はじめに
まずはこれを見てください。

チャットで
メッセージ機能ってなに?
と問い合わせた様子になります。
今回はn8nとQdrantをローカルで構築し、ローカルLLMを使用したチャットボットを構築したので、紹介したいと思います。
この記事はTDCソフト株式会社Advent Calendarの4日目です。
環境
今回使用したPC環境は以下の通りです。
| 項目 | スペック |
|---|---|
| OS | Windows11 |
| CPU | AMD Ryzen 7 7700 |
| メモリ | 32GB |
| GPU | NVIDIA RTX 4070 SUPER |
AIに特化した環境では全然ないです。
ただ、これくらいでもある程度動くのはなかなかすごいですよね。
n8n とは?
n8nは、オープンソースのワークフロー自動化ツールです。
ZapierやMake(旧Integromat)のようなツールですが、セルフホスト可能で、ノードベースのUIでワークフローを視覚的に構築できます。
Qdrant とは?
Qdrantは、ベクトル類似度検索に特化したオープンソースのベクトルデータベースです。
RAG(Retrieval Augmented Generation)の構築において、ドキュメントの埋め込みベクトルを保存し、類似検索を行うために使用します。
LM Studio とは?
LM Studioは、ローカル環境でLLM(大規模言語モデル)を簡単に実行できるデスクトップアプリケーションです。
Hugging Faceから様々なモデルをダウンロードし、OpenAI互換のAPIサーバーとして公開できます。
今回は以下のモデルを使用しました。
| 用途 | モデル |
|---|---|
| チャット生成 | openai/gpt-oss-20b |
| 埋め込み(Embedding) | text-embedding-nomic-embed-text-v1.5 |
※LM Studioの導入方法については、公式サイトや他の記事を参照してください。本記事では割愛します。
環境構築
ディレクトリ構成
n8n/
├── docker-compose.yml # n8nとQdrantのコンテナ定義
├── ingest_faq.py # FAQデータをQdrantに導入するスクリプト
└── data/ # FAQデータ
Docker Compose
n8nとQdrantをDocker Composeで起動します。
services:
n8n:
image: n8nio/n8n:latest
ports:
- "5678:5678"
environment:
- GENERIC_TIMEZONE=Asia/Tokyo
volumes:
- n8n_data:/home/node/.n8n
qdrant:
image: qdrant/qdrant
ports:
- "6333:6333"
volumes:
- qdrant_data:/qdrant/storage
volumes:
n8n_data:
qdrant_data:
起動
以下のコマンドでコンテナを起動します。
docker-compose up -d
起動後、以下のURLでそれぞれのサービスにアクセスできます。
- n8n: http://localhost:5678
- Qdrant Dashboard: http://localhost:6333/dashboard
FAQデータの準備
RAGのナレッジベースとなるFAQデータを用意します。
今回は Japanese FAQ dataset for e-learning system のデータを使用します。
以下のデータをダウンロードして使用します。
Answer2Category.csv: Categories of answers.
Answer2Tag.csv: Titles of answers.
Answers.csv: IDs for answers and texts of answers.
Categories.csv: Names of categories for answers.
Questions.csv: Texts of questions and their corresponding answer IDs.
Qdrant にデータを入れる
先ほどダウンロードしたデータを Qdrant に入れていきます。
n8n のフロー内で取得したデータを成形し、 Qdrant に入れていくこともできますが、今回は Python でデータを入れます。
質問・回答・タグ・カテゴリが分かれていますので、これらを成形していきます。
ソースコード
import csv
import json
import os
from datetime import datetime
def load_csv(file_path: str, encoding: str = "utf-8") -> list[dict]:
"""CSVファイルを読み込み、辞書のリストとして返す"""
with open(file_path, "r", encoding=encoding) as f:
reader = csv.DictReader(f)
return list(reader)
def clean_html(text: str) -> str:
"""HTMLタグをクリーンアップしてプレーンテキストに変換"""
import re
# <br>タグを改行に変換
text = re.sub(r'<br\s*/?>', '\n', text, flags=re.IGNORECASE)
# <a>タグからURLを抽出してテキストに変換
text = re.sub(r'<a[^>]*href="([^"]*)"[^>]*>([^<]*)</a>', r'\2 (\1)', text)
# その他のHTMLタグを削除
text = re.sub(r'<[^>]+>', '', text)
# 連続する改行を整理
text = re.sub(r'\n{3,}', '\n\n', text)
return text.strip()
def convert_zenodo_to_faq(data_dir: str, output_file: str):
"""ZenodoのFAQデータをfaq.json形式に変換"""
# ファイルパスを構築
questions_file = os.path.join(data_dir, "Questions.csv")
answers_file = os.path.join(data_dir, "Answers.csv")
categories_file = os.path.join(data_dir, "Categories.csv")
answer2category_file = os.path.join(data_dir, "Answer2Category.csv")
answer2tag_file = os.path.join(data_dir, "Answer2Tag.csv")
# CSVファイルを読み込み
print("CSVファイルを読み込み中...")
questions = load_csv(questions_file)
answers = load_csv(answers_file)
categories = load_csv(categories_file)
answer2category = load_csv(answer2category_file)
answer2tag = load_csv(answer2tag_file)
print(f" - Questions: {len(questions)}件")
print(f" - Answers: {len(answers)}件")
print(f" - Categories: {len(categories)}件")
# マッピングを作成
# 回答ID -> 回答テキスト
answer_map = {row["AID"]: row["Text"] for row in answers}
# カテゴリID -> カテゴリ名
category_map = {row["CID"]: row["Title"].strip('"') for row in categories}
# 回答ID -> カテゴリID
answer_to_category = {row["AID"]: row["CID"].strip() for row in answer2category}
# 回答ID -> タグリスト
answer_to_tags = {}
for row in answer2tag:
aid = row["AID"]
tag = row["Tag"].strip('"')
if aid not in answer_to_tags:
answer_to_tags[aid] = []
answer_to_tags[aid].append(tag)
# FAQデータを構築
faqs = []
faq_count = 0
today = datetime.now().strftime("%Y-%m-%d")
# 質問と回答を結合
for q_row in questions:
question_text = q_row["Text"].strip().strip('"')
answer_id = q_row[" AID"].strip() if " AID" in q_row else q_row["AID"].strip()
# 回答IDから回答を取得
if answer_id not in answer_map:
continue
answer_text = clean_html(answer_map[answer_id])
# カテゴリを取得
category = ""
if answer_id in answer_to_category:
category_id = answer_to_category[answer_id]
category = category_map.get(category_id, "")
# タグを取得
tags = answer_to_tags.get(answer_id, [])
# FAQエントリを作成
faq_count += 1
faq_entry = {
"id": f"elearn_{faq_count:03d}",
"question": question_text,
"answer": answer_text,
"tags": tags if tags else ["elearning"],
"metadata": {
"category": category if category else "e-Learning",
"updated_at": today,
"source": "zenodo_2783642"
}
}
faqs.append(faq_entry)
print(f"\n生成したFAQ数: {len(faqs)}")
# JSONとして保存
output_data = {"faqs": faqs}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
print(f"出力ファイル: {output_file}")
# カテゴリ別の統計
category_stats = {}
for faq in faqs:
cat = faq["metadata"]["category"]
category_stats[cat] = category_stats.get(cat, 0) + 1
print("\nカテゴリ別統計:")
for cat, count in sorted(category_stats.items(), key=lambda x: -x[1]):
print(f" - {cat}: {count}件")
return faqs
def merge_with_existing(existing_file: str, new_faqs: list) -> list:
"""既存のfaq.jsonと新しいFAQをマージ"""
try:
with open(existing_file, "r", encoding="utf-8") as f:
existing_data = json.load(f)
existing_faqs = existing_data.get("faqs", [])
except FileNotFoundError:
existing_faqs = []
# 既存のFAQを保持しつつ、新しいFAQを追加
merged_faqs = existing_faqs + new_faqs
return merged_faqs
def main():
print("Zenodo FAQ データセットを faq.json 形式に変換します")
# パスを設定
base_dir = os.path.dirname(__file__)
data_dir = os.path.join(base_dir, "data")
# 単一の canonical 出力を生成する
output_file = os.path.join(base_dir, "faq.json")
# 変換を実行して単一の faq.json を作成
_ = convert_zenodo_to_faq(data_dir, output_file)
print("faq.json を出力しました。ingest スクリプトで利用できます。")
if __name__ == "__main__":
main()
正常に完了すると、Qdrant Dashboard( http://localhost:6333/dashboard )でコレクションが作成されていることを確認できます。
LM Studio の設定
LM Studioを起動し、以下のモデルをダウンロードしておきます。
チャット用モデル: openai/gpt-oss-20b
埋め込み用モデル: text-embedding-nomic-embed-text-v1.5(デフォルトで入ってるかも?)
モデルのダウンロード後、LM StudioのServerタブからローカルサーバーを起動します。
n8n でワークフロー構築
ここまでの下準備が完了したら、実際にワークフローを構築していきます。
1. n8n の初期設定
http://localhost:5678/ へアクセスします。
アクセスすると初回は以下の画面が表示され、管理用ユーザの作成を促されます。
必要情報を入力したら「Next」をクリックします。
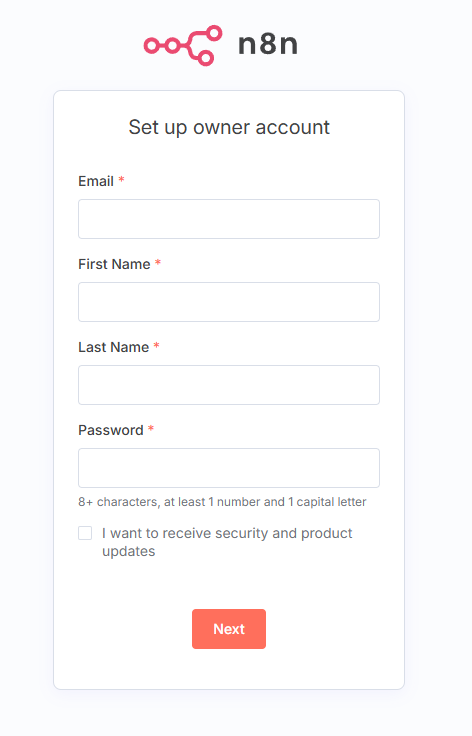
入力が完了すると以下が表示されます。
設定することも可能ですが、何も選ばずに「Get started」でも行けます。

次に進むとライセンスキーの取得を促されます。
実運用では検討したほうが良いと思いますが、今回はいったん「Skip」を選択します。
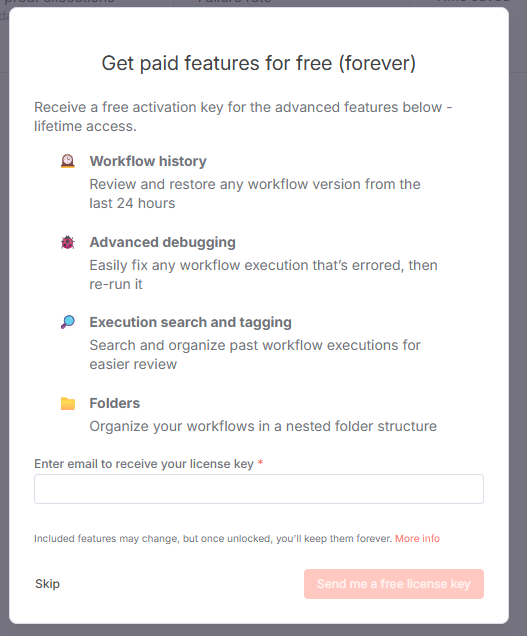
これで初期設定は完了です。
2. Credentialsの設定
まず、n8nでLM StudioとQdrantに接続するためのCredentialsを設定します。
画面真ん中の「Credentials」を選択し、画面右上の「Create Credential」を押下します。
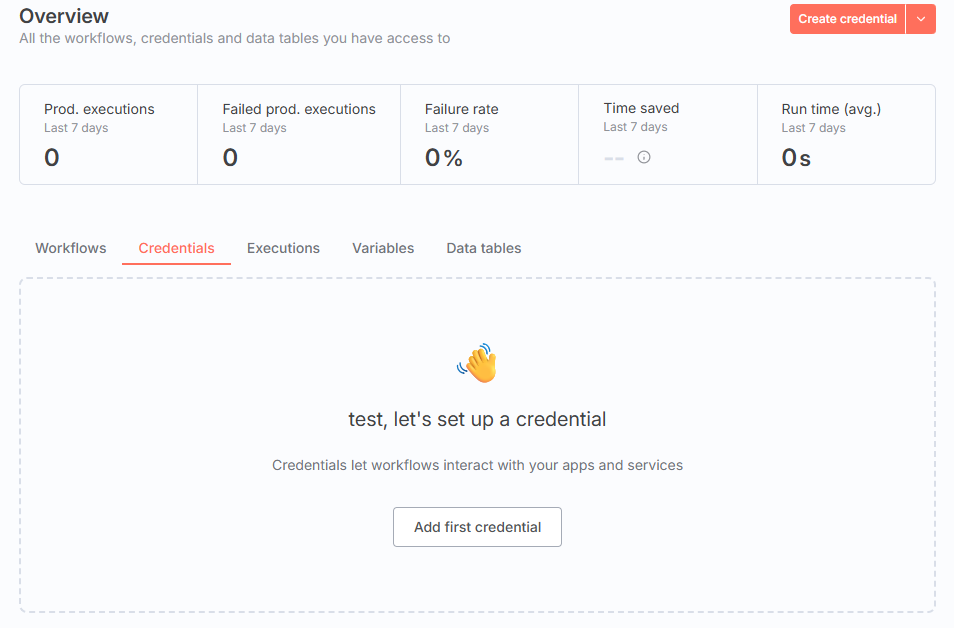
以下が表示されますので、サービスを入力して必要なCredentialsの設定を行っていきます。

OpenAI API Credentials(LM Studio用)
LM StudioはOpenAI互換のAPIを提供しているため、OpenAI APIのCredentialsとして登録します。

以下を設定して、「Save」を押します。
- API Key:
lm-studio(任意の文字列でOK) - Base URL:
http://host.docker.internal:1234/v1
Qdrant API Credentials
続けてQdrantも設定します。

以下を設定して、「Save」を押します。
- API Key: 空欄
- Qdrant URL:
http://qdrant:6333
これで認証情報の準備は完了です。
3. チャットボット用ワークフロー
では実際にユーザーからの質問に回答するRAGワークフローを作成します。
今回は n8n 内に用意されているチャットをトリガーにレスポンスを取得します。
画面真ん中の「Workflows」を選択し、「Create workflow」を選択します。
あとはワークフローを作るだけです。
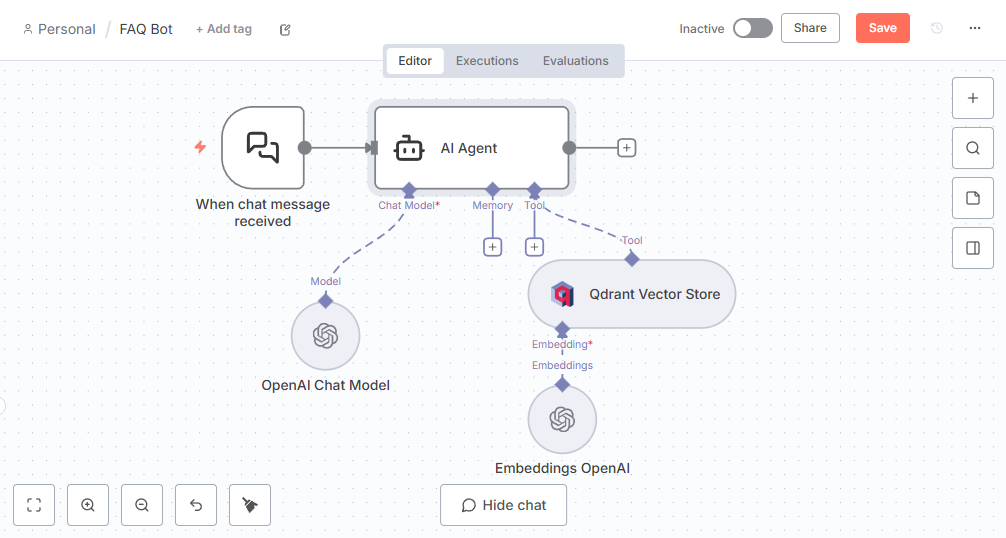
出来ました。
ちなみにJSONでインポートできますので、JSONも置いておきます。
インポート用JSON
{
"name": "FAQ Bot",
"nodes": [
{
"parameters": {
"promptType": "define",
"text": "=あなたはe-Learningシステム「kibaco」のサポートAIです。ユーザーからの問い合わせに対して、FAQデータベースを検索し、親切で簡潔な回答を提供してください。\n\n【重要な制約】\n- 回答は1800文字以内に収めてください\n- 日本語で回答してください\n- 必ずFAQツールを使用して関連情報を検索してください\n- FAQに関連情報がある場合は、その内容に基づいて正確に回答してください\n- FAQに関連情報がない場合は「申し訳ございませんが、関連する情報が見つかりませんでした。詳細についてはサポートチームにお問い合わせください。」と回答してください\n\n【回答の優先順位】\n1. FAQ検索結果の中で最もユーザーの質問に近い内容を優先する\n2. 複数のFAQが関連する場合は、要点をまとめて回答する\n3. 部分的に関連する情報でも、ユーザーの参考になる場合は提示する\n\n【禁止事項】\n- FAQにない情報を推測で補わないこと\n- 検索結果を無視して一般的な回答をしないこと\n- 技術的な詳細を勝手に追加しないこと\n\n【回答スタイル】\n- 適切に絵文字を使用して親しみやすい回答にする\n- 箇条書きを活用して読みやすくする\n- 手順がある場合は番号付きリストで説明する\n\n【ユーザーの質問】\n{{ $json.chatInput }}"
},
"alwaysOutputData": false,
"id": "d9aab823-9879-4942-94cc-f51535ca1f03",
"name": "AI Agent",
"position": [
176,
0
],
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3
},
{
"parameters": {
"model": {
"__rl": true,
"cachedResultName": "openai/gpt-oss-20b",
"mode": "list",
"value": "openai/gpt-oss-20b"
},
"responsesApiEnabled": false,
"options": {
"maxTokens": 2000,
"temperature": 0.15
}
},
"id": "a70d8141-72bf-4cd1-add6-161659e890ed",
"name": "OpenAI Chat Model",
"position": [
80,
224
],
"type": "@n8n/n8n-nodes-langchain.lmChatOpenAi",
"typeVersion": 1.3,
"credentials": {
"openAiApi": {
"id": "PuoVDjZQRkz3vBXM",
"name": "OpenAi account"
}
}
},
{
"parameters": {
"model": "text-embedding-nomic-embed-text-v1.5",
"options": {
"encodingFormat": "float"
}
},
"id": "7764be64-44aa-4638-a3d8-2126a24f01e4",
"name": "Embeddings OpenAI",
"position": [
352,
320
],
"type": "@n8n/n8n-nodes-langchain.embeddingsOpenAi",
"typeVersion": 1.2,
"credentials": {
"openAiApi": {
"id": "PuoVDjZQRkz3vBXM",
"name": "OpenAi account"
}
}
},
{
"parameters": {
"mode": "retrieve-as-tool",
"toolDescription": "FAQ情報を検索するためのツールです。ユーザーの質問に関連する情報を見つけるために必ず使用してください。検索クエリは日本語で、ユーザーの質問のキーワードを含めてください。",
"qdrantCollection": {
"__rl": true,
"cachedResultName": "faq",
"mode": "list",
"value": "faq"
},
"options": {}
},
"id": "4de0f7ee-e6e9-4148-9cf5-58044ad4a3b7",
"name": "Qdrant Vector Store",
"position": [
352,
176
],
"type": "@n8n/n8n-nodes-langchain.vectorStoreQdrant",
"typeVersion": 1.3,
"credentials": {
"qdrantApi": {
"id": "OMAhScKegsIHG1Xm",
"name": "QdrantApi account"
}
}
},
{
"parameters": {
"options": {}
},
"id": "233359ac-47a6-4e22-bbc5-7d845067ed47",
"name": "When chat message received",
"position": [
0,
0
],
"type": "@n8n/n8n-nodes-langchain.chatTrigger",
"typeVersion": 1.4,
"webhookId": "3fe0bc00-5be1-4d06-8af9-f1e684df22a3"
}
],
"pinData": {},
"connections": {
"Embeddings OpenAI": {
"ai_embedding": [
[
{
"index": 0,
"node": "Qdrant Vector Store",
"type": "ai_embedding"
}
]
]
},
"OpenAI Chat Model": {
"ai_languageModel": [
[
{
"index": 0,
"node": "AI Agent",
"type": "ai_languageModel"
}
]
]
},
"Qdrant Vector Store": {
"ai_tool": [
[
{
"index": 0,
"node": "AI Agent",
"type": "ai_tool"
}
]
]
},
"When chat message received": {
"main": [
[
{
"index": 0,
"node": "AI Agent",
"type": "main"
}
]
]
},
"AI Agent": {
"main": [
[]
]
}
},
"active": false,
"settings": {
"executionOrder": "v1",
"callerPolicy": "workflowsFromSameOwner",
"availableInMCP": false
},
"versionId": "0af32a16-f496-4a67-a687-efc979a65852",
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "2b8a44829ad9781ffb9d10d1f27cb7c2d22455799668ec7149e817645e09b63d"
},
"id": "iWy2qV8p9x10RIsM",
"tags": []
}
ノード構成
先ほど Credential は作成していますので、OpenAI やQdrant Vector Store は作成したものを指定します。
-
Chat Trigger: チャット入力を受け付け
-
AI Agent: 検索結果をコンテキストとして、LLMで回答を生成
- Model:
openai/gpt-oss-20b - System Prompt:以下に記載
System Prompt
あなたはe-Learningシステム「kibaco」のサポートAIです。 ユーザーからの問い合わせに対して、FAQデータベースを検索し、親切で簡潔な回答を提供してください。 【重要な制約】 - 回答は1800文字以内に収めてください - 日本語で回答してください - 必ずFAQツールを使用して関連情報を検索してください - FAQに関連情報がある場合は、その内容に基づいて正確に回答してください - FAQに関連情報がない場合は「申し訳ございませんが、関連する情報が見つかりませんでした。詳細についてはサポートチームにお問い合わせください。」と回答してください 【回答の優先順位】 1. FAQ検索結果の中で最もユーザーの質問に近い内容を優先する 2. 複数のFAQが関連する場合は、要点をまとめて回答する 3. 部分的に関連する情報でも、ユーザーの参考になる場合は提示する 【禁止事項】 - FAQにない情報を推測で補わないこと - 検索結果を無視して一般的な回答をしないこと - 技術的な詳細を勝手に追加しないこと 【回答スタイル】 - 適切に絵文字を使用して親しみやすい回答にする - 箇条書きを活用して読みやすくする - 手順がある場合は番号付きリストで説明する 【ユーザーの質問】 {{ $json.chatInput }} - Model:
-
OpenAI Chat Model: 回答作成を行う生成AI
-
Embeddings OpenAI: 質問文を埋め込みベクトルに変換
-
Qdrant Vector Store (Retrieve): 類似するFAQを検索
- Qdrant Collection:
faq - Limit:
4(上位4件を取得) - Include Metadata: True
- Description:以下に記載
Description
FAQ情報を検索するためのツールです。 ユーザーの質問に関連する情報を見つけるために必ず使用してください。 検索クエリは日本語で、ユーザーの質問のキーワードを含めてください。 - Qdrant Collection:
実際に動かしてみる
ワークフローを構築したら、実際に動かしてみましょう。
チャットボットのテスト
n8nのChat UIから質問を投げてみます。
質問例: 「メッセージ機能ってなに?」
回答例:
📩 メッセージ機能とは?
kibaco では「メッセージ機能」を使って、授業担当者が学生へ直接連絡を送ることができます。
- 送信対象:受講生全員・指定したグループ・個別の受講生(仮登録者も含む)
- 送信形式:kibaco 内でのチャットメッセージとして送れるほか、メールとしても送ることが可能です。メール送信を希望する場合は「電子メールとしても送信」にチェックしてください。
🔧 機能が見当たらないときの対処法
初期設定ではメッセージ機能は非表示になっています。以下の手順で有効化できます:
- 授業情報機能 → 「2. 機能を追加・削除する」
- ここに「メッセージ機能」を追加するオプションがあります(マニュアル26〜27ページ参照)。
- 変更後、kibaco の画面でメッセージアイコンが表示されるようになります。
📚 送信方法の詳細
- メールを全員ではなく一部に送る場合は、対象グループや個別受講生を選択して送信します。
- 詳細な手順は授業担当者向けマニュアル119〜122ページに記載されています。
もし上記の手順で解決しない場合は、サポートチームまでお問い合わせくださいね!
回答が返ってきました。
実際のFAQの回答データを確認したところ、以下の通りでした。
1.初期設定ではメッセージ機能は非表示となっています。こちらの機能を利用するための手順は授業担当者向けマニュアルの26~27ページ(「授業情報機能」の「2. 機能を追加・削除する」)に記載されています。
2.メッセージ機能を使うことによって、受講生全員、指定したグループだけ、指定した(複数可)受講生だけ、といった方法で、仮登録を含む受講生にメッセージを送信できます。なお、メッセージはkibaco内で送受信されるものなので、メッセージを電子メールとしても送りたい場合は「電子メールとしても送信」にチェックが必要です。詳細は授業担当者向けマニュアルの119~122ページをご覧ください。
使用している回答を見る限り、参照して回答が作成されていそうですね。
まとめ
今回は、n8n × Qdrant × LM Studio を組み合わせて、完全ローカル環境で RAG ベースのチャットボットを構築しました。
ローカルで完結させられるため、秘匿性の高いデータ(たとえば契約書の精査や社内の機密ドキュメントの検索など)に対する自動化ワークフローを検討できると感じました。
ただし今回の検証ではデータ数が少なく正規化も十分でなかったため、回答の品質は「それっぽく」動くに留まりました。
以下のような改善を行っていくことで、よりもっともな回答を得られるんじゃないかと感じました。
- データ増強と正規化:ドキュメントの分割・重複排除・メタデータ整備
- 埋め込み品質の向上:高品質な埋め込みモデルの選定や前処理の改善
- プロンプト/パイプライン調整:リランキングや照合ロジック、応答長の制御
また、n8n は多数のノードを組み合わせてワークフロー化でき、並列実行やスケジューリング、エラーハンドリングも可能です。
コンテナでセルフホスティングできることから、n8n を使用した業務効率化も検討していきたいです。
興味がある方はぜひ試してみてください。
参考リンク