機械学習の回帰と分類タスクに対しては、ほとんどの場合はlightGBMが使われています。
今日は決定木からLightGBMまでの流れと、その過程でどのような改善がなされたのかについて、木モデルの全体像を紹介したいと思います。
木モデルに関して完全に理解しているわけでもないので、間違っているところがあればぜひ教えていただきたいです。
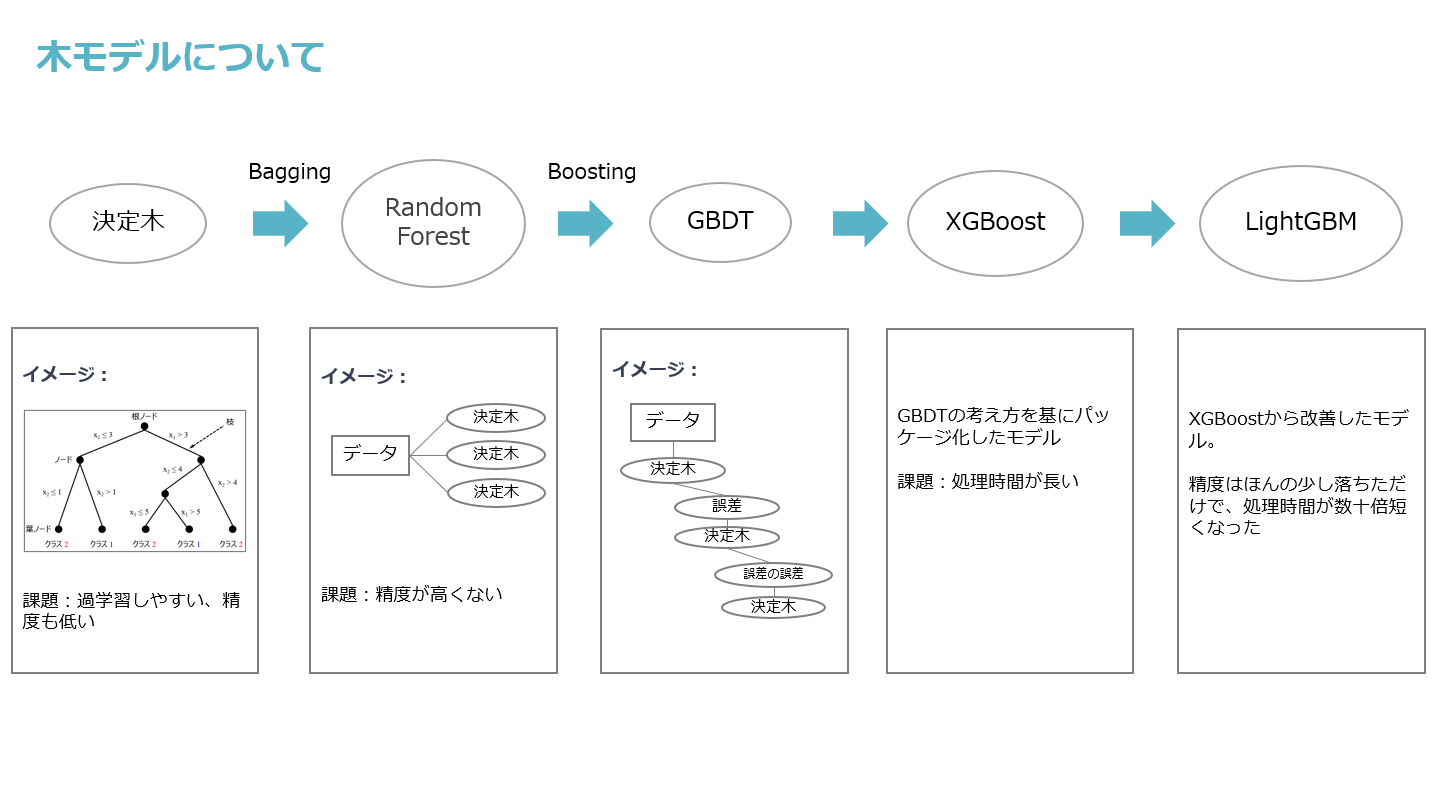
①決定木
まず木モデルで一番ベースとなっているのは決定木です。
決定木とは、データの特徴ごとの優先順位や分割ポイントを学習して、データをカテゴリに分類または数値予測を行うモデルです。
木は一個しかないために、非常に過学習しやすいかつ精度も低いというのは特徴となります。
それを改善するために、Bagging(複数モデルの平均値を取ること)の考え方に基づいて、ランダムフォレスト(RandomForest)というモデルが生まれました。
②ランダムフォレスト
ランダムフォレストは、一回で複数個の決定木を作って、それぞれの結果の平均値/多数決を取ることで、過学習しやすい問題を解決できました。
ですが、たくさんの決定木を作っても、個々の決定木の精度には限界があり、全体としての精度は必ずしも非常に高くなるわけではありません。
精度をさらに向上させるために、Boostingというアプローチが考えられました。
③GBDT
最初公開されたBoosting手法のモデルはGBDTとなります。
GBDTも決定木で予測しますが、1回で複数個の決定木を作るではなく、一つずつ順番に作成します。
各決定木は、前の決定木の予測結果の誤差を学習対象とし、これを繰り返すことで全体としてのモデルの精度を向上させます。
最初の決定木がデータの大まかな特徴を学習して、以降の決定木が誤差を補正していく流れです。
最後すべてのモデルの結果を合わせると、非常に高い精度に達します。
④XGBoost
GBDTはモデルより考え方に近いです。GBDTの考え方を元に使いやすくパッケージ化されたモデルはXGBoostです。
精度が低いという問題点はXGBoostで解決されましたが、決定木を一つずつ順番に作成する必要があるため、
処理時間が非常に長いという新たな問題が生じました。
⑤LightGBM
そこで、2017年にMicrosoftがLightGBMを公開しました。
LightGBMも決定木を一つずつ作る仕組みですが、XGBoostを基に様々な調整を行いました。
主に改善された点は2つあります。(他にも多くの改善がありますが、最も重要なのは以下の2点です)
- Goss(Gradient-based One-Side Sampling)という計算方法の導入
非常に複雑な計算方法ですが、簡単的に言えば、誤差の学習順番をモデル自身で優先順位をつけて、優先順位が高いものから学習する仕組みです。
ある程度の精度に達したら、残りの誤差を学習しても精度が大きく変わらないと判断し、学習を止めます。一方で、XGBoostは特に優先順位などなくて、全ての誤差を学習します。 - 連続値の特徴量を離散値に変換
例えば、「10」,「11」,「12」,「13」,「14」みたいな特徴があれば、これらを「10-14」という一つの特徴量にまとめます。
そうすると、少し精度が落ちますが、データの計算量や学習量は大幅に減少できます。
これら2点の改善により、精度がほんのわずかだけ落ちますが、処理時間はXGBoostの数十倍短くなります。
LightGBMは公開されてから、多くの予測・回帰問題はLightGBMしか使わないようになりました。
ちなみに、今LightGBMとXGBoostはあまり処理時間の差がないです。XGBoostもLightGBMが改善されたところを取り入れて自分のモデルに直しましたので、現在ではどちらにしてもほぼ差がないです。
参考イメージとして以下の図でまとめました。
LightGBM論文:
END