この記事では、備忘録としてメモを書いていきます。
データの構造が数字と文字が混在している場合がデータ全体を一気に処理したい。
サンプルデータはirisデータセットを用いてる。

例1.行ごとに合計値を計算したい。
t(apply(mat, 1, function(row) sum(row)))
「Species」列は文字列タイプなので、エラーになった。
Error in sum(row) : invalid 'type' (character) of argument
もっと効率ありの書き方をやってみる。
rowSums(iris)
前と同じ理由で「Species」列は文字列タイプなので、エラーになった。
Error in rowSums(iris) : 'x' must be numeric
rowSumsは数値タイプの列のみ応用する
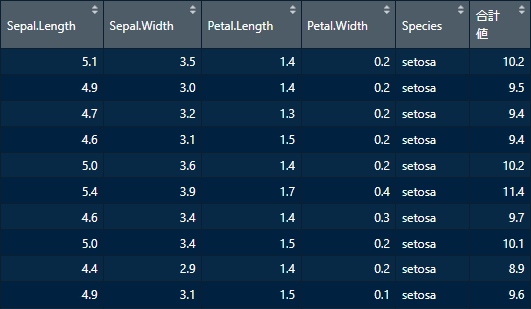
iris %>% mutate("合計値"=rowSums(iris[sapply(iris, is.numeric)], na.rm = TRUE))
成功した。イメージは↓
例2.混在データの小数点の切り捨て問題
普通のroundを利用する
round(iris, digits = 0)
まだ「Species」列は文字列タイプなので、エラーになった。
Error in Math.data.frame(list(Sepal.Length = c(5.1, 4.9, 4.7, 4.6, 5, :
non-numeric variable(s) in data frame: Species
modify_ifを利用してみる。
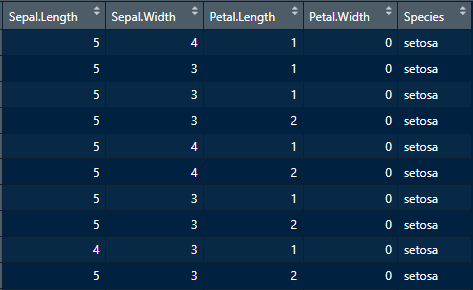
iris %>% modify_if(~is.numeric(.), ~round(., 0))
今度は成功した。イメージは↓
合計値計算の部分一部コードを↓のページから:
https://qiita.com/hoxo_m/items/d19d92130c4f6bbafcda
免責
この記事は個人のメモであり、所属する企業や団体とは関係ございません。