これまでのふりかえり
- 前編ではPostgreSQL への pg_duckdb のインストール、tpc-ds のデータロードの方法までを公開しました
- しかし、記事公開の直前にpg_duck の新バージョン v0.2.0 がリリースされたため、再度、環境構築を再測定することとしました 1
- 後編ではpg_duckdb のアップデートの手順から開始し、tpc-ds の測定結果を紹介します
pg_duckdb のアップデートの手順
インストール済みであった pg_duckdb 0.1.0 を最新の0.2.0 にアップグレードする
既存のリポジトリに移動し git pull 後 、v0.2.0 をチェックアウトし make install を実行する
cd pg_duckdb
git pull
git checkout v0.2.0
make install
- もし、リポジトリ作成からやり直したい場合は以下
-- git clone https://github.com/duckdb/pg_duckdb.git
-- cd pg_duckdb
-- git checkout v0.2.0
-- make install
成功すると以下が表示されて終了する
...
/usr/bin/mkdir -p '/home/postgres/PG16/lib'
/usr/bin/mkdir -p '/home/postgres/PG16/share/extension'
/usr/bin/mkdir -p '/home/postgres/PG16/share/extension'
/usr/bin/install -c -m 755 pg_duckdb.so '/home/postgres/PG16/lib/pg_duckdb.so'
/usr/bin/install -c -m 755 third_party/duckdb/build/release/src/libduckdb.so /home/postgres/PG16/lib
/usr/bin/install -c -m 644 .//pg_duckdb.control '/home/postgres/PG16/share/extension/'
/usr/bin/install -c -m 644 .//pg_duckdb.control .//sql/pg_duckdb--0.1.0--0.2.0.sql .//sql/pg_duckdb--0.1.0.sql '/home/postgres/PG16/share/extension/'
次に psql を起動し pg_duckdb のアップデートを行う
-- メタコマンド \dx で現在のバージョンを確認
\dx
List of installed extensions
Name | Version | Schema | Description
-----------+---------+------------+------------------------------
pg_duckdb | 0.1.0 | public | DuckDB Embedded in Postgres
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)
ALTER EXTENSION コマンドで pg_duckdb をアップデートしてみる
alter extension pg_duckdb update;
ALTER EXTENSION
再度、メタコマンド \dx を使用し、アップデート後のバージョンを確認
\dx
List of installed extensions
Name | Version | Schema | Description
-----------+---------+------------+------------------------------
pg_duckdb | 0.2.0 | public | DuckDB Embedded in Postgres
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)
アップデート後は 0.2.0 になった!
環境
- Rocky Linux 9.4
- PostgreSQL 16.6
- duckdb 1.1.3
- pg_duckdb 0.2.0
測定条件
以下の条件で測定した
パラメータやベンチマークツールの設定
- PostgreSQL のパラメータは以下のみ変更
| パラメータ | 設定値 |
|---|---|
| shared_preload_libraries | 'pg_duckdb' |
| log_destination | csvlog |
| logging_collector | on |
| shared_buffers | 2GB |
| work_mem | 16MB |
| max_parallel_workers_per_gather | default | 0 2 |
| statement_timeout | 3000ms 3 |
- pg_duckdb のパラメータ以下のみ変更
| パラメータ | 設定値 |
|---|---|
| duckdb.force_execution | on | off 2 |
- ベンチマークツールや OS の情報は以下
| 項目 | 設定 |
|---|---|
| スキーマ | tpc-ds (duckdb のものを利用) |
| データ量 (Scale Factor) | 1 |
| クエリ | 01 ~ 99.sql を Explain Analyze を付与して実行4 |
| パーティショニング | 無し |
| 制約やインデックス等 | 無し5 |
| キャッシュの状態 | OSのページキャッシュをクリア済 & pg_prewarm 不使用 |
測定パターン
| No. | 測定対象 |
|---|---|
| 1 | pg_duckdb |
| 2 | PG パラレルクエリあり |
| 3 | PG パラレルクエリなし |
測定結果
各クエリの実行時間のグラフは以下6
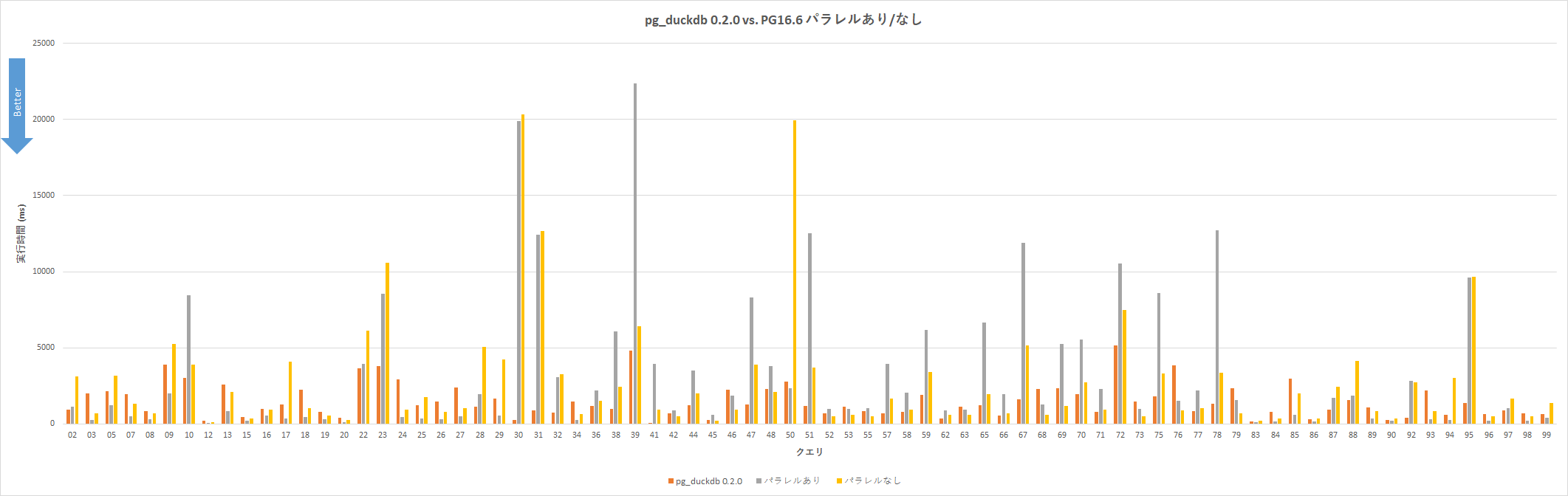
pg_duckdb でエラーとなったクエリとPostgreSQLでタイムアウトとなったクエリについてはグラフに載せていない (クエリ全99個中、77個を掲載)
上記グラフだとわかりにくいので、PG パラレルクエリなし の実行時間と比較し、パラレルクエリあり や pg_duckdb がどれほど高速なのかをグラフ化したものが以下
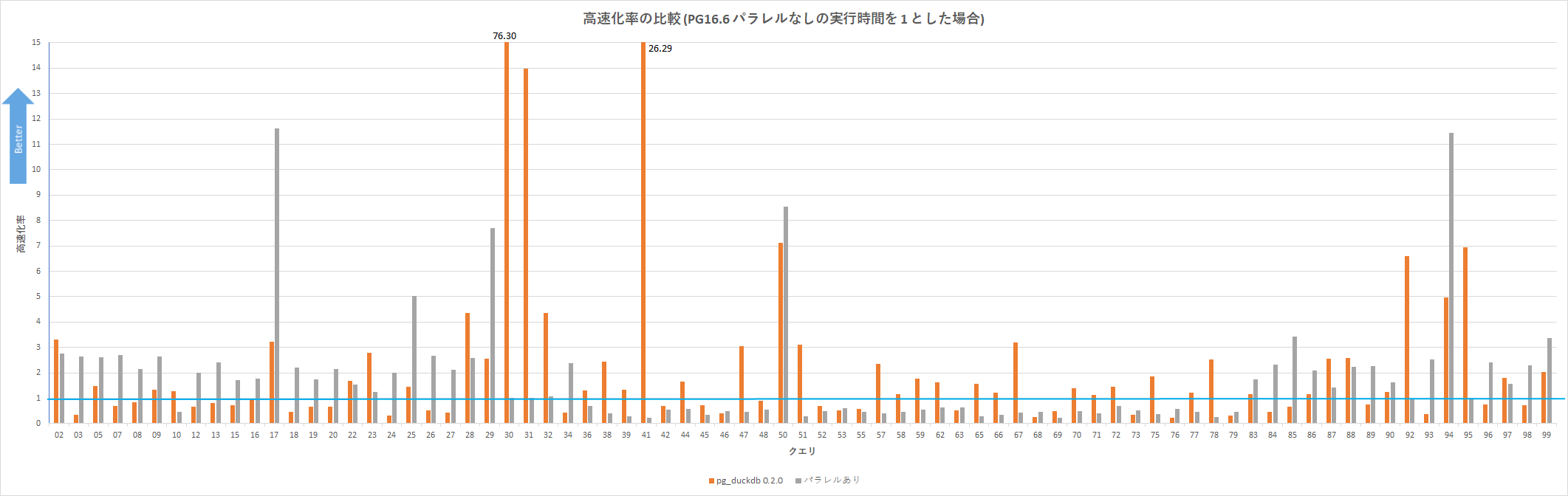
グラフ内の青線は PG パラレルクエリなし の実行時間を 1 としており、この線よりも上であれば高速である。このグラフからわかることはたとえば以下
- pg_duckdb の方が実行時間が短かかったクエリの数はクエリ全77個中、
- pg_duckdb によって最もクエリ実行時間を短縮できたクエリは Q30 で 76.3倍高速化
パターン Q30 の実行時間(ms) pg_duckdb 266.478 PG パラレルクエリあり 19891.096 PG パラレルクエリなし 20331.283
なお、実行計画を見た結果、わかったことは以下
- pg_duckdb を使用した場合、pg_duckdb の処理は Custom Scan として表示される
- pg_duckdb の Custom Scan と パラレルクエリは併用されない模様 (現時点においては)
所感?!
- pg_duckdb によりクエリ実行時間を短縮することが可能なケースは確かに存在。 ただし、それがどのような特徴のクエリなのかは明らかには出来ていないため、それ把握した上で使い分けができるようしたい (クエリ実行時にpg_duckdb と PostgreSQL のどちらで実行するかを自動的にで判断してくれるといいのだがしてくれるのだろうか)
- PostgreSQL ユーザには pg_duckdb の実行計画は読みにくい
- 当初、実行計画の比較を考えていたが不慣れであり今回はあきらめたが、今後、PostgreSQL の実行計画の Text 書式や Json 書式に対応した際に再度比較してみたい
- なお、EXPLAIN のフォーマットに関する issue に "Good First Issue" のタグが付いているため、近々改善が進むことを期待
- pg_duckdb によるクエリ実行において、現在は pg_duckdb の Custom Scan とパラレルクエリは併用不可であるため、併用できるようになればさらに実行時間の短縮が見込めそう
- ロードマップにあるのか不明だが開発に協力している hydra では可能だったようなので、この改善もいつか行われることを期待
- パーティショニングを活用できれば性能向上の可能性あり?
- 以下の issue を見ると現時点では partitioned tables は未対応であり利用不可の模様。大量データであればあるほど性能やメンテの面でパーティショニングの使用が重要であるため、これについても今後利用可能になることを期待。パーティショニングと FDW を組み合わせてシャーディング構成とし、複数のリモートサーバで pg_duckdb による Custom Scan が可能になれば面白い
https://github.com/duckdb/pg_duckdb/issues/19
- 以下の issue を見ると現時点では partitioned tables は未対応であり利用不可の模様。大量データであればあるほど性能やメンテの面でパーティショニングの使用が重要であるため、これについても今後利用可能になることを期待。パーティショニングと FDW を組み合わせてシャーディング構成とし、複数のリモートサーバで pg_duckdb による Custom Scan が可能になれば面白い
- 以下のケースについてはどなたか測定した結果を共有していただけると嬉しい
- データ量をさらに増やした場合 (Scale Factor: 10, 100, ...)
- データがオンメモリの場合
- 制約やインデックスを付与した場合
- pg_duckdb のパラメータチューニングを行った場合
おわりに
初めて pg_duckdb という拡張機能の名前を聞いた際は、PostgreSQL に duckdb を組み合わせて動かす?! 何を言っているんだ??と思いましたが、実際に動かして測定してみると確かに duckdb によるクエリ処理の高速化が可能なケースがあることを確認できました。
PostgreSQL 界隈の OLAP 向けで利用可能な拡張機能としては現在、cstore_fdw8, citus9, hydra10, pg_mooncake11, pg_analytics12 など様々ありますが、機能開発や品質向上が進んだ先にどれが生き残りデファクトとなっていくのか楽しみです。
なお、PostgreSQL 自体には OLTP, OLAP 問わずクエリ実行時間の短縮を可能とする改善点がまだまだ存在するので、来年もコミュニティ開発で貢献できるよう取り組んでいこうと考えています。
というわけで、本記事はこのあたりで終わりたいと思います。
みなさん、良い年をお過ごしください!
参考
- duckdb
- pg_duckdb
-
pg_duckdb 0.2.0 と 0.1.0 の測定結果を比較すると、0.2.0 は 約1.46倍高速だった ↩
-
他の方による過去の tpc-ds の測定結果を見るとインデックスを作成していない PostgreSQL ではクエリが終わらない可能性があったため、statement_timeout を設定することとした。設定値は pg_duckdb 0.2.0 の測定で最長の実行時間を数倍し 30秒 とした ↩
-
https://github.com/duckdb/duckdb/tree/main/extension/tpcds/dsdgen/queries から取得 ↩
-
duckdb の tpcds の DDL には制約やインデックスが含まれないため ↩
-
厳密な性能測定ではないため一発取り。真面目に性能測定したい場合は複数回測定がおすすめ ↩
-
もちろん、pg_duckdb を利用した方が遅いクエリも存在。PGにおいてはパラレルクエリあり の方が パラレルクエリなし よりも遅いクエリも存在。 ↩ ↩2
-
- https://github.com/citusdata/citus
- https://github.com/citusdata/citus/tree/main/src/backend/columnar