はじめに
「DBデータをCSVにしてS3に置いてほしい。毎日ね。」と言われ「今時、EC2でやるのはちょっと。」と思いAWS Batchでやってみたので書きます。
前提条件
今回は空のCSVファイルをS3バケットに置くだけの簡単なお仕事を行なうPythonスクリプトを例に実施します。
AWS Batchとは
バッチコンピューティングジョブを実行するためのマネージドサービスです。
料金はEC2・AWS Lambda等の使った分だけ!
こんな時に向いてる
- 定期的に実行したい
-
AWS Lambdaだとに心細い(参考) - サーバの面倒を見たくない
- 安くいきたい(使った分だけ課金)
用語説明
- ジョブ定義
- どのイメージを使用するか、CPU・メモリはどれくらい使用するか、環境変数などを定義する。
- コンピューティング環境
- ジョブを実行するための環境。特定のインスタンスタイプや特定のモデル (c4.2xlarge や m4.10xlarge など) を使うように設定できたりする。
- ジョブキュー
- ジョブがコンピューティング環境にスケジュールされるまでの待ち行列を保持するもの。
- ジョブ
- ジョブ定義で指定したパラメーターを使用して、コンピューティング環境でコンテナ化されたアプリケーションとして Amazon EC2 インスタンスで実行されるもの。
ソースコード書く
書いた。今回使用するものはこちら。
ECR(EC2 Container Registory)にイメージをプッシュ
今回はECRを使ってみる。
- マネジメントコンソールでECSを開く
- リポジトリ名決める
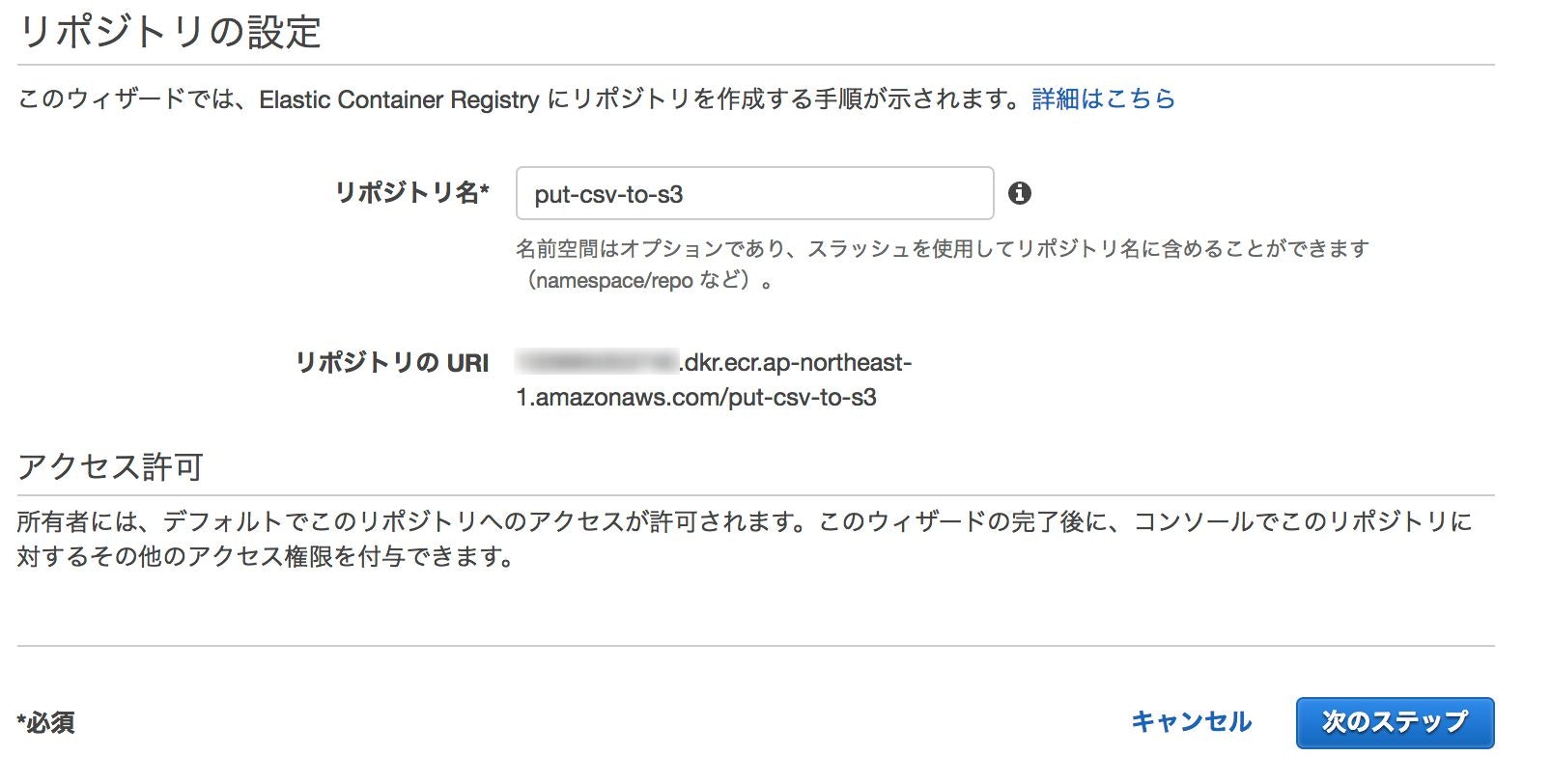
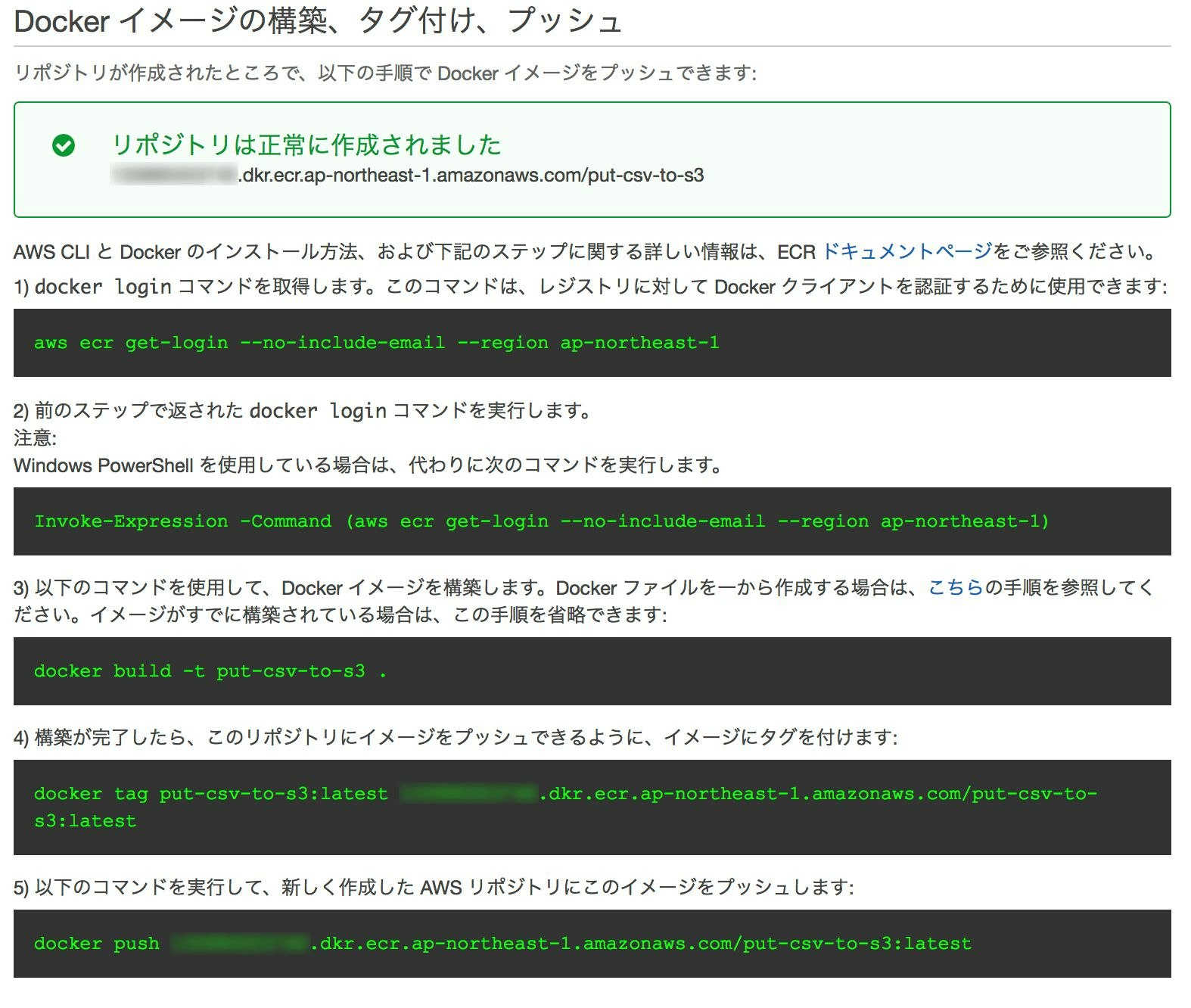
- リポジトリにイメージをPushする
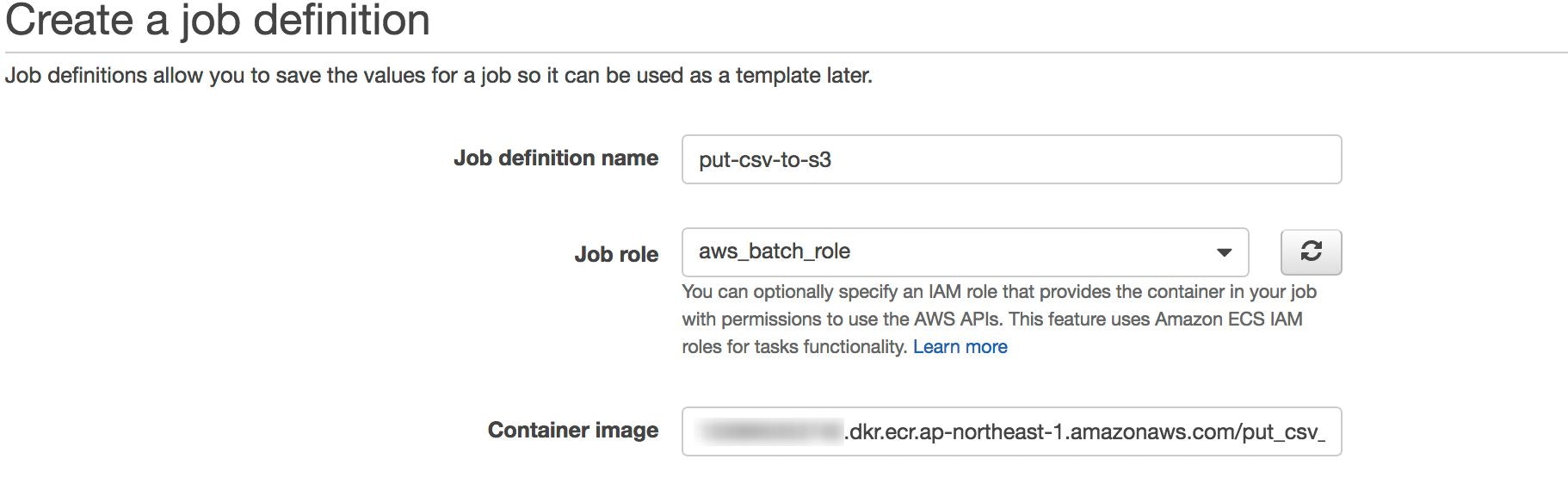
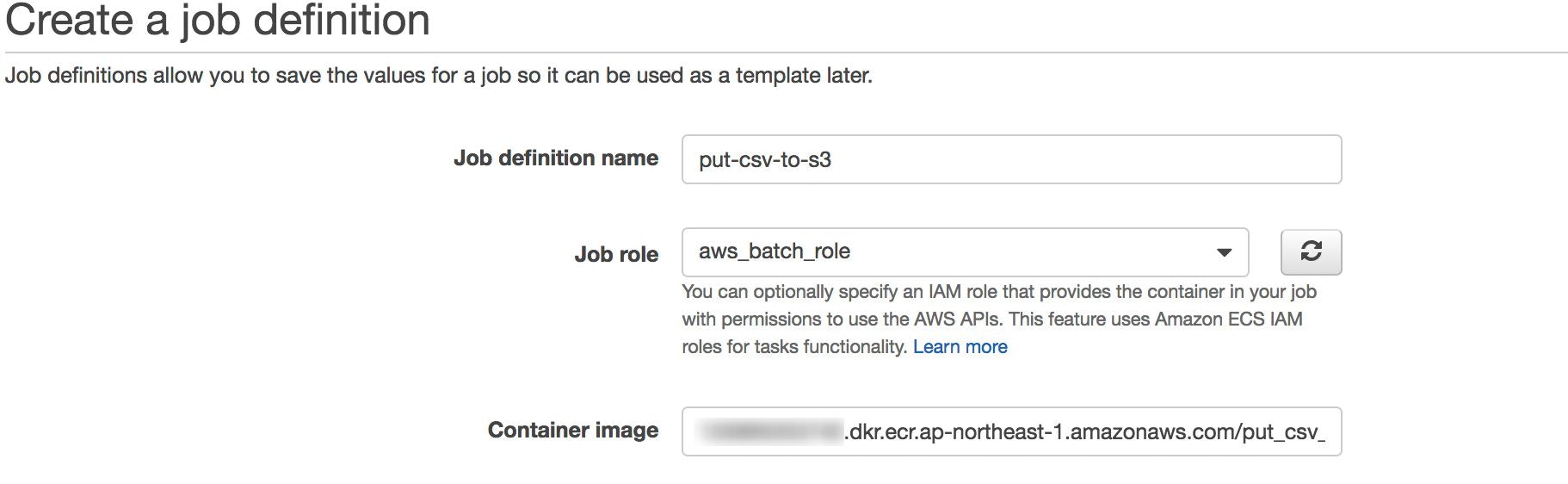
Job Definitionの作成
-
Job definition nameは任意の名前を入れます。 -
Job Roleはaws_batch_roleを選択します。- aws_batch_roleは下記ポリシーを保持
AmazonEC2ContainerRegistryFullAccessAmazonEC2ContainerServiceFullAccess
- aws_batch_roleは下記ポリシーを保持
-
Container Imageは先程作成したリポジトリのURIを指定します。
- Environment
-
CommandはDockerfileでCMDを指定しているので入力しません。 -
vCPUsはm3.mediumなので1を指定します。 -
Memory(MiB)はm3.mediumなので3072を指定します。(m3.mediumが3.75GBなので超えないように指定しています。) -
Job Attemptsは1度だけRunnableに移行すれば良いので1を指定します。 -
uLimitsは特に指定しません。 -
Parameterは特に指定しません。
-

-
Environment variables
- 下記を設定する。
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_S3_BUCKET_NAME
- 下記を設定する。
-
Security
- 今回は特に指定しません。
-
Volumes
- 今回は特に指定しません。
-
Mount points
- 今回は特に指定しません。
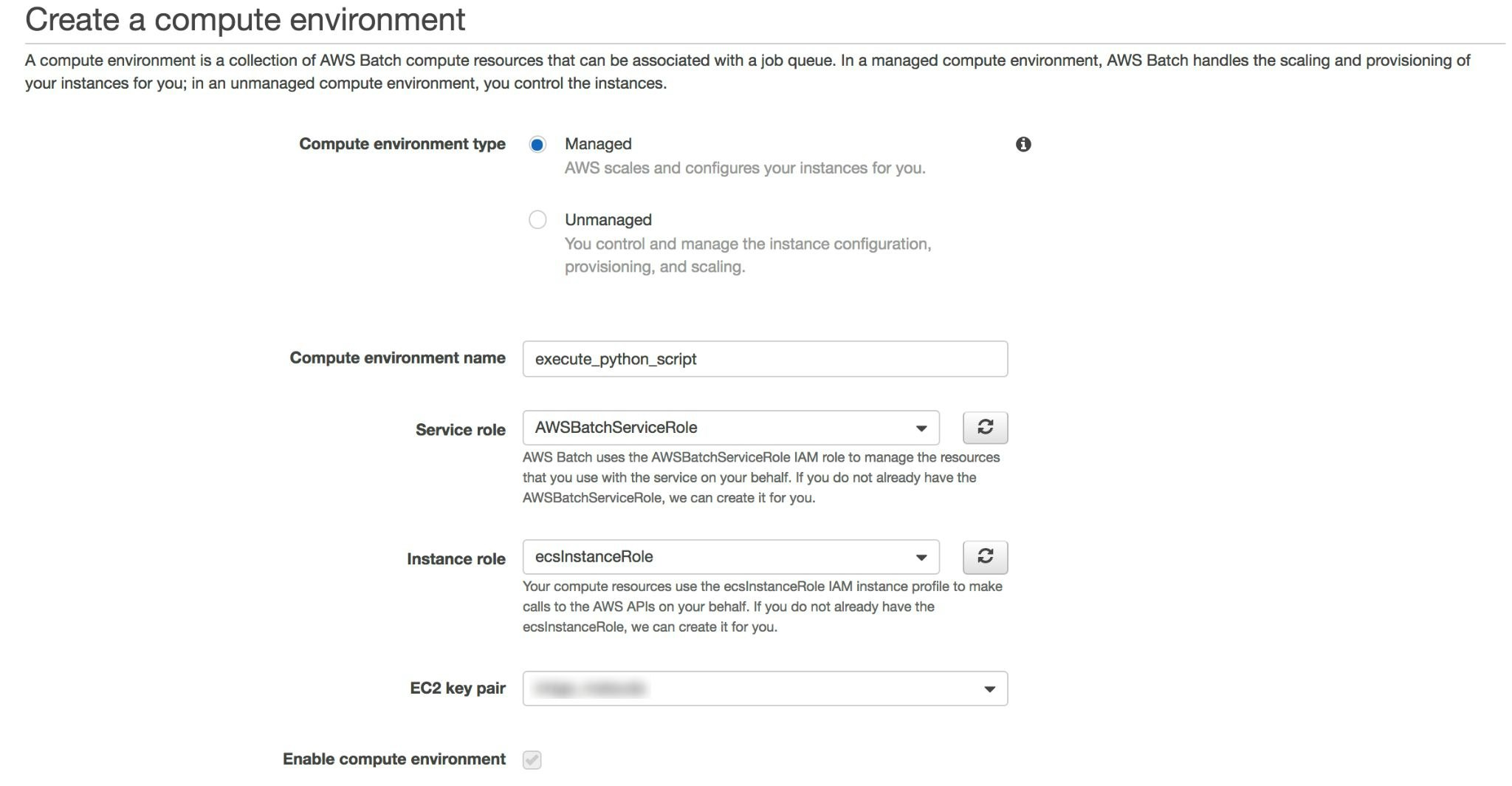
Compute Environmentの作成
- マネジメントコンソールでAWS Batchを開きます。
- Create a compute environment
-
Compute environment typeでManagedを選択します。 -
Compute environment nameで今回はexecute_python_script_envを入力します。 -
Service RoleでAWSBatchServiceRoleを選択します。 -
Instance RoleでecsInstanceRoleを選択します。 -
EC2 Key Pairで任意のKeyを選択します。
-
- Configure your compute resources
-
Provisioning Modelで今回はOn demandを選択します。 -
Allow instance typesで今回は大した処理を行わないかつ安くいきたいのでm3.mediumを選択します。(optimalがデフォルトで選択されていますがc4.largeといったインスタンスが選択されるので状況に応じての選択が重要となります。) -
Minimum vCPUs(環境で維持する必要がある EC2 vCPU の最小数。)は1を選択します。 -
Desired vCPUs(コンピューティング環境で必要なEC2 vCPUSの数)は1を選択します。 -
Maximum vCPUs(環境で到達できる EC2 vCPU の最大数)は1とします。 -
Enable user-specified AMI IDにチェックは入れません。
-

-
Networking-
VCP IDでは使用するものを選択します。 -
Subnetsでは使用するものにチェックをつけます。 -
Security groupsは任意のものを選択します。
-

-
EC2 Tags-
EC2 Tagはお好みで。
-
Job Queue作成
-
Queue nameは今回put-csv-to-s3を入力する。 -
Priorityは1を入力する。 -
Enable Job queueはチェックを入れる。 -
Select a compute environmentは先程作成したexecute_python_script_envを選択します。
Jobの実行
ここまで来たらジョブを実行していきます。まず、Jobsでsubmit jobを選択します。
- Job run-time
-
job nameはtest-put-csv-to-s3を入力します。 -
Job definitionは先程作成したput-csv-to-s3:1を選択します。 -
Job queueは先程作成したput-csv-to-s3を選択します。 -
Job typeはsingleを選択します。 -
Job depends onは特に入力しません。
-

-
Environment、Environment variablesはJob Denitionsで定義したものがセットされているのでそのまま利用します。
submitすると様々な状態にがありますが、詳細はこちらを御覧ください。
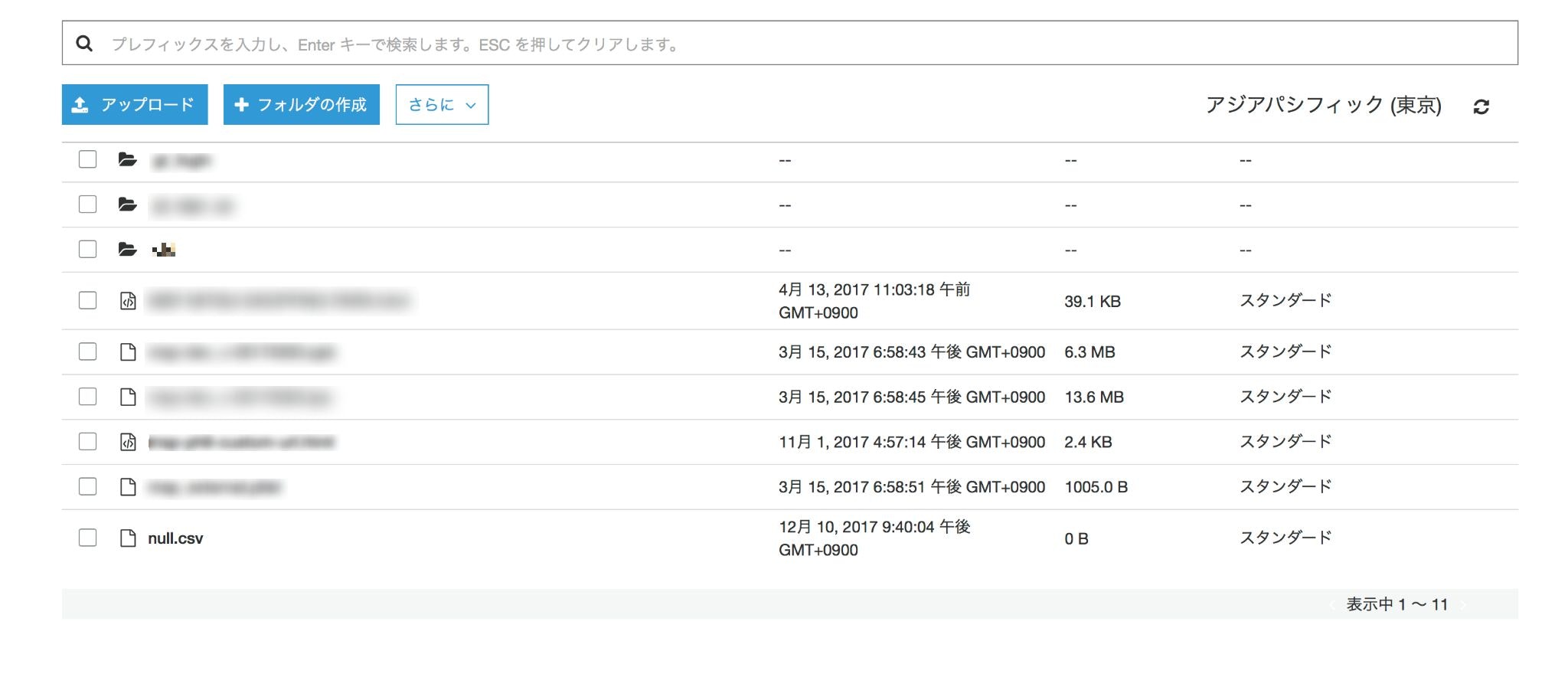
よっしゃ、成功した。

S3バケット内にnull.csvがありました。よさそうです。
lambdaでJobを叩くスクリプト作成
下記の関数を作成する。
lambda_function.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import boto3
batch = boto3.client('batch')
def submit_job(event):
result = batch.submit_job(
jobName=event['JobName'],
jobQueue=event['JobQueue'],
jobDefinition=event['JobDefinition']
)
return result
def lambda_handler(event, context):
result = submit_job(event)
print(result)
return None
環境変数は下記を指定。
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEY-
AWS_DEFAULT_REGION(ap-northeast-1を指定)
CloudWatch Eventsで実行する時間を指定
CloudWatch Eventsのルールより設定を行なう。
- イベントソース
- スケジュール
- Cron式
-
0 16 * * ? *(UTCなので日本時間の毎日1時に起動します。)
-
- Cron式
- スケジュール
- ターゲット
-
Lambda関数を指定します。 -
機能は先程作成したsubmit-jobを選択します。 -
入力の設定は下記を入力します。(xxxxxxxxxxxxxはアカウントID){ "JobName": "put-csv-to-s3", "JobQueue": "put-csv-to-s3", "JobDefinition": "arn:aws:batch:ap-northeast-1:xxxxxxxxxxxxx:job-definition/put-csv-to-s3:1" }
-
これで定期的に実行が可能となります。
まとめ
AWS BatchでPythonスクリプトを定期的に実行することができました。
今後は、CI/CDの部分(イメージ作成・Job Definitionの更新等)で改善できる余地があるので対応していきたいと思います。