概要
Windows10でWindows Machine Learningを使用することができるようになりました。ONNXモデルを実行することができ、Direct X12ベースのGPUであれば、CUDAに依存しないため、Nvidia以外のGPUでもGPUで処理を高速化することができます。
作成したコードは、少し整理してからgitで公開したいと思います。
TinyYolo-v2
YOLOは、現在はv3が公開されていますが公開されているV2のモデルを使用します。
https://pjreddie.com/darknet/yolo/
TinyYolo-v2のONNXモデルがダウンロードできます。
https://github.com/onnx/models/tree/master/tiny_yolov2
Yolov2では、セマンティックセグメンテーションのような考え方を取り入れて、クラス分類と矩形を一気に計算します。Loss関数はかなり複雑になり、学習の難しさという問題もあります。一から学習する場合、Loss関数の要素を段階的に学習させていかないとうまくいかない経験をされた方も多いのではないかと思います。
そのような状況なので、学習済みモデルを入手できることはかなり有用です。また、このモデルからFine Tuningも実行できますので、ChainerやCNTK等ONNXモデルを使えるFrameworkを使って自分の認識させたい物体を認識させるための学習も実行させることが現実的に可能になっています。
YOLOv2について
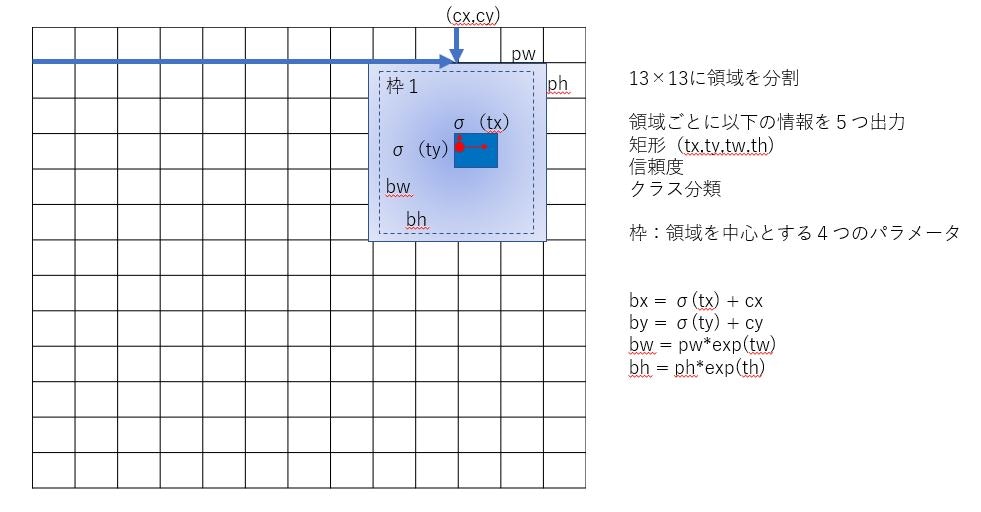
YOLOv2では、画像を13×13のセルに分割します。そのセルに対して5つの矩形候補を出力し、矩形候補には、4つの矩形情報、信頼度、各クラスの確率が出力されます結局トータルPascal VOCのデータセットを使用すると20分類なので出力されるグリッドは(矩形(4)+信頼度(1)+クラス分類(20))×矩形候補(5)×グリッド(13)×グリッド(13)となり、125×13×13という形式になります。ダウンロードしたモデルをNetronで見るとfloat型で、(null,125,13,13)という形式になっていることが確認できます。
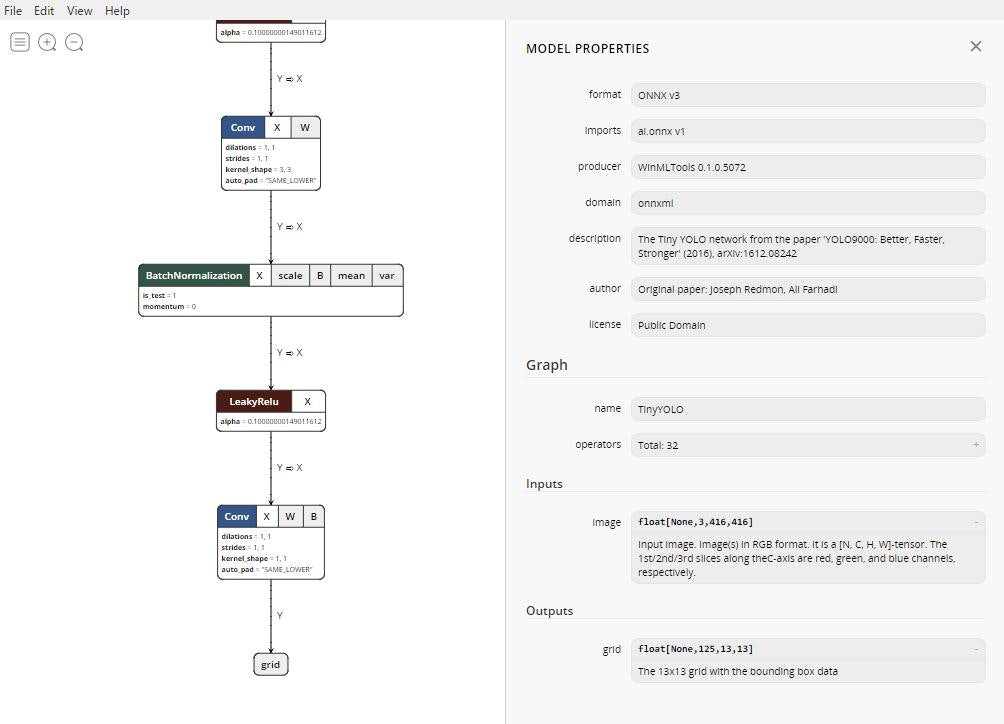
Visual Studioでコード生成
Windows10 1803以降とVisual Studio2017が必要になります。モデルをAssetに登録するとコード生成が行われます。基本的にはその機能を利用します。実行時読み込まないといけないのでビルドアクションはコンテンツを指定します。
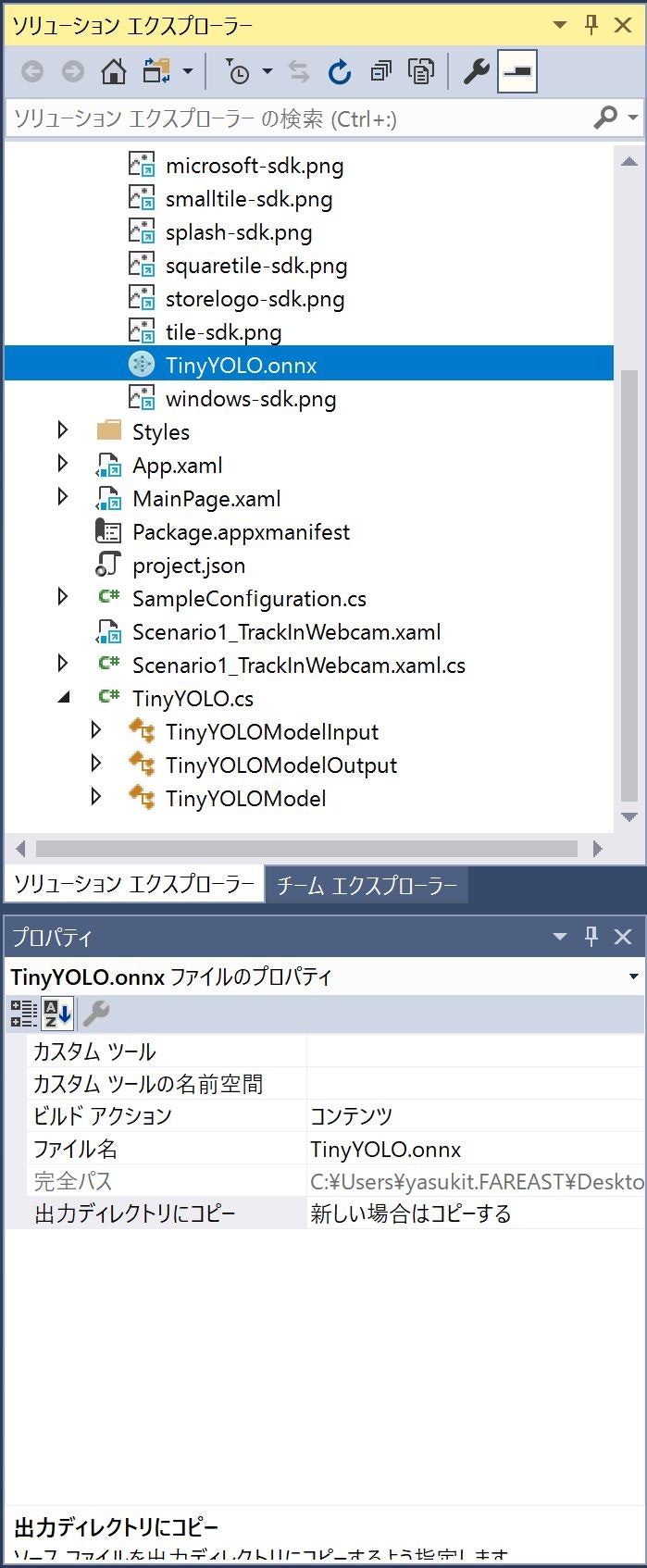
1.コード生成、クラス名はモデル名から出力されるので必要があれば、変更する
2.カメラからの動画フレームを生成されたモデルのInputにBind
3.モデルの評価実行
4.モデルOutputからNMS、Softmax処理
5.矩形をフレームに書き込み表示
NMS、SoftmaxはWindows Machine learningのAPIで公開されていないので、自作する必要があります。
下記はインファレンス部分の主要なコードです。入力のImageはVideoFrameとして渡すので、動画の場合は直接、静止画の場合は、SoftwareBitmapからVideFrameを作成します。
var outputArray = new List<float>();
outputArray.AddRange(new float[21125]); // 125×13×13
binding.Bind(this.inputImageDescription.Name, inputFrame);
binding.Bind(this.outputTensorDescription.Name, outputArray);
var results = await this.model.EvaluateAsync(binding, "TinyYOLO");
Softmax
Yolov2の出力はGridをそのまま出力するので、ラベル出力を確率にするにはSoftmax関数を適用しないといけません。Windows Machine LearningにSoftmax関数が見当たらないので、自分で計算する必要が現状あります。
こんな感じです。
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
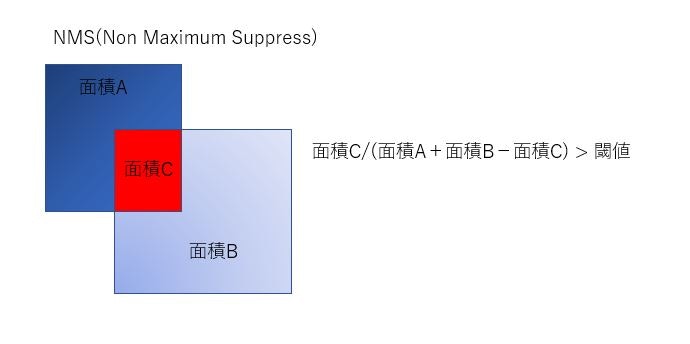
NMS(Non Maximum Suppress)処理
NMSもWindows Machine Learningには見当たらないので、自力で実装する必要があります。それほど難しくはないのですが、ちょっとめんどくさいです。基本は図のように重なっている面積が全体のどの程度の割合かで、重なりが多いと同じ矩形と認識して、信頼度の低い方を破棄するという処理になります。
各セルごとに以下の処理を実行
1.矩形をクラス分類ごとに信頼度でソート
2.重なりを計算
3.Thresh Hold以上であれば、信頼度の高い方の矩形を選択
実行速度比較
作成したアプリケーションでの検知になります。TinyYOLOv2は、416×416の入力画像なので、サイズを変えずに、カメラからの動画をリアルタイムに画面の端に検知結果を表示しています。
、
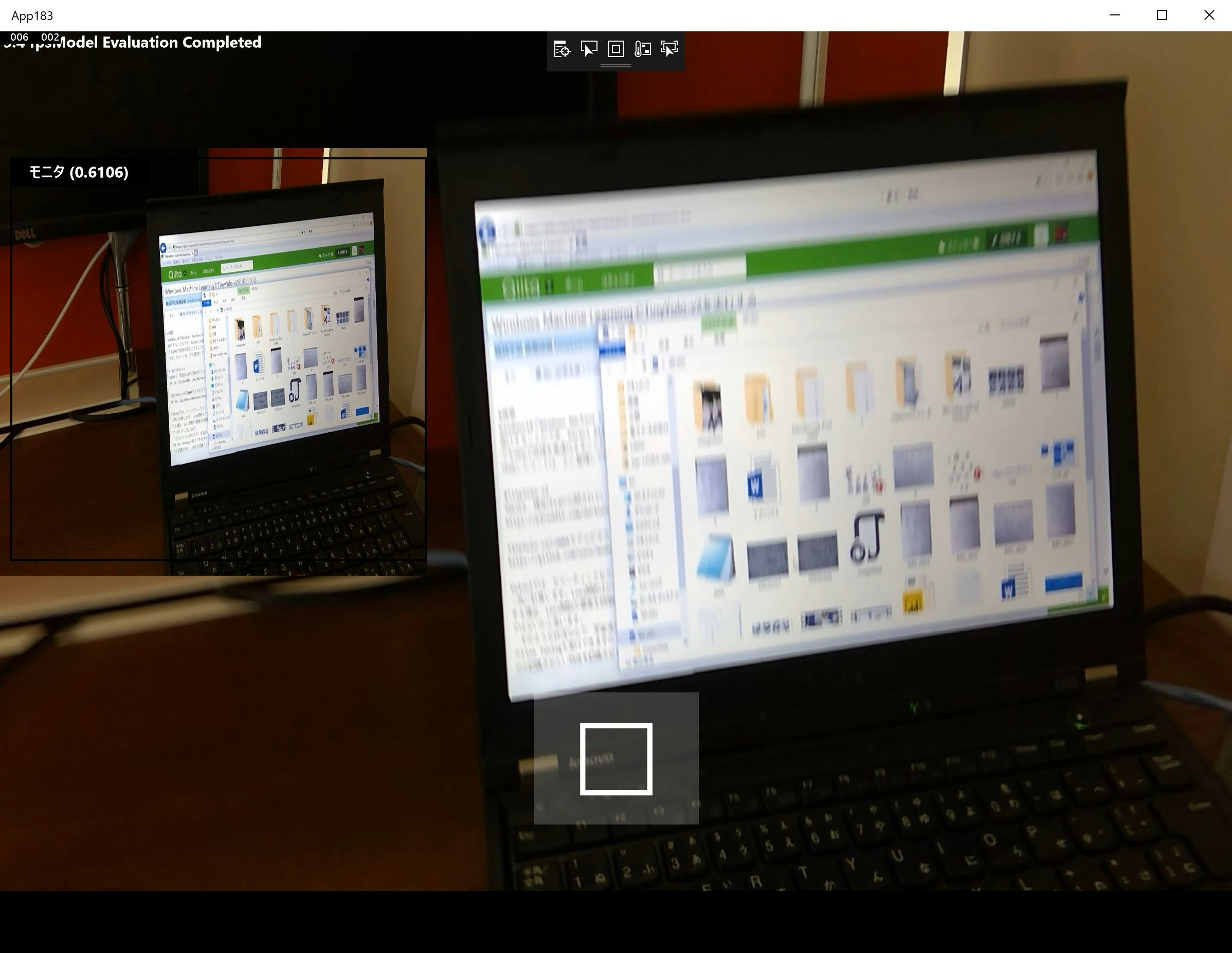
リアル処理を行い、フレームレートを測定することによりパフォーマンスの比較を行いました。
MovidiusはCaffeで実装されたTinyYolov1がサンプルに付属しているため実行します。言語はPythonになります。
Microsoft ELLは、ONNX形式をサポートしませんが、Darknet形式から、直接インポートできるため、その機能を利用します。同じくPythonで実行します。
実行手順は以下を参照ください
https://microsoft.github.io/ELL/tutorials/Getting-started-with-object-detection-using-region-of-interest-networks/
Microsoft ELLが直接実行コードを生成しているからかもしれませんが、同じスペックでのWindows MLよりも高速なようです。また、当然、GPUが高速であれば、高速で実行できます。Windows MLもまだPreviewなので、これから最適化が進んでいくと考えられます。AMDのGPUで試してみたいのですが、手持ちがなく残念です。
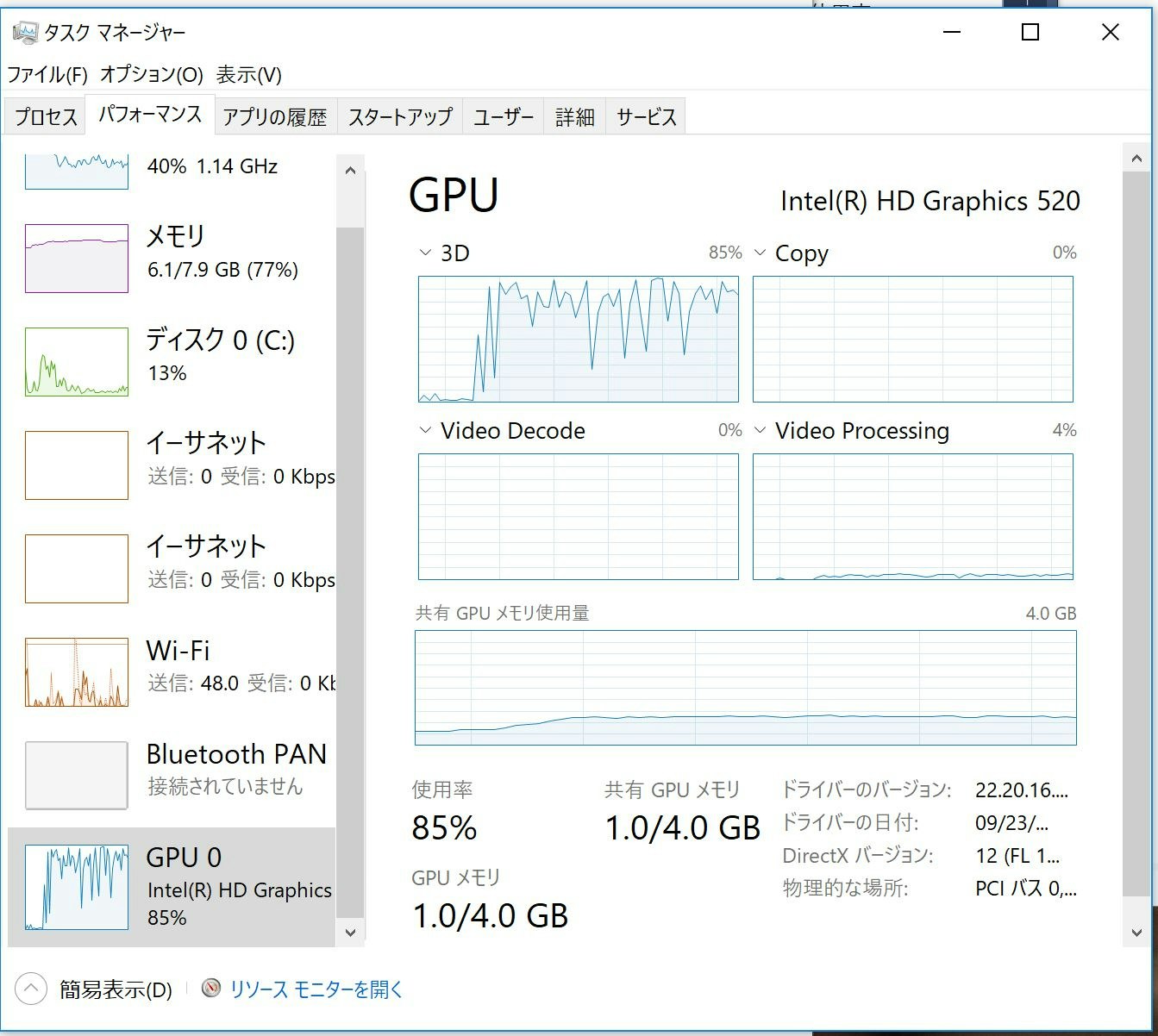
また、Surface Bookですが、インテルのHD Graphics520とGeforceGTX950相当が搭載されており、どちらもDirectX12をサポートするため、Windows MLのGPUとして実行できます。ただ、Intel HD Graphics520は、Corei7-6600Uで実行するより少し遅いという結果になりました。
Intel HD Graphic520を使っている場合の、パフォーマンスカウンタです。
| 機種 | 結果 |
|---|---|
| Movidius Compute Stick(Think Pad x230 ) | 5.2fps |
| Microsoft ELL (Think Pad x230 CPU Corei5-3320M) | 5.1fps |
| Windows ML(Surface Book Geforce GPU) | 5.4fps |
| Windows ML(Surface Book Intel HD Graphics520 GPU) | 1.8fps |
| Windows ML(Surface Book CPU Corei7-6600U) | 2.8fps |
| Windows ML(Think Pad x230 CPU Corei5-3320M) | 2.3fps |
| Windows ML(Corei7(7700)/Geforce GTX1060) | 20.2fps |