はじめに
最近、Databaseの過負荷が疑われる障害対応に携わる機会がありました。
本記事では、その際の対応を通じて自分自身が学んだポイントを中心に整理しています。
あくまで一つの事例に基づく内容であり、すべてのケースに当てはまるものではありませんが、同様の状況に遭遇した際の参考になれば幸いです。
IBM Cloud Database for PostgreSQLの基本構成について
具体的な事象を説明する前に、前提としてIBM Cloud Database for PostgreSQLの基本的な構成について簡単に触れておきます。
後続の説明では、Primary InstanceやRead-only Replicaといった用語を用いるため、それらがどのような役割を持つのかをあらかじめ整理しておくことが目的です。
※ ここでは詳細なアーキテクチャ解説は行わず、本記事の内容を理解するために必要な範囲に留めます。
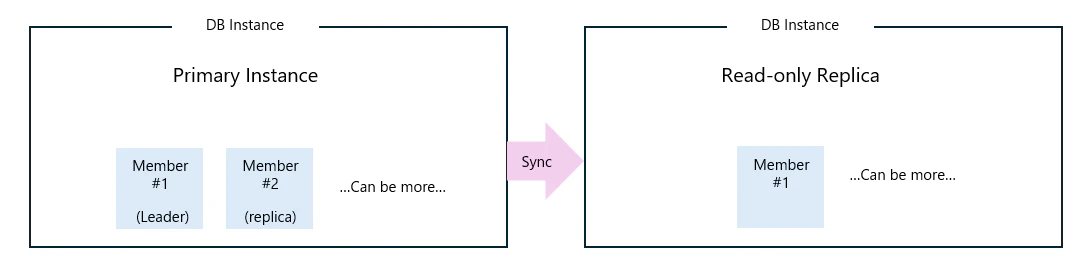
IBM Cloud Database for PostgreSQL(以下、Databaseと記載)を利用する場合、典型的なHigh-Availability構成は以下のようになります。
-
Primary Instanceについては、
Default構成として、LeaderとReplica、2つのMemberが含まれています。
通常、Read/Write RequestはLeader Memberに対して行われます。Leader Memberに障害が発生した場合には、Replica MemberへFailoverされます。
なお、IBM Cloud DatabaseはPaaSとして提供されているサービスであるため、Member間の同期制御やLeaderの切り替え(failover)といった処理は、Cloud側で自動的に監視・制御されており、ユーザーが操作できるメニューは提供されていません。 -
Read-only Replica Instanceについては、
DatabaseへのRead requestが多い場合、負荷分散を目的としてRead-only Replica Instance(以下、RR)を追加する構成がよく採られます。
RR InstanceはPrimary Instanceからデータを複製して保持しますが、Primary Instanceの負荷が高い場合や、Instance間のNetwork問題が発生した場合など、Replicationの同期が維持できなくなることがあります。
このような場合、ユーザーはResync操作を実行する必要があります。Resync操作は Console上のメニューから実施可能です。
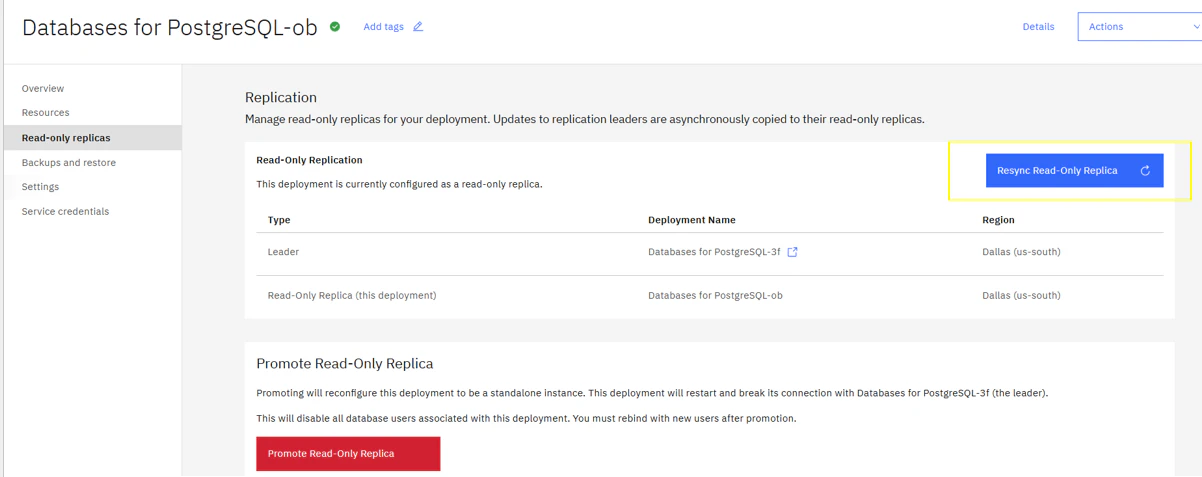
Resyncは、Primary Instanceのデータを最初から再複製する処理であるため、データサイズが大きい場合やNetwork帯域が限られている場合には、完了までに数時間かかることもあります。
また、Resyncが完了するまでの間、RR Instanceのdataは利用できず、すべての Read RequestはPrimary Instanceに向かうことになります。その結果として、Resync実行中はPrimary Instanceの負担が増加することになります。
今回の事象については
今回遭遇した事象では、RR Instanceが複数回にわたりReplicationの同期を維持できない状態となり、その都度Resync操作を実行する必要がありました。
また、いずれのResyncも完了までに数時間を要し、システム運用に実際の影響が生じている状況でした。
当初は、ネットワーク性能の問題により同期が失敗し、その結果としてResyncにも時間がかかっているのではないかと考え、原因分析や議論も主にNetwork観点で進めていました。
しかし調査を進める中で、RR Instanceが非同期状態に陥るたびに、Primary Instance上に蓄積されるWAL(Write-Ahead Logging)のサイズが継続的に増加していることに気づきました。WALにはReplication待ちのdata変更記録が保持されており、そのサイズが拡大し続け、Disk容量の約 10% に近づいている状態でした。
この状況から、影響範囲はRR Instanceにとどまらず、Primary Instance自体にもリスクが及びうると判断しました。すなわち、「同期が遅い」「RRが利用できない」といった問題だけでなく、Primary Instance側に何らかの異常があり、その影響でDataが正常に同期できなくなる可能性も考慮する必要がありました。
そのため、バックアップから新たにPrimary Instanceを作成するなどの復旧対応を優先的に実施した上で、改めて事象を振り返り分析しました。最終的には、Primary Instanceの負荷が過度に高くなっていたことが、Replicationの挙動に影響を与えていたと考えています。
Primary Instanceの過負荷をどのように判断したか
Databaseは、Dataの構造や利用方法の違いによって、負荷が高まった際に現れる兆候も一様ではありません。
例えば、Dataの読み書き自体はそれほど多くないものの、単純にDataの量が非常に大きい場合、Disk使用率は高くなりますが、Disk IOは必ずしも高くなりません。
一方で、Data量がBottleneckではなく、読み書きが非常に頻繁な場合には、Disk使用率がそれほど高くなくても、Disk IOが顕著に上昇します。
さらに、DatabaseのQuery実行状況を確認し、Slow Queryが多数記録されている場合には、DatabaseがQueryに対して十分な応答性能を発揮できていないと判断できます。
以下では、今回の分析ポイントについて説明します:
- Slow Query Logs
IBM Cloud Databases for PostgreSQLでは、Default設定において100msを超えて応答したQueryが Slow Queryとして判定され、IBM Cloud Logsに記録されます。
そのため、IBM Cloud Logs上で特定の時間帯に記録されたSlow Queryの件数を確認することで、負荷状況を把握することが可能です。また、各Slow QueryLogにはDuration(実際の応答時間)という項目が含まれており、これを集計・分析することで、Query応答時間の分布を確認できます。
例えば、数百回から数千回にわたり、数秒あるいは数分単位の応答時間を要するQueryが継続的に発生している場合、Databaseが過負荷状態に陥っていると判断できます。
※ Slow Queryは意図的に再現することが難しいため、検証環境では該当Logのスクリーンショットを用意できていません。
- Disk IOPSとDisk IO Utilizationについて
IBM Cloud Databases for PostgreSQL においては、Disk IOPS(1 秒あたりに実行可能なDisk I/O回数)は、Instanceに割り当てられたDisk Sizeに連動しており、Disk容量(GB)の10 倍で設定されます。
たとえば、Disk Sizeが100GBの場合、IOPSは1,000となります。
実際のDisk IO Utilization(IOPS使用率)については、IBM Cloud Monitoringが提供するDatabase向け Dashboardから容易に確認できます。
Disk IO Utilizationが100% に達している場合、ディスクの読み書き性能が限界に達している状態を示します。この際、Disk使用容量(残容量)が十分に残っていたとしても、I/O 性能の観点ではボトルネックが発生しているため、Disk Sizeの拡張を検討すべき状態と判断できます。

- Block Hit Rateと Block Read Rateについて
これらの指標はIBM Cloud MonitoringのDashboard上から簡単に確認できます。Database過負荷を直接判断する決定的な指標ではありませんが、負荷の傾向を把握するための参考情報として有用です。
左側のBlock Hit Rateは、Queryが要求するデータをInstanceのCache上で取得できた割合を示します。
Diskへのアクセスが発生しないため、この値が高いほどDisk IOPSの負荷軽減という観点では望ましい状態といえます。
一方、右側のBlock Read Rateは、Cache上に該当Dataが存在せず、Diskから読み込みが発生した割合を示します。この比率が高い場合、Disk IOPSへの依存度が高くなりやすく、状況によってはQuery特性やData構造の見直しを検討すべきサインとも読み取れます。

過負荷が発生する原因と、その対策について
Databaseの過負荷が発生する原因はさまざまです。Infra担当の立場では、Data構造やQuery特性といったDatabase内部の設計まで把握することが難しい場合も多く、Application開発チームと連携しながら最適化を検討することが重要になります。
ここでは、IBM CloudとInfraの観点から対応可能な改善ポイントの一例を整理します。
Dataを複数のDatabase Instanceに分散する
Cloud上でDatabase サービスを利用する際、「本番環境用に1 Instance、検証環境用に1 Instanceを用意し、必要なDiskやMemoryをそのInstance にまとめて割り当てる」という構成が取られることは少なくありません。
その結果、Application内に多数のDatabaseやTableが存在していても、本番環境ではそれらが1つの大規模なDatabase Instanceに集約されている、というケースも見られます。
このような集約構成には、確かに以下のようなメリットがあります。
- Database Instanceの数が少ないため、SW Upgradeなどの運用負荷を抑えられる
- MemoryやDiskをInstance内で共有でき、一定のコスト効率が期待できる
一方で、Application及びデータ量、アクセス量が将来的に拡張していく前提の場合には、重要かつ規模の大きいDatabasesをあらかじめ別Instanceに分散することを検討すべきです。主な理由は、以下の通りです。
- Query負荷の高いdatabaseがMemoryを大量に消費し、同一Instance内の他のdatabaseと性能面で競合する可能性があるため
- MemoryやDiskの増設はDatabase Instance単位で行う必要があり、Cloud サービスとして上限が存在するため
例えば、すでにDisk容量が2TBに達しているInstanceにおいて、数年後にデータ量が倍増した場合、3TB〜4TBへの拡張が必要になる可能性があります。しかし、4TBが上限である場合、それ以上の拡張はできません。後から一部のデータベースを別Instanceに移行することも技術的には可能ですが、事前に拡張性を見据えてInstanceを分散しておくことで、将来的な緊急対応を避けることができます。
shared_buffersのサイズを調整する
IBM Cloud DatabaseサービスはPaaSではありますが、PostgreSQLのshared_buffersパラメータはユーザー側で変更可能です。
DefaultではInstanceのMemoryサイズに関わらず262MBに設定されており、一般的には、Instance Memoryの1/4程度を目安に設定することが推奨されます。例えば、Instance Memoryが4GBの場合、shared_buffersを1GB程度に設定することで、キャッシュヒット率の改善が期待できます。
Disk IO Utilization を継続的に監視する
前述の通り、Disk IO Utilizationが100%に近づいている場合、Disk IOが明確なBottleneckとなっている状態と考えられます。IBM Cloud Databases for PostgreSQLでは、Diskサイズに応じてIOPSが割り当てられるため、このような場合はDiskを拡張することでIOPSを増やす対応が有効です。
Mission Critical databaseにはIsolated構成を検討する
IBM Cloud DatabaseのHosting Modelには、SharedとIsolatedの2 種類があります。
Databaseはコンテナベースで提供されており、Isolated構成ではSingle Tenantの専有Computeリソースが割り当てられます。そのため、Shared構成と比較して、性能面や安定性の観点でより高い保証が期待できるのがIsolated構成の特徴です。
おわりに
本記事では、IBM Cloud Database for PostgreSQL において実際に遭遇した過負荷障害をもとに、
Infra 観点で確認・対応できたポイントを整理しました。
同じような構成・運用をされている方が、
「あ、これ自分の環境でも起こり得るかも」と気づくきっかけになれば幸いです。