この記事の趣旨
こんにちは。僕は都内大学の大学院に通う学生です(2020年7月時点)。この記事では、僕自身の勉強の一環として、Computer Vision関連の論文の実装をしてみます。具体的には、CVPR 2018から論文を一つ選び、その内容を説明した上で実際に簡単にコードを書いて動かしてみます。僕自身Conputer Visionの中では3Dや深度の話にあまり慣れ親しんでいないので、深度関連の論文を選びました。
選んだ論文とその概要
元論文: https://openaccess.thecvf.com/content_cvpr_2018/papers/Xian_Monocular_Relative_Depth_CVPR_2018_paper.pdf
論文名:Monocular Relative Depth Perception with Web Stereo Data Supervision
著者:SKe Xian, Chunhua Shen, Zhiguo Cao, Hao Lu, Yang Xiao, Ruibo Li, Zhenbo Luo
を選びました(from CVPR2018)。シンプルなネットワーク構造かつインプット自体もRGB画像一枚と簡潔なところが気に入ったからです。
この論文の主な貢献は以下の3つです。
1. インターネットで集めた画像に対して相対的な深度マップを紐づけたデータセット「ReDWeb」を一枚一枚地道にアノテーションすることなく効率的に作成(後述)。
2.End-to-Endなネットワークをranking lossで学習させることで、RGB画像から相対深度マップを生成する手法を提案。
3.(この記事では触れません)データセット「DIW」と「NYUDv2」を用いた実験で提案手法がSoTAなパフォーマンスを発揮することを実証。また、Pre-trainされた提案ネットワークがピクセル単位の予想タスク(Metric Depth Estimation, Semantic Segmentation)に対して有効であることを示した。
具体的には、↓右の深度画像を生成するためのデータセットと、ネットワークの提案になります。

右は提案手法を用いての実際の出力ですが、一枚のRGB画像から正しく相対的な深度が取れていることがわかります。
論文の内容と実装の説明
論文の内容を詳しく追うと共に必要に応じて実装を挟みます。
ReDWebの作成
画像とそれに対応する相対深度マップを集めたいわけですが、画像を収集した上で一枚一枚に人の手で深度マップを作成するのはしんどそうです。そこで、一つの風景を複数の角度から撮影した画像群(論文中でStereo imagesと呼ばれているのでステレオ画像群と呼ぶことにします)を集めて、それらに対してオプティカルフローを適用することで深度マップを自動生成することを考えます。
ステレオ画像群の例を以下に挙げます。



こんなふうに、同じ風景を微妙に異なる角度から撮影した画像セットがステレオ画像群です。オプティカルフローでステレオ画像群から深度マップを抽出する際には、ステレオ画像群が厳密にside-by-sideで(視点の移動が完全に水平で)ある必要があります。ですが、Web上からとってくる画像群が全てそうとは限りません。よって、オプティカルフローを適用した際の出力がデータセットとして使うに耐えないことがあります。そのような不完全な深度マップが得られた時は、後処理をします。
基本的にクオリティが低すぎる画像は手で除外するのですが、それなりに奥行きが正しく取れている画像は採用します。採用された画像を見ると空や遠くの物体の深度が正しく取れていないケースが多いので、そのような曖昧な領域にはSemantic Segmentationを適用して領域のピクセル単位での分割を行います。オプティカルフローで得られた出力に対して適切に後処理を施した例は以下の通りです。

左の元画像は左視点から撮影された画像、中央が処理前で右が処理後です。曖昧だった空と遠くの建物の領域とその深度が明確になったことがわかります。ついでに、右上の木の葉っぱの部分もより正確な領域抽出ができていますね。
こうして作られたReDWebの特性は、以下の表にまとまっています。
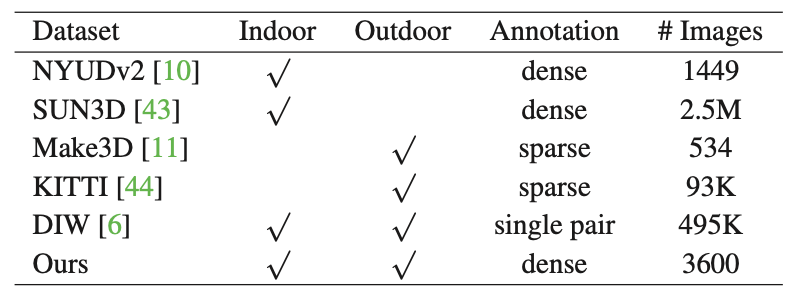
ReDWebは画像数こそ少ないものの、屋外と屋内の幅広いシーンをカバーしており、アノテーションも「密」であることがわかります(denseは細部まで丁寧、的な意味だと解釈してます)。
ネットワークアーキテクチャ
基本的な理念はResNetに由来していて、入力マップをダウンサンプリングしていきます。得られた特徴を再度アップサンプリングすることで深度マップを得ますが、ダウンサンプリングした時点でかなり情報が失われるためアウトプットが粗くなりがちです。そこで、スキップコネクション的にダウンサンプリング中のマップをアップサンプリング中のマップとfusion(日本語でなんて言えばいいのかわからん)させることで失った情報を再度獲得し、細部まで細かな深度マップを実現しています。Semantic Segmentationで出てくるU-Netと似たネットワーク構造です。具体的には、下の図の通りです(先に出せ)。
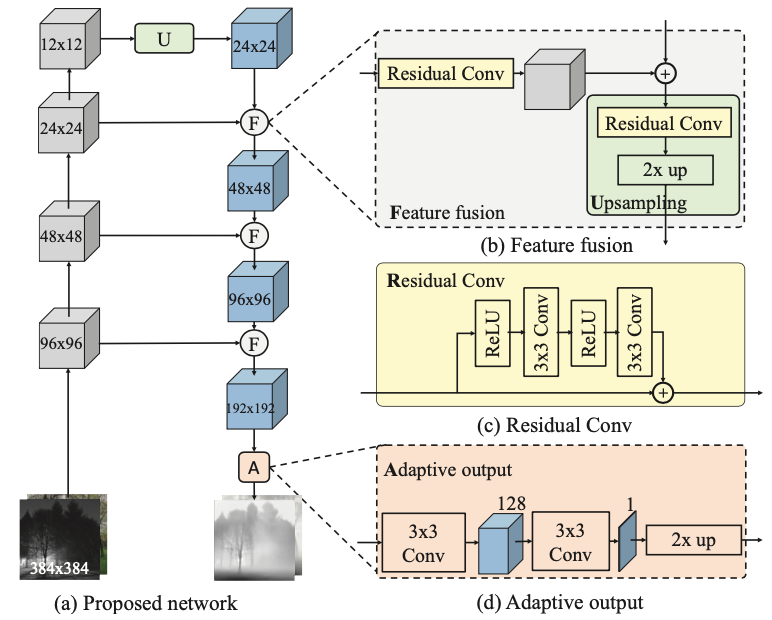
ダウンサンプリング、アップサンプリング、スキップコネクションが基本で、Residual BlockみたくResidual Convが各所に使われています。チャンネル数については図中には明記されていませんが、全て256で統一されているらしいです。また、○に+の記号はsummationであると明記されているため、実装中でもそれに則ろうと思います。
まずは、小さなユニットから実装していきます。Residual Conv(図中でいう黄色のブロック)はネットワーク中での基本的な単位です。図に従って素直に書くと以下のようになります。
import torch.nn as nn
class Residual_Conv(nn.Module):
def __init__(self):
super().__init__()
self.relu = nn.ReLU()
self.conv = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x2 = self.relu(x)
x2 = self.conv(x2)
x2 = self.relu(x2)
x2 = self.conv(x2)
return x + x2
また、Residual ConvとUpsampleを組み合わせたUpsamplingというユニット(図中でいう緑のブロック)は以下の通りです。
class Upsampling(nn.Module):
def __init__(self, width_in):
super().__init__()
self.residual_conv = Residual_Conv()
self.upsample = nn.Upsample(size=(2*width_in, 2*width_in), mode="bilinear")
def forward(self, x):
x = self.residual_conv(x)
x = self.upsample(x)
return x
さらに、最終層でのAdaptive Output(オレンジのブロック)は、以下の通りです。
class Adaptive_Output(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(128, 1, kernel_size=3, stride=1, padding=1)
self.upsample = nn.Upsample(size=(384, 384), mode="bilinear")
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.upsample(x)
return x
これで基本的なユニットが揃いました。次にネットワーク全体の実装に入っていきます。
ダウンサンプリングの際は、畳み込みの操作が必要になります。このネットワーク構造はResNetを基本理念としていることが再三言及されているので、畳み込みの操作もResNet本家に則って、
- 畳み込みレイヤ
- バッチ正規化
- 活性化関数(ReLU)
の3つのまとまりを基本単位として毎回適用することにします。最初のインプットである画像自身はチャンネル数が3(RGB画像だからです)なので、最初の畳み込み操作ではチャンネル数を256に変更します。以降は、この256というチャンネル数を最後まで使い続けることになります。
# 1回目の畳み込み操作
class Conv_Block_first(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 256, kernel_size=3, stride=2, padding=1)
self.batchnorm = nn.BatchNorm2d(256)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
# 2回目以降の畳み込み操作
class Conv_Block(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1)
self.batchnorm = nn.BatchNorm2d(256)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
以上のパーツを組み合わせてネットワーク全体を構築します。具体的には、ダウンサンプリング中の各マップをdown1, down2, down3, down4と名付け、アップサンプリングの過程で出てくるマップも順伝播で処理される順にup1, up2, up3, up4と名付けます。

import torch.nn as nn
from layer import Residual_Conv, Upsampling, Adaptive_Output, Conv_Block_first, Conv_Block
class Whole_Net(nn.Module):
def __init__(self):
super().__init__()
self.convlayer_first = Conv_Block_first()
self.convlayer = Conv_Block()
self.upsample0 = Upsampling(12)
self.upsample1 = Upsampling(24)
self.upsample2 = Upsampling(48)
self.upsample3 = Upsampling(96)
self.residual = Residual_Conv()
self.adaptive = Adaptive_Output()
def forward(self, x):
x = self.convlayer_first(x)
down1 = self.convlayer(x) # 96 * 96
down2 = self.convlayer(down1) # 48 * 48
down3 = self.convlayer(down2) # 24 * 24
down4 = self.convlayer(down3) # 12 * 12
up1 = self.upsample0(down4)
up2 = self.upsample1(up1 + self.residual(down3))
up3 = self.upsample2(up2 + self.residual(down2))
up4 = self.upsample3(up3 + self.residual(down1))
out = self.adaptive(up4)
return out
以上がネットワークアーキテクチャになります。
ミニバッチサンプリングと損失関数
次に、損失関数の作り方について見ていきます。
相対深度を考える上ではRanking Lossという損失関数が有用で、本文でもRanking Lossが用いられています。Ranking Lossを算出するステップとしては
- 正解画像(Ground Truth 以下GT)中から2ピクセルを抽出し、それらの深度を比較する。
- 出力画像(Output)中の同じ場所の2ピクセルを参照して、深度を抽出する。
- 1で出した深度の相対関係と2で出した深度を用いて、Lossの算出を行う
- 1から3のステップを十分な数繰り返し、Lossの総和を取る
という手順になります。2ピクセルをランダムにサンプリングする過程(ステップ1)は、本文中でミニバッチサンプリングと呼ばれています。ステップ1ですが、GT中の2ピクセル(iとjとします)の比を取って、以下のようにl(エルです。エルと大文字のアイ紛らわしい...)を算出します。
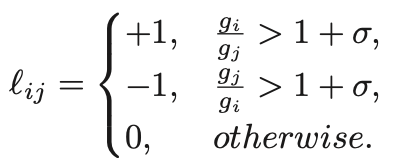
ざっくり言って、GT中の2ピクセルがどのくらい顕著にかけ離れているかどうかを見ていると解釈できます。次にステップ2ですが、出力画像の同じ箇所を見て、ピクセル値を参照します。そしてステップ3では、具体的に算出を行います。
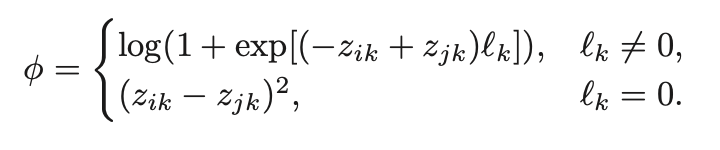
先ほど算出したl(エル)は、一つ目の式中で使われています。要するに、GTの深度の関係(どっちの点がより深くてどっちがより浅いか)を見て、Output中でもその関係性が正しく保たれていればボーナス、間違っていれば損失を与えるという仕組みになっています。なお、GT中で2ピクセルの深度が近いと判断された場合は、Output中の該当する2ピクセルの深度も当然近くなければいけないため、純粋に2ピクセルの差の絶対値を2乗した値がLossに加算されます。以上がRanking Lossの説明になります。
このようにして算出されたφを足し合わせて晴れてRanking Lossとなるわけですが、この論文中で使われるRanking Lossはそこからさらに一段階改善がなされています。以下の式を見てください。
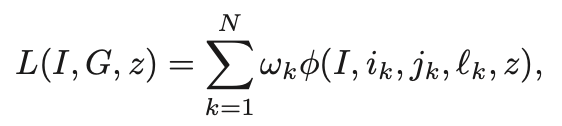
係数としてωが掛けられています。ωは0か1の値をとります。全てのωが1を取る場合は、全てのφを単純に足し合わせていることになるので、ただのRanking Lossです。しかしこの論文では、全てのφの値をソートして、下25%の値となったφ(値が大して大きくないφ)については、ωの値を0にしています。φの値が小さい場合は、2つのピクセルの値がかなり近い(= そこまで大きなペナルティを与える必要がない)状態であるため、そこに損失を発生させてしまうと、過度にパラメータの調整を行わせてしまうことになります。そのような学習のやりすぎ(≠ 過学習)的な状態を防ぐ目的で、φが小さな値を取る場合にはωの値が0に設定されています。この工夫が加えられたRanking Lossは論文中でImproved Ranking Lossと呼ばれており、実際普通のRanking Lossを使うよりも良い結果が得られるようです。
今回は学習させるモデルはImageNetの画像による事前学習などが全くなされていないため、パラメータの更新をより大幅に行いたいです。そこで、Improved Ranking Lossでなく単純なRanking Lossを採用します。Improved Ranking Lossの場合は、以下の実装に加えて、算出されたφの値をソートして上75%を採用すればokです。全体像をはじめに示します。
import random
import torch
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Ranking_Loss(nn.Module):
def __init__(self, N, minibatch):
super().__init__()
self.N = N
self.minibatch = minibatch
def calculate_l(self, x1, y1, x2, y2, gt):
pix1 = gt[:, x1, y1]
pix2 = gt[:, x2, y2]
ls = torch.zeros(self.minibatch)
for i in range(self.minibatch):
if pix1[i] / (pix2[i] + 1e-7) > 1.02:
ls[i] = 1
elif pix2[i] / (pix1[i] + 1e-7) > 1.02:
ls[i] = -1
return ls
def calculate_phi(self, x1, y1, x2, y2, gt, output):
ls = self.calculate_l(x1, y1, x2, y2, gt).to(device)
pred_depth = (output[:, x1, y1] - output[:, x2, y2]).to(device)
log_loss = torch.mean(torch.log(1 + torch.exp(-ls[ls != 0] * pred_depth[ls != 0])))
if pred_depth[ls==0].shape[0] != 0:
squared_loss = torch.mean(pred_depth[ls == 0] ** 2)
return log_loss + squared_loss
return log_loss
def random_sampling(self):
x1 = random.randint(0, 383)
y1 = random.randint(0, 383)
x2 = random.randint(0, 383)
y2 = random.randint(0, 383)
return x1, y1, x2, y2
def calculate_main(self, gt, output):
gt = gt.squeeze(1)
output = output.squeeze(1)
loss = 0
for i in range(self.N):
x1, y1, x2, y2 = self.random_sampling()
loss += self.calculate_phi(x1, y1, x2, y2, gt, output)
return loss / self.N
random_samplingの部分でピクセルのランダム抽出を行っています。calculate_lでは、GT中の2ピクセルのサンプリングからのlの値の算出を行っており、それを用いてcalculate_phiで具体的なφの値を計算しています。calculate_mainで、サンプル数を含め全体を管理し、最終的なRanking_Lossを算出しています。
以上が論文のざっくりとした内容説明と実装になります。ここからは実際にデータセットを使ってモデルの学習と推論を行います。
実験: データセットを用いた学習と推論
まず、具体的な学習に入っていくにあたって、Dataloaderの準備をする必要があります。Datasetは以下のように実装しました。
import glob
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
import torch
from torchvision import transforms
class Image_Transform():
def __init__(self, resize=384, mean=(0.485, 0.224, 0.406), std=(0.229, 0.224, 0.225), train=True):
self.data_transform = {
'img': transforms.Compose([
transforms.Resize(resize),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
'rd': transforms.Compose([
transforms.Resize(resize),
transforms.CenterCrop(resize),
transforms.ToTensor(),
])
}
if train == False:
self.data_transform['img'] = transforms.Compose([
transforms.Resize(resize),
transforms.CenterCrop(resize),
transforms.ToTensor(),
])
def __call__(self, img, img_or_rd='img'):
return self.data_transform[img_or_rd](img)
class Dataset(torch.utils.data.Dataset):
def __init__(self, transform=None, test=False):
self.imgs = glob.glob('./redweb/imgs/*.jpg')
self.rds = glob.glob('./redweb/rds/*.png')
if test:
self.imgs = glob.glob("./test_imgs/*.jpg")
self.transform = transform
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img_path = self.imgs[idx]
img = Image.open(img_path)
img_transformed = self.transform(img, img_or_rd='img')
rd_path = self.rds[idx]
rd = Image.open(rd_path)
rd_transformed = self.transform(rd, img_or_rd='rd')
return img_transformed, rd_transformed
ReDWeb中のRGB画像にはリサイズの後に正規化の処理を施し、深度画像の方はリサイズだけです。
論文中で用いられるモデルは事前学習済みのResNetをベースとしています。ですが、今回は1からモデルを構築したため、事前学習などがなされていません。そこで、事前学習としてL2 Lossを用いて学習後、Ranking Lossを用いてメインの学習を進めることにします。
- 論文: ResNetがImageNetによる事前学習 → Improved Ranking Lossを用いた学習
- 今回: L2 Lossによる直接的な事前学習 → Ranking Lossを用いた学習
最適化関数としてはAdamを用い、学習中のバッチサイズは16に設定し、事前学習には10エポック(5だと学習不足で、15だと過学習してしまい全ての深度画像が一定のパターンに陥っていたため)、メインの学習にも10エポックを使いました。
ReDWebの画像3600枚全てを学習に使い、最終的なテストはMSCOCOから取ってきた画像で行いました。
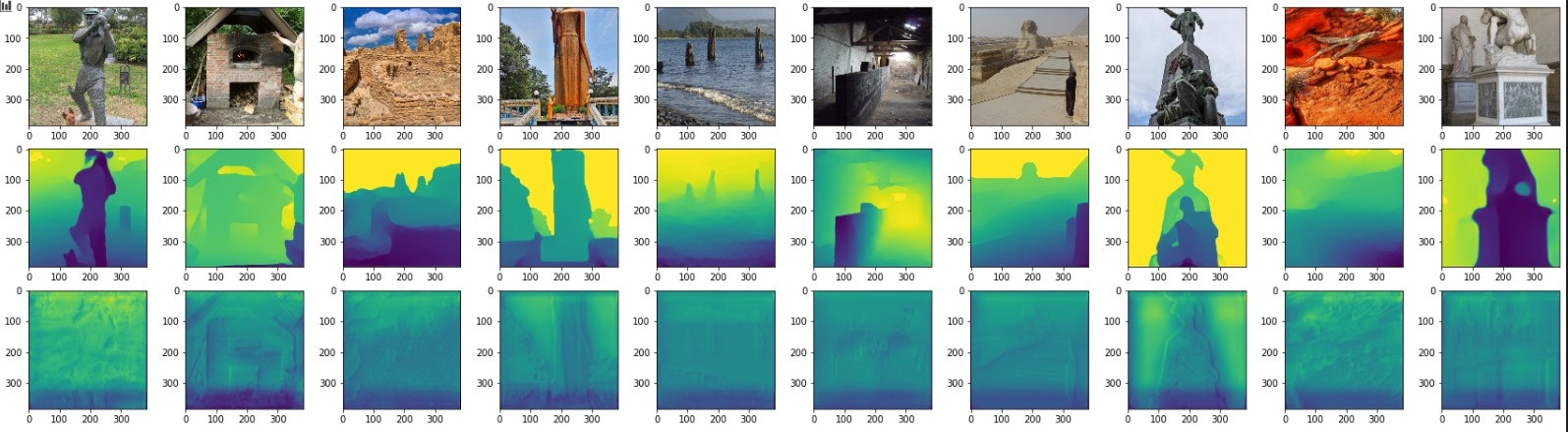
事前学習後の、学習データに対する出力は以下の通りです。一段目が元の画像、二段目が正解画像、三段目が出力になります。出力から元画像のエッジがわずかに確認できます。
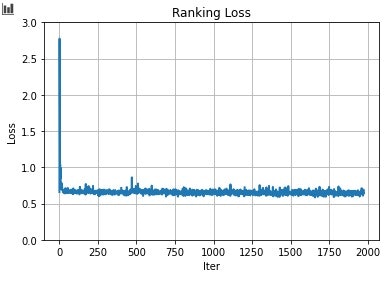
メインの学習におけるLossの値は以下の通りです。Lossがnanとなったケースは省かれているので、実際より少なめのIterとなっています。ほぼ値に変化がなく、学習が進んでいるのか微妙な気が...
MSCOCOからの画像を用いて出力した結果は以下の通りです。(一段目元画像、二段目出力)
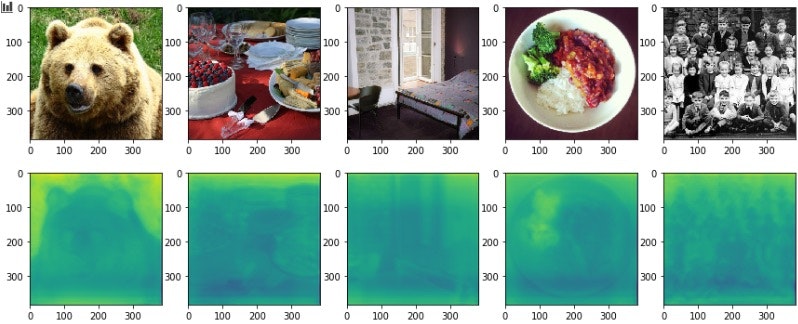
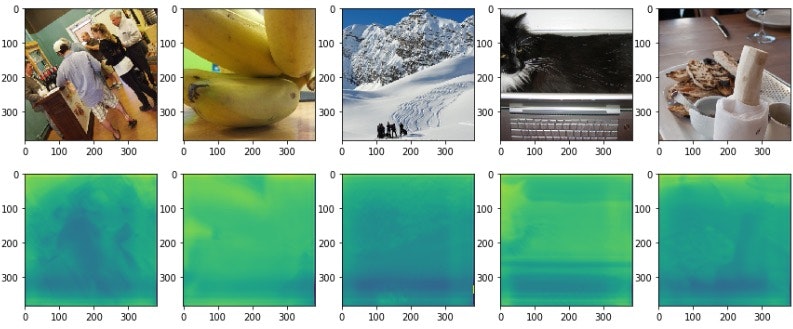
深度が正しく取れているかというと、かなり怪しい気がします。大まかには領域の色塗りはうまくいっているようですが、明らかに同じ距離にある物体が色ごとに全く異なる深度を示していたり、所々怪しいですね。一行目四枚目のお皿の上のブロッコリーや、二段目二枚目のバナナなんかはうまく深度が取れていない例だと思います。それと全体的に画像の下の方は深度が浅い(=近いところにある)という大まかな傾向が学習されていることがわかります。どの画像を見ても下の方が陰っぽくなっているからです。
だた正しく取れているっぽい箇所も散見されて、基本的に大まかには深度は正しく取れるが特定の物体の存在(形状自体や特異な色)に左右されやすいことがわかります。
今回定量的な指標による評価は行わないためここまでです。論文中ではWHDRという指標に基づいた評価がなされているので是非チェックしてみてください。
終わりに
今回はCVPR2020から深度マップを生成するタスクに取り組んだ論文を持ってきて、簡単に実装してみました。Ranking Lossを用いた学習では大まかに深度が取れる(ほんとか?)ものの細部までは難しいことがみて取れました。といっても僕の実装、特にRanking Lossのところに誤りがある可能性がかなり濃厚なので、ここが間違っているとか、ここコードは改善の余地があるみたいなご指摘がありましたら書き込んでいただけると幸いです。また、この論文、実装を理解する上で助けになる論文、他の方の実装などがありましたらそちらも教えていただけると幸いです。ご覧いただきありがとうございました。