タイトルの通りなんですが、pytorchで地味に役立つ2つのライブラリについての説明を実際にCIFAR10の識別モデルをうごかしながら説明します。
tl;dr
-
VisdomはTensorboardのPytorch版だよ -
torchsummaryはKerasでいうところのmodel.summaryだよ - Visdomの使い方の例を実際のモデルを動かしながら説明している記事がなかったから書いたよ
モデル
下のようなモデルを使います。
model.py
class Model(nn.Module):
def __init__(self, nch=3, n_classes=10):
super(Model, self).__init__()
self.layers = nn.ModuleList([
nn.Sequential(
nn.Conv2d(nch, 32, 3, 1, 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
), # 28x28 -> 14x14
nn.Sequential(
nn.Conv2d(32, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
), # 14x14 -> 7x7
])
self.classifier = nn.Sequential(
nn.Linear(8*8*64, 128),
nn.ReLU(128),
nn.Linear(128, n_classes),
)
def forward(self, x):
for layer in self.layers:
x = layer(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
pytorch-summary
ネットワークのアーキテクチャを確認するためのライブラリです。
インストール
% pip install torchsummary
使い方
from torchsummary import summary
summary(your_model, input_size=(channels, H, W))
具体例
使い方はすごく簡単でNNと入力する画像の形状を引数にして呼び出すだけです
from torchsummary import summary
net = Model().to(device)
summary(net, (3, 32, 32)) # GPUを使わない場合、引数のdeviceをcpuに変更します
出力例
forwardに書かれているviewによる形状の変化は、明示的な表示はされないことに留意してください
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 32, 32] 896
ReLU-2 [-1, 32, 32, 32] 0
MaxPool2d-3 [-1, 32, 16, 16] 0
Conv2d-4 [-1, 64, 16, 16] 18,496
BatchNorm2d-5 [-1, 64, 16, 16] 128
ReLU-6 [-1, 64, 16, 16] 0
MaxPool2d-7 [-1, 64, 8, 8] 0
Linear-8 [-1, 128] 524,416
ReLU-9 [-1, 128] 0
Linear-10 [-1, 10] 1,290
================================================================
Total params: 545,226
Trainable params: 545,226
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.97
Params size (MB): 2.08
Estimated Total Size (MB): 3.06
----------------------------------------------------------------
Visdom
データの可視化のためのツールで、TorchとNumpyをサポートしています。
今回紹介する学習過程の表示以外にも2次元、3次元プロットや画像・テキストの描画など様々な機能を備えています。
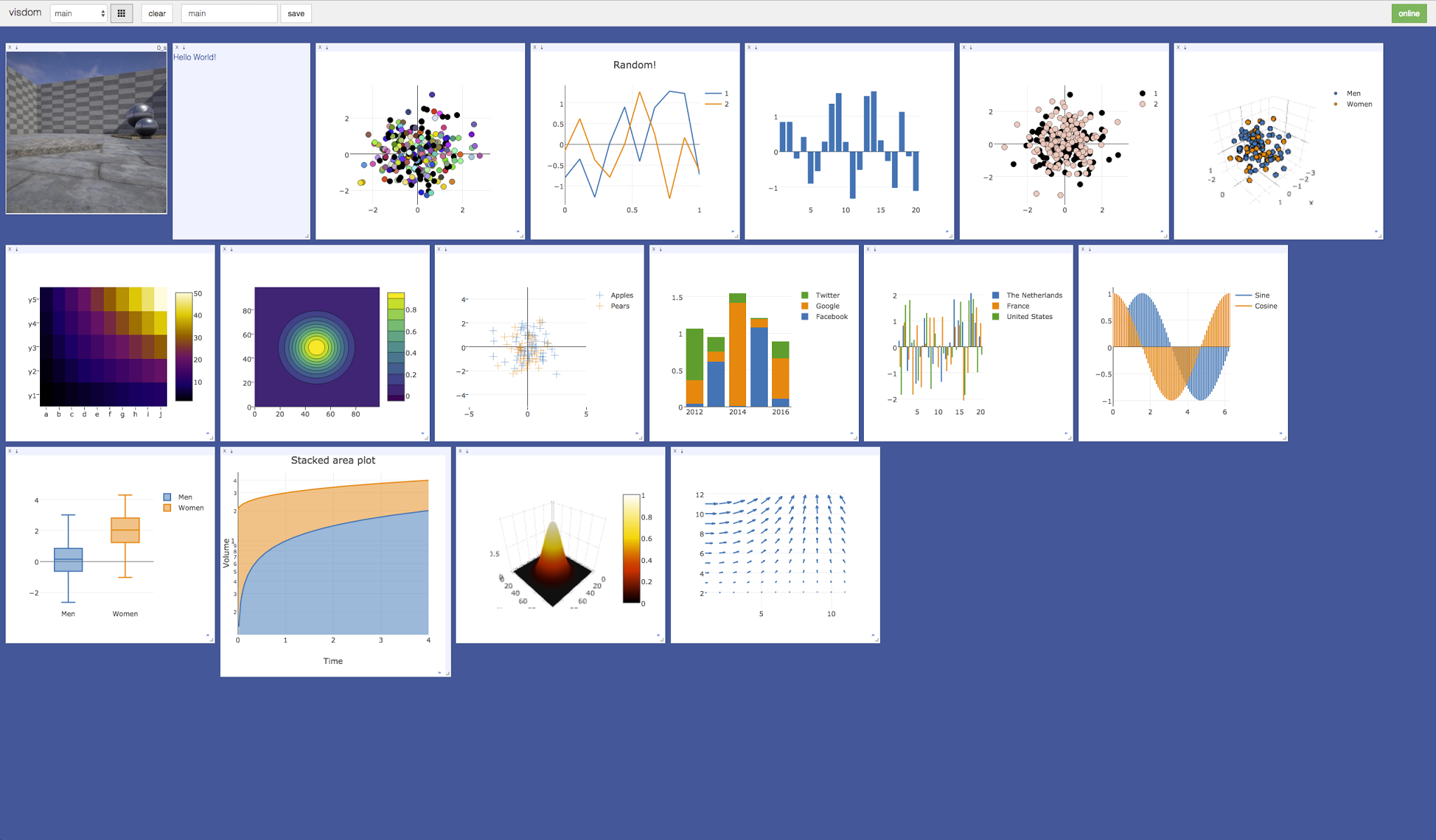
(Visdom - githubより)
インストール
$ pip install visdom
起動
$ visdom
これにより、デフォルトではlocalhost:8097でVisdomサーバーが起動します。
基本的な書き方
from visdom import Visdom
viz = Visdom()
viz.line() # 直線を引く
viz.text() # 文章を残す
viz.image() # 画像を表示する
ロス、正解率を順次プロットする
手順は
-
Visdomをインポートし、インスタンスを作成 - ロス、正解率をエポックごとに
viz.line()に追加
です。
from visdom import Visdom
viz = Visdom() # インスタンスを作る
n_epochs = 20
train_loss_list = []
train_acc_list = []
test_loss_list = []
test_acc_list = []
for epoch in range(n_epochs):
train_loss = 0
train_acc = 0
test_loss = 0
test_acc = 0
net.train() # 学習モードに切り替え
for i, (imgs, labels) in enumerate(trainloader):
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(imgs)
loss = criterion(outputs, labels)
# ロスと正解率の更新
train_loss += loss.item()
train_acc += (outputs.max(1)[1] == labels).sum().item()
loss.backward() # 逆伝搬
optimizer.step()
avg_train_loss = train_loss / len(trainloader.dataset)
avg_train_acc = train_acc / len(trainloader.dataset)
# test
net.eval()
with torch.no_grad():
for imgs, labels in testloader:
imgs = imgs.to(device)
labels = labels.to(device)
outputs = net(imgs)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_acc += (outputs.max(1)[1] == labels).sum().item()
avg_test_loss = test_loss / len(testloader.dataset)
avg_test_acc = test_acc / len(testloader.dataset)
#------ここから-------#
viz.line(X=np.array([epoch]), Y=np.array([avg_train_loss]), win='loss', name='avg_train_loss', update='append')
viz.line(X=np.array([epoch]), Y=np.array([avg_train_acc]), win='acc', name='avg_train_acc', update='append')
viz.line(X=np.array([epoch]), Y=np.array([avg_test_loss]), win='loss', name='avg_test_loss', update='append')
viz.line(X=np.array([epoch]), Y=np.array([avg_test_acc]), win='acc', name='avg_test_acc', update='append')
#------ここまで-------#
print('epoch: {}, train_loss: {:.3f}, train_acc: {:.3f}, val_loss: {:.3f}, val_acc: {:.3f}'
.format(epoch, avg_train_loss, avg_train_acc, avg_test_loss, avg_test_acc))
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
test_loss_list.append(avg_test_loss)
test_acc_list.append(avg_test_acc)
ちなみにリスト化された精度のプロットも簡単です
viz.line(X=np.array(range(n_epochs)), Y=np.array(train_loss_list), win='loss', name='avg_train_loss', update='append')
viz.line(X=np.array(range(n_epochs)), Y=np.array(train_acc_list), win='acc', name='avg_train_acc', update='append')
viz.line(X=np.array(range(n_epochs)), Y=np.array(test_loss_list), win='loss', name='avg_test_loss', update='append')
viz.line(X=np.array(range(n_epochs)), Y=np.array(test_acc_list), win='acc', name='avg_test_acc', update='append')
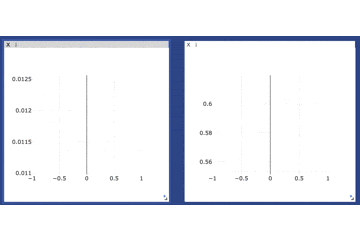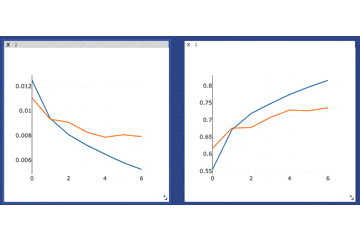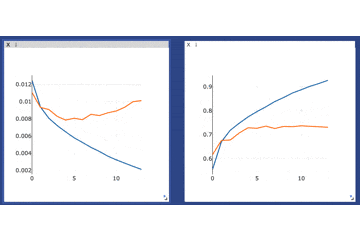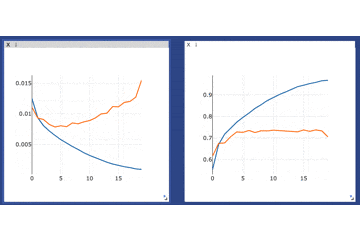
ゴリゴリに過学習してますがそれは置いておいて、カーソルを合わせることで詳細な数値などをみることもできます。
さらに、画面上部のメニューから例えば拡大などをすることでさらに細かくみることもできます(窓自体を大きくすることもできます)
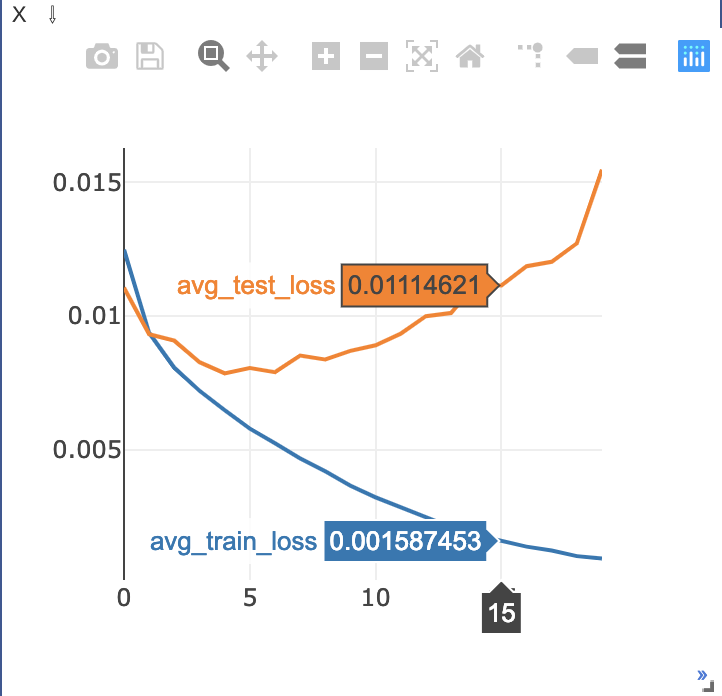
カーソルを合わせた様子
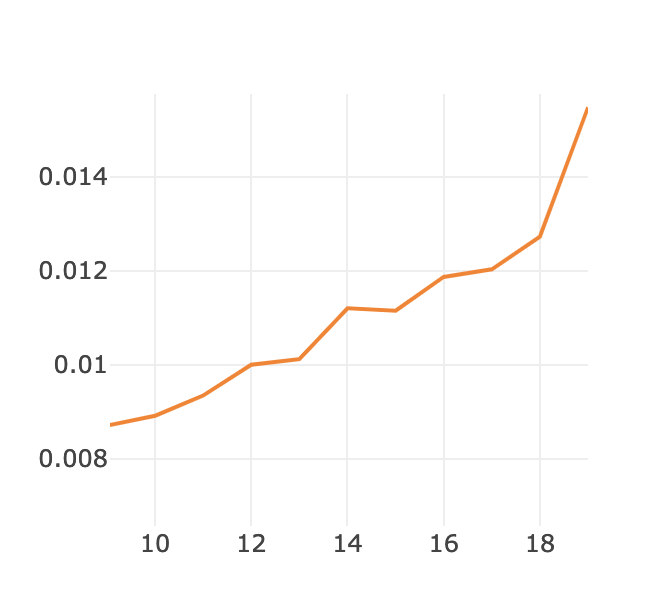 ズームした様子
ズームした様子
ちなみに、カーソルを合わせなくてもラベルと色がわかるようにするには
viz.line(~, opts={'legend': ['avg_train_loss', 'avg_test_loss']})
という風に書くことができます。
コード全体像
モデルのところだけ省いてます
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision import transforms, datasets
from torchsummary import summary
from visdom import Visdom
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
torch.set_default_tensor_type('torch.cuda.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))
])
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True, num_workers=2)
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
class Model(nn.Module):
pass
# (上にあるので中略)
net = Model(3).to(device)
summary(net, (3, 32, 32))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
viz = Visdom()
n_epochs = 20
train_loss_list = []
train_acc_list = []
test_loss_list = []
test_acc_list = []
for epoch in range(n_epochs):
train_loss = 0
train_acc = 0
test_loss = 0
test_acc = 0
net.train() # 学習モードに切り替え
for i, (imgs, labels) in enumerate(trainloader):
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(imgs)
loss = criterion(outputs, labels)
# ロスと正解率の更新
train_loss += loss.item()
train_acc += (outputs.max(1)[1] == labels).sum().item()
loss.backward() # 逆伝搬
optimizer.step()
avg_train_loss = train_loss / len(trainloader.dataset)
avg_train_acc = train_acc / len(trainloader.dataset)
# test
net.eval()
with torch.no_grad():
for imgs, labels in testloader:
imgs = imgs.to(device)
labels = labels.to(device)
outputs = net(imgs)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_acc += (outputs.max(1)[1] == labels).sum().item()
avg_test_loss = test_loss / len(testloader.dataset)
avg_test_acc = test_acc / len(testloader.dataset)
viz.line(X=np.array([epoch]), Y=np.array([avg_train_loss]), win='loss', name='avg_train_loss', update='append')
viz.line(X=np.array([epoch]), Y=np.array([avg_train_acc]), win='acc', name='avg_train_acc', update='append')
viz.line(X=np.array([epoch]), Y=np.array([avg_test_loss]), win='loss', name='avg_test_loss', update='append')
viz.line(X=np.array([epoch]), Y=np.array([avg_test_acc]), win='acc', name='avg_test_acc', update='append')
print('epoch: {}, train_loss: {:.3f}, train_acc: {:.3f}, val_loss: {:.3f}, val_acc: {:.3f}'
.format(epoch, avg_train_loss, avg_train_acc, avg_test_loss, avg_test_acc))
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
test_loss_list.append(avg_test_loss)
test_acc_list.append(avg_test_acc)