
Introduction
これは Supership Advent Calendar 2018 18日目です。
Supership Holdings傘下のMomentum株式会社の徐が担当させて
いただきます。
Momentumはインターネット広告における、アドフラウド対策やブランドセーフティといった諸課題を解決するソリューションを提供しています。
ここではMomentumでのログデータのETL*の現状とその問題点、行う予定の対応策についてご紹介します。所々割愛させていただきますので予めご了承下さい。
*主にtransformが少し、Loadの話がほとんどを占めます。
MomentumにおけるETLの現状
弊社の大部分のシステムはGoogle Cloud Platform上に構築され、ほとんどのシステムがログデータを吐き出します。
また、ほぼ全てのデータが最終的にはBigQuery上に集約されます。
現行システムの概要
現行のシステムでは以下の図のようにユーザーからの入力に応じてデータをアプリケーションからWebサーバーに転送し、Nginx上でJsonに変換してBigQueryへロードしています。
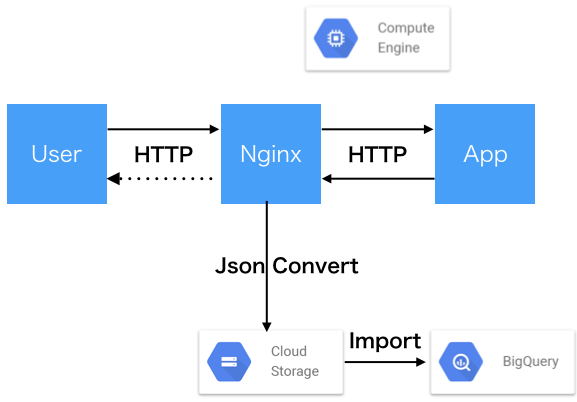
[補足]
ご存知の方もいらっしゃるかとは思いますが、BigQueryにはStreaming Insertというファイルからデータを読み込む代わりに、APIコールでほぼリアルタイムにデータをロードする機能があります。
しかしながら弊社では、利用料金の抑制や、万が一Google側で障害が発生した際のデータの欠損防止、バックアップを目的にこの機能は今回ご紹介するシステムでは使用しておりません。
なぜこうなったのか
- 500エラーなども記録したい = Nginxを挟む理由
- nginxではエスケープされてしまうので、jsonのままログファイルに出力ができない* = Transformが必要な理由
*後述しますが、できるようになりました。
問題点
この構成では、ログのスキーマ(構造体の構造)を知っている必要があるコンポーネントがなんと3つにも及びます。それぞれ
- ログを生成するApplication
- JsonへのTransformを担当するConvertor
- BigQueryのテーブルスキーマ
これらをきちんと管理するのはかなりしんどく、アプリケーションを更新するたびにconvertエラー、importエラー事故が発生します。
また、例えば通常アプリケーションはローリングアップデートを行うのですが、以下のように
{"key": "1"}
{"key": 1}
互換性のない更新をかけてしまった場合に、異なるスキーマを同じログファイルに混ぜることはできないため、このような変更をアプリケーションに加えることができません。
改善/対応策
Momentum株式会社のモットーは自動化できないことは「しない」です。
また、度重なるエラーによる想定外の手運用の発生に嫌気がさした我々はなんとかこれを改善できないかと考えました。
これには以下の2点を実現する必要があります。
- Transformまでをアプリケーション上で完結させる
- BigQueryのスキーマをプログラマティックに管理する
Transformまでアプリケーション上で完結
まず、Transformまでをアプリケーション上で完結させるために、アプリケーションからJSONを直接を吐き出して、Cloud Storageに置くことを検討します。
幸いにも、nginx v1.13.10から新たにログファイルにデータを生のまま書き出せるようになりました。
The escape parameter (1.11.8) allows setting json or default characters escaping in variables, by default, default escaping is used. The none value (1.13.10) disables escaping.
log_format logdata escape=none "\t$upstream_http_x_log_data";
これにより、わざわざデータをJSONに変換していた部分が不要になり、ただのアップロード処理となりました。
また、アップロードされたファイルはこれまた新たに追加されたCloud Storage Transfers*を使用して適切なテーブルにインポートできます。
(*この機能はBeta版です)
想定される新たなシステム構成図は以下の通りです。
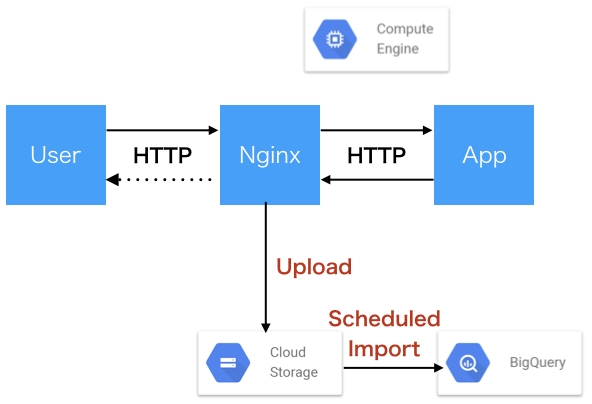
BigQueryのスキーマをプログラマティックに管理する
構成をシンプルにできたら、次にBigQueryのスキーマとプログラムの整合性を保つことを検討します。
これには二つの課題を考える必要があります。
- スキーマをアプリケーションから管理する。
- 異なるバージョンのスキーマ(テーブル)に適切にログをロードする。
アプリケーションでのスキーマの管理機能
スキーマを管理するため、以下のような機能をアプリケーションに実装しました。
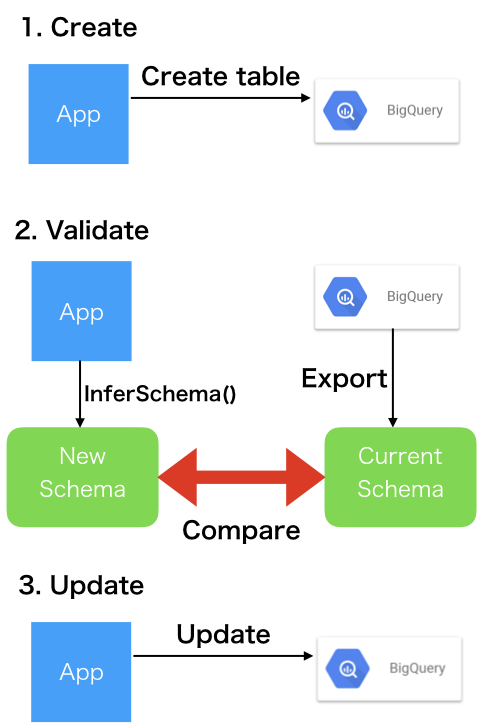
BigQueryに関する機能はほとんど公式のSDKで実現できます。
弊社ではGo言語を使用しており、ログデータはアプリケーションの構造体をMarshal( )することでjsonにできるのですが、この構造体をInferSchema( )することでスキーマを得ることが可能です。
しかしながら以下のようにjsonのキー名をカスタマイズしている場合は、少し事情が異なってきます。
type BidRequest struct {
MyNameIsTooLong string `json:"my_name"`
}
これをそのままInferSchemaに渡してしまうと、my_nameではなくMyNameIsTooLongという列が作成されてしまいます。公式の方法ではこれを防ぐために、bigqueryタグをしようします。
type BidRequest struct {
MyNameIsTooLong string `json:"my_name", bigquery:"my_name"`
}
この方法はかなり冗長であると感じます。そこで、jsonタグを読み込んで動的にbigqueryタグを作成することを検討します。自分でreflect職人になって頑張るのもいいのですが、ここでは便利なライブラリ "sevlyar/retag" を使用させていただきました
type BidRequest struct {
MyNameIsTooLong string `json:"my_name"`
}
func (br *BidRequest) MakeTag(t reflect.Type, fieldIndex int) reflect.StructTag {
field := t.Field(fieldIndex)
value = strings.Split(field.Tag.Get("json"), ",")[0]
if value == "" {
value = field.Name
}
tag := fmt.Sprintf(`%s:"%s"`, "bigquery", value)
return reflect.StructTag(tag)
}
なお、特筆すべきことがあまりないので、アプリケーションからテーブルを作成する方法などについては割愛させていただきます。
ログを分けて入れる方法
nginxでは変数(ヘッダー)を用いて動的に出力するログファイルを変更可能です。そのほかにもmapを使用する方法もありますが、こちらはnginxの設定ですので今回は割愛させていただきます。
まとめ
最終的にこれらを使用して、今までの問題点を改善するにはリリースフローにこれらを組み込む必要があります。
参考までに、弊社で考えているものを列挙します。
最終的な安全なリリースフロー
BigQueryテーブルスキーマの実際のバージョンは弊社ではGitのタグとして登録しているvX.Y.Zのメジャー(X)に一致させることとしました。Golangではプログラム内の変数にこれを埋め込むことが、以下のように ldflagsを指定することで可能です。
HASH=$(shell git describe --tags)
go build -ldflags "-X 'Version=$(HASH)'"
新しいテーブルを作る場合
新しいAPIなどを作成し、新規のテーブルが必要になった場合には、リリーススクリプトなどで作成した機能の一つである1.Createを呼び出します。
既存テーブルのテーブルを更新する場合
新しいAPIなどを作成し、新規のテーブルが必要になった場合には、リリーススクリプトなどで作成した機能の一つである3.Updateを呼び出します。互換性の無い変更を加えようとした場合には、Bigquery側でエラーとなります。
実際にアプリケーションをデプロイする
アプリケーションをデプロイする際には2.Validateが役に立ちます。
リリーススクリプトなどでValidateでスキーマに差分があった際に中止するなどの動作を定義できます。
この記事は2018年12月時点の情報に基づいて執筆しております。また、その正確性や面白みを保証するものではございませんのでご了承下さい。