概要
BERT系のモデルを活用した文章のEmbedding取得について、検証を含めていくつかTipsを紹介します。
- Paddingの最適化
- tokenの平均化
- Embeddingを取得するLayer
- 上記Tipsを複合した文章Embedding取得classの実装
はじめに
近年は、ChatGPTを始めとしたLLM活用が話題となっています(言語処理と言えば初手LLM(GPT系)の雰囲気も一部感じております)。対話型ChatBotにおいてはGPT系の生成AIが一線を画していますが、文章のEmbedding取得では旧来のBERT系のモデルが優れている例も報告されています。
今回、社内で簡単な情報検索システムを構築する機会があり、
- 社内情報(機密情報含む)を参照したいため、まずはオンプレ環境でトライしたい
- ChatBotというより情報検索システムの立ち位置であり、応答文はテンプレで良し
- 簡単な問い合わせ文のため文章が短い≒token数少なくてOK
などを勘案し、Sentence-BERTを活用することにしました。
その際に得たTipsを紹介します。
検証条件
-
環境
- GPU : NVIDIA A6000 x 1
- CUDA : 11.7
- python : 3.10.11
- torch : 2.0.0
- transformers : 4.31.0
-
モデル
- Sentence-BERT : sonoisa/sentence-bert-base-ja-mean-tokens-v2
- BERT (検証用) : cl-tohoku/bert-base-japanese-whole-word-masking (上記Sentence-BERTのベースモデル)
-
データセット
- JGLUE - JSTS データセット
Paddingの最適化
Paddingとは
Transformersで文章をEmbeddingする際、まず初めに文章をTokenizerにてtoken単位に分割します。そのままでは文章の長さに応じてtoken数が異なるため、モデル入力時にはbatch単位でtoken数を揃える必要があります。
この際に、調整分で追加されるtokenがpaddingです。(下図の黄色部)

引用元:Speeding up Transformer w/ Optimization Strategies
padding自体はEmbeddingに寄与せず、モデルの内部計算ではattention maskで0を乗算し無視する形になりますが、メモリ転送や演算は発生するためpadding数(token数)は処理時間に影響します。
そのため、padding数を最適化することが推論処理の高速化につながります。
paddingは、Transformers tokenizerの padding 引数で設定が可能です。
-
max_length: max_length引数で指定された長さ、またはmax_lengthが指定されない場合はモデルが受け付ける最大長にpadding -
trueまたはlongest:batch内で最も長い配列(token数)にpadding
参考:Hugging Face - Transformers - Padding and truncation
上記のFixed Paddingが max_length 時の処理になります。
padding引数をtrueまたはlongestに設定することで、下図のようにpaddingを削減できます(Dynamic Padding)。
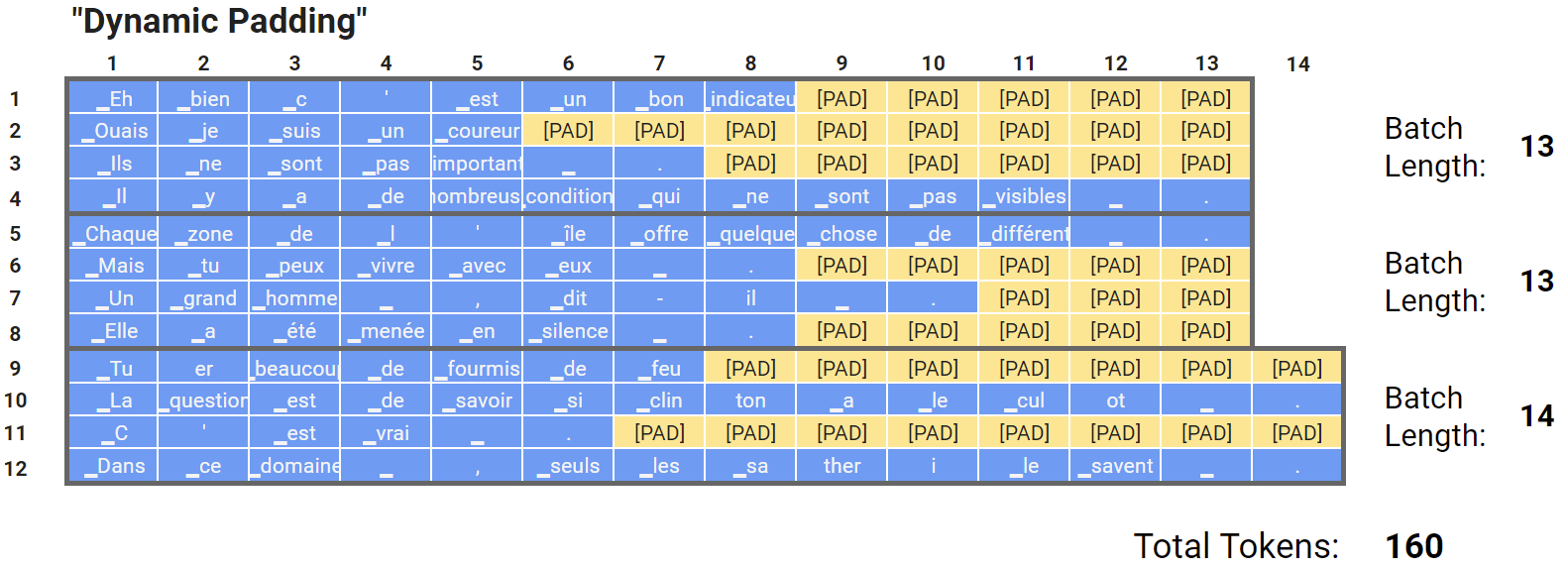
引用元:Speeding up Transformer w/ Optimization Strategies
Dynamic Paddingにてpaddingを削減できますが、batch内で最大のtoken数までpaddingするため、token数にばらつきがある場合は余分なpaddingが発生してしまいます。
文章を事前にtoken数(≒文字数)で並び替えておくことでbatch内のtoken数を均一化し、更にpaddingの削減を図ります(Uniform Length Batching)。
文字数による文章の並び替えはSentence-Transformersライブラリでも実装されている手法です。(実装例:Sentence-Transformers)
※モデルを学習する際は、文章の並び替えでデータ分布に偏りが生じるため注意が必要ですが、今回のように推論するだけであればEmbedding取得に限らず処理時間の短縮が期待できます。

引用元:Speeding up Transformer w/ Optimization Strategies
各paddingの推論時間を比較してみます。
初めに、JSTSデータセットの性質を確認します。
# import
import os
import time
import statistics
from typing import List
from tqdm.autonotebook import trange
import torch
import numpy as np
import matplotlib.pyplot as plt
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel, AutoConfig
# データセット取得
dataset = load_dataset(
"shunk031/JGLUE",
"JSTS",
)
sentences = [d['sentence1'] for d in dataset['train']]
# サンプル数、文字数確認
sentence_length = [len(s) for s in sentences]
print(f'sample num = {len(sentence_length)}')
plt.boxplot(sentence_length)
plt.title('sentence length')
plt.xticks([])
plt.show()
>>> sample num = 12451

JSTSデータセット文章の文字数は、20字前後が多いようです。
次に、各padding手法を実装し、文章Embedding処理 5回分の平均処理時間を比較します。
# 推論関連の設定
DEVICE = 'cuda'
BATCH_SIZE = 32
MODEL_NAME = 'sonoisa/sentence-bert-base-ja-mean-tokens-v2'
# tokenizer, modelの読込
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModel.from_pretrained(
MODEL_NAME,
return_dict=True
)
model.eval()
model.to(DEVICE)
# ベンチマーク用の関数定義
def embedding_benchmark(
sentences: List[str],
padding: str,
do_sort: bool
):
all_embeddings = []
if do_sort:
length_sorted_idx = np.argsort([-len(str(sen)) for sen in sentences])
sentences = [sentences[idx] for idx in length_sorted_idx]
for start_index in trange(
0, len(sentences), BATCH_SIZE, desc="Batches"
):
batch = sentences[start_index : start_index + BATCH_SIZE]
features = tokenizer.batch_encode_plus(
batch, padding=padding, truncation=True, return_tensors="pt"
).to(DEVICE)
with torch.no_grad():
output = model(**features)['last_hidden_state']
output = output[:, 0, :] # [CLS]token
output = output.cpu()
all_embeddings.extend(output)
if do_sort:
all_embeddings = [all_embeddings[idx] for idx in np.argsort(length_sorted_idx)]
all_embeddings = torch.stack(all_embeddings, dim=0)
return all_embeddings
# 文章Embedding処理を5回実施し、処理時間の平均と標準偏差を算出
def get_execution_time(
sentences: List[str],
padding: str,
do_sort: bool,
num_runs: int= 5
):
execution_times = []
for _ in range(num_runs):
start_time = time.time()
_ = embedding_benchmark(sentences, padding, do_sort)
end_time = time.time()
execution_time = end_time - start_time
execution_times.append(execution_time)
avg_time = statistics.mean(execution_times)
stdev_time = statistics.stdev(execution_times)
print(f"平均時間: {avg_time:.3f} 秒 ± {stdev_time:.3f} 秒")
# 処理時間比較
# padding='max_length', 文字数sort無し(Fixed Padding)
get_execution_time(sentences, 'max_length', False)
# padding='longest', 文字数sort無し(Dynamic Padding)
get_execution_time(sentences, 'longest', False)
# padding='longest', 文字数sort有り(Uniform Length Batching)
get_execution_time(sentences, 'longest', True)
| Padding, Batching | 推論時間[sec] | vs Fixed Padding | vs Dynamic Padding |
|---|---|---|---|
| Fixed Padding | 103.717 | x 1.000 | - |
| Dynamic Padding | 7.889 | x 13.147 | x 1.000 |
| Uniform Length Batching | 7.153 | x 14.500 | x 1.103 |
Fixed Padding -> Dynamic Padding で 約13倍、
更にUniform Length Batchingにより 約1.1倍 処理時間を短縮できました。
Tokenの平均化
BERTには文章の全体情報を集約する [CLS]token がありますが、Sentence-BERTの論文では全tokenの平均値・最大値の使用が提案されています。
参考:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
全tokenの平均値を集約する際は、padding tokenに注意する必要があります。
padding tokenはEmbedding性能に寄与しないため、単純に全tokenを平均化するとpadding分のノイズが含まれてしまいます。
そこで、attention maskを用いることで有意なtokenのみ集約できます。
features = tokenizer.batch_encode_plus(
batch, padding="longest", truncation=True, return_tensors="pt"
)
output = model(**features)
output = output["last_hidden_state"]
# [CLS] tokenの場合
output = output[:, 0, :]
# token平均値の場合
att_mask = features["attention_mask"]
att_mask = att_mask.unsqueeze(-1)
output = (output * att_mask).sum(dim=1) / att_mask.sum(dim=1)
JSTSのValidationデータセットでEmbedding性能を比較してみます。
sentence1、sentence2それぞれのEmbedding結果についてcosine類似度を算出し、labelとの pearson, spearman相関係数を算出します。
# import
from scipy.spatial.distance import cosine
from scipy.stats import pearsonr, spearmanr
# データセット用意
val_sentence_1 = [d['sentence1'] for d in dataset['validation']]
val_sentence_2 = [d['sentence2'] for d in dataset['validation']]
label = dataset['validation']['label']
# Embedding取得用関数
def get_embeddings(
model: AutoModel,
tokenizer: AutoTokenizer,
sentences: List[str],
use_token_mean: bool,
):
all_embeddings = []
length_sorted_idx = np.argsort([-len(str(sen)) for sen in sentences])
sentences_sorted = [sentences[idx] for idx in length_sorted_idx]
for start_index in trange(
0, len(sentences), BATCH_SIZE, desc="Batches"
):
batch = sentences_sorted[start_index : start_index + BATCH_SIZE]
features = tokenizer.batch_encode_plus(
batch, padding='longest', truncation=True, return_tensors="pt"
).to(DEVICE)
with torch.no_grad():
output = model(**features)
output = output["last_hidden_state"]
if use_token_mean:
att_mask = features["attention_mask"]
att_mask = att_mask.unsqueeze(-1)
output = (output * att_mask).sum(dim=1) / att_mask.sum(dim=1)
else:
output = output[:, 0, :] # get [CLS] token
output = output.cpu()
all_embeddings.extend(output)
all_embeddings = [all_embeddings[idx] for idx in np.argsort(length_sorted_idx)]
all_embeddings = torch.stack(all_embeddings, dim=0)
all_embeddings = all_embeddings.numpy()
return all_embeddings
# JSTSスコア算出関数
def get_jsts_score(
model_name: str,
use_token_mean: bool,
):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(
model_name,
return_dict=True,
output_hidden_states=True,
)
model.eval()
model.to(DEVICE)
# Embedding取得
embs_1 = get_embeddings(model, tokenizer, val_sentence_1, use_token_mean=use_token_mean)
embs_2 = get_embeddings(model, tokenizer, val_sentence_2, use_token_mean=use_token_mean)
# cosine類似度算出
embs_cosine = [1-cosine(s1, s2) for s1, s2 in zip(embs_1, embs_2)]
# pearson, spearman相関係数算出
socre_pearson = pearsonr(embs_cosine, label)[0]
socre_spearman = spearmanr(embs_cosine, label)[0]
print(f'pearson = {socre_pearson:.3f}, spearman = {socre_spearman:.3f}')
sonoisa/sentence-bert-base-ja-mean-tokens-v2 のベースとなっている、cl-tohoku/bert-base-japanese-whole-word-masking のBERTで検証します。
# BERT ([CLS]token)
get_jsts_score(
'cl-tohoku/bert-base-japanese-whole-word-masking',
use_token_mean=False
)
# BERT(token平均値)
get_jsts_score(
'cl-tohoku/bert-base-japanese-whole-word-masking',
use_token_mean=True
)
| Model | JSTS (Peason) | JSTS (Spearman) |
|---|---|---|
| cl-tohoku/bert-base-japanese-whole-word-masking ([CLS]token) | 0.566 | 0.570 |
| cl-tohoku/bert-base-japanese-whole-word-masking (token平均値) | 0.687 | 0.674 |
今回の検証では、[CLS]token に比べ token平均値 が優位な結果となりました。
Embeddingを取得するLayer
BERTは、MLM(Masked Language Model : 単語の穴埋め)などの事前学習タスクにより優れた特徴抽出性能を獲得しています。
そのためFine-tuningをしていない場合、モデル最終層は他層に比べ事前学習タスク寄りの性能になる可能性があり、最終層から2番目の層(Second-to-Last)が特徴抽出に適している例も示されています。
参考:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - Table7 など
一方、Sentence-BERTは文章のEmbedding取得に特化したFine-tuningを実施しているため、最終層をそのまま使用します。
こちらも上記同様に、JSTSのValidationデータセットでEmbedding性能を比較してみます。
# Embedding取得用関数
def get_embeddings(
model: AutoModel,
tokenizer: AutoTokenizer,
sentences: List[str],
use_last_layer: bool,
):
all_embeddings = []
length_sorted_idx = np.argsort([-len(str(sen)) for sen in sentences])
sentences_sorted = [sentences[idx] for idx in length_sorted_idx]
for start_index in trange(
0, len(sentences), BATCH_SIZE, desc="Batches"
):
batch = sentences_sorted[start_index : start_index + BATCH_SIZE]
features = tokenizer.batch_encode_plus(
batch, padding='longest', truncation=True, return_tensors="pt"
).to(DEVICE)
with torch.no_grad():
output = model(**features)
if use_last_layer:
output = output["last_hidden_state"]
else:
output = output["hidden_states"][-2]
att_mask = features["attention_mask"]
att_mask = att_mask.unsqueeze(-1)
output = (output * att_mask).sum(dim=1) / att_mask.sum(dim=1)
output = output.cpu()
all_embeddings.extend(output)
all_embeddings = [all_embeddings[idx] for idx in np.argsort(length_sorted_idx)]
all_embeddings = torch.stack(all_embeddings, dim=0)
all_embeddings = all_embeddings.numpy()
return all_embeddings
# JSTSスコア算出関数
def get_jsts_score(
model_name: str,
use_last_layer: bool,
):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(
model_name,
return_dict=True,
output_hidden_states=True,
)
model.eval()
model.to(DEVICE)
embs_1 = get_embeddings(model, tokenizer, val_sentence_1, use_last_layer=use_last_layer)
embs_2 = get_embeddings(model, tokenizer, val_sentence_2, use_last_layer=use_last_layer)
embs_cosine = [1-cosine(s1, s2) for s1, s2 in zip(embs_1, embs_2)]
socre_pearson = pearsonr(embs_cosine, label)[0]
socre_spearman = spearmanr(embs_cosine, label)[0]
print(f'pearson = {socre_pearson:.3f}, spearman = {socre_spearman:.3f}')
# Sentence-BERT (最終層からEmbedding取得)
get_jsts_score(
'sonoisa/sentence-bert-base-ja-mean-tokens-v2',
use_last_layer=True
)
# BERT (最終層からEmbedding取得)
get_jsts_score(
'cl-tohoku/bert-base-japanese-whole-word-masking',
use_last_layer=True
)
# BERT(最終層から2番目の層からEmbedding取得)
get_jsts_score(
'cl-tohoku/bert-base-japanese-whole-word-masking',
use_last_layer=False
)
| Model | JSTS (Peason) | JSTS (Spearman) |
|---|---|---|
| sonoisa/sentence-bert-base-ja-mean-tokens-v2 | 0.861 | 0.809 |
| cl-tohoku/bert-base-japanese-whole-word-masking (最終層) | 0.687 | 0.674 |
| cl-tohoku/bert-base-japanese-whole-word-masking (最終層から2番目の層) | 0.653 | 0.653 |
今回の検証では、文章のEmbeddingは最終層から取得する方が優位な結果となりました。
文章Embeddingに特化したFine-tuningを実施していることで、Sentence-BERTのスコアに大きな改善も見られます。
Tipsを複合した文章Embedding取得Class
今回検証した結果を踏まえ社内トライ用に実装した、文章Embeddingを取得するClassです。
Sentence-BERTの利用だけであればSentence-Transformersライブラリで良いですが、ドメインに特化したBERTモデルなどの使用も想定しBERT・Sentence-BERTの両方に対応させています。
from typing import Optional, Union, List
from tqdm.autonotebook import trange
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModel, AutoConfig
class SentenceEmbedding:
"""
Huggingface Transformersモデルで文章をベクトル化
"""
def __init__(self, model_name_or_path: str, device: Optional[str] = None):
"""コンストラクタ
Args:
model_name_or_path (str):
Transformersモデルパス。
ディスク上のファイルパスであれば、そのパスからモデルをロード.
異なる場合、Huggingfaceのモデルリポジトリからモデルをダウンロード.
device (Optional[str], optional):
モデル推論に使用するデバイス情報 ('cuda', 'cpu'など).
Noneの場合、GPUが使用可能かどうかをチェックし自動で割り当て.
Defaults to None.
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
self.model = AutoModel.from_pretrained(
model_name_or_path,
return_dict=True,
output_hidden_states=True,
)
self.model.eval()
self.config = AutoConfig.from_pretrained(model_name_or_path)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.model.to(self.device)
def encode(
self,
sentences: Union[List[str], str],
batch_size: Optional[int] = 32,
use_last_layer: Optional[bool] = True,
use_token_mean: Optional[bool] = True,
return_numpy: Optional[bool] = True,
normalize_embeddings: Optional[bool] = False,
show_progress_bar: Optional[bool] = False,
) -> Union[np.ndarray, torch.Tensor]:
"""Transformersモデルで文章をベクトル化
Args:
sentences (Union[List[str], str]):
ベクトル化する文章.
batch_size (int, optional):
Batchサイズ. Defaults to 32.
use_last_layer (bool, optional):
ベクトルを取得する層を、`最終層` or `最後から2番目の層` か指定.
Trueの場合:最終層、Falseの場合:最後から2番目の層を使用.
Defaults to True.
use_token_mean (bool, optional):
文章ベクトルを`全tokenの平均` or `[CLS] token` か指定.
Trueの場合:全tokenの平均、Falseの場合:[CLS] token を使用.
Defaults to True.
return_numpy (bool, optional):
returnのtypeを'numpy' or 'torch.Tensor'か指定.
Trueの場合:numpy、Falseの場合:torch.Tensor をreturn.
Defaults to True.
normalize_embeddings (bool, optional):
ベクトルをnormalize(標準化)するか指定.
Trueの場合:normalizeあり、Falseの場合:normalizeなし.
Defaults to False.
show_progress_bar (bool, optional):
ベクトル化の進捗状況をプログレスバーで表示するか指定.
Trueの場合:表示あり、Falseの場合:表示なし.
Defaults to False.
Returns:
Union[np.ndarray, torch.Tensor]: 各文章のベクトル情報
"""
all_embeddings = []
if isinstance(sentences, str):
sentences = [sentences]
length_sorted_idx = np.argsort([-len(str(sen)) for sen in sentences])
sentences_sorted = [sentences[idx] for idx in length_sorted_idx]
for start_index in trange(
0, len(sentences), batch_size, desc="Batches", disable=not show_progress_bar
):
batch = sentences_sorted[start_index : start_index + batch_size]
features = self.tokenizer.batch_encode_plus(
batch, padding="longest", truncation=True, return_tensors="pt"
).to(self.device)
with torch.no_grad():
output = self.model(**features)
if use_last_layer:
output = output["last_hidden_state"]
else:
output = output["hidden_states"][-2]
if use_token_mean:
att_mask = features["attention_mask"]
att_mask = att_mask.unsqueeze(-1)
output = (output * att_mask).sum(dim=1) / att_mask.sum(dim=1)
else:
output = output[:, 0, :] # get [CLS] token
if normalize_embeddings:
output = torch.nn.functional.normalize(output, p=2, dim=1)
output = output.cpu()
all_embeddings.extend(output)
all_embeddings = [all_embeddings[idx] for idx in np.argsort(length_sorted_idx)]
all_embeddings = torch.stack(all_embeddings, dim=0)
if return_numpy:
all_embeddings = all_embeddings.numpy()
return all_embeddings
使用例
model = SentenceEmbedding('sonoisa/sentence-bert-base-ja-mean-tokens-v2')
embeddings = model.encode(sentences)
最後まで読んでいただき、ありがとうございました!
今後は機械学習の活用を始め、開発環境やシミュレーションなど幅広く技術情報発信をしていく予定です!
最後になりますが、本記事の内容に誤りなどあれば、コメントにてご教授お願いいたします。
Reference
- SGPT: GPT Sentence Embeddings for Semantic Search
- ChatGPT vs BERT:どちらが日本語をより理解できるのか?
- sonoisa/sentence-bert-base-ja-mean-tokens-v2
- cl-tohoku/bert-base-japanese-whole-word-masking
- JGLUE: Japanese General Language Understanding Evaluation
- Speeding up Transformer w/ Optimization Strategies
- Hugging Face - Transformers - Padding and truncation
- Sentence-Transformers
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding