit(X_train, y_train)
# 評価
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
# 6. メトリクスとモデル(Artifact)の記録
mlflow.log_metric("accuracy", acc)
mlflow.sklearn.log_model(model, name="random_forest_model")
print(f"[{my_run_name} | Ver:{CODE_VERSION}] Accuracy: {acc:.4f} で完了しました!")
print("実験が完了しました。")
このコードを実行すると、Notebookと同じ階層にmlrunsというフォルダが作成され、その中に結果が保存されていきます。
結果の確認:MLflow UIで一目瞭然!
記録した結果は、MLflowのUI(Web画面)で確認します。
ターミナルを開き、Jupyter Notebookを実行しているディレクトリで以下のコマンドを実行してください。
mlflow ui
ブラウザで http://127.0.0.1:5000 にアクセスすると、MLflowのダッシュボードが以下のように表示されます。
▼ MLflow 3.x のトップ画面
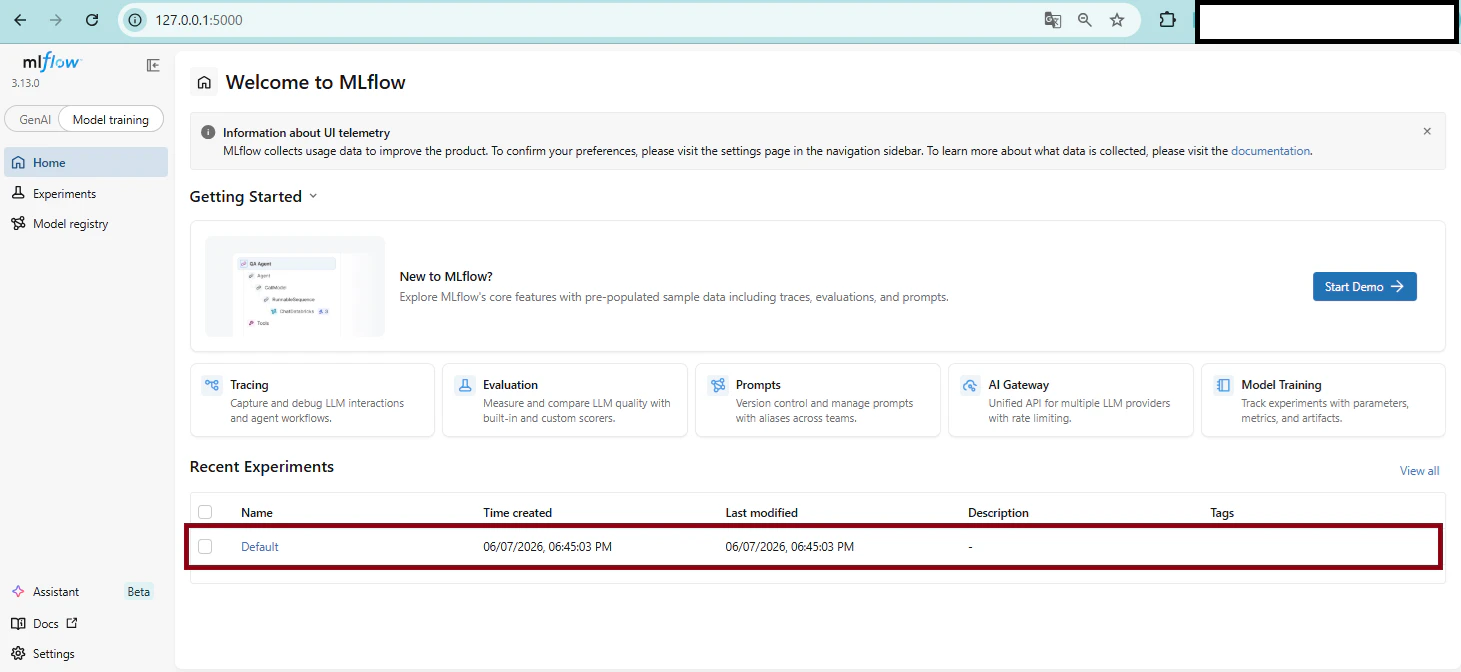
画面左側のメニューから Experiments を開き、赤枠の Default のリンクをクリックすると、今回の実験結果(Run)が一覧で表示されます。
▼ 実験結果(Runs)の一覧画面
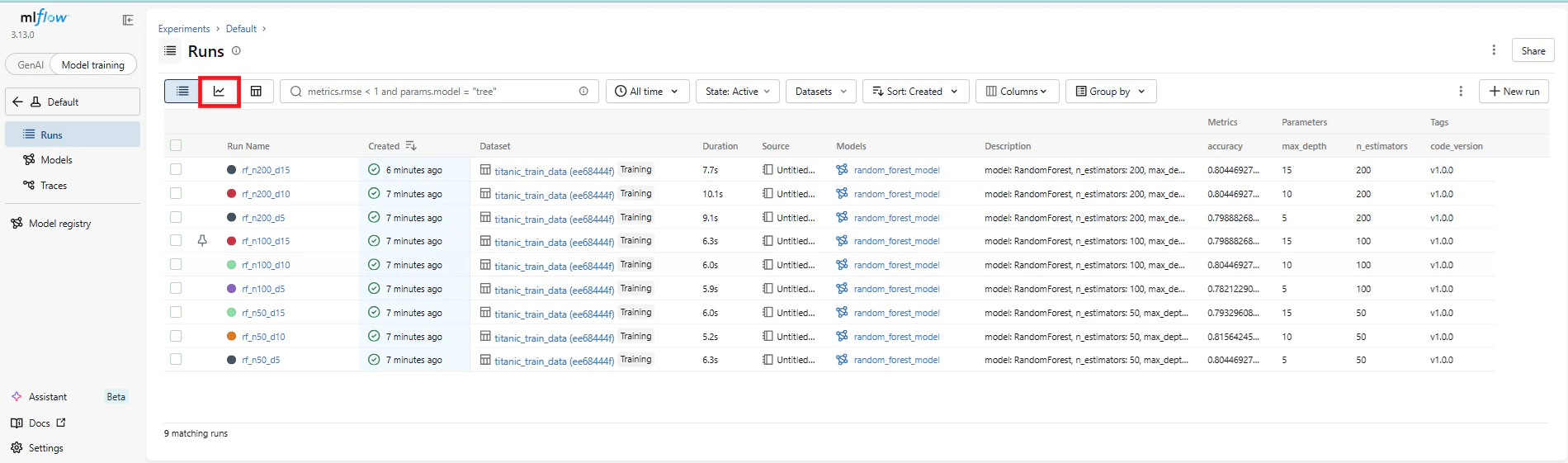
さらに、リスト上部の「グラフ」のアイコン(Chart view)をクリックすると、各パラメータと精度の関係を視覚的に分析できるグラフ画面に切り替わります。
▼ グラフ表示画面(Scatter Plotの例)
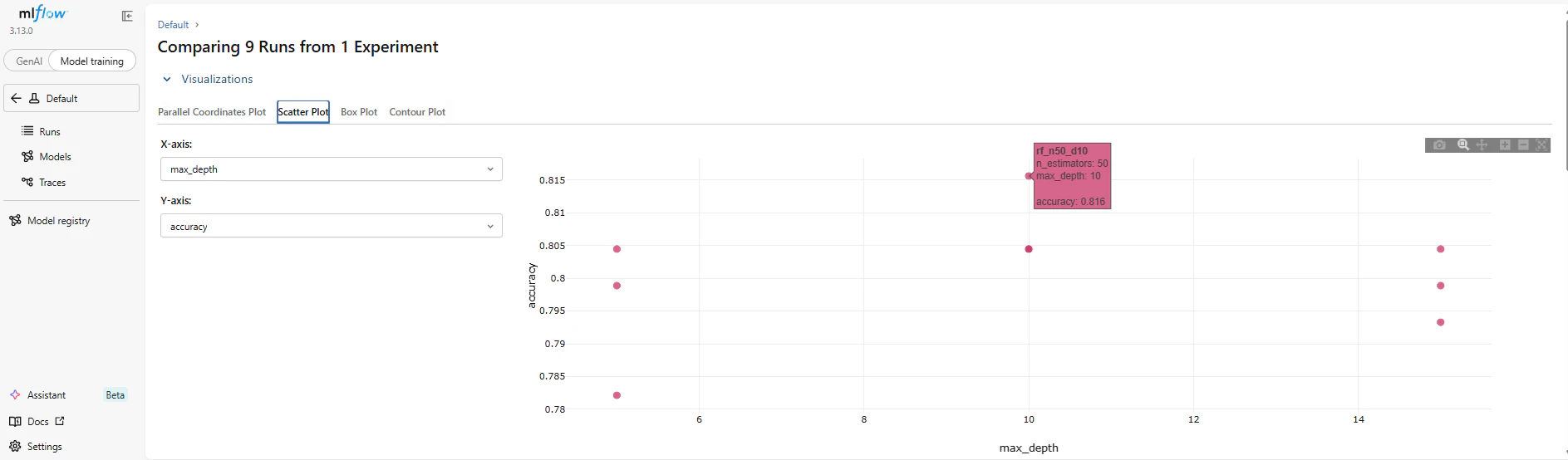
【注意】MLflow 3.xでの画面の見方
MLflow 3.x以降では、UI画面の左上で「GenAI(生成AI)」と「Model training(従来の機械学習)」のタブが分かれています。
初期状態で「GenAI」が開いている場合があるため、以下の手順で結果を確認してください。
- 画面左上から
Model trainingタブを選択する。 - 左メニューの
Experimentsをクリックし、Defaultを選択する。 - 今回実行した実験の一覧が表示されます!
画面上で確認すべき3つのポイント
無事に一覧画面が開けたら、今回コードに仕込んだ工夫がどう反映されているか見てみましょう。ただ記録するだけだった時と比べて、格段に分析しやすくなっているはずです。
-
Run NameとDescription: ランダムな名前ではなく「rf_n50_d10」のように表示され、行をクリックすると設定した詳細なメモが確認できます。
-
Accuracyでソート: カラム名をクリックして並び替えれば、ベストなハイパーパラメータが一瞬で分かります。
-
データセットとバージョンの確認: 右上の「Columns」ボタンを押し、
code_versionにチェックを入れるとバージョンが一覧に表示されます。また、行をクリックして詳細を見ると「Inputs」の欄にデータセット情報が保存されています。
まとめ
今回は、Kaggleのタイタニック問題を例に、MLflowを使った実践的な実験管理の方法をご紹介しました。
「実験カオス」を抜け出し、スマートに解析を進めるための重要なポイントを3つにまとめます。
mlflow.start_run(run_name=...)でわかりやすい名前をつける。- パラメータや評価指標だけでなく、DatasetやVersionも記録して再現性を担保する。
- 結果は
mlflow uiで一覧表示し、ソート機能でベストな実験をすぐに見つける。
この簡単なステップだけで、あなたのKaggleライフは劇的に整理され、より本質的なモデル改善の試行錯誤に集中できるようになります。
タイタニックで実験管理に慣れたら、ぜひコンペに挑戦してMLflowを活用してみてください!
参考リンク・さらに学びたい方へ
この記事ではKaggleでの個人利用にフォーカスして解説しましたが、MLflowには「複数人でのサーバー共有」や「モデルのデプロイ」など、実務で役立つ強力な機能がまだまだたくさんあります。
さらに使いこなしたい方は、ぜひ公式ドキュメントを覗いてみてください!