CoreOSでKeepalivedを使った冗長化+負荷分散
前回記事の続きになります
【CoreOS】冗長化構成 Keepalived+NginxLB+NginxWEB(1)
*今回は実際の8080ポートの構成設定を行っていきたいと思います。
バックエンドサーバー用Unitファイルの作成
注(1):実際にはnginx-web@1/2と2つのファイルを作成してください
注(2):X-FLEETのマシンIDはcore01/core04の固有のIDを指定してください
[Unit]
Description=NginxWEB
After=docker.service
Requires=docker.service
[Service]
EnvironmentFile=/etc/environment
TimeoutStartSec=0
Restart=always
ExecStartPre=/usr/bin/docker pull nginx:1.7.10
ExecStartPre=-/usr/bin/docker kill %p
ExecStartPre=-/usr/bin/docker rm %p
ExecStart=/usr/bin/docker run --rm \
--name %p \
--net host \
-v /srv/lb/web.conf:/etc/nginx/nginx.conf:ro \
-v /srv/share/html:/usr/share/nginx/html \
nginx:1.7.10 \
nginx
ExecStop=/usr/bin/docker stop -t 2 %p
[X-Fleet]
MachineID=5b1639bd3cc347cf8fac0b9f597369e3
Nginx用configファイル作成
daemon off;
worker_processes 4;
events {
worker_connections 1024;
}
http {
server {
listen *:8080;
root /usr/share/nginx/html;
location / {
index index.html;
}
}
}
nginx用configの配置及び、index.html作成
# core01サーバーへ配布
scp web.conf core@192.168.0.10:/home/core
ssh core@192.168.0.10
sudo cp -a web.conf /srv/lb/
sudo mkdir -p /srv/share/html
sudo echo "server 1" > /srv/share/html/index.html
# core04サーバーへ配布
scp web.conf core@192.168.0.11:/home/core
ssh core@192.168.0.11
sudo cp -a web.conf /srv/lb/
sudo mkdir -p /srv/share/html
sudo echo "server 2" > /srv/share/html/index.html
Unitファイル登録
fleetctl submit nginx-web@{1,2}
fleetctl load nginx-web@{1,2}
fleetctl start nginx-web@{1,2}
fleetctl list-units
UNIT MACHINE ACTIVE SUB
keepalived@1.service 5b1639bd.../192.168.0.10 active running
keepalived@2.service 6d283167.../192.168.0.11 active running
nginx-lb@1.service 5b1639bd.../192.168.0.10 active running
nginx-lb@2.service 6d283167.../192.168.0.11 active running
nginx-web@1.service 5b1639bd.../192.168.0.10 active running
nginx-web@2.service 6d283167.../192.168.0.11 active running
バッチリサービス起動していることが確認できました。
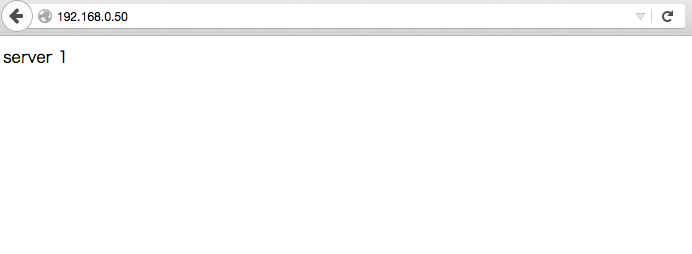
上記のようにサーバーの名称が出てくると思います。
ただし今回の設定はRRと呼ばれる1/2に振り分ける設定ではなくip-hashと呼ばれる、同一クライアントからは常に同じサーバーにアクセスする設定となります。
※前項参照:
#ロードバランサ設定
upstream backend {
ip_hash;
server 192.168.0.10:8080 max_fails=3 fail_timeout=30s ;
server 192.168.0.11:8080 max_fails=3 fail_timeout=30s ;
server 127.0.0.1:8080 down;
}
もし簡単に切り替え確認をしたい場合は、ip_hashを省いてリロードすると簡単にバランシングがされているかチェックできます!
続いてサーバーがダウンした場合のフェイルオーバーについて
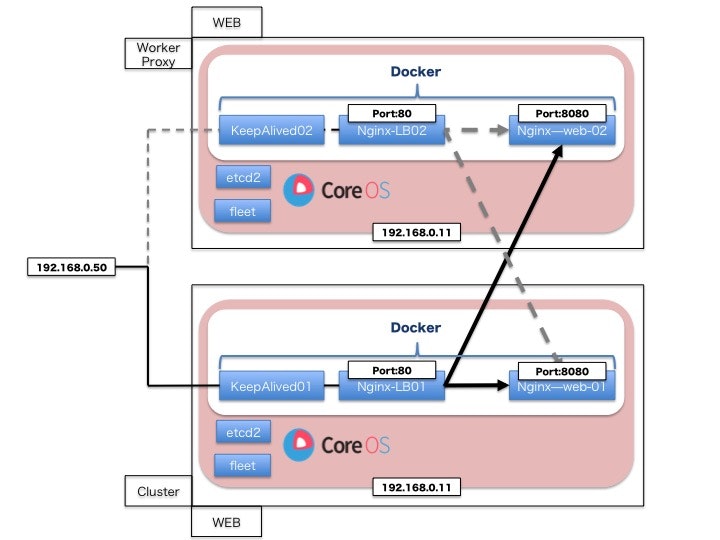
現在、VIPをcoreos01のサーバーが保持しています。
ssh core@192.168.0.10
$ ip a
〜〜〜
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:79:c4:9d brd ff:ff:ff:ff:ff:ff
inet 192.168.0.10/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet 192.168.0.50/24 scope global secondary enp0s3 <=ここ
valid_lft forever preferred_lft forever
core01のを強制的にダウンさせ、core04にVIPが移行されるか確認してみます。
イメージ図
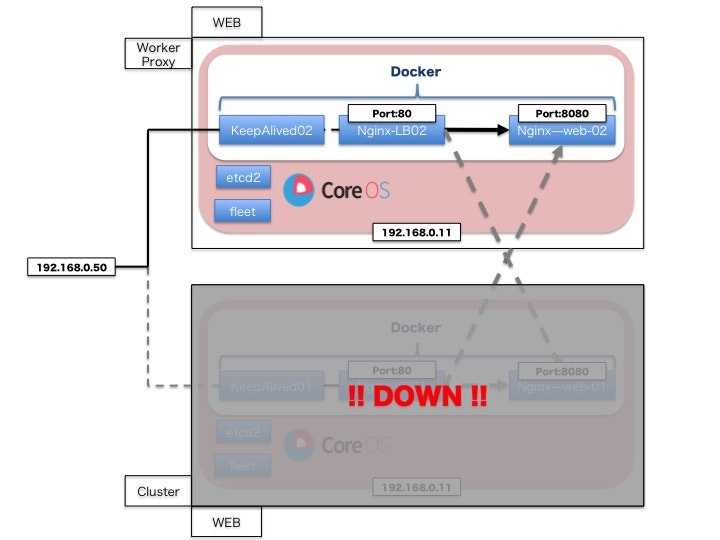
# core01の停止
ssh core@192.168.0.10
$ sudo shutdown -h now
# core04にアクセスしVIPが委譲されているか確認
ssh core@192.168.0.11
core@coreos-04 ~ $ ip a
〜〜〜
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:ad:bd:0f brd ff:ff:ff:ff:ff:ff
inet 192.168.0.11/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet 192.168.0.50/24 scope global secondary enp0s3
$ exit
# unitの確認
fleetctl --tunnel 192.168.0.11 list-units
UNIT MACHINE ACTIVE SUB
keepalived@2.service 6d283167.../192.168.0.11 active running
nginx-lb@2.service 6d283167.../192.168.0.11 active running
nginx-web@2.service 6d283167.../192.168.0.11 active running
ブラウザで表示確認
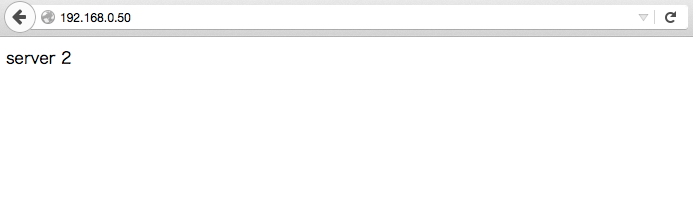
リロードしても「server 2」しかもちろん出ませんが、VIPも移行されサービスも冗長化できていることが確認できました。
※lbのタイムアウト設定はご自身の環境に合わせて変更して下さい。今回は30sの3回失敗した場合に、もう1台へ転送するという設定です
upstream backend {
ip_hash;
server 192.168.0.10:8080 max_fails=3 fail_timeout=30s ;
server 192.168.0.11:8080 max_fails=3 fail_timeout=30s ;
server 127.0.0.1:8080 down;
}
前回記事ご紹介:
【CoreOS】fleet + docker + keepalived(VRRP+VIPのみ)で簡単LB
【CoreOS】cloud-config解説〜インストール
Mac + Virtualbox + CoreOS + etcd2 + fleet の基本設定(1)
Mac + Virtualbox + CoreOS + etcd2 + fleet の基本設定(2)
Mac + Virtualbox + CoreOS + etcd2 + fleet の基本設定(完)