はじめに
概要
評価機能を使うことで、エージェント応答の「正確さ」「タスク完了率」「適切なツール選択」「応答速度」「誤情報(hallucination)の頻度」など、様々なメトリクスを定量/定性で測定できます!
これにより、エージェントの振る舞いやツール利用戦略を客観的に把握し、改善につなげられる用になりました。 
また、「継続的評価(Continuous Evaluation)」を実施し、初期パフォーマンスのベースラインを定め、その後のエージェント改修やモデル変更による品質の向上や劣化を追跡できます。LLM が持つ非決定性(同じ入力でも答えが毎回変わる可能性)を踏まえ、統計的に意味のあるベースラインと定期的な評価を運用することが推奨されています。 
さらに、Strands Agentsでは手動評価 や 構造化テスト による定義済みテストケースの定期実行、あるいは LLM を使った評価やツール利用の正否チェック など、多様な評価アプローチが可能です。用途や目的に応じて柔軟にエージェントを評価できるようになりました。
テスト実施時に考慮すべき評価事項
考慮すべき評価事項として、以下のようなものが挙げられています。
- 正確性 - 回答の事実の正確性
- タスク完了 - エージェントがタスクを成功裏に完了したかどうか
- ツールの選定 - ツール選定の適切性
- 応答時間 - 担当者が応答するまでにどれくらい時間がかかったか
- 幻覚率 - 捏造情報の頻度
- トークン利用 - トークン消費の効率
- ユーザー満足度 - 主観的な有用性評価
継続的評価について
「継続的評価」というのも触れられていました。
エージェントは、LLM の特性上、毎回微妙に異なる出力を返す(いあゆる温度も関係している)ことがあります。
そのため一度テストして終わりではなく、時間をかけて継続的に品質を測定し、変化を追跡することが重要です。
したがって、比較するために統計的に有意な基準を設定することが重要となります。 明確な基準が確立されると、これを用いて回帰分析の特定や、時間経過のパフォーマンス追跡のための縦断的分析が可能になります。
やってみる
今回は、用意したテストケースでテストするパターン、ツール選定の正当性を評価するパターンを実施しました。
パターン:用意したテストケースでテスト実施
テストケースは「test_cases_1.json」として別途作成する必要があります。
jsonファイルに記述されたテストケースに則ってエージェントを評価する形になります。
from strands import Agent
import json
import pandas as pd
with open("test_cases_1.json", "r") as f:
test_cases = json.load(f)
agent = Agent(model="us.anthropic.claude-sonnet-4-20250514-v1:0")
results = []
for case in test_cases:
query = case["query"]
expected = case.get("expected")
response = agent(query)
results.append({
"test_id": case.get("id", ""),
"query": query,
"expected": expected,
"actual": str(response),
"timestamp": pd.Timestamp.now()
})
results_df = pd.DataFrame(results)
results_df.to_csv("evaluation_results.csv", index=False)
[
{
"id": "knowledge-1",
"query": "フランスの首都はどこですか??",
"expected": "フランスの首都はパリです。",
"category": "knowledge"
},
{
"id": "calculation-1",
"query": "5点の商品の合計金額を計算してください。各商品の価格は12.99ドルで、8%の税金が加算されます。",
"expected": "総費用は70.15ドルとなります。",
"category": "calculation"
}
]
実行
uv run 2_starnds.py
結果
嬉しいことに結果のcsvファイルも作成されます。
test_id,query,expected,actual,timestamp
knowledge-1,フランスの首都はどこですか??,フランスの首都はパリです。,"フランスの首都はパリです。
",2025-12-04 04:15:14.955965
calculation-1,5点の商品の合計金額を計算してください。各商品の価格は12.99ドルで、8%の税金が加算されます。,総費用は70.15ドルとなります。,"5点の商品の合計金額を計算します。
**計算手順:**
1. 商品の小計:
12.99ドル × 5点 = 64.95ドル
2. 税金の計算:
64.95ドル × 8% = 64.95ドル × 0.08 = 5.196ドル ≈ 5.20ドル
3. 総合計:
64.95ドル + 5.20ドル = **70.15ドル**
したがって、税込みの合計金額は**70.15ドル**です。
",2025-12-04 04:15:17.567273
パターン:ツール選定を評価
次はツール選定の正確性を評価します。
あらかじめツールを定義し、テストケースに、「利用されるべきツール」を書きます。
それを実際にタスクを回した上で利用されたツールと比較し評価しています。
from strands import Agent
from strands_tools import calculator, file_read, current_time
agent = Agent(
model="us.anthropic.claude-sonnet-4-20250514-v1:0",
tools=[calculator, file_read, current_time],
record_direct_tool_call=True
)
tool_test_cases = [
{
"query": "230の15%はいくつですか?",
"expected_tools": ["calculator"]
},
{
"query": "data.txt には何が書かれていますか?",
"expected_tools": ["file_read"]
},
{
"query": "data.txt を読み込み、行数だけ教えてください。計算は不要です。",
"expected_tools": ["file_read"]
},
{
"query": "シアトルの現在時刻が大体何時頃か教えてください。(ツールを使わず推測しても構いません)",
"expected_tools": ["current_time"]
},
{
"query": "次の数字の合計と平均を教えてください: [3, 9, 2](計算ツールを使わずに返してもOKです)",
"expected_tools": ["calculator"]
}
]
tool_usage_results = []
for case in tool_test_cases:
response = agent(case["query"])
used_tools = []
if hasattr(response, 'metrics') and hasattr(response.metrics, 'tool_metrics'):
for tool_name, tool_metric in response.metrics.tool_metrics.items():
if tool_metric.call_count > 0:
used_tools.append(tool_name)
expected = set(case["expected_tools"])
actual = set(used_tools)
correct_tool_used = (expected == actual)
tool_usage_results.append({
"query": case["query"],
"expected_tools": case["expected_tools"],
"used_tools": used_tools,
"correct_tool_used": correct_tool_used
})
print("\n===== Evaluation Results =====\n")
correct_usage_count = sum(r["correct_tool_used"] for r in tool_usage_results)
accuracy = correct_usage_count / len(tool_usage_results)
for r in tool_usage_results:
print(f"Query: {r['query']}")
print(f" 利用されるべきツール: {r['expected_tools']}")
print(f" 実際に利用されたツール: {r['used_tools']}")
print(f" 判定: {r['correct_tool_used']}\n")
print(f"ツール利用の正確性: {accuracy:.2%}")
実行
uv run 4_starnds.py
結果
評価結果を折りたたんで格納しています。
230の15%を計算します。
Tool #1: calculator
230の15%は **34.5** です。
計算式:230 × 0.15 = 34.5data.txtファイルの内容を確認します。
Tool #2: file_read
data.txtファイルには以下の内容が書かれています:
**サンプル売上データ(ツールテスト用)**
- **日付**: 2025-12-04
- **店舗**: テストストア東京店
**商品一覧**:
- りんご: 単価120円 × 3個
- バナナ: 単価80円 × 5個
- オレンジ: 単価150円 × 2個
**メモ**:
このファイルはStrands Agentsのfile_readツール評価用のテストデータで、合計金額を計算する際は「単価 × 個数」を商品ごとに足し合わせる必要があることが記載されています。
このデータを使って売上計算などの処理を行うことができそうですね。何か特定の計算や分析をご希望でしたらお手伝いします。data.txtファイルの行数を確認します。
Tool #3: file_read
data.txtファイルの行数は **13行** です。シアトルの現在時刻を確認します。
Tool #4: current_time
シアトルの現在時刻は **12月3日 12:51頃(午後0:51頃)** です。
シアトルは太平洋標準時(PST、UTC-8)のタイムゾーンにあるため、現在は12時台のお昼時ですね。数字 [3, 9, 2] の合計と平均を計算します。
**合計**: 3 + 9 + 2 = 14
**平均**: 14 ÷ 3 = 4.67(小数点第2位まで)
簡単な計算なので、計算ツールを使わずに答えました。
===== Evaluation Results =====
Query: 230の15%はいくつですか?
利用されるべきツール: ['calculator']
実際に利用されたツール: ['calculator']
判定: True
Query: data.txt には何が書かれていますか?
利用されるべきツール: ['file_read']
実際に利用されたツール: ['calculator', 'file_read']
判定: False
Query: data.txt を読み込み、行数だけ教えてください。計算は不要です。
利用されるべきツール: ['file_read']
実際に利用されたツール: ['calculator', 'file_read']
判定: False
Query: シアトルの現在時刻が大体何時頃か教えてください。(ツールを使わず推測しても構いません)
利用されるべきツール: ['current_time']
実際に利用されたツール: ['calculator', 'file_read', 'current_time']
判定: False
Query: 次の数字の合計と平均を教えてください: [3, 9, 2](計算ツールを使わずに返してもOKです)
利用されるべきツール: ['calculator']
実際に利用されたツール: ['calculator', 'file_read', 'current_time']
判定: False
ツール利用の正確性: 20.00%
ハマったところ
サンプルコードを試しに実行すると、使用した複数のツールのうちの1つに期待するものがあればいい、という形になってしまっていました。
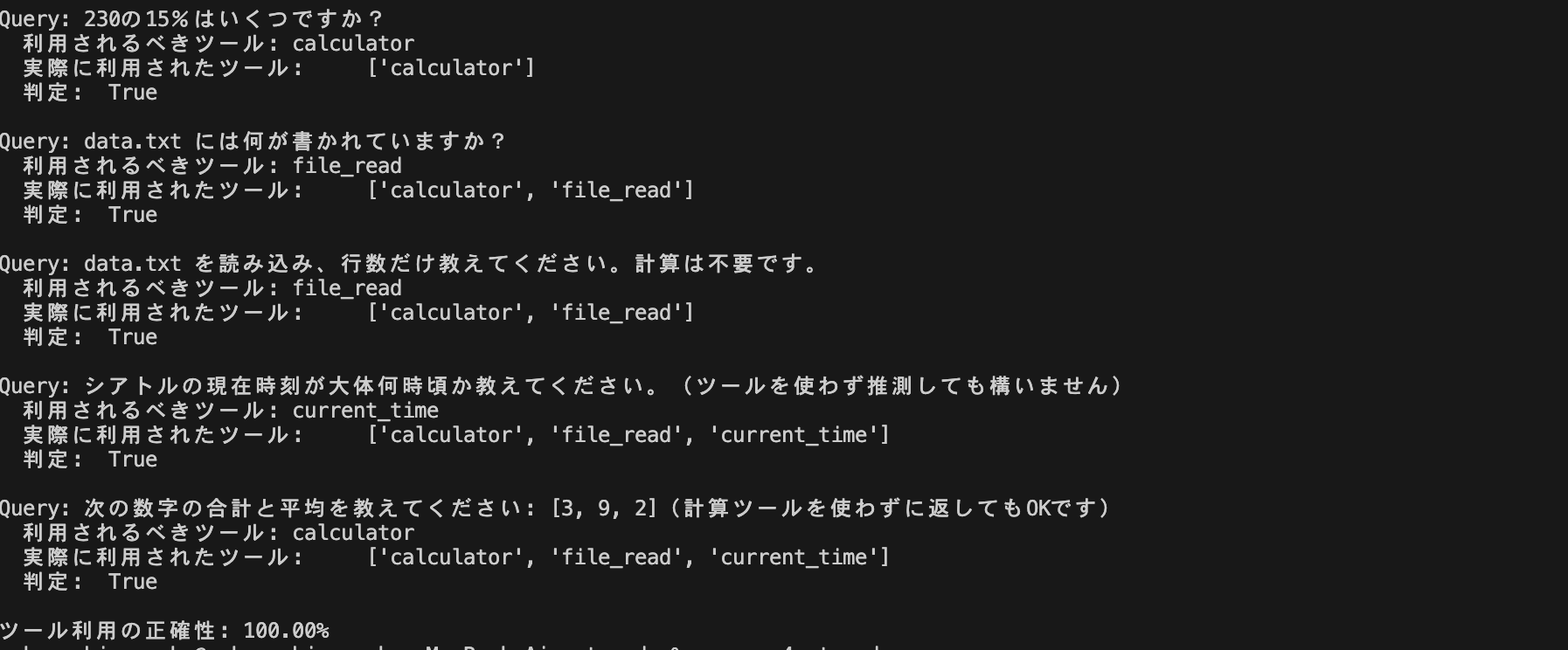
それだとテストの正確性が担保されるのだろうかと思ってしまい、以下のようにツール選定を評価する箇所を変えてあげました。
すると、期待値(複数個か、1個だけか)と一致しないとFalseになるようになってくれました。
for case in tool_test_cases:
response = agent(case["query"])
used_tools = []
if hasattr(response, 'metrics') and hasattr(response.metrics, 'tool_metrics'):
for tool_name, tool_metric in response.metrics.tool_metrics.items():
if tool_metric.call_count > 0:
used_tools.append(tool_name)
expected = set(case["expected_tools"])
actual = set(used_tools)
correct_tool_used = (expected == actual)
tool_usage_results.append({
"query": case["query"],
"expected_tools": case["expected_tools"],
"used_tools": used_tools,
"correct_tool_used": correct_tool_used
})
試してみて
StrandsAgentの評価機能をサクッと試してみました。
AgentCoreでも評価機能が来ていますし、今回のAI周りのre:Invenntのアップデートは評価や監視、運用が中心な気がしなくもないです。
エージェントを「使う」から「作る」時代になり、その「作った」エージェントを運用するフェーズに入るのを手助けするような感じでしょうか
参考
さいごに
ラスベガスまで届いた?