概要
前回のブログ記事のテキスト版類似データ検索の実装例になります。 文章のベクトル化はこちらと同様にSentence-BERTを用います。類似度検索に関しては今回も近似最近傍探索ライブラリ Faissを使っていますが、全体については流行りに乗ってLangChainで構成してみました。加えて、Streamlitの代わりにGradioを使ってwebアプリを作ってみました。
今回はオープンな言語モデルを用いて小さなサービスを簡単に作る!を目標にしてみます。
LangChain
LangChainは大規模言語モデルを用いたサービスやアプリケーション開発に便利なフレームワークです。OpenAI-APIやローカルのオープンな言語モデル(LLM)と連動させたチャットシステムなど、事例を見かけたことがある方もいらっしゃるのではないでしょうか。個人的には、公式ドキュメントがきれいにまとまっていると思うので、Web検索してもいい感じの記事が見つからないときは公式ドキュメントを頼るとよいかなと思いました。
検証条件
- 環境、ライブラリ
- python 3.10.11
- langchain==0.0.305
- faiss-cpu==1.7.2
- fugashi==1.3.0
- ipadic==1.0.0
- datasets==2.14.5
- gradio==3.45.2
- sentence-transformers==2.2.2
- モデル
- Sentence-BERT : sonoisa/sentence-bert-base-ja-mean-tokens-v2
- データセット
- JGLUE - JSTS データセット
ベクトル情報の生成
早速作っていきます。最初に任意の入力テキストに対して、類似するテキストを検索するためのベクトル情報を生成します。今回はJGLUEのJSTSを活用します。JSTSの構成はこちらを参照ください。ベクトル化する対象カラム名は「sentence1」としました。テキストをベクトル化する際の言語モデルはSentence-BERTを用います。これらを全てLangChainベースで実装します。
from langchain.document_loaders import HuggingFaceDatasetLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import FAISS
from langchain.vectorstores.utils import DistanceStrategy
# Embedding用モデル
MODEL_NAME = 'sonoisa/sentence-bert-base-ja-mean-tokens-v2'
# ベクトル情報の保存先
SAVE_PATH = './output'
# データセット名
DATASET_NAME = "shunk031/JGLUE"
# カラム名
PAGE_CONTENT_COLUMN = "sentence1"
# サブセット名
SUBSET_NAME = "JSTS"
# Embeddingモデルのロード
embeddings_model = SentenceTransformerEmbeddings(model_name=MODEL_NAME)
# データセットのロード
loader = HuggingFaceDatasetLoader(path=DATASET_NAME,
page_content_column=PAGE_CONTENT_COLUMN,
name=SUBSET_NAME)
documents = loader.load()
# train:12451, valid:1457
# ベクトル情報の生成
vector_store = FAISS.from_documents(documents=documents[:12451],
embedding=embeddings_model,
distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT,
normalize_L2=True)
# ベクトル情報の保存
vector_store.save_local(folder_path=SAVE_PATH)
5つのメソッドを呼び出すだけでベクトル情報が出来てしまいました・・・
上のコードを実行するとカレントディレクトリにoutputフォルダが生成されて、その中にベクトル化した情報としてindex.faissとindex.pklが保存されます。類似度検索するアプリでは、これらをロードして検索します。
どんどんいきましょう。
ベクトル検索
ベクトル検索するための処理を実装します。
import os
from typing import List
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import FAISS
from langchain.vectorstores.utils import DistanceStrategy
from langchain.docstore.document import Document
class VectorAccessor():
def __init__(self, embeddinngs_model: str = '') -> None:
"""初期処理
Args:
embeddinngs_model (str, optional): embeddinngに用いるモデルが存在するフォルダパス. Defaults to ''.
"""
# embedding用モデルロード
self.embeddings_model = SentenceTransformerEmbeddings(model_name=embeddinngs_model)
self.vector_store = None
def load(self, path: str = '') -> bool:
"""ベクトル情報のロード
Args:
path (str, optional): ベクトル情報が存在するフォルダパス. Defaults to ''.
Returns:
bool: True(ベクトル情報のロード成功),False(ベクトル情報のロード失敗)
"""
result = False
# pathの存在確認
if os.path.exists(path) is True:
self.vector_store = FAISS.load_local(folder_path=path,
embeddings=self.embeddings_model,
distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT,
normalize_L2=True)
result = True
return result
def search(self, query: str = '', k: int = 5) -> List[Document]:
"""検索
Args:
query (str, optional): 入力テキスト. Defaults to ''.
k (int, optional): 類似度に関して上位k番目までの文章を返却する. Defaults to 5.
Returns:
List[Document]: 類似度に関して上位k番目までの文章
"""
# 類似度検索
docs = self.vector_store.similarity_search_with_score(query=query, k=k)
return docs
クラス化してみました。クラスインスタンスを生成したのち、loadメソッドで生成したベクトル情報の出力先(今回の場合、outputフォルダ)を指定してロードします。その後、searchメソッドで類似文書を検索します。searchメソッドではFAISSクラスのsimilarity_search_with_scoreメソッドを呼び出しています。これにより、戻り値に類似文書と、それに紐づく類似度が含まれます。
具体的には以下のような使い方になります。
from vector_accessor import VectorAccessor
# インスタンス生成
va = VectorAccessor(embeddinngs_model='sonoisa/sentence-bert-base-ja-mean-tokens-v2')
# ベクトル情報のロード
va.load(path='./output')
# 文章の類似度検索
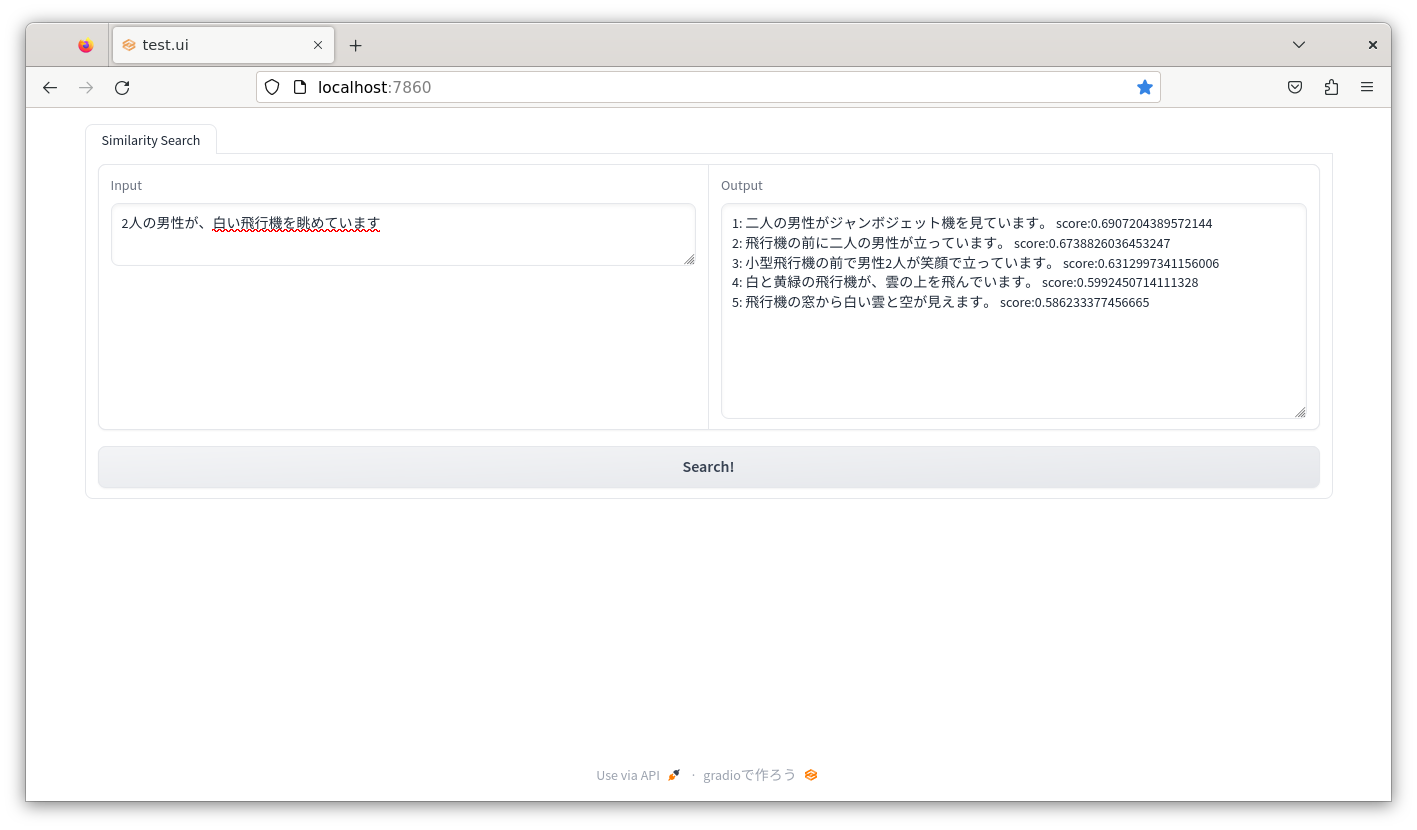
result = va.search(query='2人の男性が、白い飛行機を眺めています')
searchメソッドの戻り値はLangChainにて定義されているDocumentsクラスの配列です。Documentsクラスにはベクトル情報を生成した際のデータが含まれています。例えば、読み込むデータを工夫すればQAシステムっぽく作る事もできそうですね。
Webアプリ
最後にGradioでアプリ化します。
import gradio as gr
from vector_accessor import VectorAccessor
EMBEDDINGS_INDEX_PATH = './output'
EMBEDDINGS_MODEL = 'sonoisa/sentence-bert-base-ja-mean-tokens-v2'
# インスタンス生成
__lc_vector_store = VectorAccessor(embeddinngs_model=EMBEDDINGS_MODEL)
__lc_vector_store.load(path=EMBEDDINGS_INDEX_PATH)
# 類似度検索
def similarity_search(input_text):
output = []
result = __lc_vector_store.search(query=input_text)
for idx, value in enumerate(result):
output.append(f'{idx + 1}: {value[0].page_content} score:{value[1]}\n')
return ''.join(output)
# タブ型のUIを作る
with gr.Blocks(title="test.ui") as web_ui:
with gr.Tabs():
with gr.TabItem("Similarity Search"):
with gr.Row():
similarity_search_input = gr.Textbox(lines=2, label='Input')
similarity_search_output = gr.Textbox(lines=7, label='Output')
similarity_search_button = gr.Button("Search!")
# Button.clickイベントにメソッドを割り付ける
similarity_search_button.click(fn=similarity_search, inputs=similarity_search_input, outputs=similarity_search_output)
# アプリ実行
web_ui.launch(server_name="0.0.0.0")
# 任意のポート番号で実行したい場合は、以下のようにserver_portに設定
# web_ui.launch(server_name="0.0.0.0", server_port=12345)
アプリ起動
python3 demo.py
ブラウザを起動してhttp://localhost:7860にアクセスして検索を実行すると、このような感じになります。
おまけ
今回は公開されているデータセットを用いましたが、「いや、自分のデータでやりたいんだけど」という方もいらっしゃると思います。そのような場合のベクトル情報の作成コード例を示してみます。
今回は以下のようなCSV形式のデータを自作、使用しました。
question,answer,memo
りんごは果物ですか?,果物です。,「ふじ」などのブランドがあります。
「TTDC」は何の略ですか?,「トヨタテクニカルディベロップメント株式会社」の略称です。,本社は豊田市花本町です。
犬は動物ですか?,動物です。,トイプードルやマルチーズなど、多くの犬種が存在します。
以下がベクトル情報を生成するコードです。QAシステムを想定して、カラム名「question」を類似度検索対象にするため、CSVLoaderインスタンスを生成する際の引数「source_column」にて指定しました。これを指定しない場合は、CSVファイルから取得したデータ全てが検索対象になるようです。
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import FAISS
from langchain.vectorstores.utils import DistanceStrategy
# Embedding用モデル
MODEL_NAME = 'sonoisa/sentence-bert-base-ja-mean-tokens-v2'
# ベクトル情報の保存先
SAVE_PATH = './output'
# データファイルパス
USER_DATA_FILE_PATH='./user_data.csv'
# カラム名
SOURCE_COLUMN = "question"
# Embeddingmモデルのロード
embeddings_model = SentenceTransformerEmbeddings(model_name=MODEL_NAME)
# ----------------------------------------
# 任意のデータセットをロード
loader = CSVLoader(file_path=USER_DATA_FILE_PATH,
source_column=SOURCE_COLUMN)
# ----------------------------------------
documents = loader.load()
# ベクトル情報の生成
vector_store = FAISS.from_documents(documents=documents,
embedding=embeddings_model,
distance_strategy=DistanceStrategy.MAX_INNER_PRODUCT,
normalize_L2=True)
# ベクトル情報の保存
vector_store.save_local(folder_path=SAVE_PATH)
# 動作確認
query = 'TTDCって何?'
result = vector_store.similarity_search_with_score(query)
動作確認結果を見てみます。まずは類似度が最も高かった結果です。
print(result[0])
>>> (Document(page_content='question: 「TTDC」は何の略ですか?\nanswer: 「トヨタテクニカルディベロップメント株式会社」の略称です。\nmemo: 本社は豊田市花本町です。', metadata={'source': '「TTDC」は何の略ですか?', 'row': 1}), 0.63284177)
正しそうですね。page_contentのなかにCSVファイルから取得した情報があるので、そこだけ抜き出します。
print(result[0][0].page_content.split("\n"))
>>> ['question: 「TTDC」は何の略ですか?', 'answer: 「トヨタテクニカルディベロップメント株式会社」の略称です。', 'memo: 本社は豊田市花本町です。']
この中のanswerとmemoを組み合わせて回答したらQAシステムっぽくなりそうです。
さらに類似度を確認してみます。
print(result[0][1])
>>> 0.63284177
0.63ですので、まあまあと言ったところでしょうか。類似度を取得する事も出来たので、「検索結果に紐づく類似度が低すぎる場合は回答として扱わない」という振る舞いも実装できますね。
上記以外、検索用コードもアプリのコードもそのまま利用可能です。
最後まで読んでいただき、ありがとうございました!
今後も機械学習の活用を始め、開発環境やシミュレーションなど幅広く技術情報発信をしていく予定です!
最後になりますが、本記事の内容に誤りなどあれば、コメントにてご教授お願いいたします。