昨日、会社でAWSの生成AIハンズオン勉強会を参加しました。
そこでは、AWS上で生成AIの配置やRAGの使い方について学びました。非常に簡単で使いやすいと感じました。
AWSでRAG使う流れとしては大体⇩の通りです。
①AWS Bedrockでモデルを選定
②AWS CDK(Amazon CloudShell、Amazon Cloud9)で新しいアプリケーションを構築
③RAG用データをアップロード(Amazon S3でアップロード、Amazon Kendraで同期)
AWSのRAGは、この"Kendra"を使ってインデックス化、埋め込み、検索までを一括して行っています。
KendraのRAG検索を少し試しました。
使用したモデルはClaude-3で、テストデータは日立が公開された最適化データです。
使われたモデルはClaude3で、試すデータは
一個テキストベースの質問を投げました。実行されたら以下のようになります。

回答は以下となります。(正解です)

RAGでうまく対応できていない表データと画像データはどうなるか試してみましたが、間違いました。表データの位置関係はやはり理解できないですね。(正解は”料金体系決定”)

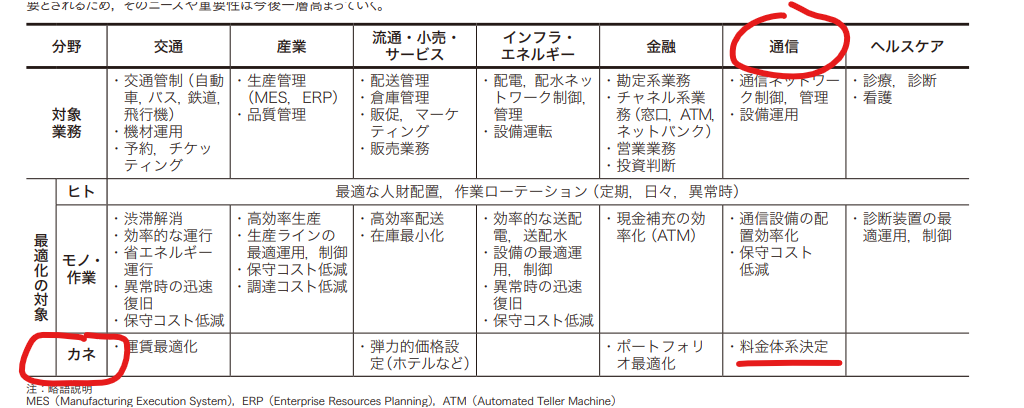
他にも色々試しまして、結果としては悪くはないのですが、やはり表データや画像に対しては弱くて、正確に回答するのは難しいようです。
⇩でも試せますので、興味ある方: