はじめに
こんにちは。株式会社ジールの@yakisobapanです。
AWS re:Invent 2024で発表されたS3メタデータの活用方法を考えてみました。
目次
- アップデート内容
- アーキテクチャ
- やってみた
- 所感(ユースケース考察)
アップデート内容
Amazon S3にオブジェクトが格納、変更、削除された際に生成されるメタデータを取得できるようになりました。
メタデータは、同タイミングで発表されたS3テーブルにて保持され、Athena等を利用してクエリすることが可能です。
Amazon S3 メタデータ (プレビュー) の発表 — メタデータを管理する最も簡単かつ迅速な方法
(2024/12/03 What's New with AWS?より)
Amazon S3 テーブルの発表 — 分析ワークロード向けに最適化されたフルマネージド型の Apache Iceberg テーブル
(2024/12/03 What's New with AWS?より)
東京リージョンでも利用可能になっていました!
Amazon S3 テーブルが新たに 5 つの AWS リージョンで利用可能になりました
(2025/1/17 What's New with AWS?より)
アーキテクチャ
以下のような構成で考えてみました。
一般的なAWS上でのETL構成*に今回のアップデートを活用できそうです。
*S3をデータストアとして、データソース(csv等)をGlueジョブでParquetへ変換し格納、Athenaでクエリするといった構成
赤矢印が新機能のS3メタデータに関するデータフロー、参照フローです。

やってみた
事前準備
上記構成を作成します。
- S3
・「テーブルバケット」形式でバケットを作成します。
⇒末尾「参考」のドキュメントをご参照ください
・バケット配下にinフォルダ、outフォルダを作成します。
・データソースとなるcsvファイルをinフォルダに配置します。 - Glue
・各用途のData Catalogを作成します。
・ジョブを作成し、csvをParquetへ変換するPythonスクリプトを記述します。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# setup
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# data read
input_path = "s3://yakisobapan-bucket-s3-metadata/in/bread/"
output_path = "s3://yakisobapan-bucket-s3-metadata/out/bread/"
datasource0 = glueContext.create_dynamic_frame.from_options(
format_options={"withHeader": True, "separator": ","},
connection_type="s3",
format="csv",
connection_options={"paths": [input_path]},
transformation_ctx="datasource0"
)
# transform Parquet(Snappy)
datasink1 = glueContext.write_dynamic_frame.from_options(
frame=datasource0,
connection_type="s3",
connection_options={"path": output_path},
format="parquet",
format_options={"compression": "SNAPPY"}
)
job.commit()
- Athena
・Data Catalogに対応したスキーマへテーブルを作成します。
Glueジョブ実行時の挙動
inフォルダにあるcsvファイルをparquetへ変換してoutフォルダに出力するというスクリプトを実行します。
- ジョブ実行前のoutフォルダ
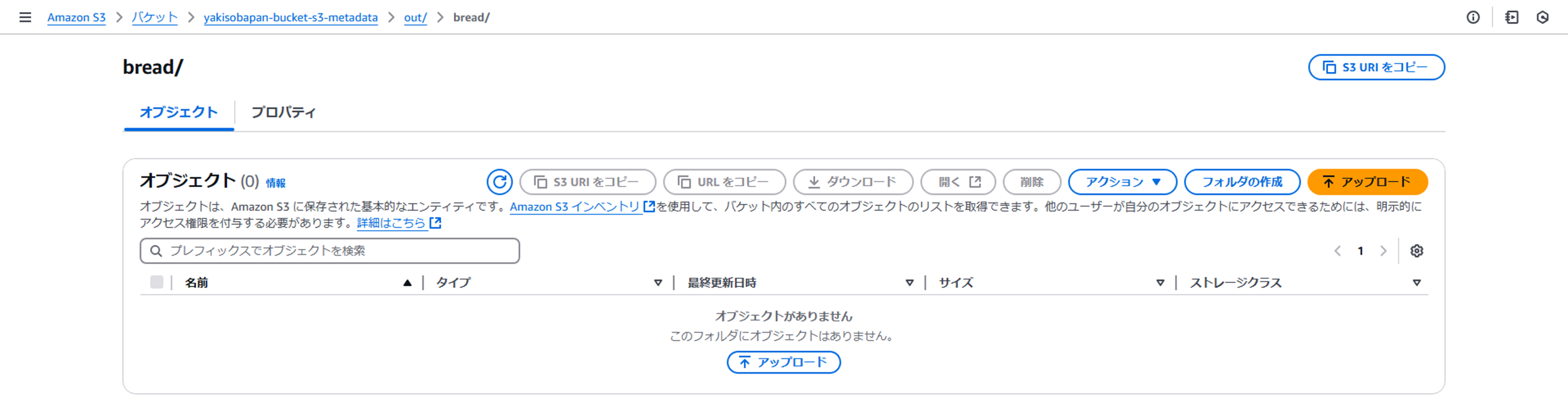
- ジョブ実行後のoutフォルダ
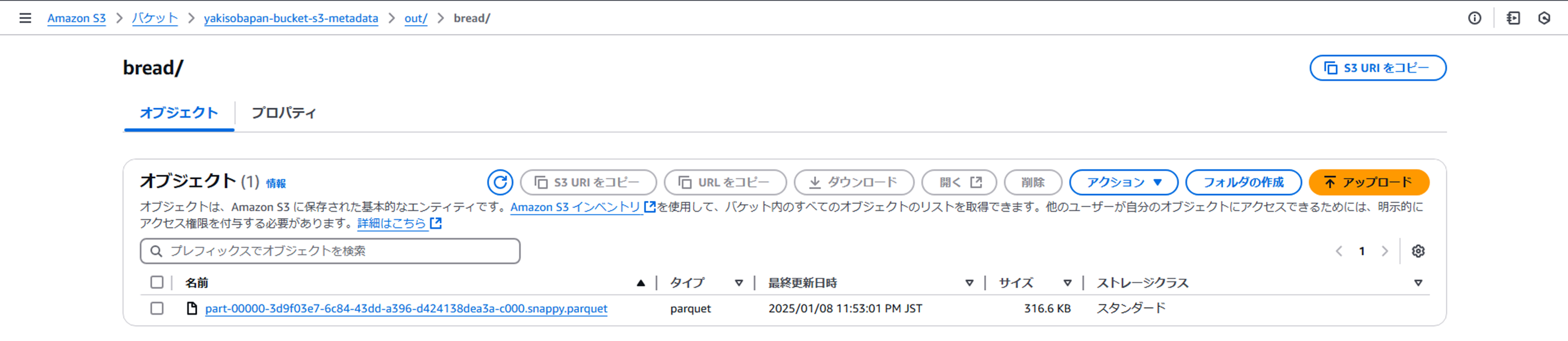
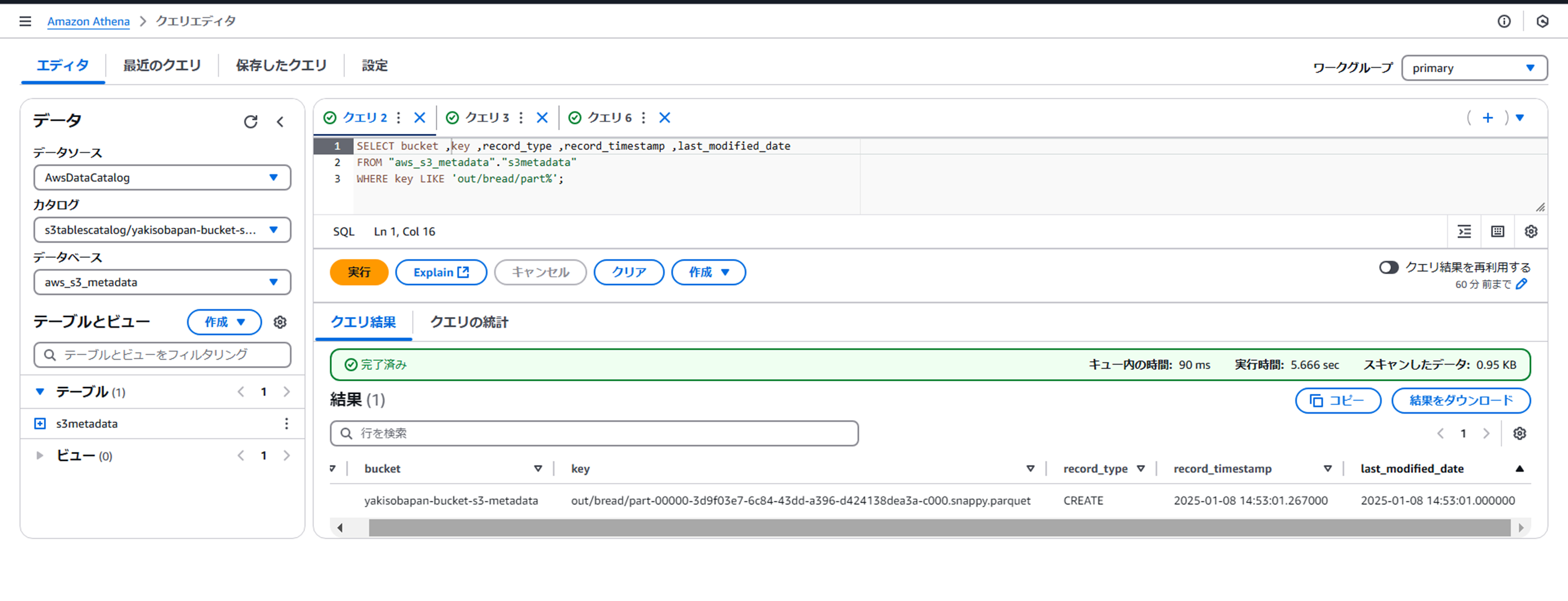
- Athenaでメタデータテーブルを確認してみる
作成されたオブジェクトに関するメタデータが1レコード追加されています。
Glueジョブ実行時の挙動(2回目以降)
- ジョブ実行後のoutフォルダ
追加で1ファイル作成されました。

- Athenaでメタデータテーブルを確認してみる
連動してレコードが作成されていますね。

オブジェクトに変更を行った際の挙動
- 変更前
- 作成されたparquetファイルの名称を変更してみる
ファイル名末尾を000→999へ変更します。
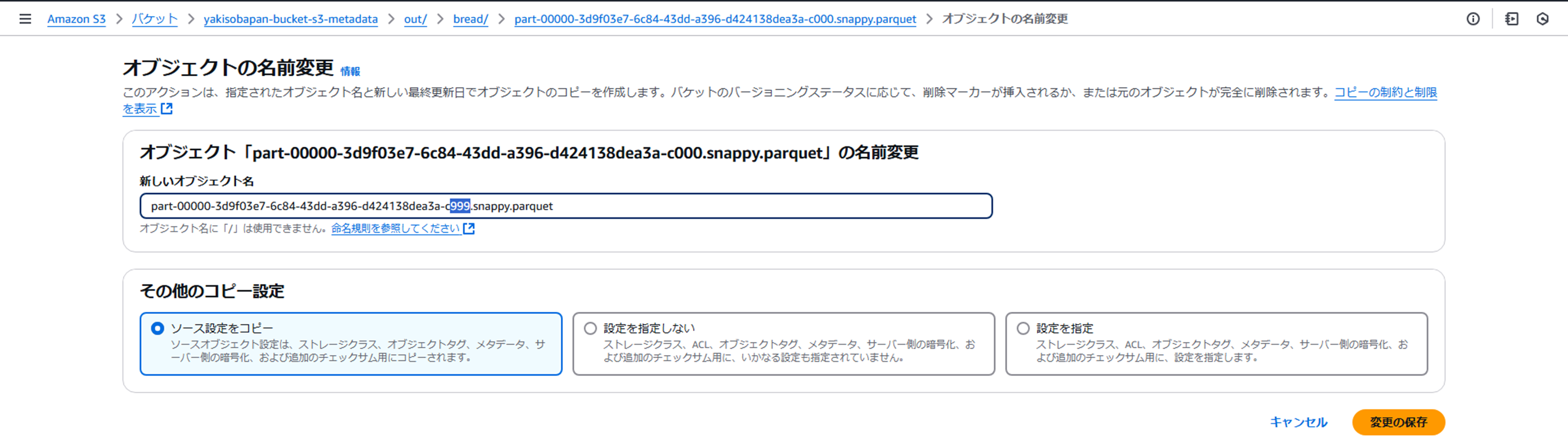
- 変更後

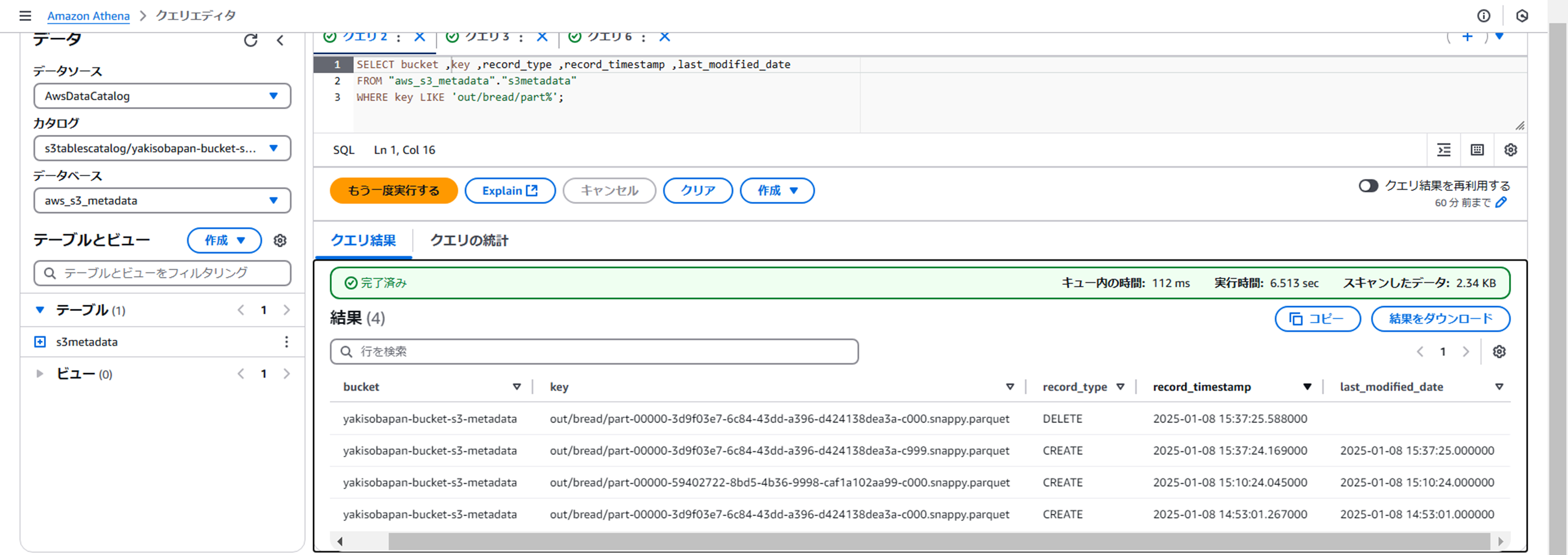
- Athenaでメタデータテーブルを確認してみる
変更が反映されていますね。
変更後名称でオブジェクトが作成、変更前名称のオブジェクトは削除という動きになるようです。
所感(ユースケース考察)
ひとことで
S3メタデータを利用すると、Glueから出力されたparquertファイルの管理(出力日時や更新日時)精度が向上する
今回のアップデート内容は、S3×Glue×AthenaのETL構成を行う際のS3オブジェクトの管理で活用できそうと考えました。
S3へのparquetファイル出力は、
Glue内でApache Sparkを利用した分散処理の結果、最適化されたファイルが出力されるため、ファイル名はpart-から始まるランダム文字列となります。
・S3メタデータを使っていない場合
例えば、ファイル名にタイムスタンプを付加して、出力日がわかるようにしたい場合、
追加で編集処理をスクリプトに加えるなどする必要がありました。
ランダム文字列のファイルで運用していた場合、例えば、S3コンソールからのオブジェクト編集や移動によって、最終更新日時が変更されてしまいます。
やってみた内の[オブジェクトに変更を行った際の挙動]のように
意図しないオブジェクト変更によって、最終更新日時が変更され「あれ、このファイルっていつ生成されたファイルだ?」となってしまっていました。
・S3メタデータを使った場合
S3に出力されたparquetファイルがいつ作成されたか、テーブル形式で保持できるようになりました。
これにより、仮にファイルが変更された場合でも情報を追うことができ、対象ファイルの作成日時を特定することができます。
参照可能なメタデータが拡充されていけば、information schemaのように利用することもできそうな気がしました。
Athenaがクエリエディターにとどまらず、DBの代替となる日も近い、、?
参考
・S3メタデータテーブルの構成、設定手順
・オブジェクトメタデータの種類
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: