 はじめに
はじめに
Linuxサーバー上でも.NETが動作し、クラウドネイティブな開発においてもファーストランゲージであることは開発者のみんなたちさまはご存じかと思います。
自分もお仕事ではLinux上で動くAPIサーバーやAWS LambdaをC#で書いたりしています。
しかし、.NETはLinux上でのサーバーアプリケーション用途だけではなく、Linuxデスクトップアプリケーションやエッジデバイスアプリケーションの用途にも使えるものです。
そこで今回はカメラの画像をキャプチャし、リアルタイムで顔検出を行なうサンプルを作ってみたので、その内容について記述します。
作成したアプリケーションの実行画面はこんな感じです。
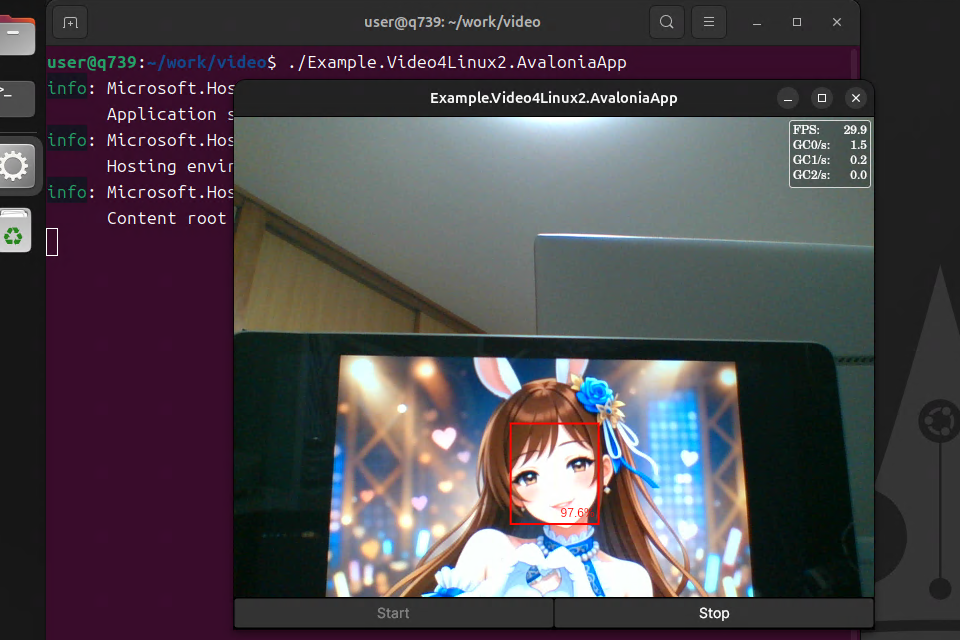
 概要
概要
実行環境
| 項目 | 概要 |
|---|---|
| PC | 中古のArrowsタブレット |
| OS | Ubuntu 24.04 |
| 言語/ランタイム | C#/.NET 10 |
| UI | Avalonia UI |
| カメラキャプチャ | V4L2(Video for Linux 2)の.NETラッパーを作成 |
| 顔検出 | ONNX Runtime |
アプリケーションは.NET 10で作成し、UIはAvalonia UIで作成しています。
Avalonia UIはXAMLベースでWindows、macOS、Linux等のアプリケーションを作成できるので、WPFに慣れている人がLinuxデスクトップアプリケーションやクロスプラットフォームアプリケーションを同じように作る事ができます。
また、LinuxのDirect Rendering Manager(DRM)を使用してAvaloniaアプリケーションを動かすことも出来るので、ウィンドウシステムを動かさないRaspberry Pi用のおもちゃを作る事にも向いています。
実行環境は中古のArrowsタブレットを使っています。
OSはUbuntuをインストールしており、特になにもせずとも内蔵カメラやタッチパネルを利用できます。
10,000~15,000円くらいで第8世代あたりのCPUを積んだものが買えるので、自分はGrafanaダッシュボードやおもちゃの実験用に4台ほど持っています。
処理フロー
アプリケーションは以下のステップでリアルタイム処理を行います。
- フレーム取得: LinuxのV4L2ラッパーを通じてカメラから画像フレームを取得
- 前処理1: 取得した画像をYUYV形式から表示に使用するRGBA形式に変換
- 前処理2: RGBA形式からONNXモデル用の入力形式も作成(リサイズ、テンソル化)
- 推論実行: ONNX Runtimeにテンソルを入力し、顔の位置を推定
- 結果描画: RGBA形式の画像をWriteableBitmapを使って表示し、推論結果の座標をその上にSkiaSharpを使って検出枠を描画
 Video for Linux 2ラッパー
Video for Linux 2ラッパー
カメラ画像の取得にはV4L2ラッパーの.NETライブラリを自前で作成しました。
カメラキャプチャを行なうライブラリの場合、APIが管理するバッファや表示用のバッファ等の管理が必要です。
既成のライブラリではこのあたりの管理がルーズで、GC発生頻度の多いものがあったことが自前のラッパーライブラリを作成した理由です。
ライブラリの使い方は以下の様にシンプルなものになっています。
using LinuxDotNet.Video4Linux2;
// カメラデバイスをオープン
var capture = new VideoCapture("/dev/video0");
capture.Open(640, 480);
// キャプチャイベント設定//
capture.FrameCaptured += frame =>
{
// YUYV形式形式のデータが毎フレーム取得できるので、ここで加工なりを実施
};
// キャプチャ開始
capture.StartCapture();
今回作ったアプリケーションではFrameCapturedイベントでRGBA形式への変換と顔認識を毎フレームを行ない、FrameCapturedイベントはバックグラウンドスレッドで発生するものなので、その後はメインスレッドに描画処理をディスパッチする内容になっています。
FrameCapturedのスレッドとUIスレッド間の描画用データの受け渡しも画像処理用のバッファをパイプライン管理するBufferManagerクラスを用意し、フレーム毎のバッファアロケーションは発生しないようにしています。
その結果、キャプチャ時のGC発生頻度も顔検出をオフにすればほぼ0となっています。
 顔検出
顔検出
顔検出はONNXランタイムを使用して行なっています。
.NETではMicrosoft.ML.OnnxRuntimeを参照するだけで簡単に使用できます。
<PackageReference Include="Microsoft.ML.OnnxRuntime" Version="1.23.2" />
顔検出処理はサンプル中のFaceDetectorクラスに実装していますが、ソースからの抜粋は以下のようなものになります。
public sealed class FaceDetector : IDisposable
{
// ONNXランタイムの推論セッション
private readonly InferenceSession session;
// テンソルの次元
private readonly int[] dimensions;
// 入力バッファサイズ
private readonly int bufferSize;
// テンソル入力用のバッファ
private float[] inputBuffer;
// 検出結果
public List<FaceBox> DetectedFaceBoxes { get; } = new();
// onnxモデルの幅
public int ModelWidth { get; }
// onnxモデルの高さ
public int ModelHeight { get; }
public FaceDetector(string modelPath, bool parallel = false, int intraOpNumThreads = 0, int interOpNumThreads = 0)
{
// ONNXランタイムのセッションオプション設定
session = new InferenceSession(modelPath, new SessionOptions
{
LogSeverityLevel = OrtLoggingLevel.ORT_LOGGING_LEVEL_ERROR,
EnableCpuMemArena = true,
EnableMemoryPattern = true,
GraphOptimizationLevel = GraphOptimizationLevel.ORT_ENABLE_ALL,
ExecutionMode = parallel ? ExecutionMode.ORT_PARALLEL : ExecutionMode.ORT_SEQUENTIAL,
IntraOpNumThreads = intraOpNumThreads,
InterOpNumThreads = interOpNumThreads
});
// モデルからサイズを取得
var inputMetadata = session.InputMetadata.First().Value;
if (inputMetadata.Dimensions.Length >= 4)
{
ModelHeight = inputMetadata.Dimensions[2];
ModelWidth = inputMetadata.Dimensions[3];
}
else
{
throw new ArgumentException("Invalid model type");
}
// バッファ準備
dimensions = [1, 3, ModelHeight, ModelWidth];
bufferSize = 3 * ModelHeight * ModelWidth;
inputBuffer = ArrayPool<float>.Shared.Rent(bufferSize);
}
...
public void Detect(ReadOnlySpan<byte> image, int width, int height, float confidenceThreshold = 0.7f, float iouThreshold = 0.3f)
{
// 入力画像サイズに応じてONNXランタム用の入力バッファを用意(単純なコピーorリサイズ)
if ((width == ModelWidth) && (height == ModelHeight))
{
CopyDirectToTensor(image, inputBuffer, width, height);
}
else
{
ResizeBilinearDirectToTensor(image, inputBuffer, width, height, ModelWidth, ModelHeight);
}
// 入力バッファからテンソル作成
var inputTensor = new DenseTensor<float>(inputBuffer.AsMemory(0, bufferSize), dimensions);
var inputs = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor(session.InputMetadata.First().Key, inputTensor)
};
// モデル推論の実行
using var results = session.Run(inputs);
// 結果から信頼度とバウンディングボックス座標を取得
var scoresTensor = results[0].AsTensor<float>();
var boxesTensor = results[1].AsTensor<float>();
var numBoxes = scoresTensor.Dimensions[1];
DetectedFaceBoxes.Clear();
if (numBoxes == 0)
{
return;
}
var detectionBuffer = ArrayPool<FaceBox>.Shared.Rent(numBoxes);
try
{
var detectionCount = 0;
for (var i = 0; i < numBoxes; i++)
{
// 信頼度閾値を超える検出結果のみを収集
var faceScore = scoresTensor[0, i, 1];
if (faceScore > confidenceThreshold)
{
detectionBuffer[detectionCount++] = new FaceBox
{
Left = boxesTensor[0, i, 0],
Top = boxesTensor[0, i, 1],
Right = boxesTensor[0, i, 2],
Bottom = boxesTensor[0, i, 3],
Confidence = faceScore
};
}
}
// Non-Maximum Suppressionを適用して重複検出を除去
ApplyNMS(detectionBuffer.AsSpan(0, detectionCount), iouThreshold);
}
finally
{
ArrayPool<FaceBox>.Shared.Return(detectionBuffer);
}
}
...
}
コンストラクタではonnxモデルを読み込み、推論セッションの作成とメタデータから入力バッファの準備をしています。
Detect()は推論の実施処理で、RGBA値をインプットとして毎フレームこの処理を呼び出してリアルタイムの顔検出を行なっています。
処理は以下の流れになります。
- RGBA値の入力画像を、推論で使用するRGBチャネル毎の320x240の画素情報(inputBuffer)に変換
- inputBufferを元に推論用のテンソル作成
- session.Run(inputs)で推論実行
- 推論結果から信頼度と検出結果の座標を取得
- 閾値を超えるスコアの検出結果のみを採用し、その上で重複を除去して検出結果とする
なお、サンプルアプリケーションでは顔検出のモデルにはversion-RFB-320.onnxを使用しました。
 結果の描画
結果の描画
キャプチャした画像の描画は、フレーム毎にFrameCapturedイベント内でWriteableBitmap用のRGBA形式のデータを用意して、それをXAML上ではImageで表示しています。
検出枠の描画はSkiaSharpを使ったFaceBoxOverlayカスタムコントロールを作成し、それをImageの上に描画するような形としています。
XAMLとしては以下のような感じです。
<Image Grid.Row="0"
Width="640"
Height="480"
Stretch="Uniform"
Source="{Binding Bitmap}"
HorizontalAlignment="Center"
VerticalAlignment="Center" />
<controls:FaceBoxOverlay Grid.Row="0"
Width="640"
Height="480"
HorizontalAlignment="Center"
VerticalAlignment="Center"
FaceBoxes="{Binding FaceBoxes}" />
 完全なコード
完全なコード
本記事で紹介した完全なコードは以下のExample.Video4Linux2.AvaloniaAppプロジェクトにあります。
 うさコメ
うさコメ
Avalonia UIを使えばLinuxデスクトップアプリケーションも簡単に作れますし、V4L2ラッパーを作ったことで簡単にカメラキャプチャもできるようになりました( ˙ω˙)
ちなみに、V4L2ラッパーのリポジトリでは以下のようなLinux用のラッパーライブラリも作成しています。
| ライブラリ | 概要 |
|---|---|
| LinuxDotNet.Cups | 印刷用CUPSラッパー |
| LinuxDotNet.GameInput | XInputのジョイスティック入力 |
| LinuxDotNet.InputEvent | /dev/input/event入力、キーボードタイプのバーコードリーダー等で使用 |
| LinuxDotNet.SystemInfo | /proc/*等の各種メトリクス取得 |
| LinuxDotNet.Video4Linux2 | 今回使ったV4L2ラッパー |
また、ONNXランタイムを使えば簡単に.NETアプリケーションに推論機能を導入できます。
今回はCPUのみを使っていますが、GPUを使うオプションもあります。
使用するモデルについてもAzure AI Custom Vision等を使えば、画像ファイルをアップロードしてマウスでポチポチしながらタグ付けを行ないトレーニングをするだけで、簡単に独自のONNXモデルを作る事もできます。1
それとMicrosoft.ML.OnnxRuntimeを使えば、例えばMAUIアプリケーション等にも簡単に画像分類や物体検出機能を導入できます。2

なお、このMAUIでのサンプルは以下の中にあります。
ところで顔検出のモデルでアニメ絵も問題無く認識できるんですね( ˙ω˙)