この記事は インフォマティカ Advent Calender 2025 Day 4 の記事として書かれています。
はじめに: 生成AIのハルシネーションとビジネスリスク
近年、ChatGPTをはじめとする生成AIの活用がビジネス現場でも本格化しています。しかしその便利さの裏で問題となるのが「ハルシネーション(hallucination)」と呼ばれる現象です。ハルシネーションとは、AIが学習データに基づいて存在しない情報や事実をあたかも本物のように作り出してしまう現象を指します。例えば、本当は発表されていない製品をAIが「最新ニュース」として創作してしまうケースなどが挙げられます。これは学習データの偏りや不足、あるいはモデルの内部問題によって、AIが現実とは異なる解釈・推論をしてしまうことが原因です。言い換えれば、AIが持つ知識に穴や誤りがあると、もっともらしいウソを生成してしまうのです。
こうしたハルシネーションが起きると、企業にとって深刻なリスクにつながりかねません。主なリスクの例を挙げると:
- 誤情報提供による顧客トラブル: AIチャットボットが製品仕様や価格を誤って案内し、顧客からクレームが発生する
- 虚偽情報による法的リスク: 誤った金融アドバイスや医療判断が提供され、訴訟問題に発展する可能性
- 信頼失墜やブランド毀損: 誤情報拡散により企業や製品への信頼が損なわれ、ブランドイメージが低下する
実際の事例として、Facebook(Meta社)が公開した大規模言語モデル「Galactica」は、架空の科学者経歴や存在しない理論名を生成してしまい、公開からわずか3ヶ月で運用停止に追い込まれました。この件では「AIの事前検証やデータ品質への配慮が足りない」と厳しい批判を招き、企業の信頼も大きく揺らいでしまいました。このように、ハルシネーションは意思決定ミスや顧客信用の低下、法的トラブルなど、多方面で企業に重大な損失をもたらし得るリスクなのです。
データ品質ガバナンスがハルシネーションを防ぐ鍵
では、このハルシネーション問題にどう対処すれば良いのでしょうか。そのポイントの一つが 「データ品質のガバナンス(管理)」 です。俗に「Garbage in, Garbage out(ゴミ入力をすればゴミ出力しか得られない)」と言われるように、AIも元となるデータが悪ければ誤ったアウトプットを返してしまいます。実際、不正確・不完全・古いなど品質の悪いデータは、AIの判断を誤らせ戦略ミスや誤情報拡散を招く原因になります。逆に言えば、データが高品質で信頼できるものであれば、AIによる誤情報生成のリスクを大幅に減らすことが可能です。
企業のデータ責任者への最新調査でも、「生成AI導入の課題」のトップに「データの品質」が挙げられています。これは多くのリーダーが、AIを有効活用するためにまずデータ品質の確保が不可欠だと認識していることを示しています。
データ品質の評価軸とハルシネーション防止への関係
データの「品質」と一口に言っても、その評価にはいくつかの側面(ディメンション)が存在します。Informaticaのデータマネジメント製品群では、代表的な6つのデータ品質評価軸が定義されており、Cloud Data Governance & Catalog (CDGC)でもこれらを用いてデータ品質を計測・可視化できます。以下の表に、この6軸の定義と生成AIへの影響、そしてCDGCを利用した対策を整理します。

生成AIは本質的に誤回答(ハルシネーション)を生成するリスクを内包しているため、従来は「人間による最終チェック」が強調されてきました。しかし、真に効果的な運用を目指すのであれば、人間による確認の前段階で、ハルシネーションの発生を極力抑制する仕組みを構築することが不可欠です。
そのためには、先に提示した6つのデータ品質の評価軸に基づき、入力データの健全性を担保するプロセスを設計し、可能な限り自動化されたチェック機構を組み込むことが求められます。
これにより、
- 人間によるレビューの負荷を軽減し、
- 誤回答の発生率を構造的に低減し、
- 生成AIの活用を「安心してスケール可能な仕組み」へと昇華させる
ことが可能になります。
CDGCによるデータ品質ガバナンスの実践
では、こうしたデータ品質をどのように管理・担保していけば良いのでしょうか。その具体策として有効なのがInformaticaのクラウドデータガバナンス&カタログ (CDGC) を活用したデータ品質ガバナンスです。CDGCはInformatica Intelligent Data Management Cloud (IDMC)の一部であり、データ資産のカタログ化やリネージュ可視化に加えて、ビジネス主導でデータ品質ルールを定義・適用し、その結果をモニタリングする機能を備えています。
データ品質のルールを作成してチェックを行うと、以下のようにデータ品質の評価軸に沿って評価した結果のスコアを確認できるようになります。
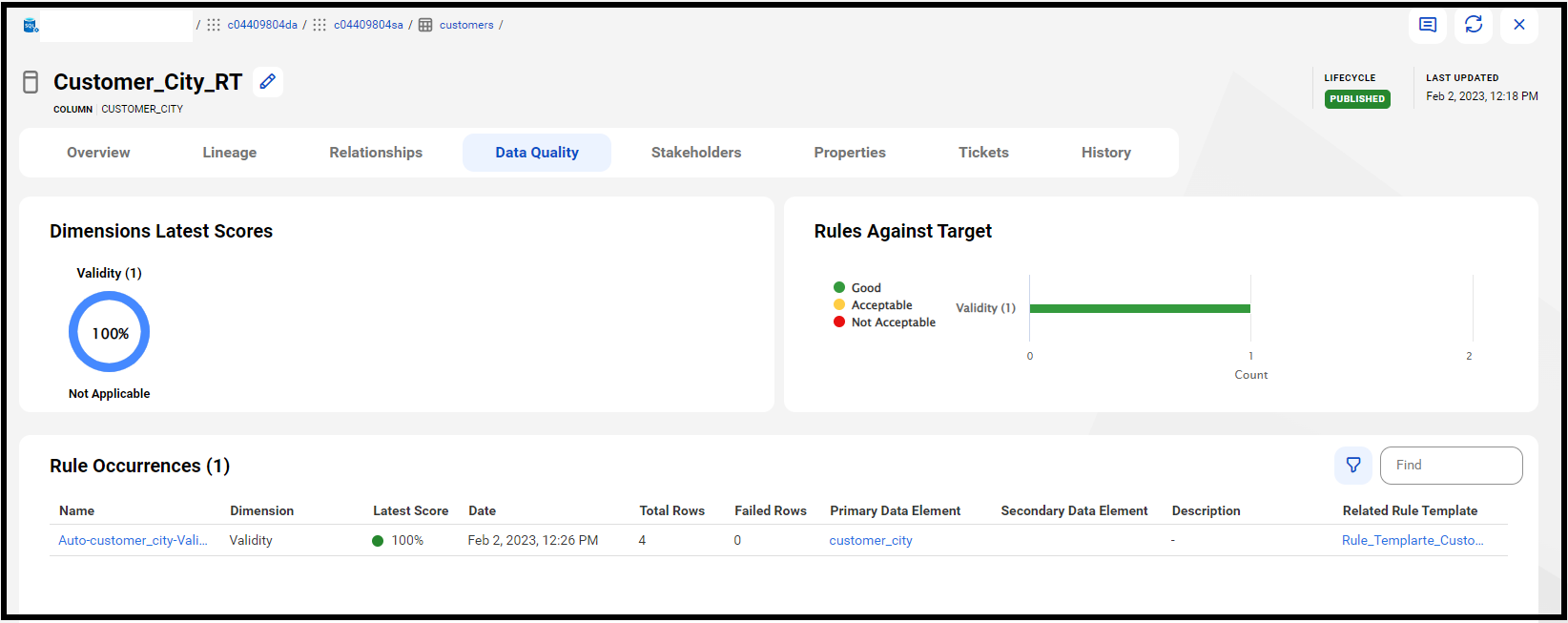
CDGCでは、データ品質管理の実装パターンとして以下の3つの仕組みが用意されています。それぞれ目的や役割が異なる機能ですが、組み合わせて使うことで組織全体のデータ品質を効果的にモニタリングして、ガバナンスを利かせていくことが可能となります。
- データ品質ルールオカレンス (Data Quality Rule Occurrence)
- データ品質ルールテンプレート (Data Quality Rule Template)
- スコアカードルールオカレンス (Scorecard Rule Occurrence)
これらの使い分けが分かるように、特徴やユースケースなどを以下の表にまとめました。

データ品質ルールオカレンスとデータ品質ルールテンプレートの違いは、"顧客住所"を意味する"address"列が複数のテーブルに存在するとき、データ品質ルールオカレンスはそれぞれのテーブルに対して作成する必要があるのに対して、データ品質ルールテンプレートは1つだけ作成すれば良いということです。
データ品質ルールオカレンスとデータ品質ルールテンプレートで共通しているのは、データを1行ずつ読みながら、単項目または項目間チェックを行うということです。それに対して、スコアカードルールオカレンスは複数行に対してGROUP BYしてチェックして重複チェックを行うなど、柔軟な使い方が可能です。これらを活用してデータ品質の評価軸ごとのチェックを実装していきます。
上記の3つのパターンに関する具体的な実装方法については、以下の記事を参照ください。
以上の3つの機能を活用することで、データの品質を定義→適用→測定というサイクルをCDGC上で一元管理できます。統一的なテンプレートで基準を定め、各データにルールを適用し、スコアカードで継続監視することで、企業のデータは常にAI利用に耐えうる品質が保たれることになります。結果として、生成AIのハルシネーションを源流(データ)から防止し、安心してAIをビジネス活用できる体制を築くことが可能となります。
さいごに
データ品質ガバナンスを強化しハルシネーションリスクを低減することは、ビジネス側にも大きなメリットがあります。本記事ではCDGCにおけるデータ品質ソリューションの概要を紹介しましたが、実際の設定方法や具体的な操作手順については上記でご紹介した記事や、Informatica公式のナレッジベース、ドキュメントなどを参照してください。そうしたリソースを活用しながら、高品質なデータに支えられたAI活用をぜひ実現していきましょう。