Pandasの概要
Pandasとは
Numpyを基盤に作られたライブラリで、表形式のデータを操作するための機能を提供する。Pandasには配列の次元ごとに異なる型が定義されている。
- Series(1次元)
- DataFrame(2次元)
- Panel(3次元 非推奨)
インポート
numpyも使うのでともに別名をつけてインポートする。
import pandas as pd
import numpy as np
以下、このようにインポートされてある前提とします。
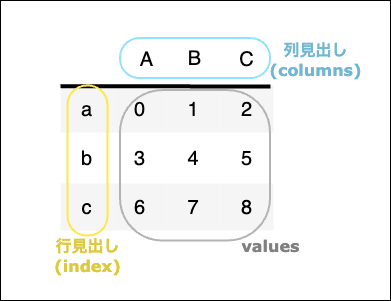
DataFrameの概要
構成
DataFrame型(2次元配列)では次の3点で構成されている。
- 列見出し:
columns - 行見出し:
index - 要素:
values
特徴
DataFrameの特徴として以下のことが挙げられる。
- イテラブルではない
- ミュータブルである(要素の追加・削除・更新が可能)
- 同じ列では同一のデータ型を格納する必要がある(列が異なれば異なる型の混在可)
- 欠損値は自動でNaNが補完される
DataFrameの作成
pd.DataFrame(arr,index=[ ],columns=[ ])
-
第1引数: 2次元Numpy配列、2次元リスト -
index:行見出しのstrリスト -
columns:列見出しのstrリスト
df = pd.DataFrame([[0,1,2],[3,4,5],[6,7,8]],
index=["a","b","c"],columns=["A","B","C"])
df
実行結果
| A | B | C | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| b | 3 | 4 | 5 |
| c | 6 | 7 | 8 |
pd.DataFrame(dict,index=[ ])
配列ではなく辞書を渡して作成することもできる。
辞書のキーは列名、値はその列内にある値のリストとなる。
-
第1引数: 列情報の辞書("列名":[値リスト]) -
index:行見出しのstrリスト
df = pd.DataFrame(
{
"A":[0,3,6],
"B":[1,4,7],
"C":[2,5,8],
},
index=["a","b","c"]
)
df
実行結果
| A | B | C | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| b | 3 | 4 | 5 |
| c | 6 | 7 | 8 |
欠損値
要素に欠損値がある場合、NaNが自動で補完される。
その場合、数値型の列はFloat型、数値型以外の列はObject型になる。
df = pd.DataFrame([[0,1,2],[3,4,5],[6,7]])
↓第2列がFloat型になる。
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 1 | 2.0 |
| 1 | 3 | 4 | 5.0 |
| 2 | 6 | 7 | NaN |
型の混在
Numpy配列とは違い、DataFrameでは異なる型の混在が可能。ただし、同じ列には全て同じの型に揃える必要がある。
df = pd.DataFrame([
[1,True,"one"],
[2,False,"two"],
[3, True,"Three"]
])
df
実行結果
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | True | one |
| 1 | 2 | False | two |
| 2 | 3 | True | Three |
pd.DataFrame()の引数にNumpy配列を渡した場合、元のNumpy配列と同じ実体を参照する。よって、一方の変更がもう一方へ影響を与える。
np_arr = np.arange(9).reshape(3,3)
df = pd.DataFrame(np_arr)
np_arr[0,0] = 100 # Numpy配列の内容を変更
df
↓Numpy配列の(0,0)を変更すると、DataFrameの(0,0)も変わってしまう。
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 100 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
引数に渡すのをNumpy配列ではなくリストにすると、DataFrameが参照する実体と元のリストは別なので、片方の変更は影響しない。
プロパティ
index
行見出しはindexプロパティで参照できるが、これはpandas.core.indexes.base.Index という特殊な型で、さらにvaluesプロパティでNumpy配列として得ることができる。
df = pd.DataFrame(np.arange(9).reshape(3,3),
index=["a","b","c"],columns=["A","B","C"])
print(df.index.values) # ['a' 'b' 'c']
columns
列見出しはcolumnsプロパティで、行見出しと同じように取得できる。
df.columns.values # ['A' 'B' 'C']
values
DataFrameの全ての値をNumpy配列として取得する
df.values #[[0 1 2] [3 4 5] [6 7 8]]
shape
(行数,列数)のタプルを取得する
df = pd.DataFrame(np.arange(12).reshape(3,4),
index=["a","b","c"],columns=["A","B","C","D"])
df.shape # (3, 4)
dtype
列ごとの型を調べる
df = pd.DataFrame([
[1,True,"one"],
[2,False,"two"],
[3, True,"Three"]
])
df.dtypes
実行結果
0 int64
1 bool
2 object
dtype: object
メソッド
info()
行数、列数、列ごとの欠損値の有無、DataFrameの型、使用メモリ量などの情報を表示する。
describe()
以下の内容の基本統計量をDataFrameで表示する。
| インデクス | 内容 |
|---|---|
| count | 件数 |
| mean | 平均値 |
| std | 標本標準偏差 |
| min | 最小値 |
| 25% | 第1四分位値 |
| 50% | 中央値 |
| 75% | 第3四分位値 |
| max | 最大値 |
head()
先頭5行を表示する。
tail()
末尾5行を表示する。
各種集計
以下の統計量を列ごとまたは行ごとに集計する。
要素全体を集計するのではないことに注意。
-
axis=0を指定する or指定なしの場合 列の集計 -
axis=1を指定する場合 行の集計
| メソッド名 | 戻り値 |
|---|---|
| count( ) | データ件数 |
| min( ) | 最小値 |
| max( ) | 最大値 |
| mean( ) | 平均値 |
| std( ) | 標準偏差 |
df = pd.DataFrame(np.arange(9).reshape(3,3),
index=["a","b","c"],
columns=["A","B","C"])
df の出力
A B C
a 0 1 2
b 3 4 5
c 6 7 8
df.sum() の出力
A 9
B 12
C 15
dtype: int64
df.sum(axis=1) の出力
a 3
b 12
c 21
dtype: int64
df.sum().sum() の出力
36
sort_values( [ "列名" ] )
特定の列を指定してソートする。
ascending=Falseと指定すると降順になる。
df = pd.DataFrame([
[7,3,8],
[1,4,6],
[5,0,2]
],
columns=["A","B","C"])
df.sort_values(["C"])
実行結果
| A | B | C | |
|---|---|---|---|
| 2 | 5 | 0 | 2 |
| 1 | 1 | 4 | 6 |
| 0 | 7 | 3 | 8 |
要素の参照
以下のような3×3構成のDataFrameを使って、要素の参照方法を見ていく。
df = pd.DataFrame(np.arange(9).reshape(3,3),
index=["a","b","c"],columns=["A","B","C"])

要素を参照する方法には df[] ・df.loc[] ・df.iloc[]の3つがある。
細かく見ていくとキリがないが、まずはざっくりだいたい次のような使い分け。
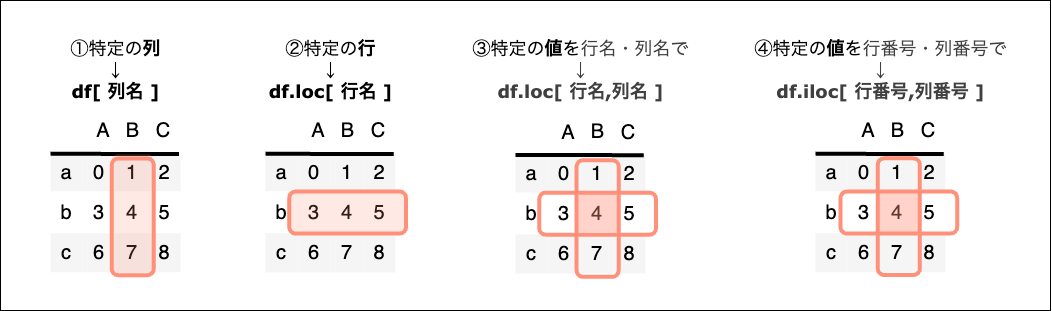
① df[ ~ ]
~には 列名、列名リスト、行名スライス、行番号スライス、条件式 が入る。
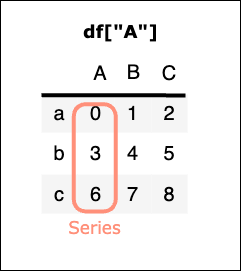
df[ 列名 ]
特定の一列を列名で指定する → Series型を取得
df["A"]
実行結果
a 0
b 3
c 6
Name: A, dtype: int64
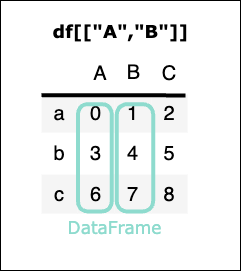
df[ 列名リスト ]
任意の複数列をリストで指定する → DataFrame型を取得
(1列のみをリストで指定した場合でもDataFrame型になる)
df[["A","B"]]
実行結果
| A | B | |
|---|---|---|
| a | 0 | 1 |
| b | 3 | 4 |
| c | 6 | 7 |
df[ 行名スライス ]
任意の複数行をスライス(開始行名:終了行名:ステップ)で指定する → DataFrameを取得
終了行は含む。
※ df[行名スライス] はindexがソートされていないと正しく動かないことがあるので、 .loc を使うのが安全。
df["a":"c":2]
実行結果
| A | B | C | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| c | 6 | 7 | 8 |
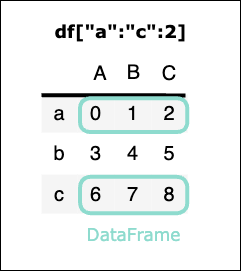
※単独の行名での指定はできない。(df["a"]などはエラー)
df[ 行番号スライス ]
任意の複数行をスライス(開始行番号:終了行番号:ステップ)で指定する → DataFrameを取得
終了行は含まない。
df[0:3:2]
実行結果
| A | B | C | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| c | 6 | 7 | 8 |
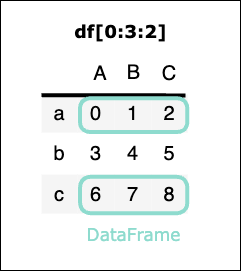
df[ 条件式 ] ブールインデクス参照
DataFrameをオペランドとして条件式に使うと(df > 4)、そのDataFrameの要素ひとつひとつを条件式で評価し、その結果のブール値を要素として持つDataFrameを新たに作成する。
さらにそのブール値を格納したDataFrameをインデクスとして用いると(df[df > 4])、Trueとなる要素のみを格納したDataFrameを取得することができる。
df[df > 4]
実行結果
| A | B | C | |
|---|---|---|---|
| a | NaN | NaN | NaN |
| b | NaN | NaN | 5.0 |
| c | 6.0 | 7.0 | 8.0 |

② df.loc[ 行指定 , 列指定 ]
行指定には 行名、行名リスト、行名スライス、行名タプル、
列指定には 列名、列名リスト、列名スライス、列名タプルが入る。
全行を指定する場合、全行を表す:は省略できない。
全列を指定する場合は全列を表す:は省略できる。

df.loc[ 行名 , 列名 ]
特定の行と列を指定 → 値を取得
df.loc["a","C"]
実行結果:2

df.loc[ 行名リスト , 列名リスト ]
任意の複数行と複数列をリストで指定 → DataFrameを取得
df.loc[["a","c"],["A","C"]]
実行結果
| A | C | |
|---|---|---|
| a | 0 | 2 |
| c | 6 | 8 |
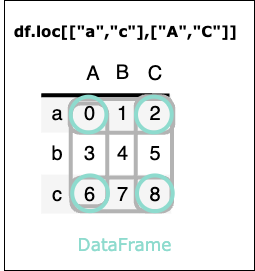
df.loc[ 行名スライス , 列名スライス ]
任意の複数行と複数列をスライスで指定 → DataFrameまたはSeriesを取得
行名・列名でのスライスは終了行を含む。
どちらか一方のみを単独の行名や列名にするとSeries型になる。
一方をスライス、もう一方をリストやタプルにすることも可。
df.loc["a":"c":2,"A":"B"]
実行結果
| A | B | |
|---|---|---|
| a | 0 | 1 |
| c | 6 | 7 |
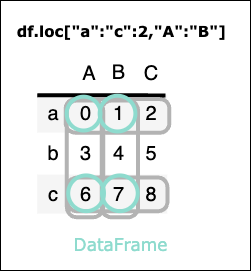
③ df.iloc[ 行指定 , 列指定 ]
locが行名・列名を使用するのに対して、ilocは行番号・列番号を使って指定する。
行指定には 行番号、行番号リスト、行番号スライス
列指定には 列番号、列番号リスト、列番号スライスを入れる。
全列指定を表す:のみ省略できる。
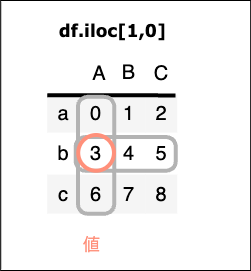
df.iloc[行番号,列番号]
特定の行と列を番号で指定 → 値を取得
df.iloc[1,0]
実行結果:3
df.iloc[ [ 行番号リスト ] , [ 列番号リスト ] ]
任意の複数行と複数列をリストで指定 → DataFrameを取得
df.iloc[[0,2],[0,2]]
実行結果
| A | C | |
|---|---|---|
| a | 0 | 2 |
| c | 6 | 8 |

df.iloc[ 行番号スライス , 列番号スライス ]
任意の複数行と複数列をスライスで指定 → DataFrameまたはSeriesを取得
番号なので終了行は含まない。
df.iloc[0:2:2,0:2:1]
実行結果
| A | B | |
|---|---|---|
| a | 0 | 1 |

要素の順次参照
DataFrameはイテラブルではないので、そのままではfor 変数 in イテラブル:に適用できないが、items()を使うことで要素の順次参照をすることができる。
items()はデータフレームを列ごとにタプル化し、(列名, その1列のSeries) のジェネレータを生成する。よって分割代入すると第1変数に列名、第2変数にその1列分の行名 値 行名 値 行名 値 ... が代入される。
for e in df.items():
print(e,end=" ")
実行結果
('A', a 0
b 3
c 6
Name: A, dtype: int64)
('B', a 1
b 4
c 7
Name: B, dtype: int64)
('C', a 2
b 5
c 8
Name: C, dtype: int64)
要素の追加・削除
① 行の追加
df.loc["行名"] = [ , , ]
追加したい行名のインデクスに値リストを追加する。
df = pd.DataFrame(np.arange(9).reshape(3,3),
index=["a","b","c"],
columns=["A","B","C"])
df.loc["d"] = [9,10,11]
df
実行結果
| A | B | C | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| b | 3 | 4 | 5 |
| c | 6 | 7 | 8 |
| d | 9 | 10 | 11 |
② 列の追加
df["列名"] = [ , , ]
追加したい列名のインデクスに値リストを追加する。
df["D"] = [0,0,0]
df
実行結果
| A | B | C | D | |
|---|---|---|---|---|
| a | 0 | 1 | 2 | 0 |
| b | 3 | 4 | 5 | 0 |
| c | 6 | 7 | 8 | 0 |
df.insert( 列番号, "列名", [値リスト] )
列番号で指定した列の直前に、"列名"という列を作成し、[値リスト]を追加する。
df.insert(2,"X",[0,0,0])
df
実行結果
| A | B | X | C | |
|---|---|---|---|---|
| a | 0 | 1 | 0 | 2 |
| b | 3 | 4 | 0 | 5 |
| c | 6 | 7 | 0 | 8 |
演算結果の追加
df["新列名"] = df["列名"]を使った式
既存の列名を使って演算子を適用したものを、新しい列名を使ったインデクスに代入する。
以下の例では、quantity(数量),price(価格)の値の積から、新たにtotalという列を追加する。
df = pd.DataFrame([[2,300],[1,500],[4,100]],columns=["quantity","price"])
df["total"] = df["quantity"] * df["price"]
df
実行結果
| quantity | price | total | |
|---|---|---|---|
| 0 | 2 | 300 | 600 |
| 1 | 1 | 500 | 500 |
| 2 | 4 | 100 | 400 |
③ 行の削除
df.drop("行名")
drop()メソッドに、削除したい行名を第1引数で渡し、キーワード引数axisに行を表す0を渡すと、対象となる列を削除した新しいDataFrameを作成する。
axisのデフォルト値は 行を表す0なので、行を削除したい場合は省略できる。
④ 列の削除
df.drop("列名",axis = 1)
drop()メソッドに、削除したい列名を第1引数で渡し、キーワード引数axisに列を表す1を渡すと、対象となる列を削除した新しいDataFrameを作成する。
axisのデフォルト値は 行を表す0。
df = df.drop("D",axis=1)
del df["列名"]
del df["D"]
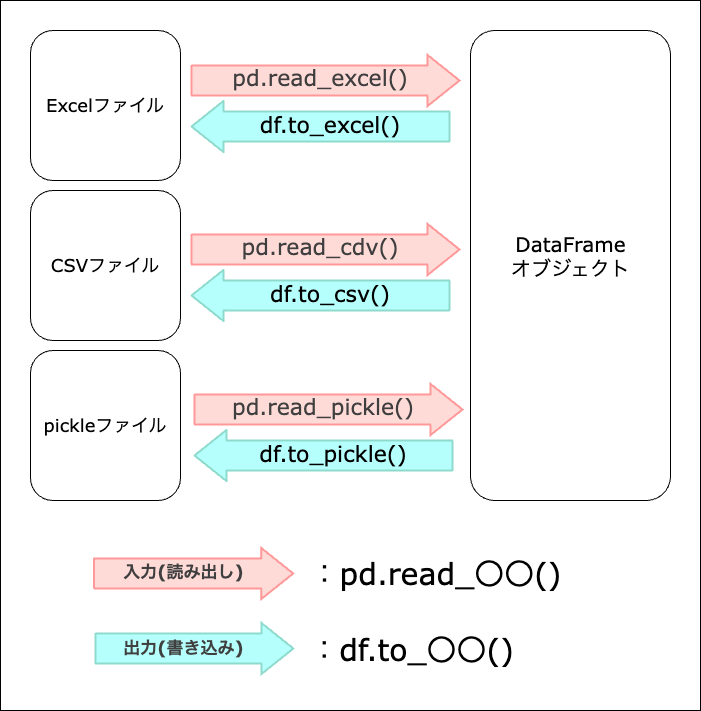
ファイルの入出力
Pandasには、Excel/CSVファイルからDataFrameオブジェクトとしてデータの読み出しをしたり、DataFrameオブジェクトが持つデータをExcel/CSVファイルに出力するための関数・メソッドが用意されている。
Excelファイル
df.to_excel( "~", sheet_name="~" )
DateFrameオブジェクトからExcelファイルを出力する。
-
第1引数:出力するファイル名 -
sheet_name:出力するシート名
まずは次のようなDataFrameを用意する。
df = pd.DataFrame([[80,20,54],[200,72,62],[300,76,84]],
index=["lemon","orange","grapefruit"],
columns=["weight","vitaminC","calories"])
| weight | vitaminC | calories | |
|---|---|---|---|
| lemon | 80 | 20 | 54 |
| orange | 200 | 72 | 62 |
| grapefruit | 300 | 76 | 84 |
このDataFrameをnutrition.xlsxという名前のExcelファイルとして出力する。
df.to_excel("nutrition.xlsx",sheet_name="fruit")
これを実行すると同じフォルダにファイルnutrition.xlsxが作成され、以下のような内容のシートfruitが作成される。

pd.read_excel( "~", sheet_name="~", index_col=0 )
-
第1引数:読み込むファイル名 -
sheet_name:読み込むシート名 -
index_col=0:先頭列(第0行)をindexとして使用する
df = pd.read_excel("nutrition.xlsx",sheet_name="fruit",index_col=0)
Excelファイルnutrition.xlsx内のシートfruitを読み込んでDataFrameに格納する。その際、第0列の値をindexとして使用する。
df.to_csv("nutrition.csv",sep=",")
nutrition.csvというCSVファイルがという名前のファイルが作成され、dfのデータが出力される。
CSVファイル
df.to_csv( "~", sep="," )
DateFrameオブジェクトからCSVファイルを出力する。
-
第1引数:出力するファイル名 -
sep=",":区切り文字として,を設定
pd.read_csv( "~", sep=",", index_col=0, encoding="~" )
-
第1引数:読み込むファイル名 -
sep=",":区切り文字として,を設定 -
index_col=0:先頭列(第0行)をindexとして使用する -
encoding:UTF-8以外の文字コードを使用している場合は"shift-jis"
df = pd.read_csv("nutrition.csv",sep=",",index_col=0)
pickleファイル
pickleとは
データを直列化(シリアライズ)することで、オブジェクトの状態を保ったまま保存・復元することのできるPythonのモジュールのこと。シリアライズとは、メモリ上に散らばって存在しているオブジェクトを一連の連続したビット列へ変換すること。テキスト化(人間が目で見てわかる形式にすること)をしないので入出力処理を高速に行うことができるという利点があり、学習済みモデルや前処理済みデータを再利用する場合など、処理速度を優先して人間が読む必要がないデータ形式にしたいときに使う。
df.to_pickle( "~" )
DateFrameオブジェクトからpickleファイルを出力する。
-
第1引数:出力するファイル名
df.to_pickle("nutrition.pickle")
pd.read_pickle( "~" )
-
第1引数:読み込むファイル名
df = pd.read_pickle("nutrition.pickle")
欠損値
欠損値があると予期せぬ計算結果になる可能性があるので、データ分析の前処理として欠損値の処理をする必要がある。
欠損値の種類
- None(NoneType):Pythonの欠損値
- NaN(Not a Number): Numpyの欠損値
- NaT(Not a Time): Pandasの日時データに関する欠損値
欠損値の調べ方
isnull()
isnull()は、要素が欠損値であればTrue、欠損値でなければFalseを格納したDataFrameを作成する。
df = pd.DataFrame([[np.NaN,1,2],[3,4,5],[6,7,np.NaN]],
index=["a","b","c"],
columns=["A","B","C"])
df.isnull()
実行結果
| A | B | C | |
|---|---|---|---|
| a | True | False | False |
| b | False | False | False |
| c | False | False | True |
df.isnull()に対してany()メソッドを適用すると、列ごとに欠損値が存在するかどうか調べ、bool値のSeriesを作成する。
df.isnull().any()
実行結果
A True
B False
C True
dtype: bool
df.isnull()に対してsum()メソッドを適用すると、列ごとにTrueの合計数の一覧を格納したSeriesを作成する。
df.isnull().sum()
実行結果
A 1
B 0
C 1
dtype: int64
このSeriesに対して再びsum()を適用すればDataFrame全体の欠損値の合計数を求めることができる。
df.isnull().sum().sum()
実行結果:2
欠損値の処理
df.dropna()
欠損値の行を削除した、新しいDataFrameを作成する。
df = pd.DataFrame([[0,1,2],[3,np.NAN,5],[6,7,8]],
index=["a","b","c"],
columns=["A","B","C"])
df = df.dropna()
欠損値のあるb行が削除される。
| A | B | C | |
|---|---|---|---|
| a | 0 | 1.0 | 2 |
| c | 6 | 7.0 | 8 |
df.ffill()
欠損値を一つ手前の値で補完する。
ただし、1行目に欠損値がある場合は補完されない。
df = pd.DataFrame([[np.NAN,1,2],[3,np.NAN,5],[6,7,8]],
index=["a","b","c"],
columns=["A","B","C"])
df.ffill()
b行の欠損値は一つ上の値で補完されたが、
a行の欠損値は補完されない。
| A | B | C | |
|---|---|---|---|
| a | NaN | 1.0 | 2 |
| b | 3.0 | 1.0 | 5 |
| c | 6.0 | 7.0 | 8 |
df.bfill()
欠損値を一つ後ろの値で補完する。
ただし、末尾行に欠損値がある場合は補完されない。
df = pd.DataFrame([[0,1,2],[3,np.NaN,5],[6,7,np.NaN]],
index=["a","b","c"],
columns=["A","B","C"])
df.bfill()
b行の欠損値は一つ下の値で補完されたが、
c行の欠損値は補完されない。
| A | B | C | |
|---|---|---|---|
| a | 0 | 1.0 | 2.0 |
| b | 3 | 7.0 | 5.0 |
| c | 6 | 7.0 | NaN |
df.fillna(~)
欠損値を引数で指定した値で補完する。
引数の例
0で補完:0
平均値で補完:df.mean()
中央値で補完:df.median()
最頻値で補完:df.mode().iloc[0]
欠損値を最頻値で補完する
列ごとの最頻値を格納したDataFrameを作成するメソッド。
同率首位の場合は複数出力する。
df = pd.DataFrame([[np.NaN,2,2],[1,3,2],[1,4,3],[1,5,3]])
df.mode()
第0列は単独首位だが、第1列・第2列は同列首位。
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.0 | 2 | 2.0 |
| 1 | NaN | 3 | 3.0 |
| 2 | NaN | 4 | NaN |
| 3 | NaN | 5 | NaN |
このDataFrameからiloc[0,:]で先頭行の全列を指定すれば最頻値の行データを取得できる。
df.mode().iloc[0] # 全列選択を表す : は省略できる
実行結果
0 1.0
1 2.0
2 2.0
Name: 0, dtype: float64
この結果を元のDataFrameのfillna()メソッドの引数に渡せば、欠損値をその列の最頻値で補完することができる。
df = pd.DataFrame([[np.NaN,2,2],[1,3,2],[1,4,3],[1,5,3]])
df.fillna(df.mode().iloc[0])
実行結果
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.0 | 2 | 2 |
| 1 | 1.0 | 3 | 2 |
| 2 | 1.0 | 4 | 3 |
| 3 | 1.0 | 5 | 3 |
DataFrameの連結
複数のDataFrameの連結にはpd.concat()関数を使う。
-
第1引数:連結したいDataFrameのリスト -
axis:列方向(横)に連結する場合は1、行方向(縦)の場合は0または指定なし -
sort:連結後に見出し語によるソートを行う場合はTrue
連結する方向によってキーワード引数axisに渡す値を変える。
列方向(横)に連結
pd.concat()関数にaxis=1を渡す
df1 = pd.DataFrame(np.arange(6).reshape(3,2),
index=["a","b","c"],
columns=["A","B"])
df2 = pd.DataFrame(np.arange(6,12).reshape(3,2),
index=["a","b","c"],
columns=["C","D"])
pd.concat([df1,df2],axis=1)
実行結果
| A | B | C | D | |
|---|---|---|---|---|
| a | 0 | 1 | 6 | 7 |
| b | 2 | 3 | 8 | 9 |
| c | 4 | 5 | 10 | 11 |
行方向(縦)に連結
pd.concat()関数にaxis=0を渡す
df1 = pd.DataFrame(np.arange(6).reshape(2,3),
index=["a","b"],
columns=["A","B","C"])
df2 = pd.DataFrame(np.arange(6,12).reshape(2,3),
index=["c","d"],
columns=["A","B","C"])
pd.concat([df1,df2],axis=0)
実行結果
| A | B | C | |
|---|---|---|---|
| a | 0 | 1 | 2 |
| b | 3 | 4 | 5 |
| c | 6 | 7 | 8 |
| d | 9 | 10 | 11 |
df1 = pd.DataFrame(np.arange(6).reshape(2,3),
index=["a","b"],
columns=["A","B","C"])
df2 = pd.DataFrame(np.arange(6,12).reshape(2,3),
index=["c","d"],
columns=["D","E","F"])
pd.concat([df1,df2])
実行結果
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | NaN | NaN | NaN |
| b | 3.0 | 4.0 | 5.0 | NaN | NaN | NaN |
| c | NaN | NaN | NaN | 6.0 | 7.0 | 8.0 |
| d | NaN | NaN | NaN | 9.0 | 10.0 | 11.0 |
グループ化
要素の値が同じもの同士でグループ化し、合計や平均などの集計値を求める時に使えるのがdf.groupby()。このメソッドの戻り値はDataFrameGroupByオブジェクトというもので、この型が持つget_group()メソッドからグループ化されたDataFrameを取得したり、sum()、mean()などのメソッドからグループごとの集計を求めることができる。

まず以下のようなDataFrameを用意する。
df = pd.DataFrame([["男",32,"総務"],
["男",45,"人事"],
["女",31,"人事"],
["男",29,"営業"],
["女",38,"営業"],
["女",43,"人事"]],
index=[0,1,2,3,4,5],
columns=["性別","年齢","部署"])
| 性別 | 年齢 | 部署 | |
|---|---|---|---|
| 0 | 男 | 32 | 総務 |
| 1 | 男 | 45 | 人事 |
| 2 | 女 | 31 | 人事 |
| 3 | 男 | 29 | 営業 |
| 4 | 女 | 38 | 営業 |
| 5 | 女 | 43 | 人事 |
df.groupby( "列名" )
引数で受け取った列名から、その列の値を基準にグループ分けを行いDataFrameGroupByオブジェクトを生成する。
例えば上のdfを部署ごとにグループ分けして集計したい場合は、df.groupby()メソッドの引数に列名"部署"を指定する。
df.groupby("部署")
これを実行するとDataFrameGroupByオブジェクトを取得し、このオブジェクトの持つメソッドを使って様々な集計ができる。
.get_group("値")
グループ分け後、引数で受け取った要素の値のグループを抽出してDataFrameを作成する。
dfを部署ごとにグループ分けした後、"人事"のグループのDataFrameを取得する。
df.groupby("部署").get_group("人事")
実行結果
| 性別 | 年齢 | 部署 | |
|---|---|---|---|
| 1 | 男 | 45 | 人事 |
| 2 | 女 | 31 | 人事 |
| 5 | 女 | 43 | 人事 |
size()
各グループの要素数を集計したSeriesを取得する。
各グループの値がindex名となる。
df.groupby("部署").size()
部署
人事 3
営業 2
総務 1
dtype: int64
人事の行数を得るならSeriesからloc[]で行名指定する。
df.groupby("部署").size().loc["人事"]
実行結果:3
count()
各グループの要素数を集計したDataFrameを取得する。
各グループの値がindex名に、他の列名がcolumns名になり、各列ごとに要素数を集計する。
df.groupby("部署").count()
実行結果
| 性別 | 年齢 | |
|---|---|---|
| 部署 | ||
| 人事 | 3 | 3 |
| 営業 | 2 | 2 |
| 総務 | 1 | 1 |
グループの値も1つの列として作成したい場合は、df.groupby()の引数にas_index=Falseと指定する。
df.groupby("部署",as_index=False).count()
実行結果
| 部署 | 性別 | 年齢 | |
|---|---|---|---|
| 0 | 人事 | 3 | 3 |
| 1 | 営業 | 2 | 2 |
| 2 | 総務 | 1 | 1 |
grp.first()
各グループの 先頭1行のDataFrameを取得する。
grp.last()
各グループの 末尾1行のDataFrameを取得する。
各種集計
グールプ分け後、各列の値を集計する。
sum(),min(),max(),mean()などがあり、数値の要素を集計する。
要素が文字列の場合は以下のような計算になる。
-
sum():文字列同士の連結 -
min():文字コードの比較 -
max():文字コードの比較 -
mean():TypeError
grp.sum()
実行結果
| 性別 | 年齢 | |
|---|---|---|
| 部署 | ||
| 人事 | 男女女 | 119 |
| 営業 | 男女 | 67 |
| 総務 | 男 | 32 |
grp.min()
実行結果
| 性別 | 年齢 | |
|---|---|---|
| 部署 | ||
| 人事 | 女 | 31 |
| 営業 | 女 | 29 |
| 総務 | 男 | 32 |
人事部の平均年齢
f"{grp.get_group("人事")["年齢"].mean():.1f}歳"
実行結果: 39.7歳
ピボットテーブル
大量の列を持つDataFrameから、どの列を値・行・列にするのかを選択し、テーブルを自分の見たい形に生成することができる機能。
df.pivot_table( values=[ 列 ], index=[ 列 ], columns=[ 列 ] )
-
values:表示する値に使用する列を指定する -
index:行として使用する列名を指定する -
columns:列として使用する列名を指定する -
aggfunc:集計する関数を文字列で指定する("sum","mean"など) -
fill_value:欠損値の値を指定する
以下のようなデータを例に考える。
data = {
"注文ID": [1,2,3,4,5,6,7,8,9,10,11,12],
"顧客": ["田中","田中","鈴木","鈴木","佐藤","佐藤","田中","鈴木","佐藤","田中","鈴木","佐藤"],
"地域": ["東京","東京","大阪","大阪","名古屋","名古屋","東京","大阪","名古屋","東京","大阪","名古屋"],
"支払い方法": ["クレジット","現金","クレジット","現金","クレジット","現金",
"クレジット","クレジット","現金","現金","現金","クレジット"],
"購入商品": ["PC","イヤホン","PC","スマホ","スマホ","PC","イヤホン","PC","スマホ","イヤホン","スマホ","PC"],
"金額": [120000,8000,110000,90000,95000,100000,7000,115000,88000,7500,87000,98000]
}
df = pd.DataFrame(data)
| 顧客 | 地域 | 支払い方法 | 購入商品 | 金額 | |
|---|---|---|---|---|---|
| 0 | 田中 | 東京 | クレジット | PC | 120000 |
| 1 | 田中 | 東京 | 現金 | イヤホン | 8000 |
| 2 | 鈴木 | 大阪 | クレジット | PC | 110000 |
| 3 | 鈴木 | 大阪 | 現金 | スマホ | 90000 |
| 4 | 佐藤 | 名古屋 | クレジット | スマホ | 95000 |
| 5 | 佐藤 | 名古屋 | 現金 | PC | 100000 |
| 6 | 田中 | 東京 | クレジット | イヤホン | 7000 |
| 7 | 鈴木 | 大阪 | クレジット | PC | 115000 |
| 8 | 佐藤 | 名古屋 | 現金 | スマホ | 88000 |
| 9 | 田中 | 東京 | 現金 | イヤホン | 7500 |
| 10 | 鈴木 | 大阪 | 現金 | スマホ | 87000 |
| 11 | 佐藤 | 名古屋 | クレジット | PC | 98000 |
この表から顧客別に支払い方法の平均金額を集計するには
行見出しに使用する列は顧客、列見出しに使用する列は支払い方法、値には金額、集計関数に"mean"を指定する。
df.pivot_table(values="金額",index="顧客",columns="支払い方法",aggfunc="mean")
実行結果
| 支払い方法 | クレジット | 現金 |
|---|---|---|
| 顧客 | ||
| 佐藤 | 96500.0 | 94000.0 |
| 田中 | 63500.0 | 7750.0 |
| 鈴木 | 112500.0 | 88500.0 |
aggfuncには複数の集計関数をリストにして渡すこともできる。
pd.pivot_table(df, values="金額", index="地域", columns="購入商品", aggfunc=["sum", "mean"], fill_value=0)
実行結果
| sum | mean | |||||
|---|---|---|---|---|---|---|
| 購入商品 | PC | イヤホン | スマホ | PC | イヤホン | スマホ |
| 地域 | ||||||
| 名古屋 | 198000 | 0 | 183000 | 99000.0 | 0.0 | 91500.0 |
| 大阪 | 225000 | 0 | 177000 | 112500.0 | 0.0 | 88500.0 |
| 東京 | 120000 | 22500 | 0 | 120000.0 | 7500.0 | 0.0 |
地域別に購入商品の金額合計を表示する。
df.pivot_table(values="金額",index="地域",columns="購入商品",aggfunc="sum",fill_value=0)
実行結果
| 購入商品 | PC | イヤホン | スマホ |
|---|---|---|---|
| 地域 | |||
| 名古屋 | 198000 | 0 | 183000 |
| 大阪 | 225000 | 0 | 177000 |
| 東京 | 120000 | 22500 | 0 |
関数を適用する
SeriesやDataFrameには、各要素・各行・各列に対して関数を適用し、その結果を格納するSeriesやDataFrameを作成するためのメソッドがある。
- Series:
apply()map() - DataFrame:
apply()
(DataFrameにはapplymap()もあるが廃止予定)
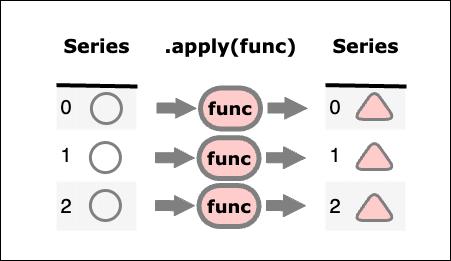
Series型.apply(func)
Seriesの要素それぞれに関数を適用し、その戻り値を要素とするSeriesを作成する。
以下のようなDataFrameがあるとする。
| name | height | weight | |
|---|---|---|---|
| 0 | Sato | 160.0 | 60 |
| 1 | Tanaka | 170.0 | 50 |
| 2 | Nakamura | NaN | NaN |
この"weight"の値から洋服の重さ1kgを除いた正味の体重を表す列を作成する。関数net_weight()を定義し、dfから取り出した"weight"カラム(Series型)のapply()`に、この関数を引数として渡す。
df = pd.DataFrame({
"name" : ["Sato","Tanaka","Nakamura"],
"height" : [160,170,np.nan],
"weight" : [60,50,np.nan]
}
)
def net_weight(weight):
return weight - 1
df["weight"].apply(net_weight)
実行結果
0 59.0
1 49.0
2 NaN
Name: weight, dtype: int64
これと同じコードを、ラムダ式を使って書くこともできる。
df["weight"].apply(lambda w: w - 1)
Series型であれば、ラムダ式の中にif文を書くこともできる。
df["weight"].apply(lambda w: w - 1 if np.isnan(w) == False else "-")
実行結果
0 59.0
1 49.0
2 -
Name: weight, dtype: object
Series型.map(func)
関数の引数が1つのみの場合なら、apply()と同じようにmap()を使って、Seriesの要素に関数を適用することができる。
df["weight"].map(net_weight)
df["weight"].map(lambda w: w - 1 if np.isnan(w) == False else "-")
それぞれapply()と同じ結果となる。
またmap()にのみ欠損値を無視するためのキーワード引数があり、na_action=ignoreと指定すれば欠損値が関数に渡されることはない。
df["weight"].map(net_weight,na_action="ignore")
実行結果
0 59.0
1 49.0
2 NaN
Name: weight, dtype: float64
Series型.apply(func,引数指定)
関数が2つ以上の引数を取る場合、引数を指定する方法が2つある。
-
applyのキーワード引数argsにタプルで引数を渡す -
applyの引数に、関数で定義された引数名を使ってキーワード引数として渡す
※タプルの場合、要素数1の場合もカンマが必要であることに注意する。
例えば、関数net_weight()の除数1を、引数で受け取る値として引数名xに変更し、身長カラムにこの関数を適用する際にxの値も指定できるようにする。
def net_weight(weight,x):
return weight - x
df["weight"].apply(net_weight,args=(0.5,)) # カンマ必要
df["weight"].apply(net_weight,x=0.5)
# applyを使わない場合
net_weight(df["weight"],0.5)
いずれも同じ結果となる。
実行結果
0 59.5
1 49.5
2 NaN
Name: weight, dtype: float64
これと同じことをmap()でやろうとするとエラーになる。
適用する関数の引数が複数の場合、apply()は使えるがmap()は使えない。
Series型.map(dict)
Seriesの要素の値と、引数で渡された辞書のキーとをマッピングし、辞書の値を要素とするSeriesを作成する。
map()のみ可能で、引数に辞書を渡す。
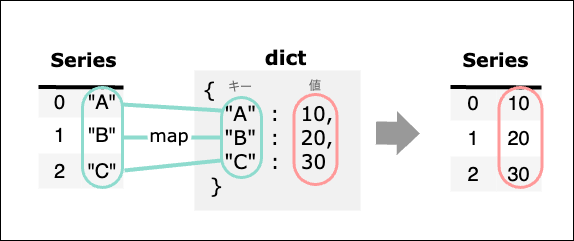
dfの"name"カラムの値をキー、年齢を値とする辞書を定義し、dfの"name"カラム(Series)の持つmap()の引数に渡すと、Seriesの値と辞書のキーをマッピングし、辞書の値を要素とするSeries型が作成される。
dict = {
"Sato" : "20",
"Tanaka" : "38",
"Nakamura" : "45",
}
df["name"].map(dict)
実行結果
0 20
1 38
2 45
Name: name, dtype: object
DataFrame型.apply(func,axis=0)
DataFrameの持つapply()は行ごとまたは列ごと(デフォルトは列ごと)に関数を適用し、その結果(Series)を縦方向または横方向に連結したDataFrameを返す。
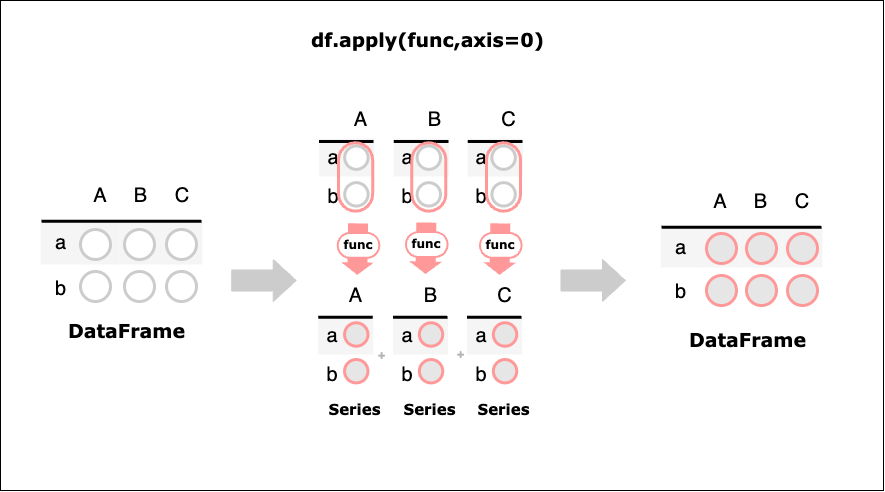
以下のように、値を2乗する関数calcをDataFrameのapply()メソッドに渡す。
df = pd.DataFrame([[1,2,3],[1,2,3]])
def calc(x):
return x * x
df.apply(calc,axis=1)
実行結果
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 4 | 9 |
| 1 | 1 | 4 | 9 |
各要素を2乗したDataFrameが生成されたが、これは行に対して関数を適用した結果のSeriesを横に連結してDataFrameを作成しているのであって、「各要素に対して関数を適用している」というわけではない。
同じことをラムダ式を使って書くこともできる。
df.apply(lambda x : x * x,axis=1)
実行結果
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 4 | 9 |
| 1 | 1 | 4 | 9 |
DataFrame型.apply(集約関数,axis=0)
適用する関数に、単一の値を返す集約関数を指定した場合、列ごとまたは行ごとに関数を適用し、その結果の値を要素とするSeries型を作成する。
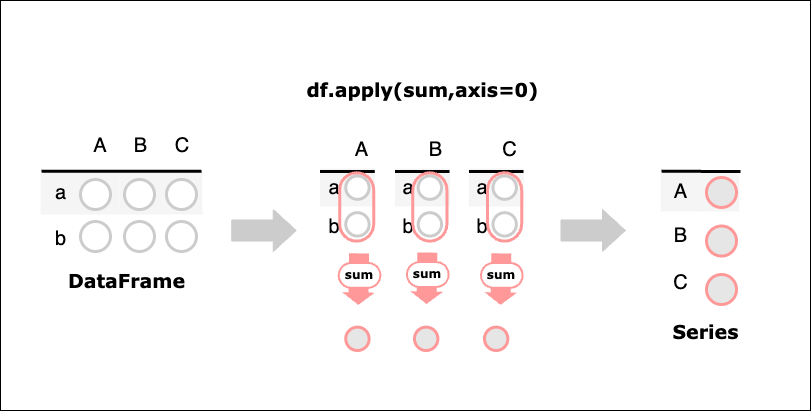
次のDataFrameの要素を列ごと・列ごとに合計する。
df = pd.DataFrame([[1,2,3],[1,2,3]])
df.apply(sum,axis=0)
df.apply(sum,axis=1)
実行結果 (axis=0)
0 2
1 4
2 6
dtype: int64
実行結果 (axis=1)
0 6
1 6
dtype: int64
axis=0は列ごと、axis=1は行ごとにsum関数に渡され、結果の値を要素とするSeriesを作成する。
複数列を引数として渡す
apply()を使って、適用したい関数の引数に複数列を渡したい場合は、以下のようにする。
-
DataFrameから
apply()メソッドを呼ぶ -
apply()に渡す関数の引数をDataFrameにして、関数の中で列参照をする -
apply()のキーワード引数axisに列指定を表す1を指定
例えば、「身長カラムと体重カラムをcalc_bmi()関数に渡して、その計算結果をbmiカラムとして新しく追加する」というコードをapply()を使って書くと、
# applyに渡す関数の引数をdfにして、関数内で列参照する
def calc_bmi(df):
height = df["height"] / 100
return round(df["weight"] / (height * height),2)
# dfからapplyを呼び、axisに列指定の 1
df["bmi"] = df.apply(calc_bmi,axis=1)
ちなみにapply()を使わず、関数の引数に列を指定する方法でも書ける。
df["bmi"] = calc_bmi(df["height"],df["weight"])
実行結果
| height | weight | bmi | |
|---|---|---|---|
| 0 | 160 | 50.0 | 19.53 |
| 1 | 170 | 70.0 | 24.22 |
| 2 | 180 | NaN | NaN |
ユニバーサルファンクション関数
Numpyのユニバーサルファンクション関数の引数にSeriesやDataFrameを渡すことができる。
df = pd.DataFrame(np.array([[-1,2],[3,-4]]))
np.abs(df) # DataFrame
np.abs(df[0]) # Series
実行結果
| 0 | 1 | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
0 1
1 3
Name: 0, dtype: int64