はじめに
こんにちは。株式会社ジールの@yakisobapanです。
S3 Tables
Athena Icebergテーブル
どちらもApache Iceberg形式をサポートしていますが、何が違うのかわかっていなかったので、Snowflakeへの連携まで構築してみました。
本記事は、S3 Tablesとの連携編です。
Athenaとの連携編はこちら↓
目次
- アーキテクチャ
- 構築手順
- 動作確認
- Tips
- 所感
アーキテクチャ
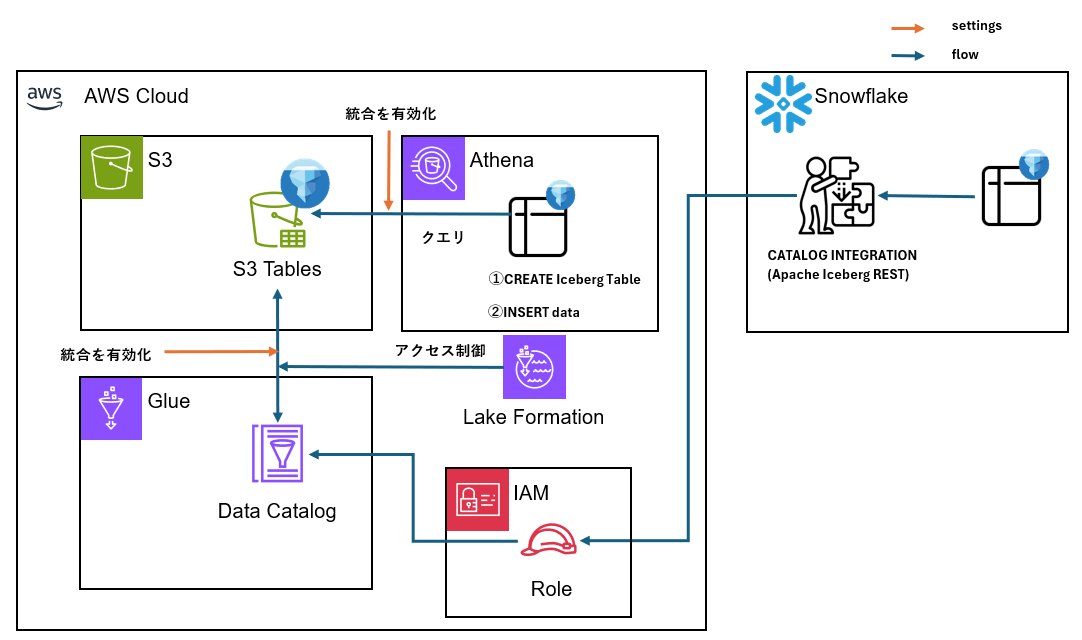
構築手順
S3 Tables
①統合を有効化
AWS分析サービスと連携させるために有効化させます。
有効化することで、例えば以下のような事が行えます。
・AthenaからSQLでテーブル作成やデータ投入、SELECTができる
・Glue DatacatalogにS3 Tablesのテーブルバケット、名前空間、テーブルが登録される
・Lake Fomationを介してテーブルバケット、テーブルのアクセス制御が行える
リージョンごとに1回実行する必要があります。
初回利用時は、公式ドキュメントに沿って、有効化します。

後述でTipsあり)有効化ステータスが[不明]となっている場合
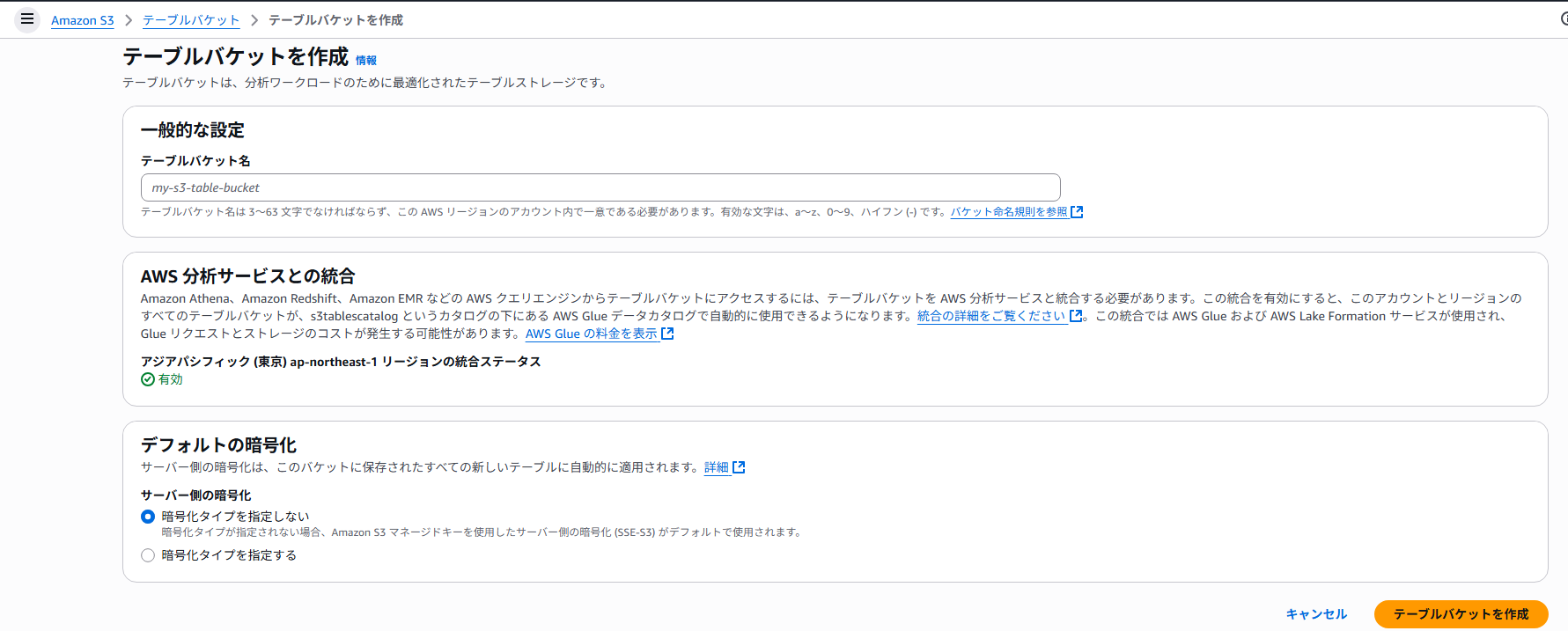
②テーブルバケットを作成
テーブルバケットを作成します。
テーブルバケットはGlueDatacatalogですとカタログに該当します。

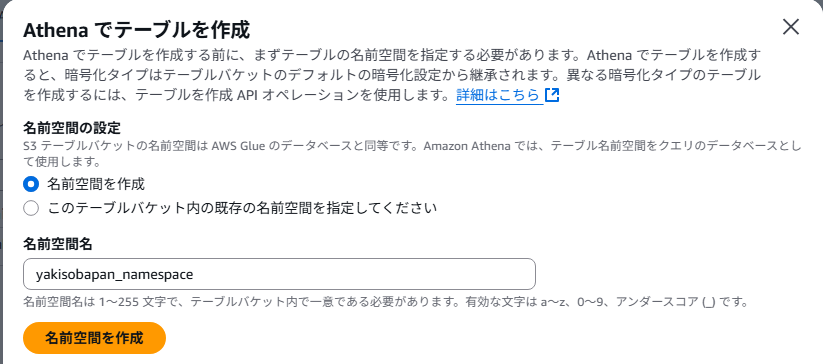
③名前空間の作成
[Athenaでテーブルを作成]より、名前空間を作成します。
名前空間はGlueDatacatalogですとデータベースに該当します。

④テーブルの作成
[Athenaでテーブルを作成]より、テーブルを作成します。
テーブルはGlueDatacatalogですとテーブルに該当します。
画面遷移後のテーブル作成は、Athenaパートにて説明します。

Lake Formation
①S3 Tablesカタログの利用権限付与
カタログを使用できるように権限を付与する

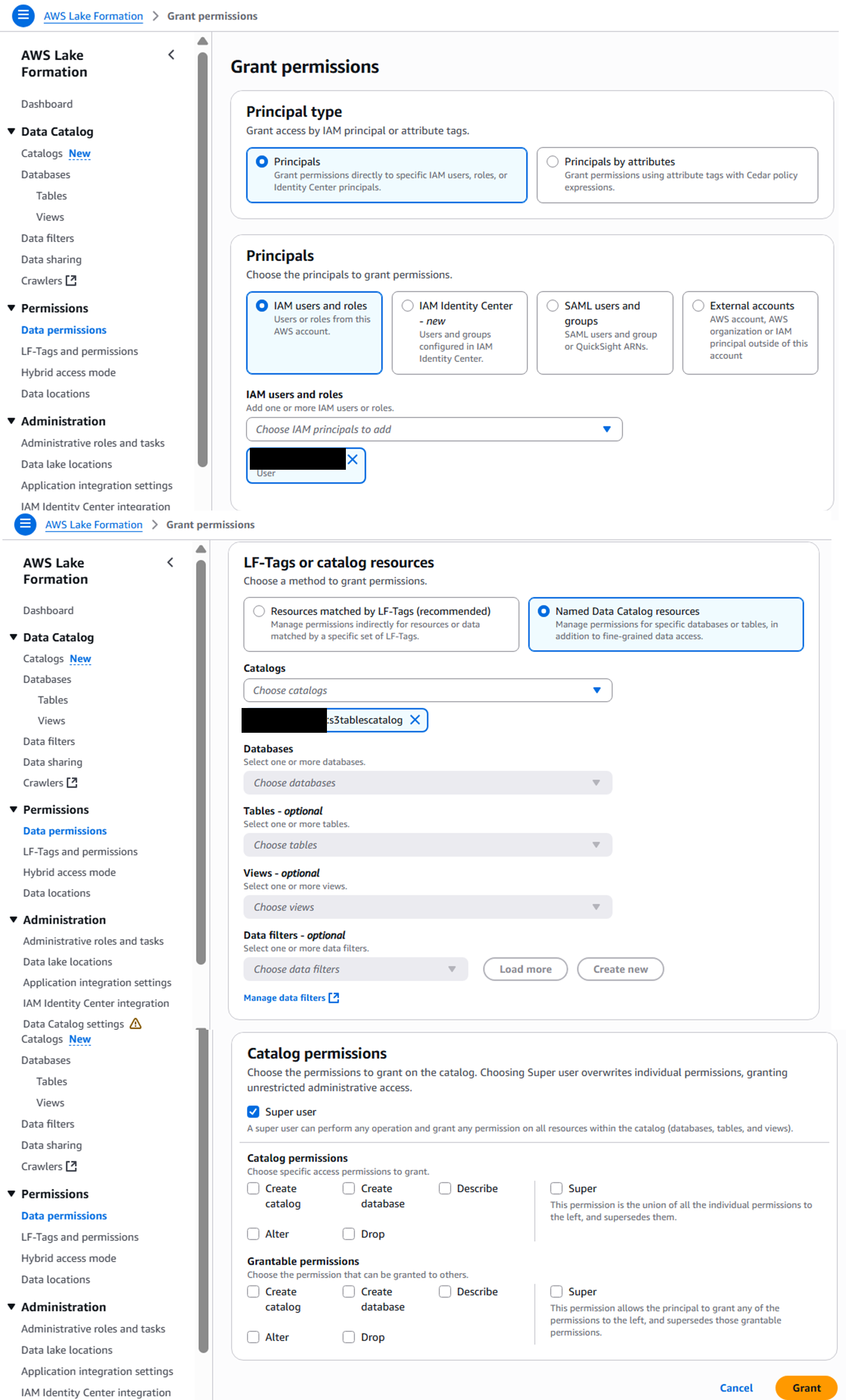
IAMのパートで説明しますが、Snowflakeが利用するIAMロールへのGRANTも別途行います。
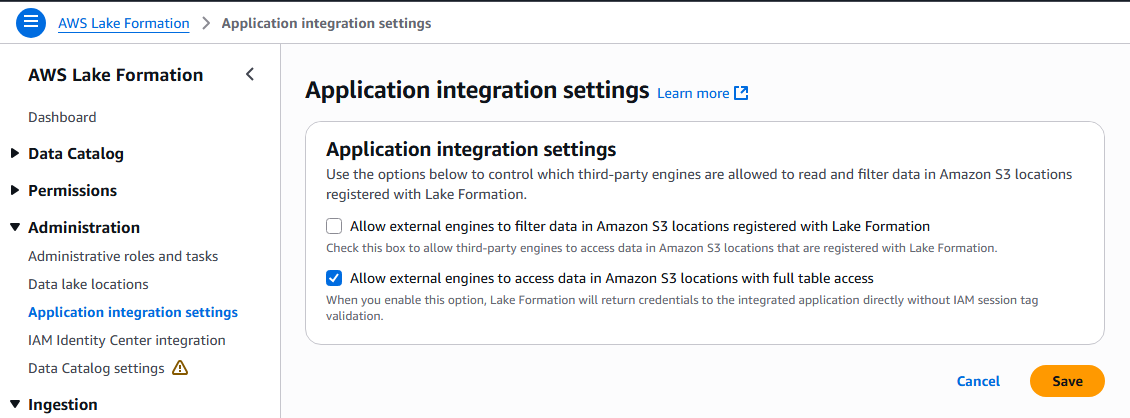
②
[Allow external engines to access data in Amazon S3 locations with full table access]にチェックを入れて保存します。
Snowflakeがs3tablescatalogを参照できるようにすることで、後述するSnowflake CATALOG INTEGRATIONでカタログ統合が実現できます。
Athena
①テーブルの作成
Iceberg形式でテーブルを作成します。

CREATE TABLE "yakisobapan_namespace"."s3tables_iceberg_table" (
id string,
seqnum string,
name string,
birth string,
code string,
date string,
timestamp string,
mail string)
TBLPROPERTIES (
'table_type'='iceberg', --テーブル形式
'write_compression'='zstd' --データ圧縮方式
);
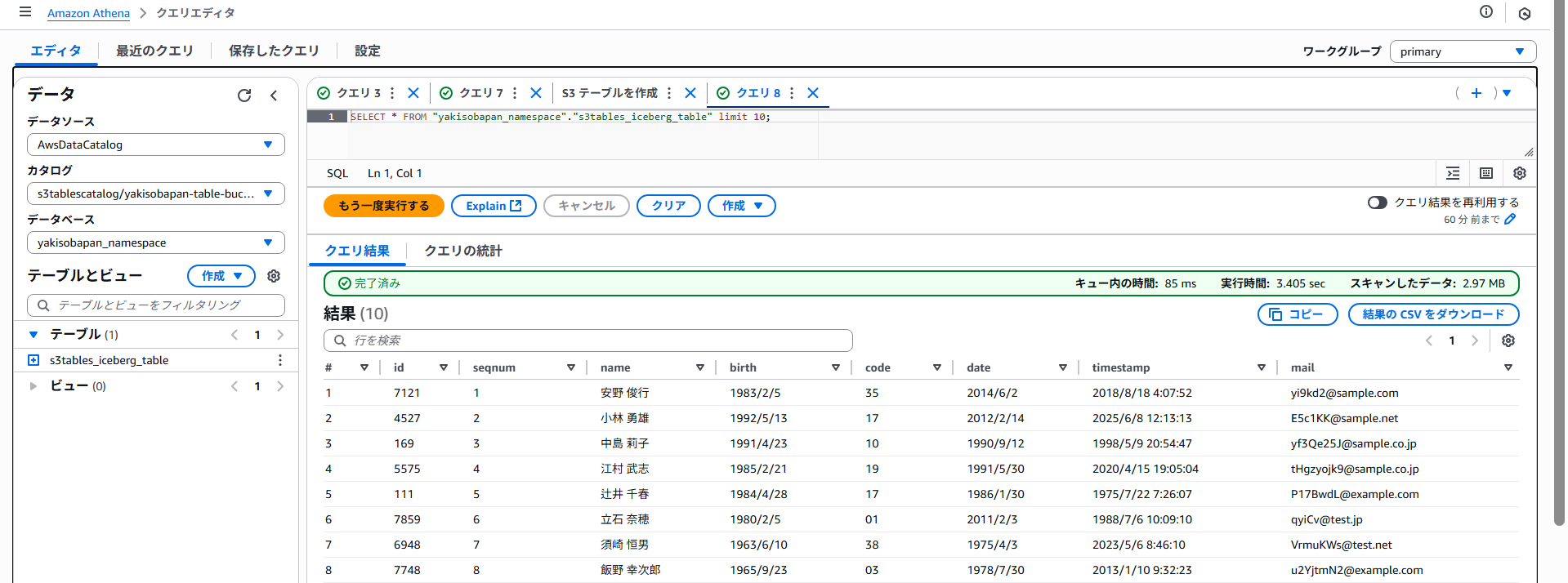
②テーブルへデータの投入
今回は10万行のcsvをS3標準バケットへ配置し、それをAthena上の別データベース内テーブルstaging_tableとして用意し、それをINとしてデータ挿入しました。
INSERT INTO
"s3tablescatalog/yakisobapan-table-bucket"."yakisobapan_namespace"."s3tables_iceberg_table"
SELECT * FROM
"AwsDataCatalog"."yakisobapan-db"."staging_table";
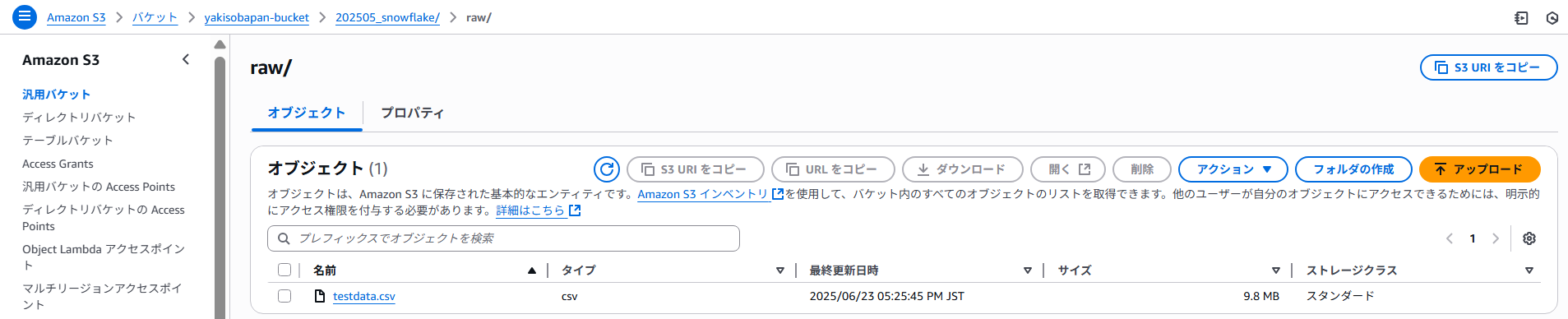
(参考)投入データの配置
・S3
・Athena
※表示データはランダム生成した10万件のデータです。

IAM
①IAMロールを作成
Snowflakeが引き受けてGlue s3tablescatalogを参照するためのロールを作成します。
[信頼されたエンティティ]については、後ほどSnowflakeの設定値を設定するため、このタイミングでは適当でOKです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::[カタログがあるアカウントID]/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::[カタログがあるアカウントID]",
"Condition": {
"StringLike": {
"s3:prefix": [
"*"
]
}
}
},
{
"Effect": "Allow",
"Action": "lakeformation:GetDataAccess",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:*:[カタログがあるアカウントID]:catalog/*",
"arn:aws:glue:*:[カタログがあるアカウントID]:database/*",
"arn:aws:glue:*:[カタログがあるアカウントID]:table/*"
]
}
]
}
②カタログへのアクセス許可を付与
Lake FormationでこのIAMロールがカタログへアクセスする許可を与えます。
アーキテクチャの通り、このIAMロールを介してSnowflakeがカタログを参照するため、必要な許可を付与してあげます。

Snowflake
①CATALOG INTEGRATIONを作成
CATALOG INTEGRATIONは複数用意されていますが、CREATE CATALOG INTEGRATION (Apache Iceberg REST)を作成します。
CREATE OR REPLACE CATALOG INTEGRATION s3tables_catalog_integration
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'default'
REST_CONFIG = (
CATALOG_URI = 'https://glue.ap-northeast-1.amazonaws.com/iceberg'
CATALOG_API_TYPE = AWS_GLUE
WAREHOUSE = '[カタログがあるアカウントID]:s3tablescatalog/yakisobapan-table-bucket'
ACCESS_DELEGATION_MODE = vended_credentials
)
REST_AUTHENTICATION = (
TYPE = SIGV4
SIGV4_IAM_ROLE = 'arn:aws:iam::[カタログがあるアカウントID]:role/[IAMパートで作成したIAMロール名]'
SIGV4_SIGNING_REGION = 'ap-northeast-1'
)
ENABLED = TRUE
;
Athena編で利用するCREATE CATALOG INTEGRATION (AWS Glue) との違いは、APIの種類のようです。
S3 TablesのIcebergカタログはAWSのREST APIで提供されており、Glue APIを使う以下ではアクセスできないためらしいです。
↓Athena(Glue Data Catalog)用の統合
②作成した統合がIAMロールを引き受けられるようにする
作成した統合を確認し、以下情報を取得します。
API_AWS_IAM_USER_ARN:SnowflakeがホストされているAWSアカウントのIAMユーザーarn
API_AWS_EXTERNAL_ID:AWS外部ID
DESC CATALOG INTEGRATION s3tables_catalog_integration;
(AWSで作業)取得した2項目を、IAMロールの[信頼されたエンティティ]へ設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::[SnowflakeのAWSアカウントID]:[SnowflakeのIAMユーザー]"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId":"AWS外部ID"
}
}
}
]
}
カタログ統合を作り直した場合、[AWS外部ID]は変更されるので、信頼ポリシーも併せて変更が必要です。
③Icebergテーブルの作成
カタログ統合を使って、Snowflakeにテーブルを作成します。
CREATE OR REPLACE ICEBERG TABLE YAKISOBAPAN_DB.public.s3tables_table
CATALOG = 's3tables_catalog_integration' --カタログ統合
CATALOG_NAMESPACE = 'yakisobapan_namespace' --名前空間
CATALOG_TABLE_NAME = 's3tables_iceberg_table' --テーブル名
AUTO_REFRESH = FALSE
;
動作確認
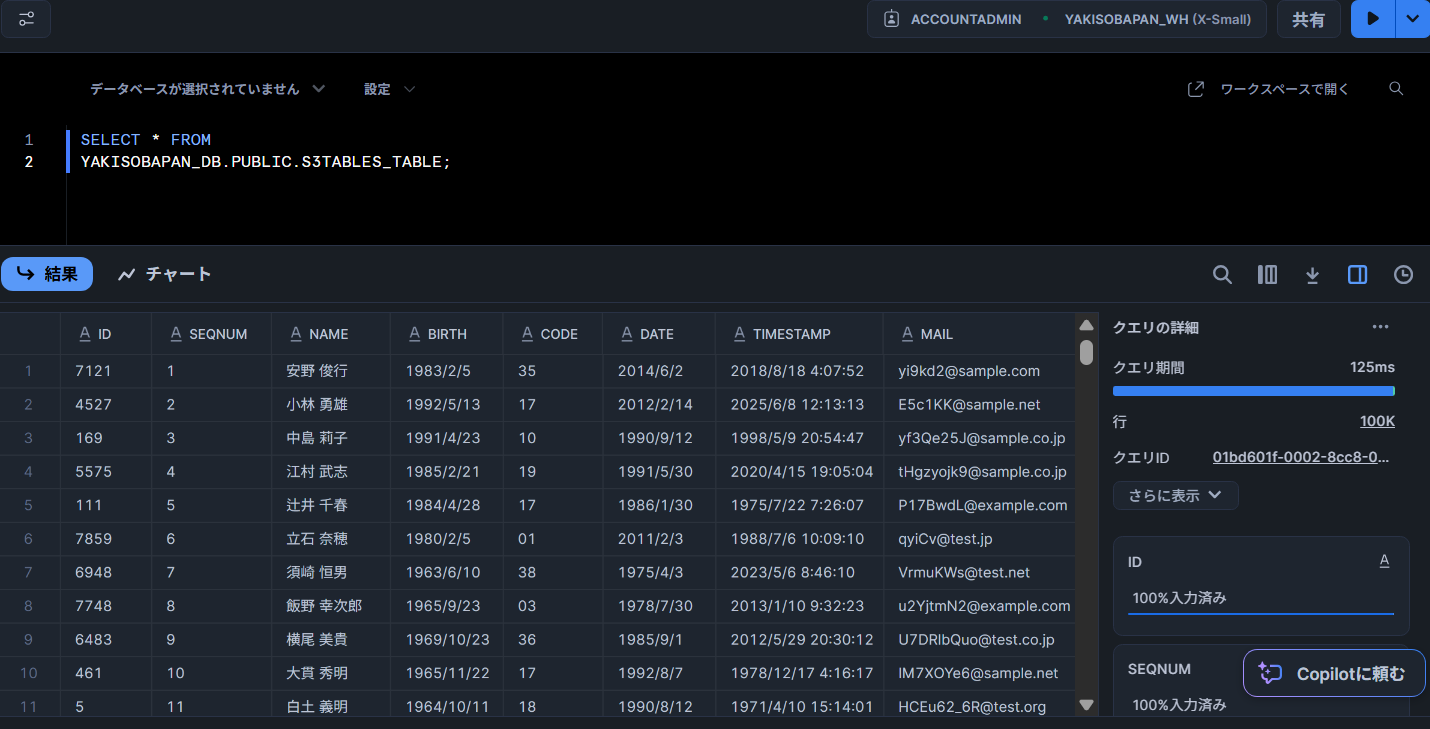
S3 Tablesに存在するデータが参照できています。
※表示データはランダム生成した10万件のデータです。
Tips
S3 Tables利用時、[統合を有効化]する際に、有効化ステータスが[不明]となっている場合
・確認すること
①自身に以下ポリシーが許可されているか確認
glue:GetCatalog
lakeformation:DescribeResource

②自身がデータレイク管理者になっているか確認
以下ポリシーが自身にアタッチされた状態だと、自分自身でデータレイク管理者になることができないため、そのポリシーはデタッチする必要があります。
・AWSLakeFormationDataAdmin
・AmazonAthenaFullAccess
所感
Snowflakeは一度公式チュートリアルを触っただけですので、試行錯誤しながらでしたがかなり体系的に理解できた気がします。
また一連の構築をしてみたことで、実務でも使えそうと純粋に思いました。
今までですと、お手軽分析基盤の構成(S3 × Glue × Athena)にはACIDトランザクションが担保できなかったため、信頼性に欠ける部分がありました。
そこにIcebergの要素が加わることで、データの整合性が担保され、より要件にリーチできるような構成(特に非機能部分)が実装できるのではないかと思いました。
参考
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: