データ分析したいけど、DWH(データウェアハウス)を導入するとなると大げさだなぁ、くらいのタイミングでライトに始められるデータ分析基盤を考えてみました。
アーキテクチャ
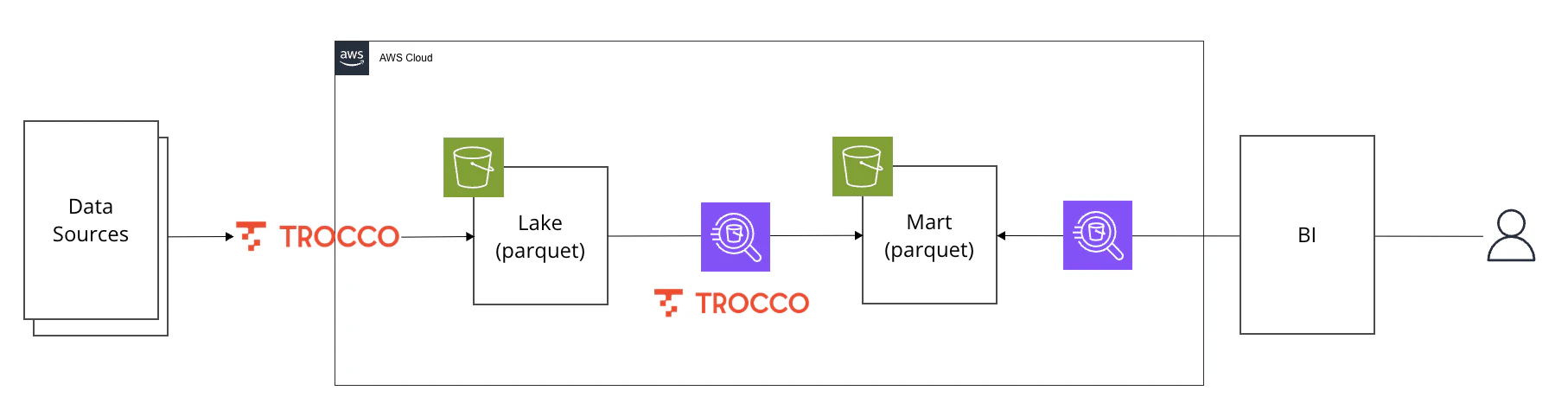
Amazon AthenaはS3上のファイルに直接クエリできて、スキャン量のみのオンデマンド課金なのでランニングコストがかからず、今回の目的に合致していそうです。
本記事ではデータマート作成までを扱います。
データレイク構築
S3へのデータ収集手段として、無料プランのあるTROCCO® を利用します。
TROCCOのデータ転送先として「S3」とは別に「S3 parquet」という選択肢があります。
こちらは、ファイル形式をparquetに変換してくれるだけでなく、裏側でAWS GlueのジョブをキックしAthenaで参照できるカタログを自動生成してくれる便利機能が備わっています。
HTTP APIで取得できるオープンデータを使って、データ収集を試してみましょう。

公式ドキュメントに従って転送元/転送先の情報を入力していきます。
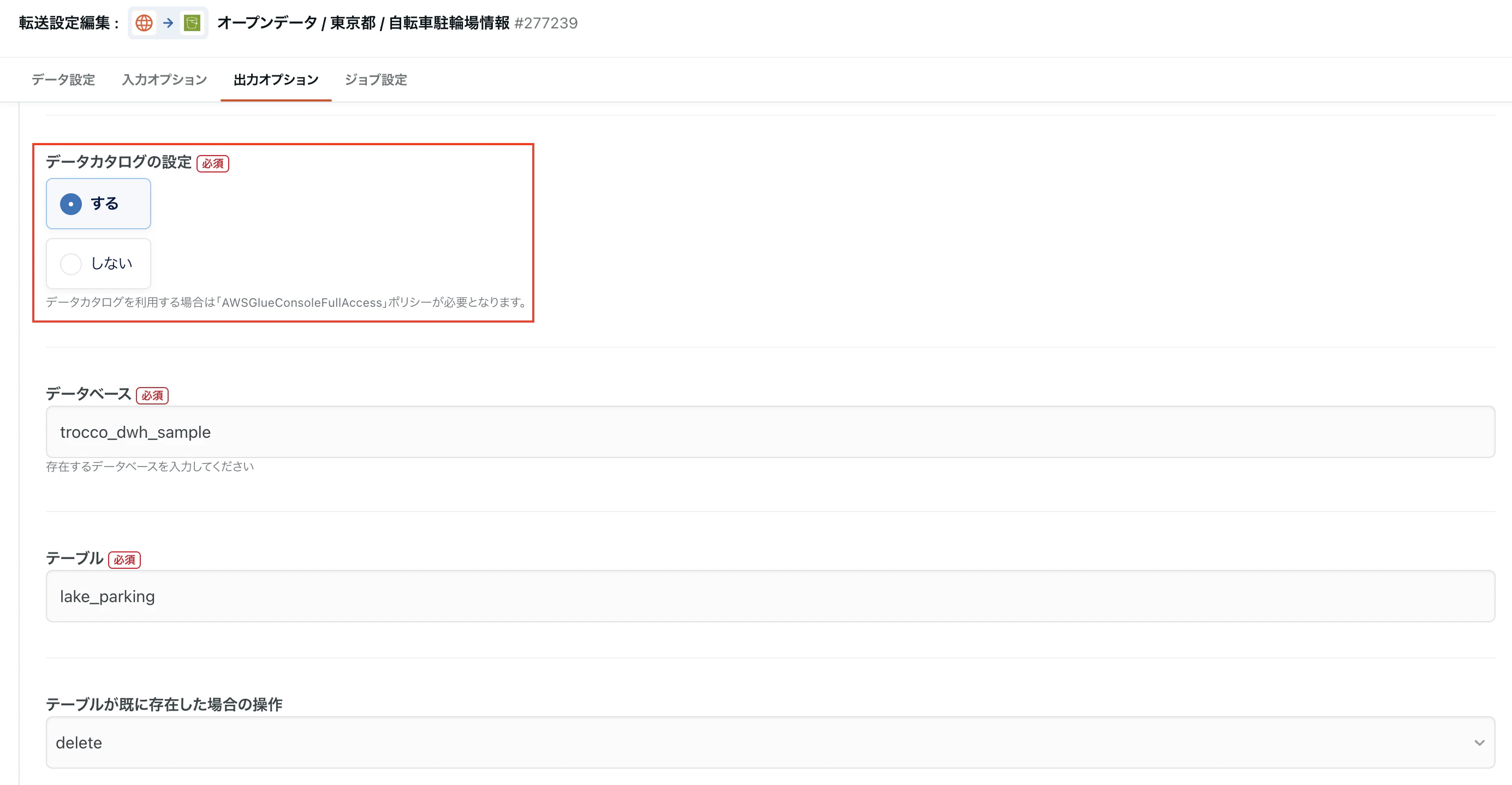
転送設定作成フォームのStep2 にて「出力オプション」のタブを選択すると、「データカタログの設定」という項目があります。こちらを有効化することで、Glueカタログジョブを自動実行することが可能になります。
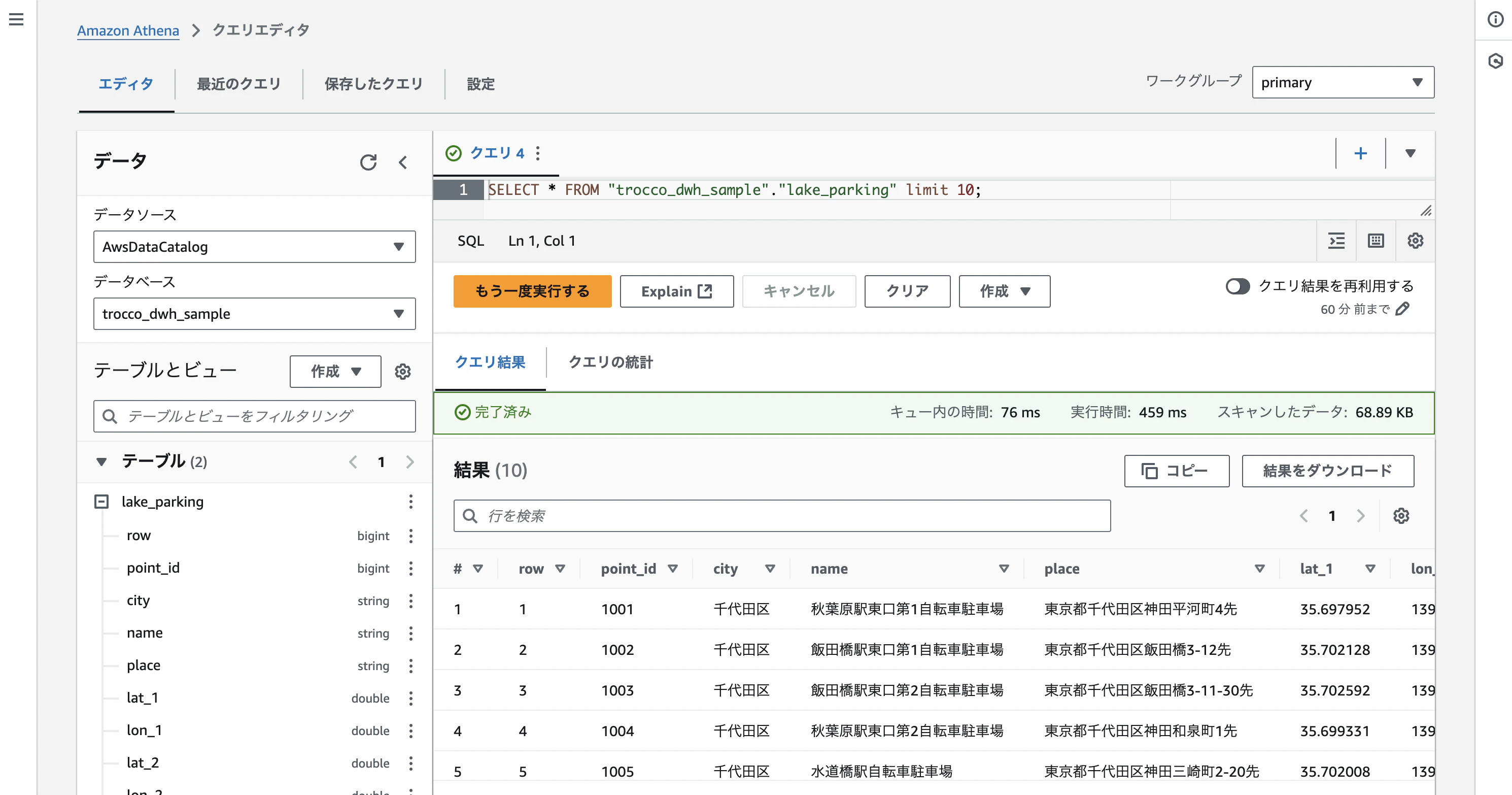
データ転送を実行すると、Athena上でテーブルが作成されクエリ可能になります。
データマート化
転送元: Athena を指定すると、Athenaに対してクエリした結果を転送先に送ることができます。
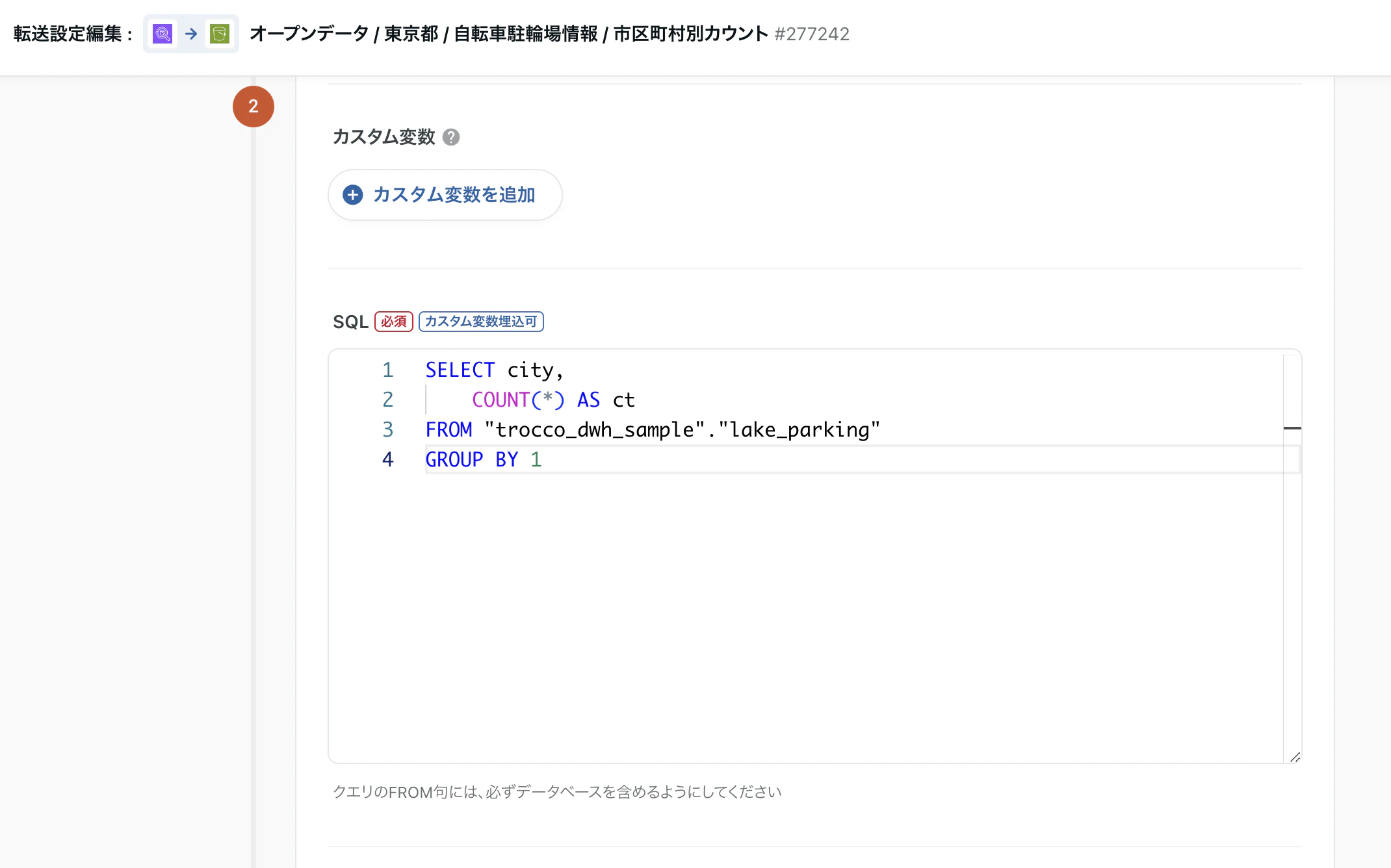
複数のテーブルを結合するなど、SQLを用いた柔軟なデータ加工が可能です。
クエリ結果は先ほどと同様に、再度S3に配置しGlueカタログ化します。
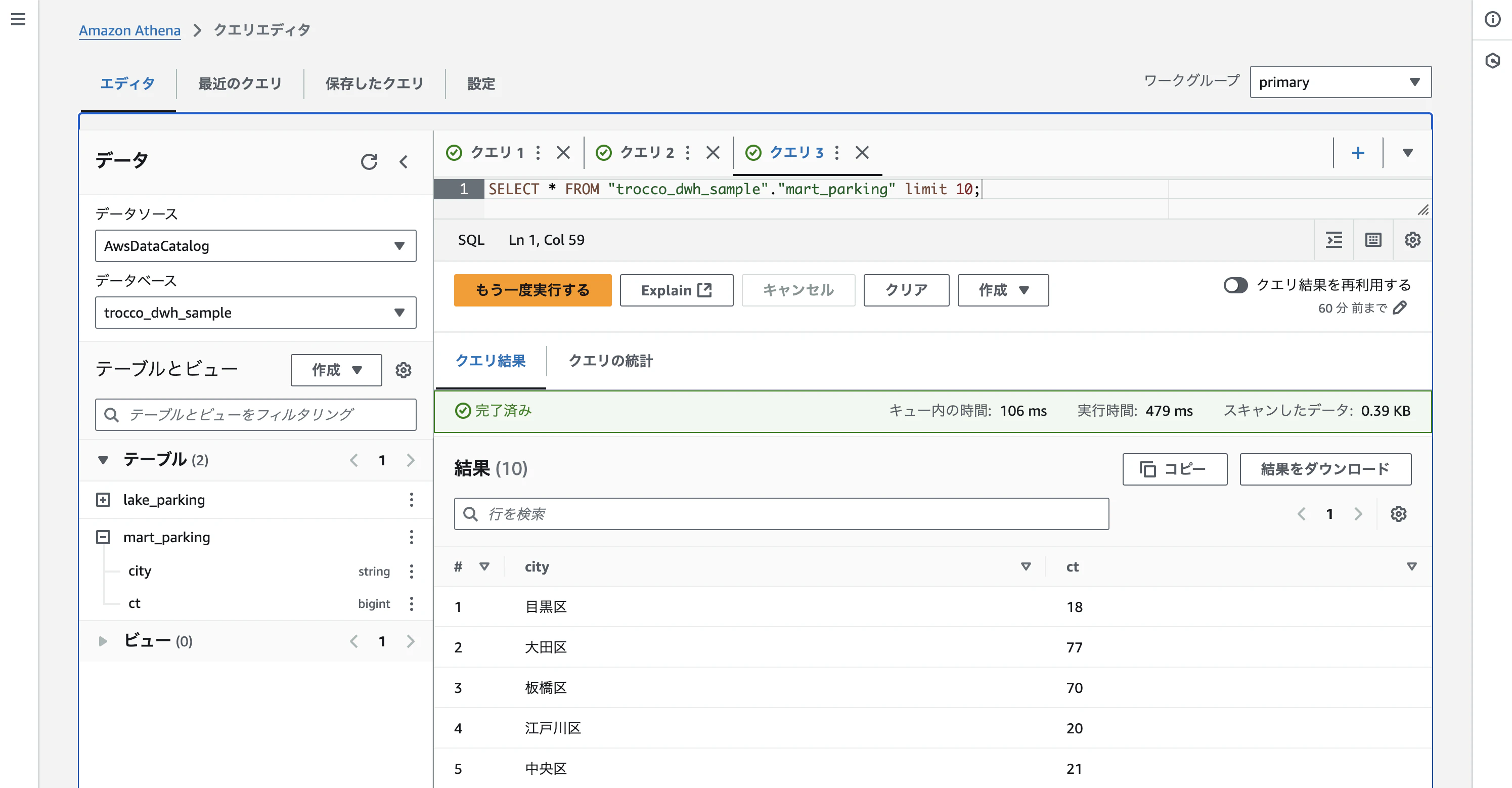
加工後のデータもAthena上でクエリできました。
データパイプライン管理
Lake→Martの2つの処理を直列に配置します。
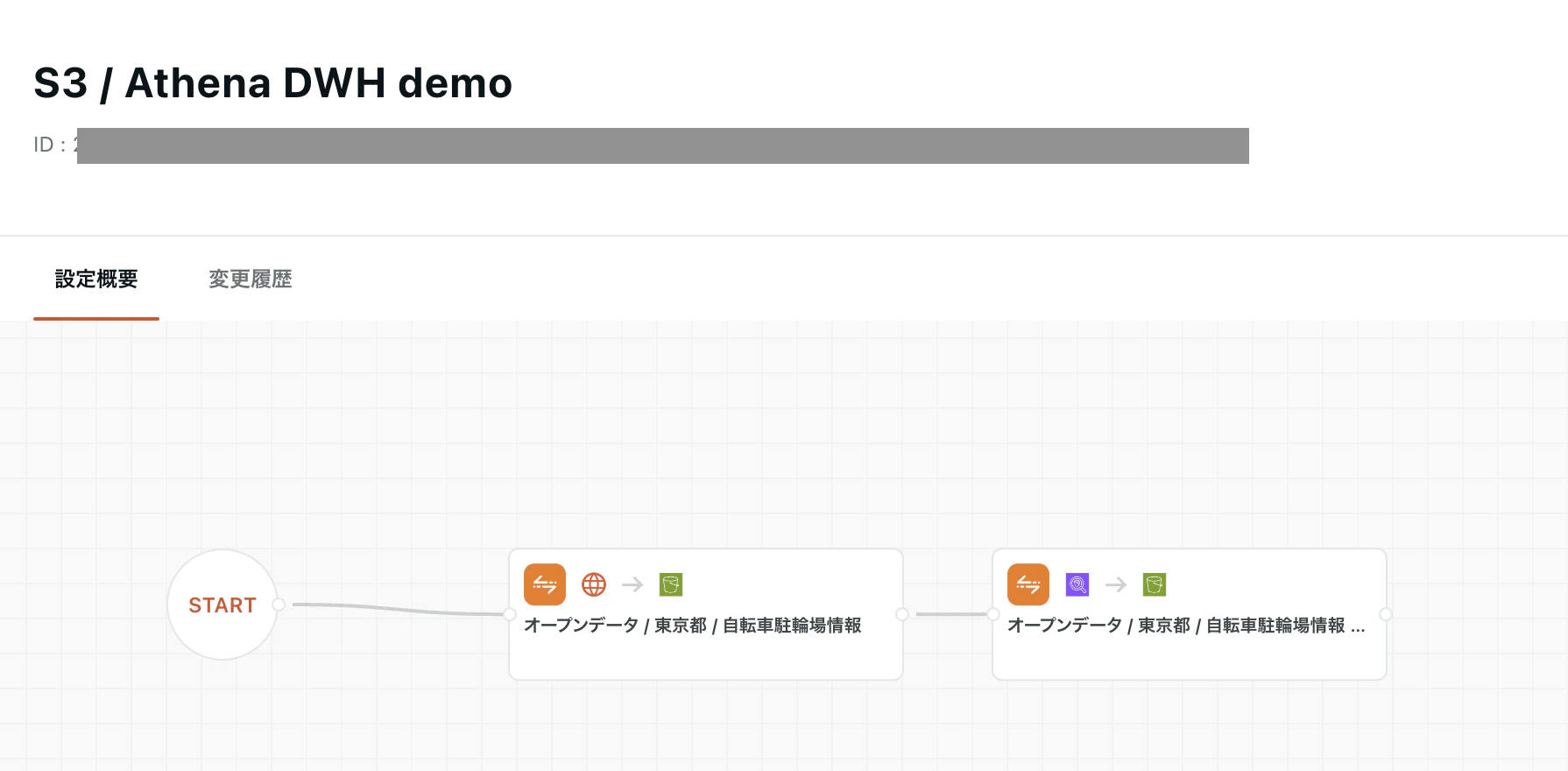
データソースからのデータ取得が完了すると、後続の集計処理が自動で実行されます。
ワークフローにスケジュール設定を追加することで、毎日最新のデータをマートテーブルに反映することができます。
まとめ
S3をベースに、クイックに一定のスケーラビリティを持ったデータ活用環境を立ち上げることができました。
parquetデータ形式は列志向で圧縮効率に優れ、大規模なデータセットにおける分析利用にも対応しやすいフォーマットです。
Icebergテーブルの実データ形式としても採用されているため、今回構築したS3上のデータをIceberg化して別サービスから参照するような形を取れば、スムーズに中〜大規模なアーキテクチャへも移行していけそうですね。