CoreOSクラスタ構築 3台構成
本章ではクラスタ構成を3台用意し、1台サーバーがダウンしても他メンバーが情報を継承し、運用可能な状態を目指します。
前提
Mac + Virtualbox + CoreOS + etcd2 + fleet の基本設定(1)
目指す構成
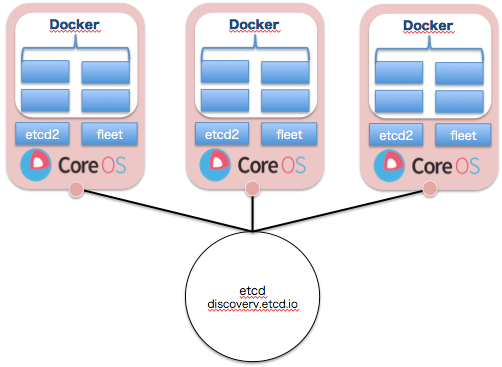
discoveryチャネルでのクラスタメンバー管理
今回はクラスタサイズを3台構成としますので、以下のURLにアクセスしトークンを発行します。
※追記:クラスタ構成がうまく行かず断念。。。
curl -s discovery.etcd.io/new?size=3
https://discovery.etcd.io/<TOKEN>
TOKENと書かれている所には実際には英数字混在の文字列が入ってきます。
ではトークンを取得したので、以前の項で作成したcoreosを利用し、クラスタを作成したいと思います。
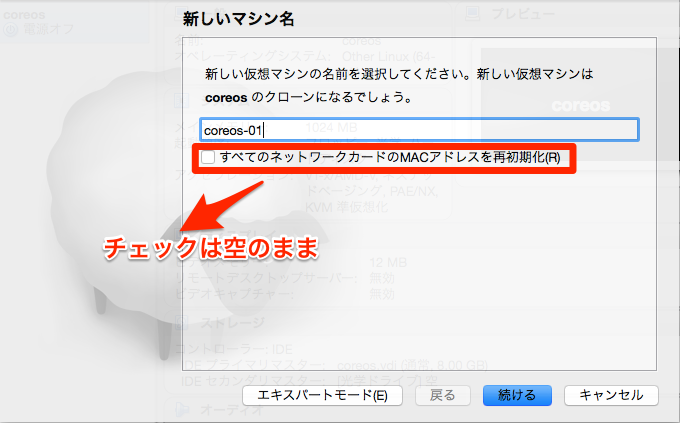
※全てのネットワークカードのMACアドレスを初期化は忘れずに
※名称はcoreos-01/02/03と作っていきます。
1.Virtualboxからのクローン作成
virtualboxを起動し、テンプレートを右クリックでクローンを作成を押下します。
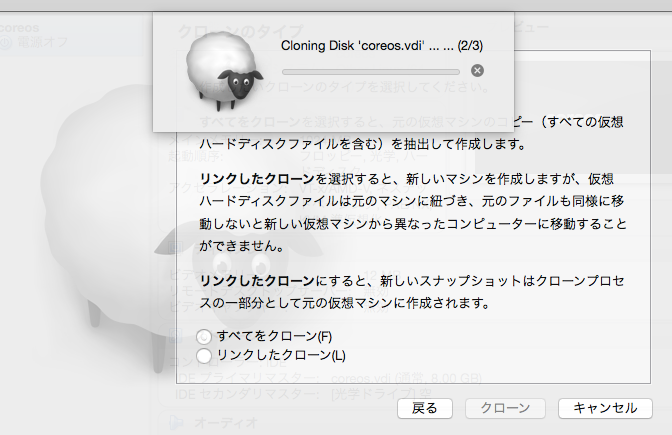
2.全てをクローンを選択し、クローン作成実行を
※5分ほど時間かかります。。。
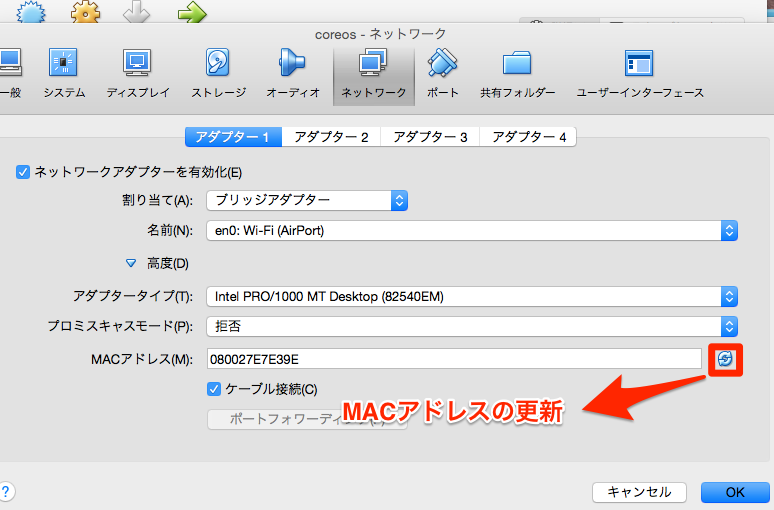
3.MACアドレスのリフレッシュ
IPアドレス、MACアドレスが競合しないようにリフレッシュをかけます。
4.クラスタ3サーバーの起動、cloud-config.ymlの作成
クローンしたサーバーを全て起動します。
# cloud-config
hostname: coreos-01 #hostname suffixに合わせてください
write_files:
- path: /etc/environment
permissions: 0644
content: |
COREOS_PUBLIC_IPV4=192.168.0.10 #ここは3台別別のIPを指定してください
COREOS_PRIVATE_IPV4=192.168.0.10
coreos:
update:
reboot-strategy: 'off'
etcd2:
name: coreos-01
heartbeat-interval: 1000
election-timeout: 5000
advertise-client-urls: http://192.168.0.10:2379
initial-advertise-peer-urls: http://192.168.0.10:2380
listen-client-urls: http://0.0.0.0:2379
listen-peer-urls: http://0.0.0.0:2380
initial-cluster-token: etcd-cluster-1
initial-cluster: coreos-01=http://192.168.0.10:2380,coreos-02=http://192.168.0.20:2380,coreos-03=http://192.168.0.30:2380
initial-cluster-state: new
fleet:
public-ip: 192.168.0.10
metadata: "role=services,cabinet=one"
flannel:
interface: 192.168.0.10
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
- name: docker.service
command: start
- name: timezone.service
command: start
content: |
[Unit]
Description=timezone
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/usr/bin/ln -sf ../usr/share/zoneinfo/Japan /etc/localtime
- name: 10-static.network
runtime: false
content: |
[Match]
Name=enp0s3
[Network]
Address=192.168.0.10/24 #public_ipv4にするIPを記述
DNS=8.8.8.8
DNS=8.8.4.4
ssh_authorized_keys:
- ssh-rsa ※ここに自身の鍵を設置
users:
- name: coreuser
passwd: $1$VIyj3wZe$HVVOEAc/H6a6YZGKCBWSD/
groups:
- sudo
- docker
ssh-authorized-keys:
- ssh-rsa ※ここに自身の鍵を設置
5.cloud-config.ymlを書き込み
sudo coreos-cloudinit -from-file=./cloud-config.yml
# 念のためuser_dataも上書き
sudo cp -a cloud-config.yml /var/lib/coreos-install/user_data
sudo reboot
6.各クラスタからfleetctl/etcdctl cluster-healthが実行できるか
ssh core@192.168.0.10
etcdctl cluster-health
member 59d0611e956db7d1 is healthy: got healthy result from http://192.168.0.20:2379
member 6fb0d145a155e8ee is healthy: got healthy result from http://192.168.0.30:2379
member 7a0fb1a3031d4c79 is healthy: got healthy result from http://192.168.0.10:2379
検証:クラスタを1つダウンさせて、クラスタを維持させることができるか
ssh core@192.168.0.10
fleetctl list-machines --full
MACHINE IP METADATA
87799244733442d381cc207c049e1f68 192.168.0.30 cabinet=one,role=services
# coreos-03をシャットダウン
ssh core@192.168.0.30
sudo shutdown -h now
# coreos-01にアクセスし状況確認
ssh core@192.168.0.10
etcdctl cluster-health
member 59d0611e956db7d1 is healthy: got healthy result from http://192.168.0.20:2379
failed to check the health of member 6fb0d145a155e8ee on http://192.168.0.30:2379: Get http://192.168.0.30:2379/health: dial tcp 192.168.0.30:2379: no route to host
member 6fb0d145a155e8ee is unreachable: [http://192.168.0.30:2379] are all unreachable
member 7a0fb1a3031d4c79 is healthy: got healthy result from http://192.168.0.10:2379
fleetctl list-machines --full
MACHINE IP METADATA
87799244733442d381cc207c049e1f68 192.168.0.10 cabinet=one,role=services
検証:クラスタを2つダウンさせて、クラスタを維持させることができるか
# coreos-03を起動
ssh core@192.168.0.20
sudo shutdown -h now
ssh core@192.168.0.30
sudo shutdown -h now
ssh core@192.168.0.10
etcdctl cluster-health
failed to check the health of member 59d0611e956db7d1 on http://192.168.0.20:2379: Get http://192.168.0.20:2379/health: dial tcp 192.168.0.20:2379: no route to host
member 59d0611e956db7d1 is unreachable: [http://192.168.0.20:2379] are all unreachable
failed to check the health of member 6fb0d145a155e8ee on http://192.168.0.30:2379: Get http://192.168.0.30:2379/health: dial tcp 192.168.0.30:2379: no route to host
member 6fb0d145a155e8ee is unreachable: [http://192.168.0.30:2379] are all unreachable
member 7a0fb1a3031d4c79 is unhealthy: got unhealthy result from http://192.168.0.10:2379
cluster is unhealthy
fleetctl list-machines --full
Error retrieving list of active machines: googleapi: Error 503: fleet server unable to communicate with etcd
※3台クラスタ構成で2台消失してしまうと、クラスタが保持できない様子。。。
検証:再度coreos-02/03を起動
ssh core@192.168.0.10
etcdctl cluster-health
member 59d0611e956db7d1 is healthy: got healthy result from http://192.168.0.20:2379
member 6fb0d145a155e8ee is healthy: got healthy result from http://192.168.0.30:2379
member 7a0fb1a3031d4c79 is healthy: got healthy result from http://192.168.0.10:2379
fleetctl list-machines --full
MACHINE IP METADATA
87799244733442d381cc207c049e1f68 192.168.0.10 cabinet=one,role=services
※問題なく復旧しました。
考察
etcd2でクラスタを構築する場合は最低3台の構成が必要であり且つ、2台消失するとクラスタの保持ができないようです。
quoramアルゴリズムで生存が2台以下になると情報の保持が出来なくなり、クラスタとして維持できなくなります。ただし、Central Serviceが1台よりは複数台で稼働し、シングルポイントをなくすことが重要になります。
次回はworkerロール(proxy)の設定です。
次項:
Mac + Virtualbox + CoreOS + etcd2 + fleet の基本設定(完)
参考:
CoreOS Cluster Architectures
Configuration Flags
CoreOSを使ってDockerコンテナを動かす