クロスアビリティ Winmostarサポートチームです。
本記事ではpymatgenを用いた物性データの取得・活用について触れていきます。
本記事の作成にあたり以下のページを参考にしています。
目次
- 環境整備
- pymatgenによるJSON形式でのデータ取得・閲覧
- 取得データの活用 機械学習を用いた半導体物性予測
環境整備
pymatgenを利用するにあたって、初めにデータサイエンス向けのPythonパッケージであるAnacondaにpymatgenをインストールします。これらに関してはこちらの記事を参考にしてください。
次に、Anacondaのインストールにより利用可能となるエディターツールJupyter Notebookを起動します。
Windowsではタスクバーにある検索ボックスから"Jupyter Notebook"で検索することで利用できます。
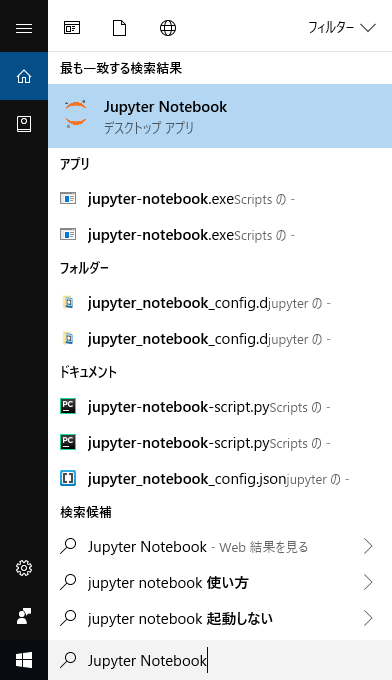
以降はこのJupyter Notebook上で操作を行います。
pymatgenによるJSON形式でのデータ取得・閲覧
pymatgenを用いてMaterials Projectから物性データを取得し、JSON形式で出力します。データの取得はこちらの記事を参考にしています。
初めに空のfeature.jsonファイルを作成し、物性データを取得する物質名だけを列記した辞書を定義します。
# datalist.py
symbols = ["H", "He", "Li", "Be", "B"] #時間短縮目的のテスト用配列
# symbols = ["H", "He", "Li", "Be", "B", "C", "N", "O", "F", "Ne", "Na", "Mg", "Al", "Si", "P", "S", "Cl", "Ar", "K", "Ca", "Sc", "Ti", "V", "Cr", "Mn", "Fe", "Co", "Ni", "Cu", "Zn", "Ga", "Ge", "As", "Se", "Br", "Kr", "Rb", "Sr", "Y", "Zr", "Nb", "Mo", "Tc", "Ru", "Rh", "Pd", "Ag", "Cd", "In", "Sn", "Sb", "Te", "I", "Xe", "Cs", "Ba", "La", "Ce", "Pr", "Nd", "Pm", "Sm", "Eu", "Gd", "Tb", "Dy", "Ho", "Er", "Tm", "Yb", "Lu", "Hf", "Ta", "W", "Re", "Os", "Ir", "Pt", "Au", "Hg", "Tl", "Pb", "Bi", "Po", "At", "Rn", "Fr", "Ra", "Ac", "Th", "Pa", "U", "Np", "Pu", "Am", "Cm", "Bk", "Cf", "Es", "Fm", "Md", "No", "Lr"]
print(symbols)
import itertools
combinations = itertools.combinations(symbols, 2) # 二元物質のみ
# combinations = itertools.combinations_with_replacement(symbols, 2) 単体も含める場合
materials = list(combinations)
print(materials)
output = {}
for system in materials:
if (system[0] == system[1]): #単体を考慮できるようにするため。二元物質のみの場合はこのifは通らない。
name = system[0]
else:
name = system[0] + '-' + system[1]
output[name] = None
import os
import json
filename = 'feature.json'
if os.path.exists(filename):
print("ERROR: Delete ", filename)
else:
file = open(filename , 'w')
file.write(json.dumps(output))
file.close()
ここではH, He, Li, Be, Bの5原子から考えられる10種類の二元物質について考えます。
Jupyter notebook上では以下のような操作となります。In[1]と記されているコマンドラインにコードを打ちこみ、コマンドバーにあるRunを押して流します。print文にしたがい、対象となる物質名が出力されます。
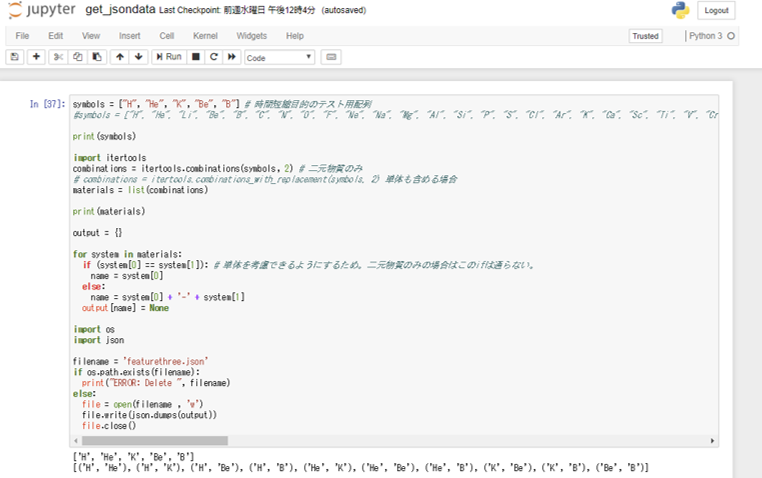
物質名が列記されたfeature.jsonファイルが作成されたところで、pymatgenを用いた物性データの取得を行います。
# get_data.py
import shutil
from pprint import pprint
from pymatgen import MPRester
API_KEY = #自分のAPI_KEYを文字列として代入する
mpr = MPRester(API_KEY)
import json
file = open('feature.json' , 'r')
features = json.loads(file.read())
file.close()
for name in features:
value = features[name]
if value == None or value == "ERROR":
print("Now accessing: ", name)
try:
results = mpr.get_data(name, data_type='vasp')
except:
print("Maybe timeout...")
pass
else:
try:
json.dumps(results)
except:
features[name] = "ERROR"
pass
else:
features[name] = results
else:
print("Already finished: ", name)
# 空の要素が存在しているかチェック
Done = True
for name in features:
value = features[name]
if value == None:
Done = False
break
if Done:
print("Done")
else:
print("Try again")
# まれに書き込み失敗することがあるので、一応バックアップをとっておく
shutil.copy('feature.json', 'feature.json.bkp')
file = open('feature.json' , 'w')
file.write(json.dumps(features))
file.close()
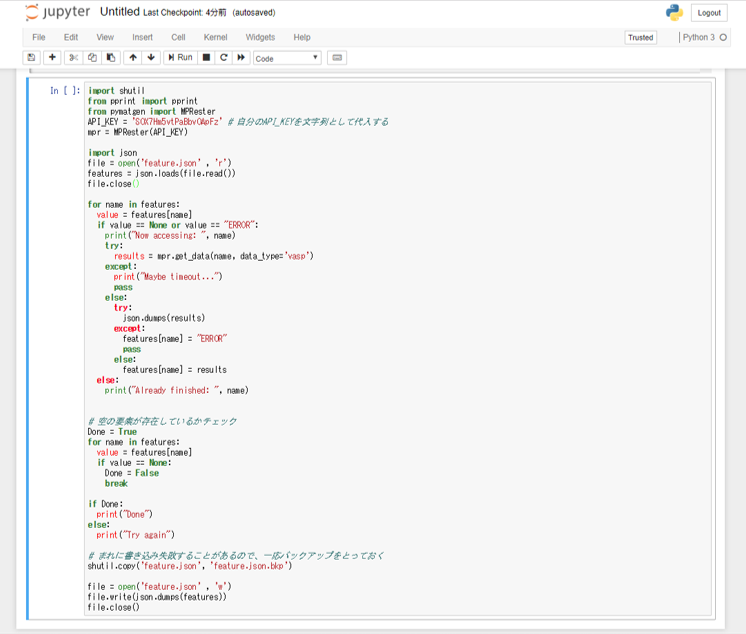
上記のように10分子程度なら問題ありませんが、Materials Projectとの接続は非常に不安定なため、原子種を増やし多量のデータを取得しようとすると一度に全ての物性データを取得できないことがあります。タイムアウトにより物性データが得られなかった物質がある場合"Try again"と打ち出されるので、"Done"と打ち出されるまで何度かget_data.pyを流してください。
get_data.pyより得られたjsonファイルからエラーを除外します。
pymatgenのデータの中にクラス型のデータが含まれているとjsonへの自動変換ができないことがあります。単体では特にERRORになる場合が多いです。上記のコードではクラス型変数の保存には対応していません。
# check_json.py
import json
file = open('feature.json' , 'r')
features = json.loads(file.read())
file.close()
dict = {}
for name in features:
value = features[name]
if value == "ERROR":
print(name, "= ERROR")
elif value == None:
print(name, "= None")
else:
dict[name] = value
データエラーがあった場合に Li = ERROR のように表示されれば、正常に動作しています。
得られたjsonファイルをjson viewerで可視化します。ここではオンラインjson viewerのCode Beautifyを利用します。画面左のコマンドラインにデータをコピーペーストし、Beautifyを押すことでツリー状に可視化されます。
取得データの活用 機械学習を用いた半導体物性予測
得られたデータから機械学習による物性予測を行います。
初めにjson形式で保存したデータをcsv形式にコンバートします。今回は説明変数にdensity、目的変数にband_gapを選択します。
# makeCSV.py
import json
file = open('feature.json' , 'r')
features = json.loads(file.read())
file.close()
import csv
count = 0
listcsv = []
keys = ['density', 'band_gap']
for name in features:
value = features[name]
if value != "ERROR" and value != None:
for v in value:
if v['band_gap'] != 0.0:
count = count + 1
if count > 500: break
dict = {}
for key in keys:
dict[key] = v[key]
listcsv.append(dict)
file = open('feature.csv', 'w')
writer = csv.DictWriter(file, fieldnames=keys, lineterminator='\n')
writer.writeheader()
for l in listcsv:
writer.writerow(l)
file.close()
print('Saved')
csvファイルが得られたあとは半導体物性予測記事のコードに従い物性予測を行います。
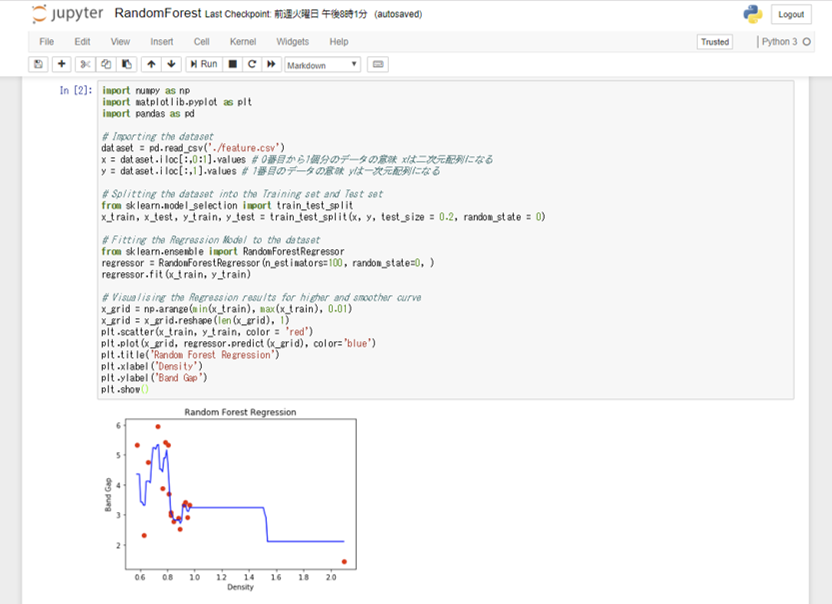
学習は以下のようなフローで進めています。
- pandasを用いてCSVからデータを取得
- sklearnを用いて訓練用データ(train)と検証用データ(test)に分割
- sklearnを用いてランダムフォレストによる回帰の実行
- matplotlibを用いて回帰の結果を可視化
# random_regression.py
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('./feature.csv')
x = dataset.iloc[:,0:1].values #0番目から1個分のデータの意味 xは二次元配列になる
y = dataset.iloc[:,1].values #1番目のデータの意味 yは一次元配列になる
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 0)
# Fitting the Regression Model to the dataset
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor(n_estimators=100, random_state=0, )
regressor.fit(x_train, y_train)
# Visualising the Regression results for higher and smoother curve
x_grid = np.arange(min(x_train), max(x_train), 0.01)
x_grid = x_grid.reshape(len(x_grid), 1)
plt.scatter(x_train, y_train, color = 'red')
plt.plot(x_grid, regressor.predict(x_grid), color='blue')
plt.title('Random Forest Regression')
plt.xlabel('Density')
plt.ylabel('Band Gap')
plt.show()
横軸に実測値、縦軸に予測値をとってグラフ化します。
# visualisation.py
# Visualising the Regression results for higher and smoother curve
plt.scatter(y_train, regressor.predict(x_train), color='blue')
plt.scatter(y_test, regressor.predict(x_test), color='red')
plt.title('Band gap prediction')
plt.xlabel('Measured [eV]')
plt.ylabel('Predicted [eV]')
plt.show()
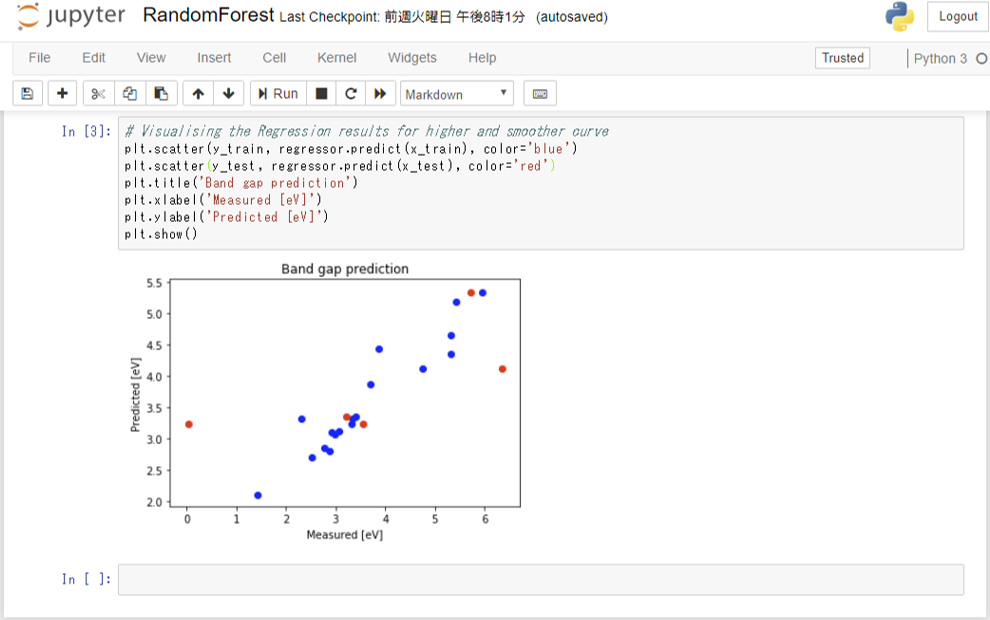
青い点は訓練用データからの予測値、赤は検証用データからの予測であることを意味します。点の分布がy=xに近ければ近いほど、実測値と予測値が近いということですから、予測精度を検証する上で役立ちます。また訓練用データと検証用データの正答率を比較することで、過学習が起こっているかどうかを判断できます。
今回は説明変数として重量密度のみを用いていますから、精度よく学習することは難しいでしょう。
原理的には物質の特徴をよく表す物性値を増やせば学習の精度が向上する可能性があります。