この記事は ミクシィグループ Advent Calendar 2019 、9日目の記事です
概要
(3行まとめ)
- 機械学習のトレーニングジョブの精度モニタリング、モデル比較をいい感じにやりたい
- Amazon SageMaker では CloudWatch メトリクスのチャートが提供されるが、見づらい・・
- SageMaker SDK または 独自コードでメトリクス収集して、メトリクスデータやグラフをモデルと同じ場所(S3)に置くとよかった
課題 
Amazon SageMaker では、トレーニングジョブのメトリクス監視用に CloudWatch メトリクスをベースとしたチャートが提供 され、マネジメントコンソールのジョブ詳細にも表示されるようになっています
設定がお手軽ですが個人的には、ログの滑らかさ(出力頻度)や縮尺、単位表記など、アルゴリズムメトリクス監視用としては厳しい印象です
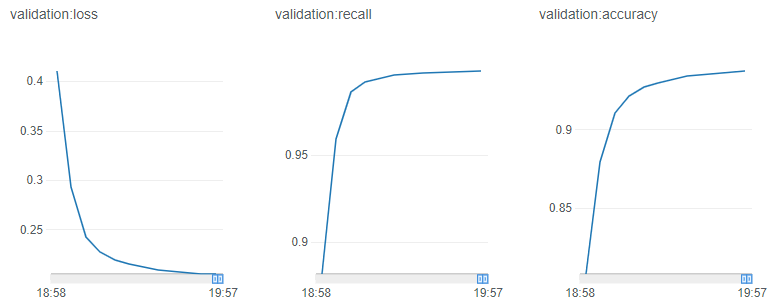
- 横軸は時間で固定されている
- epoch 単位などの描画はできない
- 時間軸のグラフはインスタンス性能などによって歪む
- 手動で時間範囲を操作してフォーカスすることもできるが不正確
- プロットが最短でも 1分 間隔 で、描画が粗い
- 縦軸がメトリクスの実測値周辺に固定され、縮尺が揃わない
- ジョブ間で視覚的に比較しづらい
- 操作感が厳しい・・
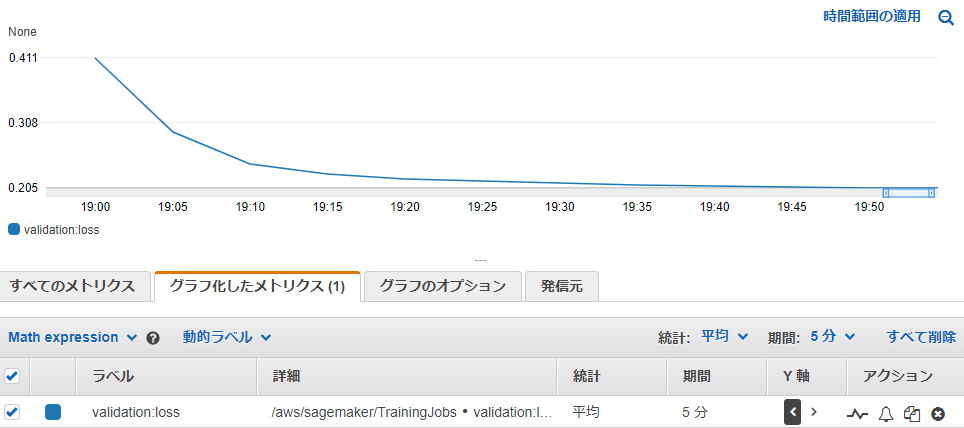
対処1:SageMaker SDK API (Python) を使う 
SageMaker SDK の TrainingJobAnalytics を使ってデータを取得し、描画を自身で制御します
データソースは変わらず CloudWatchLogs (根本解決してない)ですが、 可読性はぐっと改善できます
トレーニング中に Jupyter Notebook で描画させてもよいですし、Estimator 呼び出し元のコードで、定期あるいは終了時に描画して、所定の場所へ保存させるでもよいと思います
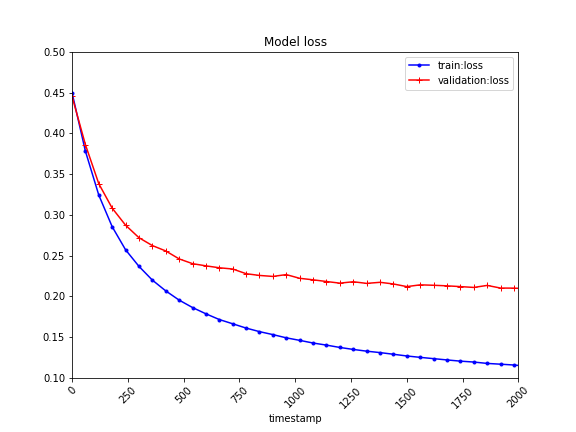
metric_names = ['train:loss','validation:loss']
metrics_dataframe = sagemaker.analytics.TrainingJobAnalytics(
training_job_name=training_job_name,
metric_names=metric_names,
period=60, # 1 min が限界値
).dataframe()
# dataframe をもろもろ整形
...
plt = metrics_dataframe_fixed.plot(
kind='line',
figsize=(20,15),
fontsize=18,
x='timestamp',
y=[metric_names[0],metric_names[1]],
xlim=[0, 2000],
ylim=[0.1, 0.5],
style=['b.-','r+-'],
rot=45,
)
plt.figure.savefig('metrics_training_job_xxx.png')
plt.clf()
できること
- メトリクスデータを DataFrame に変換して、描画をお好みに調整できる
- 縦横の縮尺、サイズを指定できる
- 描画開始位置を揃えられる
- コード上で管理できるので、いろいろいじれる
- トレーニング中に定点的にとり、定期的に通知したりできる
- 描画したグラフをモデル置場(S3)に一緒に上げておけば、モデル評価の助けになる
SageMaker の組み込みアルゴリズム でもこの方法が使える
できないこと
- データそのものは変わらない(CloudWatchベースのまま)
- 横軸は時間以外にできない
- プロット間隔もそのまま(最大1分間隔)
対処2:独自エントリポイント、または独自アルゴリズム内でグラフ描画する 
SageMaker には使い方が 公式には4通り ありますが、Amazon の提供するMLフレームワークコンテナや独自コンテナを使うケースであれば、自身のプログラムコードでトレーニング中の状況を定期的にグラフ描画・出力し、S3 へ送ったりできます
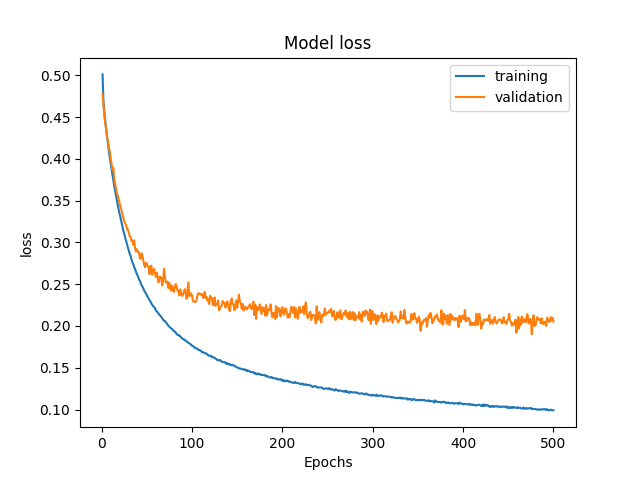
SageMaker を使ってるのに提供されるモニタリング機能を使わないのは忍びないですが、ほしい形式で得られない場合はコンテナ内でとるしかありません(エントリポイントのスクリプトや独自MLアルゴリズムは自身で記述するため、把握しているコードにグラフ描画を加える手間はそう大きくありません)
できること
- メトリクスデータから自由に定義できる
- epoch 単位などで出力できる
- 描画もお好みでできる
- 縦横の縮尺、サイズを指定できる
- 描画開始位置を揃えられる
- コード上で管理できるので、いろいろいじれる
- トレーニング中に定点的にとり、定期的に通知したりできる
- 描画したグラフをモデル置場(S3)に一緒に上げておけば、モデル評価の助けになる
できないこと
- コードに触れない
組み込みアルゴリズム ではこの方法は使えない
処理の流れ
「コンテナ内で描画したグラフをどこに送るか、コンテナの内と外でグラフ配置先(S3 path)をどのように共有するか」が意外と難しいですが、例として次のような方法が使えます
- S3 上に、トレーニングジョブごとのMLモデル出力先を定義する
- 同じ場所に
conditions置き場も定義し、モデルに関する情報を記載した JSON ファイルを置く - 同じ場所に
metrics置き場を定義し、メトリクスデータや描画したグラフを置く場所とする
- 同じ場所に
-
conditionsパスをinputsとしてEstimator に引き渡し、トレーニングを開始する - SageMaker コンテナ内でトレーニングアルゴリズムを実行する
- トレーニングジョブ内で
conditionsにあるJSONを参照して、モデル出力先パスを組み立てる - トレーニングを実行し、途中経過のログを出力してグラフ描画する
- S3グラフ配置先
metricsに、描画したグラフデータを(定点的に)アップロードする
- トレーニングジョブ内で
- S3 にアップロードされたグラフをお好みで処理
3. 常時監視する、通知だすなど
コード例
# conditions 生成、training_job_name を記録
dict_conditions = { "training_job_name" : training_job_name }
s3_conditions_path = '/model/{}/conditions/training_job_config.json'.format(training_job_name)
boto3.resource('s3').Object(bucket,s3_conditions_path).put(Body=json.dumps(dict_conditions))
# sagemaker の トレーニングジョブへ conditions を引き渡し
Estimator.fit(
job_name=training_job_name,
inputs={'train_data':s3_train_data_path,'conditions':s3_conditions_path},
)
# Estimator.fit 呼び出し元から引き渡してきた conditions からトレーニングジョブ名を取得
# (引き渡した inputs の dict key に対応するパスが生成され、ファイルが配置されている)
input_conditions = '/opt/ml/input/data/conditions/training_job_config.json'
with open(input_conditions) as f:
conditions = json.load(f)
training_job_name = input_conditions['training_job_name']
# グラフパス定義
graph_name = 'training_history_{}.png'.format(metrics)
graph_outpath = '{}/{}'.format(output_path,graph_name)
s3_graph_outpath = '/model/{}/metrics/{}'.format(training_job_name,graph_name)
# グラフを描画・保存(keras例)
history = model.fit(...)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.legend(['training', 'validation'], loc='upper right')
plt.figure.savefig(graph_outpath)
plt.clf()
# S3 トレーニングジョブ結果を保存するバケットへグラフを送信(更新)
boto3.resource('s3').Bucket(bucket).upload_file(graph_outpath,s3_graph_outpath)
コードにあるように、 sagemaker の Estimator を呼び出す部分で training_job_name を json で引き渡せるようにしておき、共有した情報からトレーニングジョブごとのメトリクス出力先を、所定の形式( s3://{bucket}/model/{training_job_name}/metrics/{graph_name}.png )で組み立てます
余談:TensorBoard で描画する
対処2ではコードを自由に書けるので、 TensorBoard 用にログを出力してS3の指定バケットと同期し、Notebook Instance などで立ち上げた TensorBoard から S3 上のログを参照して描画させる、といったこともできます
tensorboard_log_outpath = '{}/{}'.format(output_path,tensorboard_log_name)
tensorboard_callback = keras.callbacks.TensorBoard(
log_dir=tensorboard_log_outpath,
histogram_freq=1)
callbacks = [tensorboard_callback]
model.fit(..., callbacks=callbacks)
boto3.resource('s3').Bucket(bucket).upload_file(
tensorboard_log_outpath, s3_tensorboard_log_outpath)
tensorboard --logdir={s3_tensorboard_log_outpath}
その他お好みのツールで描画させることも可能ですが、管理コストをふまえてバランスのよい方法をとっておくと良いと思います
まとめ
途中で何度か触れていますが、SageMaker の利用方法 によってとれる選択肢が違ってきます
-
組み込みアルゴリズム または Marketplace
- 対処1 を使う
- TrainingJobAnalytics で描画してメトリクスデータを取得し可読性をあげられる
- データは CloudWatch 仕様の制約を受ける
- 対処1 を使う
-
独自エンドポイント または 独自アルゴリズム
- 対処1 または 対処2 を使う
- 自身のアルゴリズム内でメトリクスデータを収集したりグラフ描画したりできる
- S3 等を介して、他ツールと連携させることもできる
対処1,2 どちらに関しても、 メトリクスデータ(Dataframeやログ)や描画したグラフ画像を、モデル置場と同じS3へ上げておく と、管理しやすいと思います
比較対象のメトリクスは、同じ定義で、ぱっと見て判断できるように整理しておきたいですね