データ収集基盤作成の超入門用ハンズオンです。
Fluentdによるデータ収集, Kafkaによるメッセージングを連携させて、超絶シンプルなリアルタイムデータ収集基盤を構築します。
内容はこちら の書籍を参考にさせていただきました。
目的
HTTPによって送信されるリアルタイムデータをFluentdで収集し、Kafkaに連携してコンソール出力する。
完成図

利用技術
Fluentd
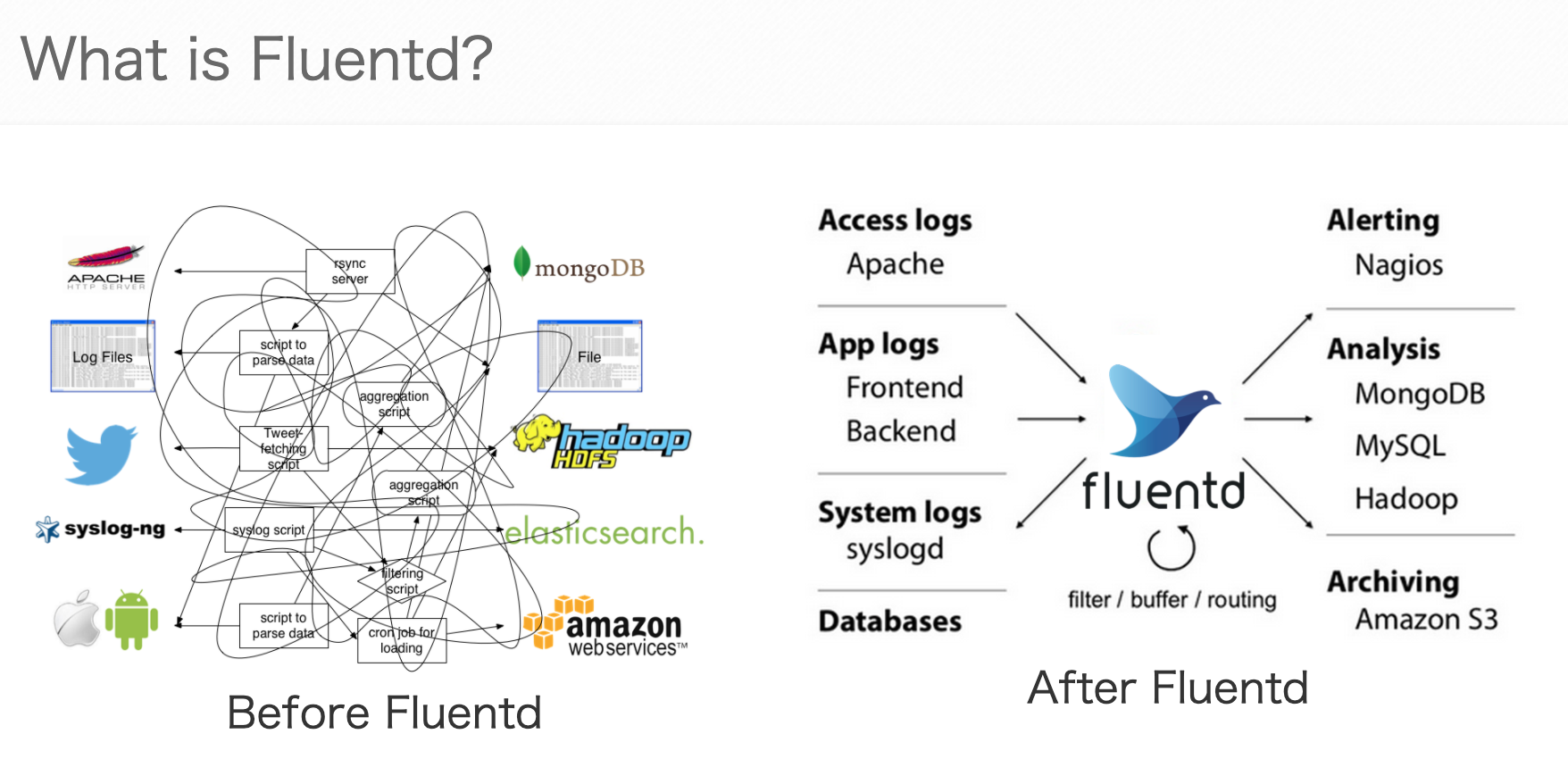 公式サイト(https://www.fluentd.org/)より
公式サイト(https://www.fluentd.org/)より
Fluentdはオープンソースのデータ収集のためのソフトウェアです。
各種データソース、データ送信先の連結を一括で管理することができ、連携に必要な設定の負担を軽減することができます。
Fluentdの特徴として、コア機能は最小限としていて、プラグインを追加することで様々なデータソース、送信先に対応することができます。
Kafka
 公式サイト(https://kafka.apache.org/)より
公式サイト(https://kafka.apache.org/)より
Apache Kafkaは大量のデータを高速に収集できる分散メッセージキューです。
Kafkaは下記のようにして、データソースから送信先へとデータを連携します。
- Kafkaへデータを送信する側(Producer)はメッセージ連携用のトピックを宛先にメッセージを送信する
- Kafakaからデータを受信する側(Consumer)は取得したいトピックをConsumeすることで、メッセージを受信する
Kafkaでは各トピックのデータを処理するクラスタをブローカーとよび、ブローカーの数を増減させることで、データ量に対するスケーラビリティを実現します。
環境
CentOS7.2
実装
Fluentdの設定
Fluentd側の設定を行います。
まず、tg-agentをインストールします
# curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
tg-agentを起動します
# systemctl start td-agent
td-agentの起動状態を確認します
# systemctl status td-agent
active(running)と表示されていればOKです。
続いて、Fluentdの設定ファイル(/etc/td-agent/td-agent.conf)を編集します。
Fluentdでは設定ファイルにデータソース、送信先の情報を記載することで動作を規定することができます。
まず、httpにより送信されたデータを9999ポートで受け付けるようにします。
[編集前]
<source>
@type http
@id input_http
port 8888
</source>
[編集後]
<source>
@type http
@id input_http
port 9999
</source>
続いて、ルーティング条件、送信先を設定します。
Fluentdでは入力されたデータに対し、タグを付与することで、タグごとに処理や送信先を設定します。
in_httpプラグインでは、データへのタグの付与は下記のように、POST時のURLパスで設定されます。
http://[host]:[port]/[tag]
今回の場合は、sampleから始まるタグに対する設定を記載します。
設定ファイルに下記のスクリプトを追加します。
<match sample.**>
@id output_sample_to_kafka
@type kafka_buffered
brokers localhost:9092
default_topic topic-sample
output_data_type json
exclude_topic_keys true
</match>
<match sample.**>でsampleタグを指定します。
@type kafka_bufferedで、FluentdからKafkaへデータを投入するためのプラグインを指定します。
brokers localhost:9092でブローカーが起動しているポートを指定します。
default_topic topic-sample で送信先のトピック名を指定します。
後ほど、Kafkaの9092ポートでConsumerを起動させます。
以上により、Fluentdで9999ポートに来たhttpのpostリクエストを受け取って、KafkaのConsumerに連携する設定が完了しました。
設定を反映させるために、td-agentを再起動させます。
# systemctl restart td-agent
続いてKafkaの設定を行います。
Kafkaの設定
まず、Kafkaをインストールします。
wget -O /tmp/kafka_2.11-1.0.0.tgz https://archive.apache.org/dist/kafka/1.0.0/kafka_2.11-1.0.0.tgz
tar -xzf /tmp/kafka_2.11-1.0.0.tgz -C /opt
mv /opt/kafka_2.11-1.0.0/ /opt/kafka
Kafkaの起動前に、Zookeeperを起動します。
Zookeeperとは分散アプリケーションの実装に必要となる同期処理や設定管理などを行ってくれるミドルウェアで、Kafka Brrokerは起動時にZookeeperへコネクションを確率する必要があります。
# nohup /opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties &
Kafkaを起動します。
# nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties &
続いて、今回データを送信するトピック(topic-sample)を作成します。
トピックは指定したパーティション数で構成され、トピックに送信されたメッセージは分散配置されたパーティションのいずれかに配置されます。
# /opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic-sample
Console-consumerにより、トピックをConsumeします。
Console-consumerはKafkaにデフォルトで付属しているconsumerで、指定したトピックに送信されたデータを単純にコンソール出力します。
# /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-sample --from-beginning
これで、Producer(Fluentd)からsample-topicにデータ送信があれば、Console-consumerにリアルタイムに連携されるようになりました。
データソースの作成
最後にデータソースを作成し、Fluentdに送信します。
今回はSreamingデータのサンプルとして、一定時間おきにPOSTリクエストを吐き出し続けるスクリプトを用意します。
import requests
import time
# 5秒に1回POSTリクエストを送信する
url = 'http://localhost:9999/sample.data'
i = 0
while True:
payload = {"id":i}
requests.post(url, json=payload)
i += 1
time.sleep(1)
URLで指定しているsample.dataがFluentdでのタグとなります。
データ連携
console-consumerを起動させた状態で、バックグラウンドで上記のpythonスクリプトを実行すると、コンソール上にデータがリアルタイムで表示されます。
[root@localhost ~]# /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-sample --from-beginning
{"id":0}
{"id":1}
{"id":2}
{"id":3}
{"id":4}
{"id":5}
まとめ
Fluentd, Kafkaを利用したリアルタイムデータ収集基盤を構築することができました。
今回はデータソース、データ連携先共にシンプルなサンプルですが、実データを利用してより大規模なデータ収集も試してみたいです。