想定読者
- 非同期処理がいまいちイメージできないという人
- 非同期処理って具体的にどう書くの?という人
- Pythonの基本文法はなんとなく知っているよという人(←具体的な実装方法を知りたい人のみ)
- Pythonがパソコンにインストールされている(←動作確認したい人のみ)
非同期処理、同期処理とは?
まずは結論から。
非同期処理とは、
あるタスクが終了するのを待っている間、別のタスクを実行すること。
同期処理とは、
処理を順番に実行していくこと。
以下、詳しく書いて行きます。
非同期処理のイメージ
非同期処理のイメージは、
家事を並行してこなすことに似ています。
例えば、
ご飯を炊いている間、炊飯器の前でただ炊けるのを待っていては、時間がもったいないです。
炊けるまでの1時間の間に、他のメニューを作ったり、部屋の掃除をした方が効率的です。
このように、
タスクA(ご飯を炊く)が完了するまでの間、別のタスクBやC(食材を切る、掃除機をかける)を行うのが、非同期処理です。
対して、
同期処理は、1つのタスクが完了してから次のタスクに移る処理のことをいいます。
同じ家事を例にするなら、
1ご飯を炊く
2食材を切る
3部屋の掃除をする
と、順番にこなしていくということです。
作業の効率としては非同期処理に劣るかもしれませんが、
処理が直線的な分、プログラムの流れを理解しやすいというメリットもあります。
ここまでのまとめ
- 非同期処理
- 「同時に、複数」のタスクを処理する方法で、タスクの完了を待っている間に他のタスクを開始できる
- メリット:効率的に処理を進めることができる
- デメリット:プログラムの複雑さが増し、コードが分かりにくくなる
- 同期処理
- 「順番に、一つずつ」タスクを完了させる方法
- メリット:非同期と比べ、プログラムが簡単で理解しやすい
- デメリット:プログラムの処理としては効率が悪くなる可能性あり
【全文】Pythonコードで非同期処理の動きを確認
それではPythonのコードで非同期処理を実装してみます。
完成したコードは以下になります。
import datetime
import aiohttp
import asyncio
start = datetime.datetime.now()
def log(message):
print(f'{(datetime.datetime.now() - start).seconds}秒経過', message)
async def fetch(session, url):
"""非同期にURLからデータを取得する関数"""
print(f"Fetching {url}")
async with session.get(url) as response:
return await response.text()
async def main():
log("タスク開始")
"""メインの非同期処理を行う関数"""
urls = [
"http://google.com",
"http://qiita.com",
"https://www.python.org/",
"https://www.mozilla.org/en-US/",
"https://html.spec.whatwg.org/multipage/",
"https://www.w3.org/TR/css/",
"https://ecma-international.org/",
"https://www.typescriptlang.org/",
"https://www.oracle.com/jp/java/technologies/",
"https://www.ruby-lang.org/ja/",
"https://www.postgresql.org/",
"https://www.mysql.com/jp/",
"https://docs.djangoproject.com/ja/5.0/",
"https://spring.pleiades.io/projects/spring-boot",
"https://rubyonrails.org/"
"https://firebase.google.com/?hl=ja",
"https://go.dev/",
"https://nodejs.org/en"
]
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
print("Starting tasks...")
# 非同期タスクを開始する前にメッセージを出力
print("Tasks are running in the background...")
# 非同期タスクの結果を待つ
results = await asyncio.gather(*tasks)
print("Tasks completed. Results:")
for result in results:
print(result[:100]) # 結果の最初の100文字を表示
log("タスク終了")
# asyncio.run()を使ってメイン関数を実行する
if __name__ == "__main__":
asyncio.run(main())
「urls = [...]」で20個近いウェブサイトのURLを定義しています。
上記のコードは、複数サイトの情報(HTML)を、
非同期で(並行して)取得しに行っています。
必要なライブラリのインストール
上記コードは、
aiohttpというライブラリを別途インストールする必要があります。
以下コマンドでインストールできます。
pip install aiohttp
aiohttpは、
ウェブページから情報を取得する作業など、待ち時間が発生する処理を非同期にするためのライブラリです。
aiohttpを使うことで、
ウェブ関連の処理で待ち時間が長いタスクを非同期で行うことができ、
システムの処理効率を向上させることができます。
公式サイトでは、aiohttpを以下のように定義しています。
Asynchronous HTTP Client/Server
Client(クライアント)/Server(サーバー)は、役割にちなんだコンピュータの呼び方です。
クライアントはサービスやデータを要求する側(例: ウェブブラウザ)、
サーバーはそれに応答してデータを提供する側(例: ウェブサイト)のことです。
HTTPは、
インターネット上で情報をやり取りするためのルールのことです。
これは「HyperText Transfer Protocol」の略で、「ハイパーテキスト(ウェブページを相互にリンクで結びつけることができるテキスト)を転送するための手順」という意味になります。
ようするにHTTPとは、
ウェブブラウザ(Google ChromeやSafariなど)とウェブサーバー(ウェブページを提供するコンピュータ)が、インターネットを介してお互いに話すための「共通の言語」のようなものです。
一方が日本語で話しているのに、もう一方が英語で話してたら、コミュニケーションがしづらいです。
システム同士がやり取り(通信)する際にも、「これからHTTPで話そうぜ」といったルールが必要になります。
動作確認
Pythonコマンドで、作成した処理を実行してみます。
python3 async_http_request.py
出力結果は以下のようになります。
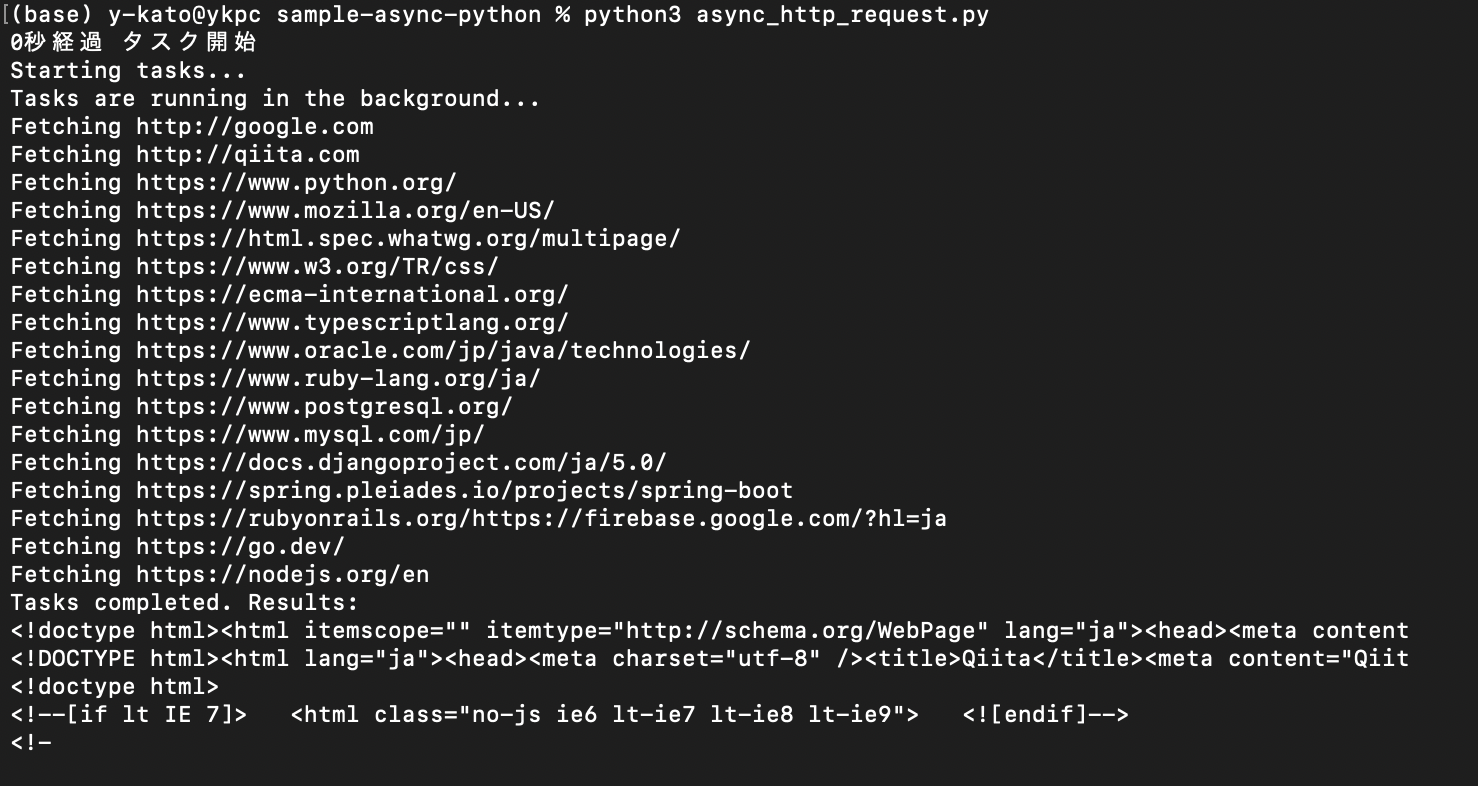
非同期で(並行処理で)URLから情取得したおかげか、
最終的に2秒ほどで処理が完了しました。

1行ずつ解説
1.
import aiohttp
import asyncio
aiohttpとasyncioという2つのツールをプログラムに追加します。
aiohttpはウェブサイトからデータを非同期で取得するため、
asyncioはプログラムが複数のことを同時に行えるようにするためのツールです。
2.
async def fetch(session, url):
fetchという名前の関数を作成します。
この関数は非同期に動作し、ウェブサイトのデータを取得します。
sessionとurlという2つの引数が必要です。
3.
print(f"Fetching {url}")
どのウェブサイトからデータを取得しようとしているかを画面に表示します。
文字列の前にあるfは、
Pythonの「フォーマット済み文字列リテラル(f-string)」を示しています。
fが付いた文字列内で、{}内に書いた変数の結果を、文字列として埋め込むことができます。
4.
async with session.get(url) as response:
指定したurlのウェブサイトからデータを非同期に取得し始めます。
取得したデータはresponseという変数に保存されます。
5.
return await response.text()
ウェブサイトから受け取ったデータをテキスト形式で返します。
6.
async def main():
メインの処理を行うmainという名前の関数を作成します。
この関数も非同期に動作します。
7.
urls = [
"http://google.com",
"http://qiita.com",
"https://www.python.org/",
"https://www.mozilla.org/en-US/",
"https://html.spec.whatwg.org/multipage/",
"https://www.w3.org/TR/css/",
"https://ecma-international.org/",
"https://www.typescriptlang.org/",
"https://www.oracle.com/jp/java/technologies/",
"https://www.ruby-lang.org/ja/",
"https://www.postgresql.org/",
"https://www.mysql.com/jp/",
"https://docs.djangoproject.com/ja/5.0/",
"https://spring.pleiades.io/projects/spring-boot",
"https://rubyonrails.org/"
"https://firebase.google.com/?hl=ja",
"https://go.dev/",
"https://nodejs.org/en"
]
データを取得したいウェブサイトのアドレスを、urlsという変数にリストとして保持します。
8.
async with aiohttp.ClientSession() as session:
aiohttpを使って、
ウェブサイトと情報をやり取りするためのセッションを開始します。
ここでの「セッション」とは、ウェブサイトとの一連の情報交換の期間を指します。
async withを使っているのは、
この情報交換(データの送受信)を他のタスクと同時並行で進められるようにするためです。
9.
tasks = [fetch(session, url) for url in urls]
各ウェブサイトのアドレスに対してfetch関数を呼び出し、その結果を待つタスクのリストを作成します。
10.
print("Starting tasks...")
print("Tasks are running in the background...")
タスクが開始されたことを画面に表示しています。
11.
results = await asyncio.gather(*tasks)
全てのタスクが完了するのを待ち、その結果をresultsに保存します。
12.
print("Tasks completed. Results:")
for result in results:
print(result[:100])
全てのタスクが完了したことを出力。
そして、取得結果の最初の100文字を、一つずつ画面に表示します。
13.
if __name__ == "__main__":
asyncio.run(main())
このプログラム(async_http_request.py)が、
直接実行された場合にのみ(「python3 ファイル名」で実行された時のみ)、
main関数を非同期で実行します。
__name__は、現在のファイルの名前を表す組み込み変数です。
もしファイルが直接実行されている場合、__name__の値は"main"になります。
一方、ファイルが他のファイルからインポートされている場合(つまり、モジュールとして使用されている場合)、__name__はそのファイル名(拡張子.pyなし)になります。
__name__を利用することで、
ファイルがスクリプトとして実行された時にのみ実行したい処理(例えば、テストコードやデモ用のコード)をif name == "main":の下に記述することができます。
これにより、他のファイルからこのファイルをインポートしても、インポートした側で不要なコードが実行されることを防げます。
同期処理との比較
上記の非同期処理を、今度は同期処理で書いて処理速度を比較してみます。
コードの全文は以下のようになります。
import datetime
import requests
start = datetime.datetime.now()
def log(message):
"""ログを出力する関数"""
print(f'{(datetime.datetime.now() - start).seconds}秒経過', message)
def fetch(url):
"""同期的にURLからデータを取得する関数"""
print(f"Fetching {url}")
response = requests.get(url)
return response.text
def main():
"""メインの同期処理を行う関数"""
log("タスク開始")
urls = [
"http://google.com",
"http://qiita.com",
"https://www.python.org/",
"https://www.mozilla.org/en-US/",
"https://html.spec.whatwg.org/multipage/",
"https://www.w3.org/TR/css/",
"https://ecma-international.org/",
"https://www.typescriptlang.org/",
"https://www.oracle.com/jp/java/technologies/",
"https://www.ruby-lang.org/ja/",
"https://www.postgresql.org/",
"https://www.mysql.com/jp/",
"https://docs.djangoproject.com/ja/5.0/",
"https://spring.pleiades.io/projects/spring-boot",
"https://rubyonrails.org/"
"https://firebase.google.com/?hl=ja",
"https://go.dev/",
"https://nodejs.org/en"
]
print("Starting tasks...")
# 同期的にHTTPリクエストを実行
results = [fetch(url) for url in urls]
print("Tasks completed. Results:")
for result in results:
print(result[:100]) # 結果の最初の100文字を表示
log("タスク終了")
if __name__ == "__main__":
main()
一つのウェブサイトから情報を取得した後、次のサイトの取得へ進んでいます。
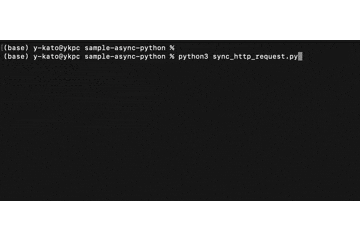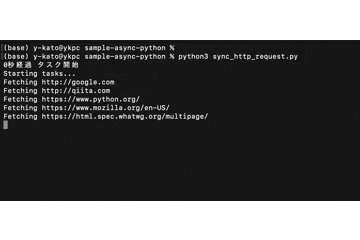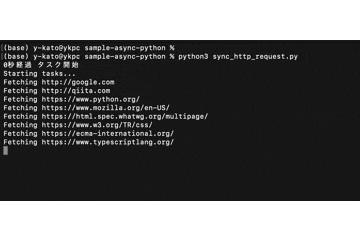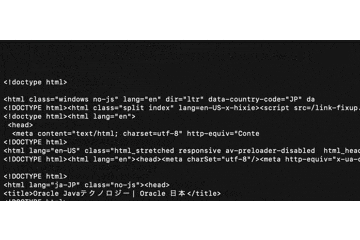
最終的に10秒ほどで完了。
並行して動いていた非同期処理と比べて、結構時間がかかっています。

上記のコードを実行するには「requests」ライブラリが必要なので、動作確認したい人は以下コマンドでインストールしましょう。
pip install requests
まとめ
- 非同期処理とは、「同時に、複数」のタスクを処理する方法で、タスクの完了を待っている間に他のタスクを開始できる処理のこと。
- (例)いろんな家事を並行して行う
- 「待ち時間が発生するような処理」を非同期で実装する
- (例)Webサイトからデータを取得する、ファイルのアップロード、大量のデータ操作、チャットアプリの送受信、など
- Pythonで非同期処理を実装する際は、標準ライブラリ(Pythonインストールしたら初めから使える)のasyncioを使う
- asyncがdefの前にあったら「この関数は非同期で行われるんだな」と理解する
- awaitは、asyncが付いた関数の中でしか使えない。awaitが前についた処理は非同期処理
- awaitの処理が終わるのを待っている間、プログラム全体は停止することなく、他のタスクを進められる
- (例)
delicious_rice = await cook_riceのようにあったら、「cook_riceしてる間に他の処理進めるんだな」と考える
- (例)
参考
GitHub
今回書いたコードに加えて、
非同期処理のサンプルコードを私のGitHubで公開しています。
https://github.com/katoyuki1/sample-async-python
これからより非同期処理でできることを研究し解説できるようになりたいと思います。
Python以外のコードでも書いてみたり。
補足
@shiracamusさんの記事「Pythonで非同期処理をシンプルに書けない例」に
非同期処理の動きがより分かりやすいサンプルコードで記載されております!
shiracamusさん、ありがとうございます!勉強になりました🙇♂️