前回は、MacBook Pro上でPyTorchに含まれている(torchvisionに含まれている)モデルを実行できることを確認しました。今回はGitHubで配布されているモデルでも、MacBook ProのMPS(Metal Perfomance Shaders)を使えることを確認してみました。
事前準備
下記の記事を事前に実施し、MacBook Pro上でPyTorchが動くことを確認しておきましょう。
YOLOv9を導入する
今回は、画像中の物体を高速かつ高精度に検出するためのアルゴリズムであるYOLOを実行してみます。バージョンは2024年11月現在最新となるYOLOv9(PyTorch上に実装されている)を利用しました。導入、推論、学習、学習結果を利用した顔検出を試してみました。今回の手順におけるMacBook Pro固有の部分は--device mpsの指定ぐらいですので、Ubuntu + CUDAの環境でも--device 0を指定(GPU番号を指定)すれば、ほぼ同じ手順で実行できるかと思います (学習時に少し落とし穴あり、記事の最後に詳細を追記しました)。
参考記事
YOLOv9の導入は、下記記事を参考にしました。
全体の流れ
PyTorch上で実行されるYOLOv9のモデルはGitHub上で配布されています。gitコマンドを利用してローカルにダウンロードしましょう。ダウンロード後 requirements.txt に指定されたパッケージを pipコマンドでインストールしてください。推論に使う学習済みパラメータはwget https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.ptによりダウンロードできます (スクリプトの不具合によりutils/general.pyを一部書き換える必要があります)。最後にdetect.pyを実行することによりYOLOv9による物体検出を行えます。コマンド実行時に --deviceを指定することで推論をCPU上で行うか、ハードウェアアクセラレータ上で行うかを選択することができます。本例では推論にMacBook ProのMPSをハードウェアリソースとして利用しています(--device mps)。
# 作業ディレクトリを作成
(base) $ pwd
/Users/shino
(base) $ mkdir -p ./yolov9
(base) $ cd ./yolov9
# GitHubより入手する
(base) $ git clone https://github.com/WongKinYiu/yolov9.git
(base) $ cd yolov9
(base) $ pwd
/Users/shino/yolov9/yolov9
# 仮想環境を作成する
(base) $ conda create --prefix ./env python=3.8
(base) $ conda activate ./env
(env) $ pip install -r requirements.txt
(env) $ pip install Pillow==9.5.0
## -->> https://github.com/tensorflow/models/issues/11040
# 推論に使う学習済みの重みをダウンロードする
(env) $ mkdir -p weights
(env) $ wget -P weights https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
# スクリプトの不具合を修正する
(env) $ vi utils/general.py
####
# 903行目を下記に変更
####
prediction = prediction[0][0] # select only inference output
####
# 変更して保存する
####
# 一旦推論ができるかを確認する
(env) $ python detect.py --weights weights/yolov9-c.pt --conf 0.1 --source data/images/horses.jpg --device mps
# ...
# Speed: 80.6ms pre-process, 647.3ms inference, 7.7ms NMS per image at shape (1, 3, 640, 640)
# Results saved to runs/detect/exp5
(env) $ open runs/detect/exp5/horses.jpg
# 推論ができていればバウンディングボックス付きの画像が表示される
# 終了後に仮想環境から抜けておく
(env) $ conda deactivate
(base) $

顔を検出するための学習データを準備する
続いて、YOLOv9の学習を試してみましょう。今回は、顔検出器を作るため、学習データとして顔画像データセットのWIDER FACEを使います。Google Driveからダウンロードし、アノテーションデータをYOLOv9対応の形式に変換、学習データセットディレクトリにまとめます(YOLOv9の学習で、このディレクトリにアクセスします)。
学習データ「WIDER FACE」をダウンロードする
WIDER FACEは大量の画像と、その画像内の顔位置をアノテーションデータとして含むデータセットです。WIDER Face Training Images [Google Drive]、WIDER Face Validation Images [Google Drive]から画像を、Face annotationsからアノテーションデータを入手できます。それぞれダウンロードしてunzipしておきましょう。また、推論のテストに使う画像としてWIDER Face Testing Images [Google Drive]もダウンロードしておきます。本例ではダウンロードしたファイルを/Users/shino/widerface_dataset に格納しています。

# Google Driveからダウンロードしたデータ
(base) $ pwd
/Users/shino/widerface_dataset
(base) $ ls
WIDER_val.zip WIDER_train.zip WIDER_test.zip wider_face_split.zip
# それぞれ解凍します
(base) $ unzip WIDER_train.zip
(base) $ unzip WIDER_val.zip
(base) $ unzip WIDER_test.zip
(base) $ unzip wider_face_split.zip
# アノテーションデータを画像データとセットにしておきます
(base) $ cp wider_face_split/wider_face_train_bbx_gt.txt WIDER_train/images/original_labels.txt
(base) $ cp wider_face_split/wider_face_val_bbx_gt.txt WIDER_val/images/original_labels.txt
# 不要になったzipファイルは削除しておきます
(base) $ rm ./*.zip
アノテーションデータをYOLO向けに変換する
WIDER FACEのアノテーションデータは、データセット毎(train, val)で1ファイルにまとめられており、ファイルには画像ファイルへのパス名と、その画像に含まれている顔の数、続けて顔のあるバウンディングボックス(ピクセル単位)が列挙されています。 注意:バウンディングボックスが含まれていない画像の場合は、顔の数が0となっていますが、直後の座標情報にダミーデータとしてオールゼロが格納されています(バウンディングボックスの行がないわけではない)
(base) $ cd WIDER_train/images
(base) $ head -n 20 original_labels.txt
0--Parade/0_Parade_marchingband_1_849.jpg
1
449 330 122 149 0 0 0 0 0 0
0--Parade/0_Parade_Parade_0_904.jpg
1
361 98 263 339 0 0 0 0 0 0
0--Parade/0_Parade_marchingband_1_799.jpg
21
78 221 7 8 2 0 0 0 0 0
78 238 14 17 2 0 0 0 0 0
113 212 11 15 2 0 0 0 0 0
134 260 15 15 2 0 0 0 0 0
163 250 14 17 2 0 0 0 0 0
201 218 10 12 2 0 0 0 0 0
182 266 15 17 2 0 0 0 0 0
245 279 18 15 2 0 0 0 0 0
304 265 16 17 2 0 0 0 2 1
328 295 16 20 2 0 0 0 0 0
389 281 17 19 2 0 0 0 2 0
406 293 21 21 2 0 1 0 0 0
YOLOv9の学習には、アノテーションデータとして画像ファイル.jpg毎に、画像ファイルと同名の.txtファイルが必要で、各ファイルには 「ピクセル単位でなく縦横を1とした場合の比率座標」 が含まれている必要があります。そのため、WIDER FACEの配布しているアノテーションデータを、YOLOv9向けに書き換える必要があります。
# YOLOv9に対応したアノテーションデータは下記のような構成になる
# 作成方法は後述(ここではまず、作るべきデータとして紹介しておきます)
(base) $ cd WIDER_train/images/6--Funeral
(base) $ ls 6_Funeral_Funeral_6_95.*
6_Funeral_Funeral_6_95.jpg 6_Funeral_Funeral_6_95.txt
(base) $ cat 6_Funeral_Funeral_6_95.txt
0 0.15576171875 0.4322916666666667 0.0126953125 0.04861111111111111
0 0.50537109375 0.4140625 0.0166015625 0.050347222222222224
0 0.53759765625 0.421875 0.0185546875 0.04861111111111111
0 0.59912109375 0.4427083333333333 0.0185546875 0.052083333333333336
0 0.64111328125 0.4574652777777778 0.0224609375 0.022569444444444444
0 0.71923828125 0.4105902777777778 0.0185546875 0.050347222222222224
0 0.7490234375 0.4045138888888889 0.017578125 0.05555555555555555
アノテーションデータの変換スクリプトを実装する
下記のスクリプトにより、先の手順でデータセットと組みにしたアノテーションデータoriginal_labels.txtに基づき、データセットの各*.jpgに対応する座標データ*.txtを生成します。ピクセル単位でなく縦横を1とした比率座標のアノテーションデータを得るために、OpenCVを使って各画像を開き、画像の縦横ピクセル数を取得します。
参考記事
変換するプログラムは、下記の記事のものを利用させていただきました。本記事ではダミーデータの読み飛ばし対策のみ追加しています。
import os
import cv2
import math
import random
txt_file = 'original_labels.txt'
with open(txt_file) as f:
num = f.read().count('jpg')
print('number of images:',num)
def generator():
with open(txt_file) as f:
img_paths=[]
for i in range(num):
# 両端の空白や改行を除去して1行ずつ読み込む
img_path=f.readline().strip()
# 画像パス一覧取得
img_paths.append(img_path)
# 画像を読み込み幅・高さ取得
im = cv2.imread(img_path)
im_h=im.shape[0]
im_w=im.shape[1]
# '/'で分割
split=img_path.split('/')
# Annotationファイルを格納するディレクトリ取得
dir_name=split[0]
# Annotationファイル名作成
file_name=split[1].replace('.jpg', '.txt')
# ボックス数取得
count = int(f.readline())
# ボックスが0の場合はダミーデータが1個入っている
if count == 0:
count = 1
readline=[]
readlines=[]
for j in range(count):
readline=f.readline().split()
# ボックスの左上座標を取得
xmin=int(readline[0])
ymin=int(readline[1])
# ボックスの幅・高さを取得
w=int(readline[2])
h=int(readline[3])
# ボックスの中央座標(相対値)を作成
xcenter=str((xmin+w/2)/im_w)
ycenter=str((ymin+h/2)/im_h)
# ボックスの幅・高さを相対値に変換
w=str(w/im_w)
h=str(h/im_h)
class_num='0'
# クラス x座標 y座標 ボックス幅 ボックス高さを半角スペースで結合
string=' '.join([class_num, xcenter, ycenter, w, h])
readlines.append(string)
# 改行で結合
readlines_str='\n'.join(readlines)
# 該当するディレクトリ内にAnnotationファイルを保存
with open(dir_name+'/'+file_name, 'w') as j:
j.write(readlines_str)
# 画像パス一覧を出力
return img_paths
img_paths = generator()
print(img_paths)
アノテーションデータを変換する
前述のスクリプトを/Users/shino/widerface_dataset/genetator.pyとして保存し、次の手順で、スクリプトを実行します。
(bash) $ pwd
/Users/shino/widerface_dataset
(bash) $ cd WIDER_train/images
# trainデータの格納場所
(base) $ pwd
/Users/shino/widerface_dataset/WIDER_train/images
# アノテーションデータをoriginal_labels.txtとして格納しておく
(base) $ ls
...
34--Baseball 8--Election_Campain
35--Basketball 9--Press_Conference
36--Football original_labels.txt
# アノテーションデータの内容を確認する
(base) $ head -n 10 original_labels.txt
0--Parade/0_Parade_marchingband_1_849.jpg
1
449 330 122 149 0 0 0 0 0 0
0--Parade/0_Parade_Parade_0_904.jpg
1
361 98 263 339 0 0 0 0 0 0
0--Parade/0_Parade_marchingband_1_799.jpg
21
78 221 7 8 2 0 0 0 0 0
78 238 14 17 2 0 0 0 0 0
# 仮想環境を作成する
(base) $ conda create --prefix ./env python=3.8
(base) $ conda activate ./env
# OpenCVをインストールする
(env) $ pip install opencv-python
# 変換スクリプトを実行する
(env) $ python /Users/shino/widerface_dataset/genetator.py
# lsでアノテーションデータが作成できていることを確認する
(env) ls 0--Parade/0_Parade_Parade_0_21.*
0--Parade/0_Parade_Parade_0_21.jpg 0--Parade/0_Parade_Parade_0_21.txt
# 生成されたアノテーションデータを確認する
(env) head -n 5 0--Parade/0_Parade_Parade_0_21.txt
0 0.64990234375 0.4136163982430454 0.0146484375 0.027818448023426062
0 0.52783203125 0.38726207906295756 0.0166015625 0.03074670571010249
0 0.3525390625 0.3967789165446559 0.03125 0.05856515373352855
0 0.4091796875 0.42752562225475843 0.0234375 0.040995607613469986
0 0.2744140625 0.4136163982430454 0.037109375 0.06588579795021962
# valデータも変換する
(env) $ cd ../../WIDER_val/images
(env) $ pwd
/Users/shino/widerface_dataset/WIDER_val/images
# 変換スクリプトを実行する
(env) $ python /Users/shino/widerface_dataset/genetator.py
# lsでアノテーションデータが作成できていることを確認する
(env) $ ls 0--Parade/0_Parade_marchingband_1_910.*
0--Parade/0_Parade_marchingband_1_910.jpg
0--Parade/0_Parade_marchingband_1_910.txt
# 生成されたアノテーションデータを確認する
(env) $ head -n 5 0--Parade/0_Parade_marchingband_1_910.txt
0 0.0546875 0.3235677083333333 0.03515625 0.04296875
0 0.091796875 0.3424479166666667 0.0390625 0.041666666666666664
0 0.1513671875 0.3203125 0.033203125 0.044270833333333336
0 0.22314453125 0.3046875 0.0458984375 0.0546875
0 0.2939453125 0.3619791666666667 0.037109375 0.0390625
# 仮想環境から抜ける
(env) $ conda deactivate
(base) $
アノテーションデータのファイルをまとめる
YOLOv9の学習には、画像のみを格納したimagesディレクトリと、各画像ファイルに対応したアノテーションデータを格納したlabelsディレクトリが必要になります。上記の変換スクリプトの結果は画像とアノテーションデータ同じディレクトリに混在する形となっておりますので、次のスクリプトでYOLOv9向けのディレクトリ構造に変換します。
import os
import re
import shutil
work_dir = '/Users/shino/widerface_dataset'
orig_train_dir = 'WIDER_train/images'
orig_val_dir = 'WIDER_val/images'
dest_train_dir = 'data/yolov9/train'
dest_val_dir = 'data/yolov9/val'
orig_train_dir = os.path.join(work_dir, orig_train_dir)
orig_val_dir = os.path.join(work_dir, orig_val_dir)
dest_train_dir = os.path.join(work_dir, dest_train_dir)
dest_val_dir = os.path.join(work_dir, dest_val_dir)
dest_train_images = os.path.join(dest_train_dir, 'images')
dest_train_labels = os.path.join(dest_train_dir, 'labels')
dest_val_images = os.path.join(dest_val_dir, 'images')
dest_val_labels = os.path.join(dest_val_dir, 'labels')
os.makedirs(dest_train_images, exist_ok=True)
os.makedirs(dest_train_labels, exist_ok=True)
os.makedirs(dest_val_images, exist_ok=True)
os.makedirs(dest_val_labels, exist_ok=True)
def copyfiles(srcdir, dstimages, dstlabels):
dirs = os.listdir(srcdir)
for dir in dirs:
dir = os.path.join(srcdir, dir)
if os.path.isdir(dir) == False:
continue
print('proc:' + dir)
files = os.listdir(dir)
for file in files:
file = os.path.join(dir, file)
if os.path.isfile(file) == False:
continue
if re.search('.txt', file) != None:
shutil.copy2(file, dstlabels)
continue
if re.search('.jpg', file) != None:
shutil.copy2(file, dstimages)
continue
return dirs
files = copyfiles(orig_train_dir, dest_train_images, dest_train_labels)
files = copyfiles(orig_val_dir, dest_val_images, dest_val_labels)
上記スクリプトをconverter.pyとして保存し、ディレクトリ構成を変換します。
# tarinとvalを内包するディレクトリへ移動
(base) $ pwd
/Users/shino/widerface_dataset
# WIDER_train、WIDER_valは前手順により変換したアノテーションデータが格納されている
(base) $ ls
WIDER_test WIDER_val genetator.py
WIDER_train converter.py wider_face_split
# ディレクトリ構成を変換する
(base) $ mkdir -p ./data/yolov9
(base) $ python ./converter.py
# 変換後のディレクトリ内容を確認する
(base) $ ls ./data/yolov9/*
./data/yolov9/train:
images labels
./data/yolov9/val:
images labels
(base) $
YOLOv9で学習する
YOLOv9の学習データセットの位置情報ファイルを作成する
先の手順で作成した学習データの位置をYOLOv9から正しく参照するために、データセットの場所を記したyamlファイルを作成します。今回は、YOLOv9と同じディレクトリにdata.yamlとして位置情報ファイルを作成しました。yamlファイルには下記のパラメータを設定します。パスは、実行する環境に合わせて調整してください。
-
path: 学習データセットが含まれている作業ディレクトリ- 本例では
/Users/shino/widerface_dataset/data/yolov9内のデータが学習に利用されます
- 本例では
-
train: 作業ディレクトリ上で、学習に使う画像フォルダへのパス- 本例では
./train/imagesが学習に利用されます
- 本例では
-
val: 作業ディレクトリ上で、バリデーションに使う画像フォルダのパス- 本例では
./val/imagesが学習に利用されます
- 本例では
-
nc: 分類するクラス数- 今回は顔検出のみのため、顔クラスのみを定義 =
nc: 1
- 今回は顔検出のみのため、顔クラスのみを定義 =
-
names: クラス名リスト- オブジェクトは顔のみですので
0: faceとします
- オブジェクトは顔のみですので
# YOLOv9のカレントディレクトリへ移動する
(base) $ pwd
/Users/shino/yolov9/yolov9
# yamlファイルを作成する
(base) $ vi data.yaml
yamlファイルの内容は下記。
path: /Users/shino/widerface_dataset/data/yolov9
train: train/images
val: val/images
nc: 1
names:
0: face
YOLOv9の学習スクリプトを実行する
学習用データセットの準備ができましたので、train_dual.pyを実行してモデルの学習を行います。スクリプトには引数として下記のパラメータを指定しました(最低限必要なパラメータのみ指定)。
-
--batch: 同時にいくつの入力データを処理するかを指定 -
--epochs: 全データの学習を、何回繰り返すかを指定 -
--img: 入力画像を何pxとして扱うかを設定 -
--device: 学習に使うアクセラレータの指定(MacBook Pro:mps、CUDA:0,1,...) -
--min-items: 学習に使う最小アイテム数(アノテーションの数???) -
--close-mosaic: 完了前にトレーニングを安定させるために、最後の数エポックでモザイクデータの拡張を無効にする設定 -
--data: 学習に使うデータな場所を書いたyamlファイルを指定 -
--weights: 転移学習に使う最初の重みを指定 -
--cfg: 転移学習に使う最初のコンフィグレーションを指定 -
--hyp: 学習に指定するハイパーパラメータを指定
さらなる引数の設定については下記の記事が参考になります。
下記のコマンドで学習を実行します。今回は10epochs学習させて約16時間かかりました。ただ、後に学習曲線を表示しますが、10epochsでは結果が収束していないため、本当は20〜30epochsぐらい実行しておきたいところです(ワークステーションで25epochs実行した結果も後述します)。
# YOLOv9のカレントディレクトリへ移動する
(base) $ pwd
/Users/shino/yolov9/yolov9
# 仮想環境を有効化する
(base) $ conda activate ./env
# 学習スクリプトを実行する
(env) $ python train_dual.py --batch 2 --epochs 10 --img 640 --device mps --min-items 0 --close-mosaic 15 --data ./data.yaml --weights weights/yolov9-c.pt --cfg models/detect/yolov9-c.yaml --hyp data/hyps/hyp.scratch-high.yaml
# ...
# yolov9-c summary: 604 layers, 50698278 parameters, 0 gradients, 236.6 GFLOPs
# Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 807/807 48:31
# all 3225 39675 0.63 0.454 0.401 0.208
# Results saved to runs/train/exp14
# python train_dual.py --batch 2 --epochs 10 --img 640 --device mps --min-items 53353.10s user 10098.88s system 111% cpu 15:48:34.27 total
### 学習完了
(env) $ ls runs/train/exp14
F1_curve.png
PR_curve.png
P_curve.png
R_curve.png
confusion_matrix.png
events.out.tfevents.1732002003.ShingonoMacBook-Pro.local.36181.0
hyp.yaml
labels.jpg
labels_correlogram.jpg
opt.yaml
results.csv
results.png
train_batch0.jpg
train_batch1.jpg
train_batch2.jpg
val_batch0_labels.jpg
val_batch0_pred.jpg
val_batch1_labels.jpg
val_batch1_pred.jpg
val_batch2_labels.jpg
val_batch2_pred.jpg
weights
(env) $
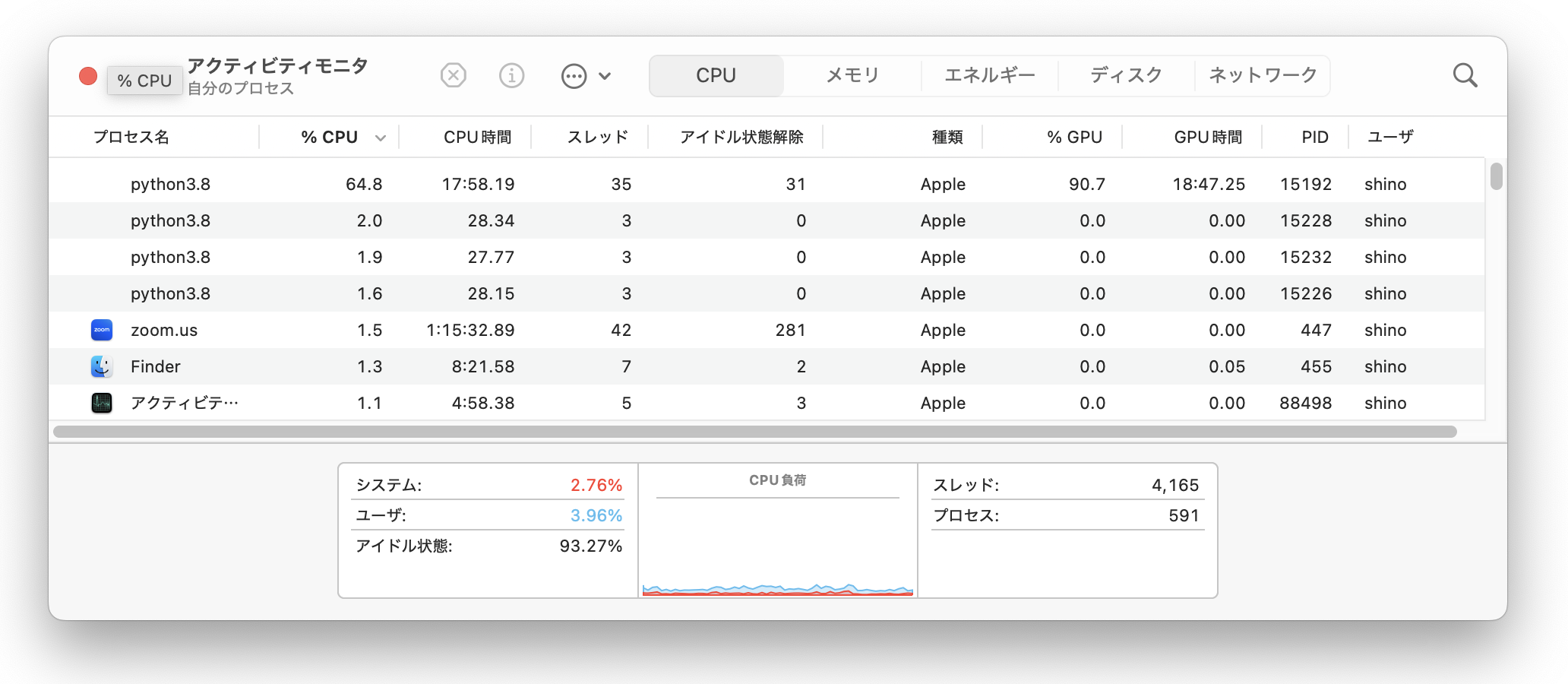
学習中のハードウェアリソース使用率を確認する
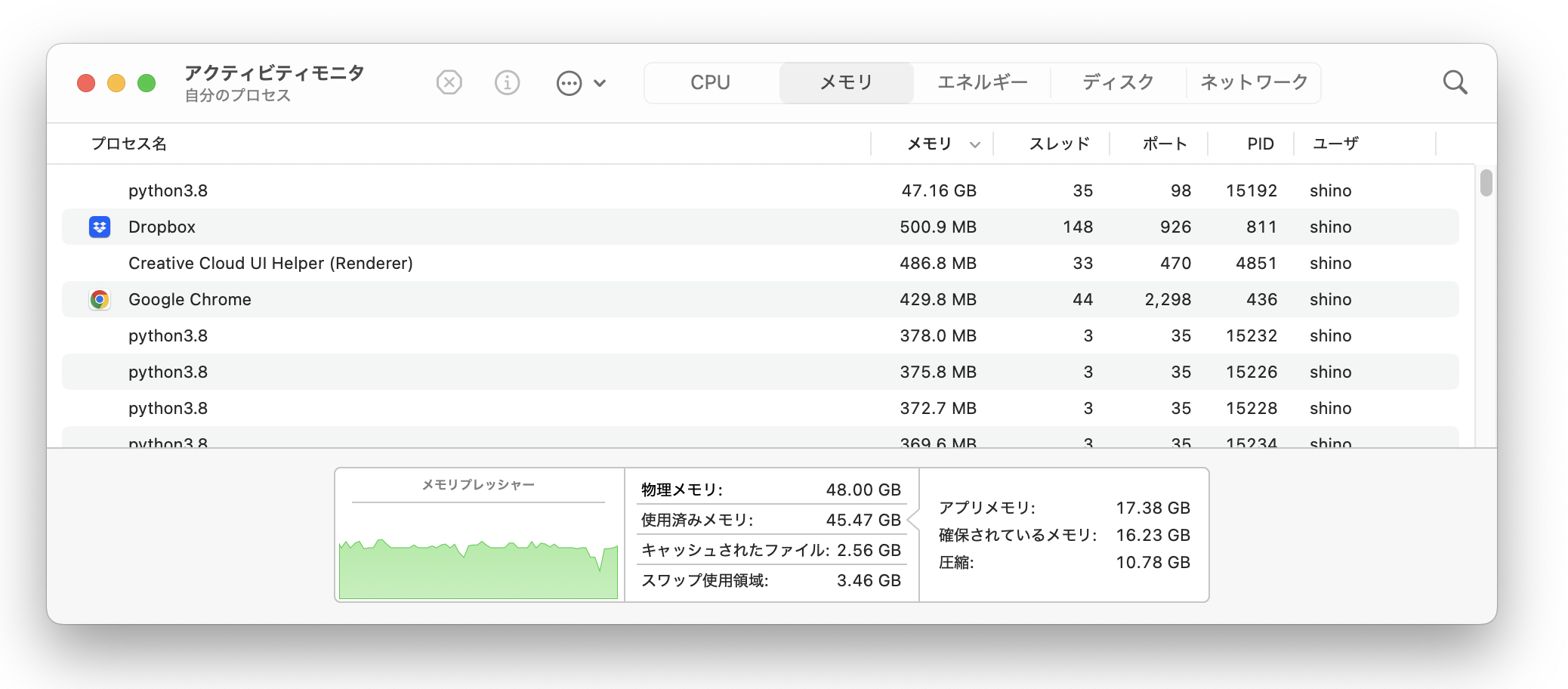
train_dual.pyが学習にMPSを使用できているかを調べるには、アクティビティモニタを使用しましょう。--device cpuを指定するとGPUの使用率が0に、--device mpsが指定するとGPU使用率が上がります。また学習に使うパラメータもアクティビティモニタ(CPU使用率/GPU使用率/メモリ使用率)を見ながら調整すると良さそうです。
学習結果を参照する
学習結果は以下で確認することができます。
(env) $ ls runs/train/exp14
F1_curve.png
PR_curve.png
P_curve.png
R_curve.png
confusion_matrix.png
events.out.tfevents.1732002003.ShingonoMacBook-Pro.local.36181.0
hyp.yaml
labels.jpg
labels_correlogram.jpg
opt.yaml
results.csv
results.png
train_batch0.jpg
train_batch1.jpg
train_batch2.jpg
val_batch0_labels.jpg
val_batch0_pred.jpg
val_batch1_labels.jpg
val_batch1_pred.jpg
val_batch2_labels.jpg
val_batch2_pred.jpg
weights
(env) $ open runs/train/exp14/results.png
(env) $ open runs/train/exp14/val_batch0_labels.jpg
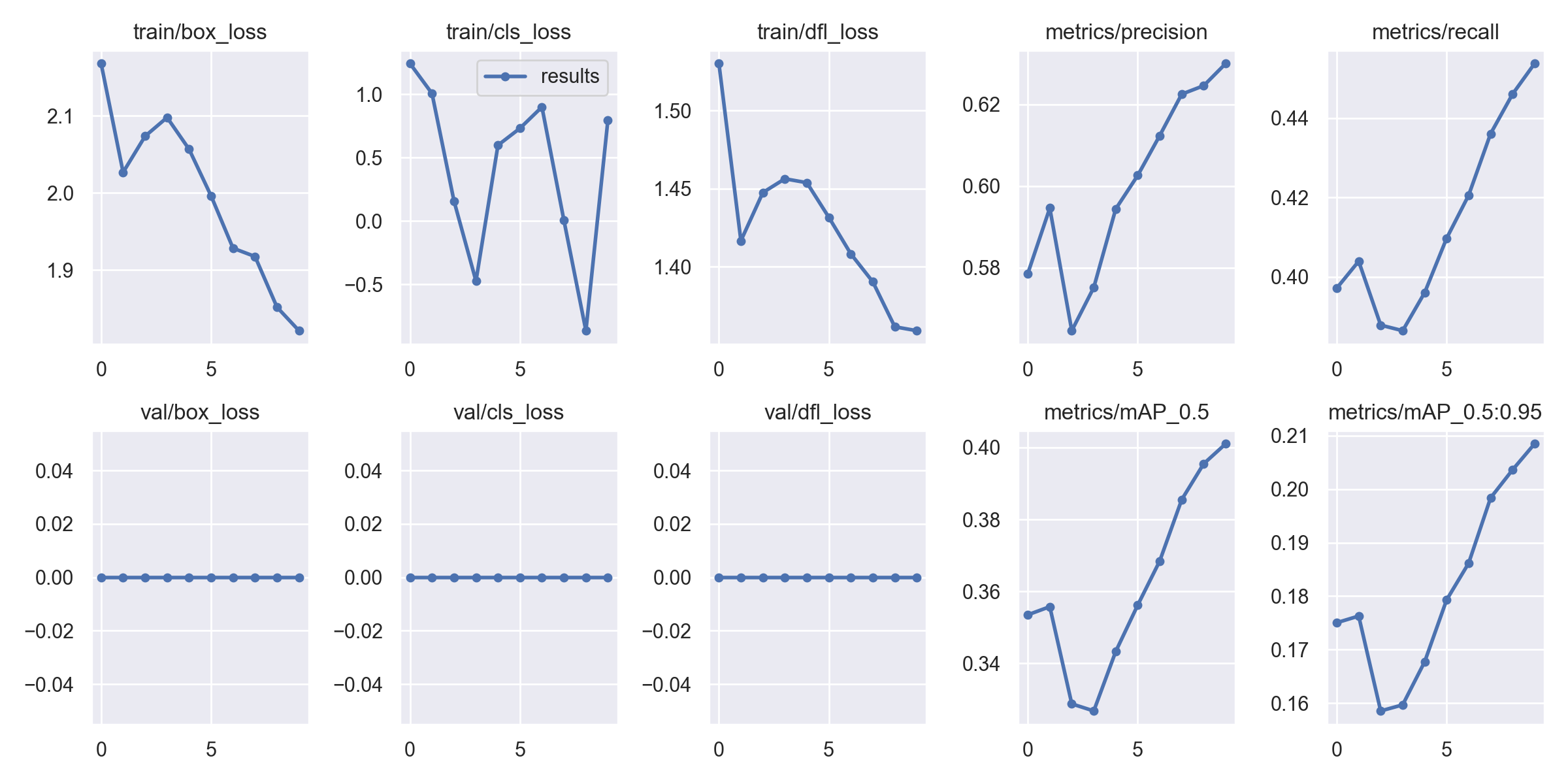
学習曲線はこのようになっています。10epochsでは収束していませんね。これ検出できるのかな。。。

学習の結果として生成されたモデルを使って推論する
最後に、生成したモデルを使って推論してみました。 が、誤検出が多いです。右下のバウンディングボックスは腕を顔と誤検出しているみたい。またバウンディングボックスも顔全体を覆うことができていないものもあるようです。 10epochs以上学習したいので、Corei5-14500 + RTX3060Tiのワークステーションで25epochsの学習にトライしてみます。
(env) $ python detect.py --weights runs/train/exp14/weights/best.pt --conf 0.1 --source /Users/shino/widerface_dataset/WIDER_test/images/0--Parade/0_Parade_Parade_0_871.jpg --device mps
# ...
# Results saved to runs/detect/exp6
(env) $ open runs/detect/exp6/0_Parade_Parade_0_871.jpg

on Ubuntu 24.04 + RTX3060Ti
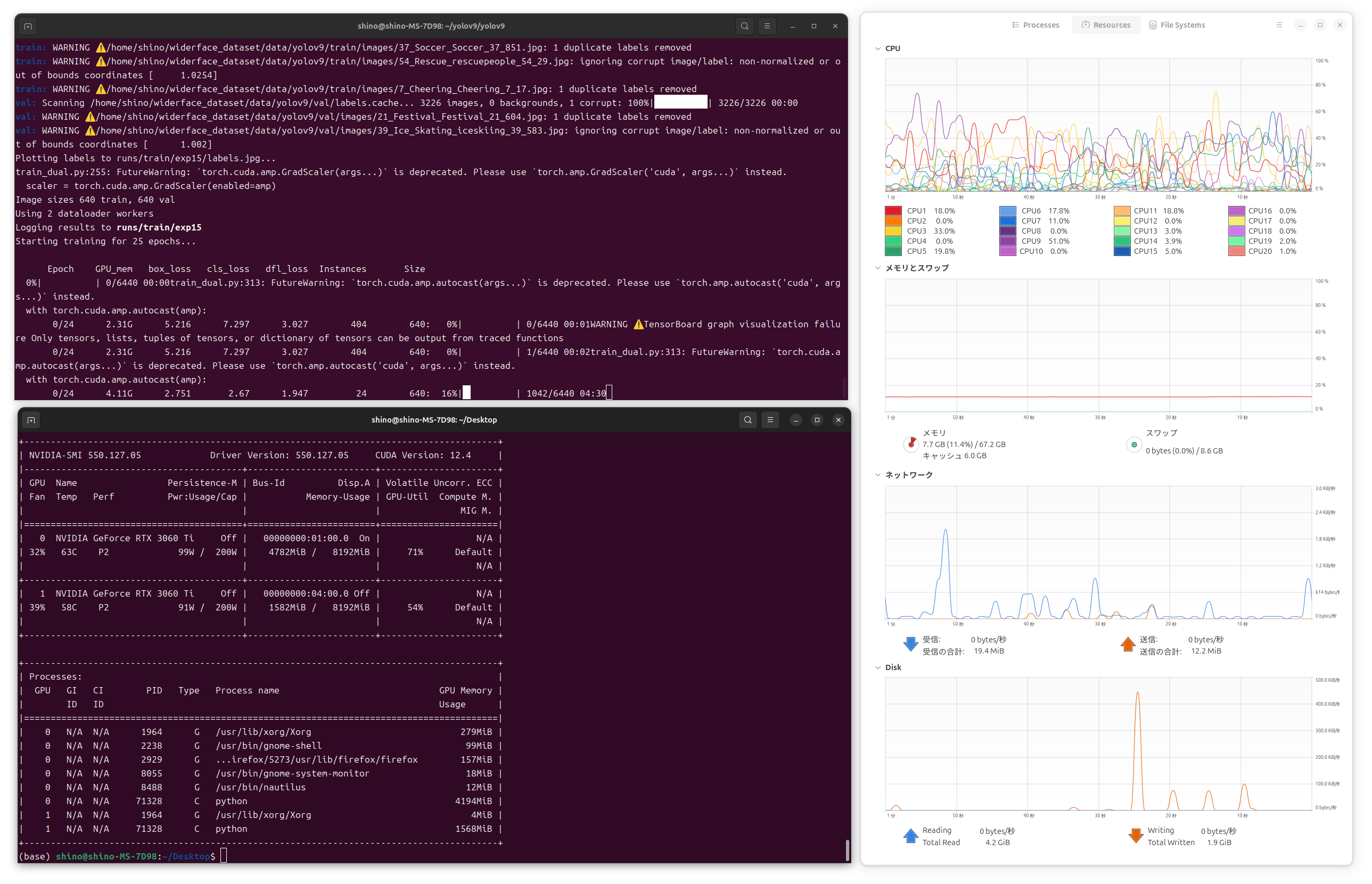
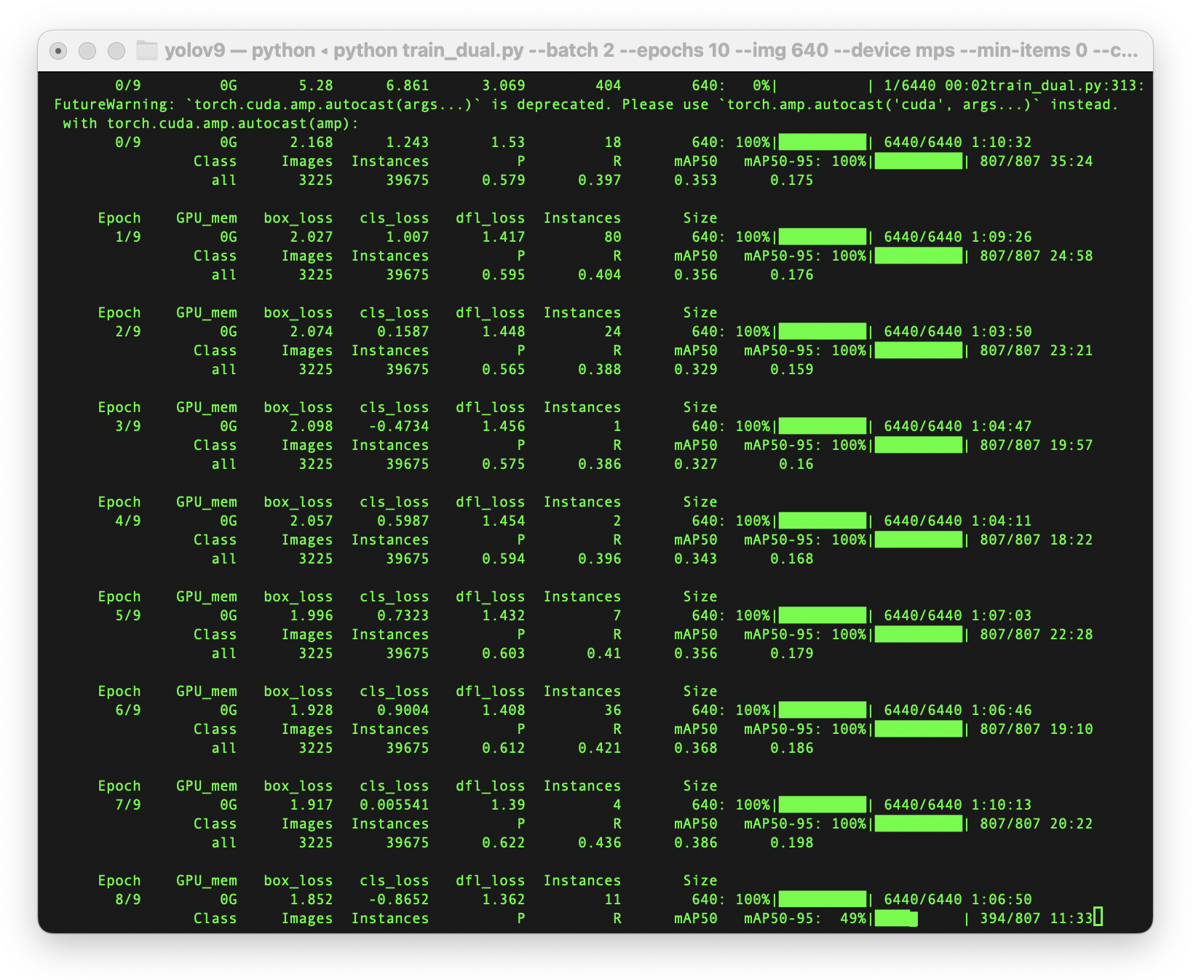
Ubuntuでも手順ほぼ同じでしょう!と書いたのですが、学習時に指定するパラメータに--device 0を指定してGPUの利用すると、CUDA環境でOutOfMemoryErrorが発生しました。MacBook Proのユニファイドメモリで確保できていた領域が、グラフィックボードになったのでGPUのメモリ容量上限に引っかかったという感じでしょうか。このエラーは、バッチサイズが大きい場合に発生しやすいとのこと、また PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True でメモリの断片化を防いで回避できるとのことなので、下記のように学習実行前に環境変数PYTORCH_CUDA_ALLOC_CONFをexportで設定し、バッチサイズを4から2まで小さくして学習を実施したところ、最後まで走らせることができました。
学習時間は25epochsで、約7時間程でした。やはり早いです。 結果から、MacBook Pro / ワークステーションの使い分けとしては、MacBook Proの手元GPUを使って外出先でコーディングして、実際に学習を走らせるのはワークステーション、みたいな流れが良さそうです。
(env) $ python train_dual.py --batch 4 --epochs 25 --img 640 --device 0 --min-items 0 --close-mosaic 15 --data ./data.yaml --weights weights/yolov9-c.pt --cfg models/detect/yolov9-c.yaml --hyp data/hyps/hyp.scratch-high.yaml
...
torch.OutOfMemoryError: CUDA out of memory.
Tried to allocate 2.21 GiB. GPU 0 has a total
capacity of 7.77 GiB of which 1.83 GiB is free.
Including non-PyTorch memory, this process has
5.44 GiB memory in use. Of the allocated
memory 5.08 GiB is allocated by PyTorch, and
158.15 MiB is reserved by PyTorch but unallocated.
If reserved but unallocated memory is large try setting
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
to avoid fragmentation.
See documentation for Memory Management
(https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
# GPU(RTX3060Ti [RAM 8GB])の場合
# GPUメモリを先に確保し、試行毎に確保済みのメモリを切り出して使う
(env) $ export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
# メモリ不足のため学習のバッチサイズを2まで下げる
(env) $ python train_dual.py --batch 2 --epochs 25 --img 640 --device 0 --min-items 0 --close-mosaic 15 --data ./data.yaml --weights weights/yolov9-c.pt --cfg models/detect/yolov9-c.yaml --hyp data/hyps/hyp.scratch-high.yaml
# ...
# Results saved to runs/detect/exp6
(env) $ ls runs/train/exp6
F1_curve.png labels_correlogram.jpg val_batch0_pred.jpg
PR_curve.png opt.yaml val_batch1_labels.jpg
P_curve.png results.csv val_batch1_pred.jpg
R_curve.png results.png val_batch2_labels.jpg
confusion_matrix.png train_batch0.jpg val_batch2_pred.jpg
events.out.tfevents.1731934075.shino-MS-7D98.15733.0 train_batch1.jpg weights
hyp.yaml train_batch2.jpg
labels.jpg val_batch0_labels.jpg
(env) $ open runs/train/exp6/results.png
(env) $ open runs/train/exp6/val_batch0_pred.jpg
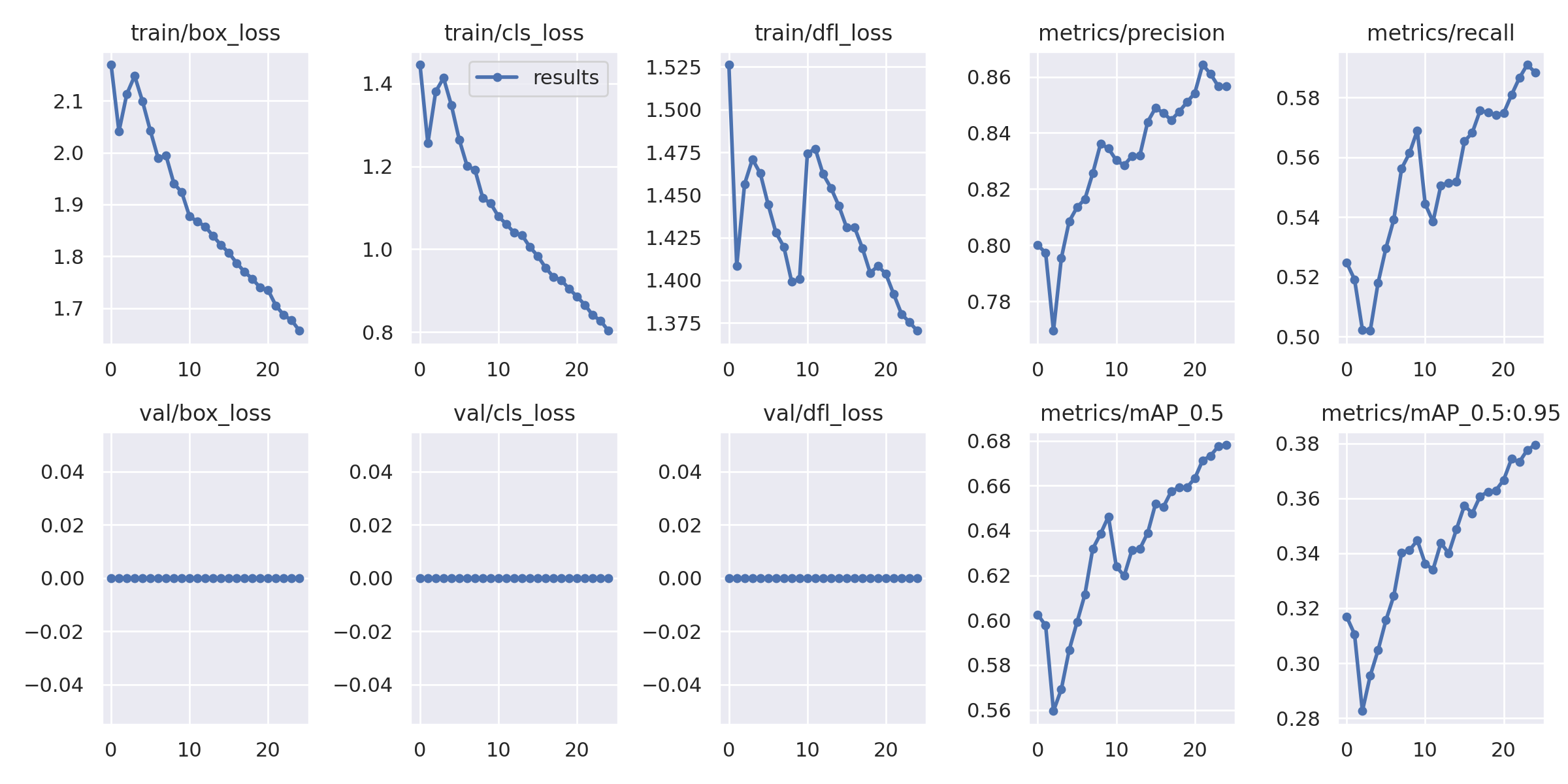
25epochs実行した結果です。かなり収束していますね。
40epochs実行すると、ここまで収束します。
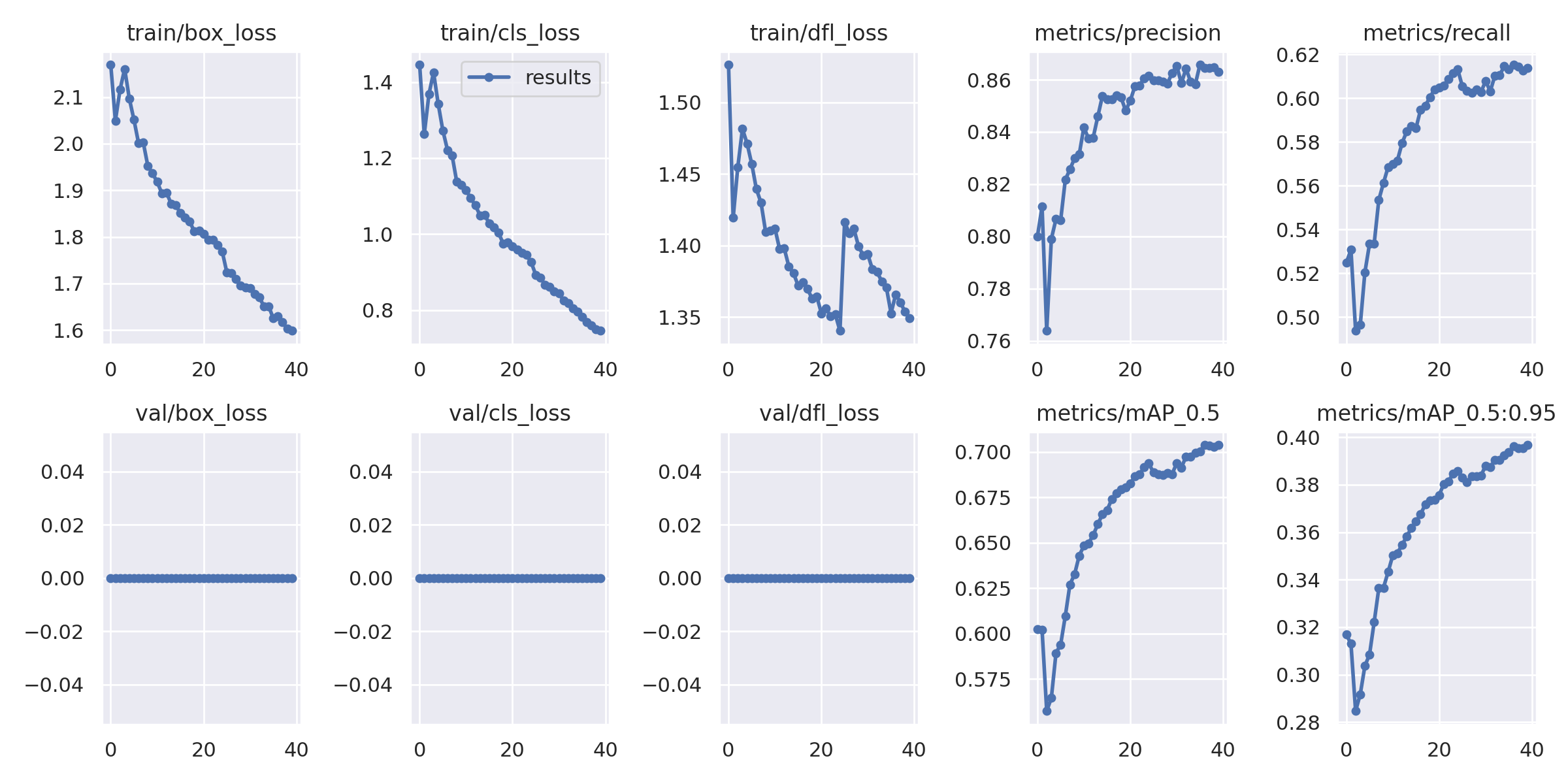
10epochsの時に、誤検出していた箇所が正しく処理されるようになりました。

複数のGPUを利用する
なお余談ですが、train_dual.pyの引数に--device 0,1を指定すると複数のGPUを利用することができます。参考として、RTX3060Tiを2枚さしたワークステーションでYOLOv9をWIDER FACEデータセットで学習を実行させたスクリーンショットを下記に掲載します。