はじめに
個人用のChrome拡張を作っていたとき、記事タイトルから単語を抽出してユーザーの興味傾向を学習する機能が必要になりました。
kuromoji.jsなどの外部形態素解析ライブラリを拡張に同梱するのはファイルサイズが大きいと感じ、もう少し手軽な方法がないかと調べていたところ、Intl.Segmenter というブラウザ標準APIで要件を満たせることがわかりました。
const segmenter = new Intl.Segmenter('ja', { granularity: 'word' });
const words = [];
for (const segment of segmenter.segment(title)) {
if (segment.isWordLike) words.push(segment.segment);
}
わずか数行で日本語の単語分割ができました。外部ライブラリも辞書データも一切不要です。
本記事では
このAPIから取得できる情報を網羅的に整理し、Chrome拡張に組み込むうえでの精度とパフォーマンスをまとめてみました。
Intl.Segmenter とは
Intl.Segmenter はECMAScript Internationalization API(ECMA-402)の一部として定義されたテキスト分割APIです。
Unicode Text Segmentation(UAX #29)のアルゴリズムに基づき、ロケール対応の文字列分割を行います。
Chrome 87(2020年)からフラグなしで使用でき、現在はEdge・Safari・Firefoxといった主要ブラウザでサポートされています。
コンストラクタ
第1引数にBCP 47言語タグ('ja' など)、第2引数のオプションで granularity を指定します。
granularity は 'grapheme' / 'word' / 'sentence' の3種類で、省略時は 'grapheme' になります。
const segmenter = new Intl.Segmenter('ja', { granularity: 'word' });
resolvedOptions() で実際に適用されたオプションを確認できます。
console.log(segmenter.resolvedOptions());
// { locale: 'ja', granularity: 'word' }
segment() の戻り値
segment() はイテラブルオブジェクトを返します。各セグメントは segment(文字列本体)・index(開始位置)・input(元の入力文字列全体)の3つのプロパティを持ちます。
word granularityのときだけ、語かどうかを示す isWordLike(boolean)が追加されます。
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
for (const s of seg.segment('東京タワーへ行く。')) {
console.log(s);
}
ChromeのConsoleで実行した結果は以下の通りです。
{ segment: '東京タワー', index: 0, input: '東京タワーへ行く。', isWordLike: true }
{ segment: 'へ', index: 5, input: '東京タワーへ行く。', isWordLike: true }
{ segment: '行く', index: 6, input: '東京タワーへ行く。', isWordLike: true }
{ segment: '。', index: 8, input: '東京タワーへ行く。', isWordLike: false }
助詞「へ」もそれ自体がひとつのセグメントとして抽出され、isWordLike は true で返ってきました。
句読点「。」だけが isWordLike: false となっています。
isWordLike: false になるのは主に句読点・空白・記号です。
形態素解析ライブラリのような品詞(名詞/動詞/助詞…)情報は取得できないため、isWordLike だけでは助詞と一般名詞を区別することはできません。
granularity別の動作を見てみる
grapheme - ユーザー知覚文字単位
最小単位の分割です。絵文字の合成シーケンス(ZWJ結合など)も1セグメントにまとめてくれます。
const seg = new Intl.Segmenter('ja', { granularity: 'grapheme' });
const result = Array.from(seg.segment('👨👩👧á'));
[...text] のようなスプレッドや split('') ではZWJ絵文字が分解されてしまいますが、grapheme granularityを使うと正確に1文字として扱えます。
word - 単語・形態素単位
日本語テキストに最もよく使うのがこちらです。isWordLike フラグで語と非語を区別できます。
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
const text = '機械学習モデルのファインチューニングにはGPUが必要です。';
for (const s of seg.segment(text)) {
if (s.isWordLike) console.log(`"${s.segment}" [${s.index}..${s.index + s.segment.length - 1}]`);
}
"機械学習" [0..3]
"モデル" [4..6]
"ファインチューニング" [8..17]
"GPU" [20..22]
"が" [23..23]
"必要" [24..25]
"です" [26..27]
出力からわかる通り、品詞による分類はされておらず、助詞「が」や助動詞「です」も isWordLike: true の語として含まれます。
助詞・助動詞を除外したい場合は、文字数や別途用意した助詞リストでフィルタする必要があります。
sentence - 文単位
テキストを文に分割します。日本語では、句点・感嘆符・疑問符(。!?)や改行で区切られます。
const seg = new Intl.Segmenter('ja', { granularity: 'sentence' });
const text = '吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。';
for (const s of seg.segment(text)) {
console.log(`[${s.index}] "${s.segment.trim()}"`);
}
[0] "吾輩は猫である。"
[8] "名前はまだ無い。"
[16] "どこで生れたかとんと見当がつかぬ。"
精度を確認してみる
代表的なケースで、どのように分割されるのかを確認してみました。
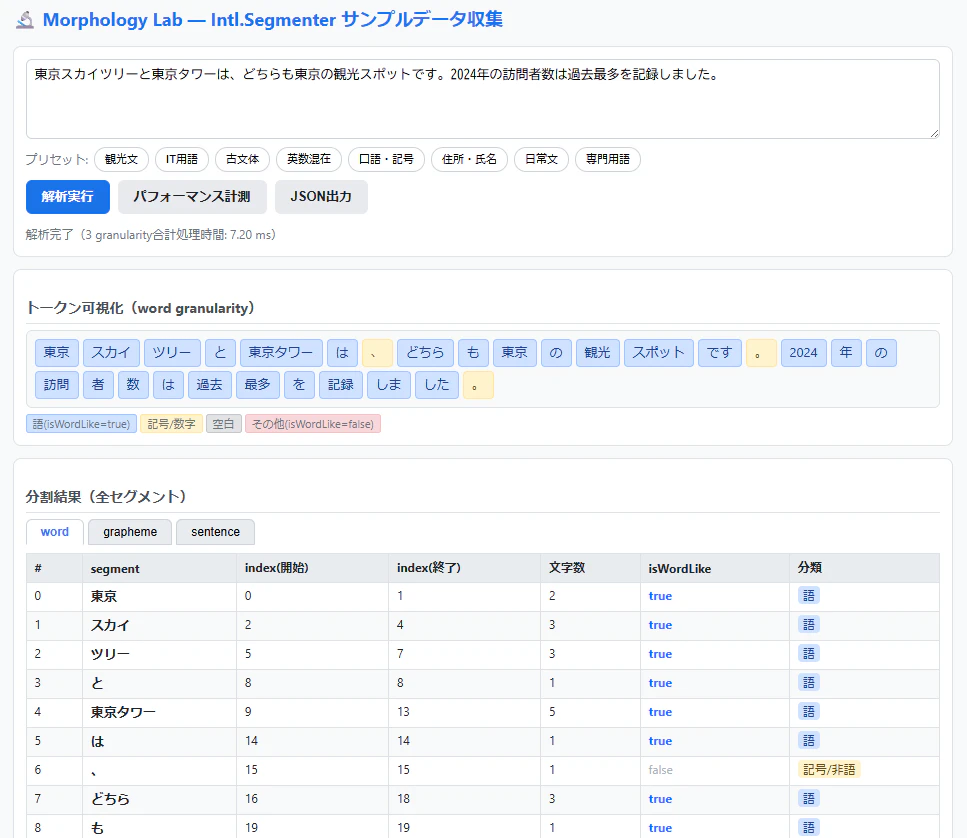
ケース1: 固有名詞・複合語
const texts = [
'東京スカイツリーと東京タワー', // 観光地名
'株式会社フューチャーアーティザン', // 会社名
'新型コロナウイルス感染症対策本部', // 行政用語
'渋谷駅東口バスターミナル', // 複合地名
];
抽出された語(isWordLike: true のもの)と所感は以下の通りです。
-
東京スカイツリーと東京タワー →
東京スカイツリー/東京タワー:複合固有名詞を正しく結合できた -
株式会社フューチャーアーティザン →
株式会社/フューチャーアーティザン:自然な分割 -
新型コロナウイルス感染症対策本部 →
新型コロナウイルス/感染症/対策本部:「感染症対策本部」までは結合されなかった -
渋谷駅東口バスターミナル →
渋谷/駅/東口/バスターミナル:駅名としての結合は期待できなかった
辞書ベースではないため、固有名詞でも単語の組み合わせとして自然に切られる傾向があります。
ケース2: 英数字混在
'iPhone15ProはA17 Proチップを搭載し、USB-C端子に対応した。'
iPhone15Pro A17 Pro といった英数字混じりの製品名は概ね正しく扱われましたが、「USB-C」のようにハイフンで結合された語は USB / - / C に分割されました。
ケース3: 口語・記号・絵文字
'ありがとうございます!本当にうれしいです(^▽^)また会いましょう~'
顔文字部分((^▽^))は記号の連続として認識され、isWordLike: false の細かいセグメントに分解されました。
顔文字を一括で扱いたい場合は別途フィルタリング処理が必要になります。
ケース4: 専門用語・未知語
'ペルフルオロアルキルスルホン酸化合物(PFAS)の環境汚染が問題視されている。'
辞書に存在しない非常に長いカタカナ語でも、ひとまとまりの isWordLike: true セグメントとして扱われました。
但し、この挙動はChromeのバージョンによって異なる可能性が高いです。
Intl.Segmenter は辞書不要ですが、専門用語や複合語のまとまりには期待通りにならない場合があります。
精度の総評
ここまでのケースを観点ごとに整理すると以下の通りです。
| 観点 | Intl.Segmenter | kuromoji.js(参考) |
|---|---|---|
| 固有名詞・複合語 | △(文脈依存、やや分割過多) | ◯(辞書登録語は正確) |
| 未知語・新語 | ◯(分割せず保持) | △(未登録語は1文字ずつになることも) |
| 英数字混在 | ◯ | ◯ |
| 品詞情報 | ✗(取得不可) | ◯(名詞/動詞/助詞…) |
| ライブラリ不要 | ◯ | ✗(辞書込みで数MB〜) |
| Service Worker対応 | ◯ | ✗(DOM API依存の場合あり) |
パフォーマンスを測ってみる
計測方法
Intl.Segmenter のインスタンス生成と分割処理は別々にコストがかかるため、segment() の呼び出し時間のみを取得するように計測しました。
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
const text = '東京スカイツリーと東京タワーは、どちらも東京の観光スポットです。2024年の訪問者数は過去最多を記録しました。'; // 55文字
const N = 1000;
const t0 = performance.now();
for (let i = 0; i < N; i++) Array.from(seg.segment(text));
const elapsed = performance.now() - t0;
console.log(`1回あたり: ${(elapsed / N * 1000).toFixed(1)} µs`);
計測結果
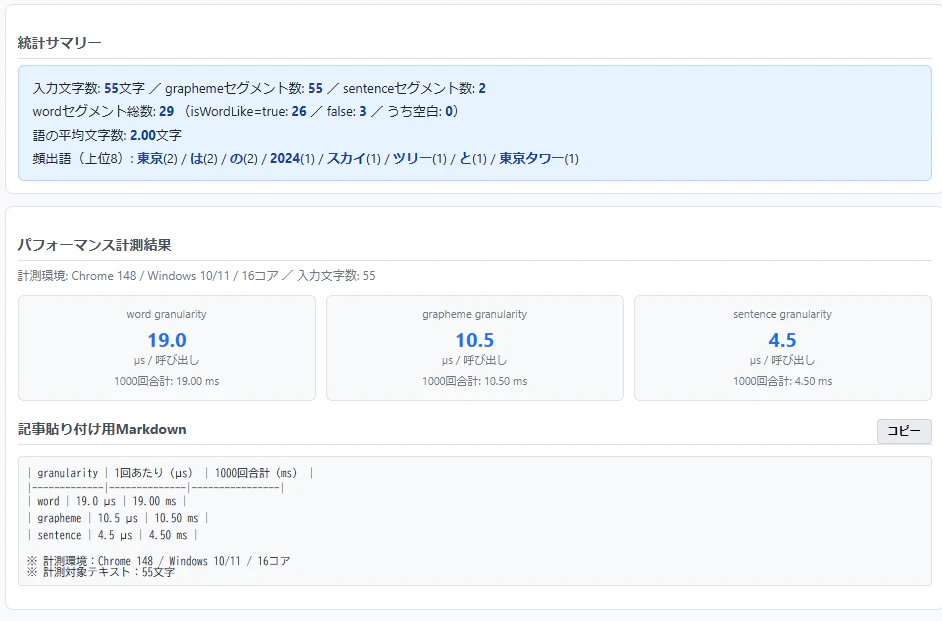
自作の拡張機能を用いて、55文字の文章を1000回処理した結果は以下の通りです。
| granularity | 1回あたり(µs) | 1000回合計(ms) |
|---|---|---|
| word | 19.0 µs | 19.00 ms |
| grapheme | 10.5 µs | 10.50 ms |
| sentence | 4.5 µs | 4.50 ms |
※ 計測環境:Chrome 148 / Windows 11 / 16コア
※ 計測対象テキスト:55文字
※ 処理時間は入力文字数におおよそ比例して増加します。
インスタンスの生成コストに注意
Intl.Segmenter のコンストラクタはロケールデータの初期化を伴うため、segment() 本体より生成コストが大きくなります。
ループ内で毎回 new するのは避け、外側で一度だけ生成して使い回すようにします。
// NG: ループ内で毎回生成
items.forEach(title => {
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
for (const s of seg.segment(title)) { ... }
});
// OK: 事前に生成して使い回す
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
items.forEach(title => {
for (const s of seg.segment(title)) { ... }
});
Array.from vs for...of
全セグメントを後段で参照したい場合は Array.from() で配列化、単語フィルタだけなら for...of のほうがメモリ効率が良いです。
// for...of(遅延評価・省メモリ)
for (const s of seg.segment(text)) {
if (s.isWordLike) words.push(s.segment);
}
// Array.from(一括展開・全セグメントをメモリに保持)
const all = Array.from(seg.segment(text));
実装上のポイント
Service Workerでも使える
Manifest V3のService WorkerはDOMを持たないため DOMParser が使えませんが、Intl.Segmenter はグローバルスコープで問題なく動作しました。
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
chrome.runtime.onMessage.addListener((msg) => {
const words = [];
for (const s of seg.segment(msg.text)) {
// 文字数1の語(助詞など)を簡易的に除外
if (s.isWordLike && s.segment.length > 1) words.push(s.segment);
}
return words;
});
私の拡張では上記のように、長さ1の語を除外することで、助詞「が」「を」「は」などを簡易的にフィルタしています。
品詞情報が取れない Intl.Segmenter では、文字数フィルタが最も手軽な後処理ですが、「猫」など一文字の一般名詞なども弾かれることとなるため、実運用上は別の方法が必要です。
インデックス情報の活用
index プロパティを使うと、セグメントの位置情報を元にハイライト表示なども実装できます。
function highlightWords(text, keywords) {
const seg = new Intl.Segmenter('ja', { granularity: 'word' });
const keySet = new Set(keywords);
let result = '';
for (const s of seg.segment(text)) {
if (s.isWordLike && keySet.has(s.segment)) {
result += `<mark>${s.segment}</mark>`;
} else {
result += s.segment;
}
}
return result;
}
※実運用ではHTMLエスケープも必要です
さいごに
Intl.Segmenter を使うと、外部ライブラリなしでブラウザだけで日本語の単語分割ができることがわかりました。
取得できる情報は segment(文字列本体)・index(開始位置)・input(元の入力)・isWordLike(word のみ)の4つです。
品詞・読み・原形といった情報は取得できないため、単語頻度の集計やキーワード抽出・ハイライト表示といったシンプルな用途に向いています。
私自身、Chrome拡張のタイトルから興味語を抽出する用途では Intl.Segmenter で十分でした。
文字数1の語を除外するだけで助詞や記号がある程度フィルタでき、辞書ファイルの読み込みコストもないため、Service Worker内でも軽快に動いてくれています。
品詞レベルの処理が必要な場面ではkuromoji.jsなどとの使い分けになりますが、組み込みコストの低さは大きな利点です。軽量な単語処理を考えている方は試してみていただけると嬉しいです。