arxiv: https://arxiv.org/abs/1904.09730
正式な論文タイトルは "An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection".
つまり、この論文ではGPU上でリアルタイム実行するときに本当に性能の良いモデルはなにかということを理論的に考察している。また、考察の結果としてOne-Shot Aggregationというアーキテクチャを提案している。
既存の研究とその問題
**DenseNet**は出力をすべての後続のレイヤーの出力にconcatする。
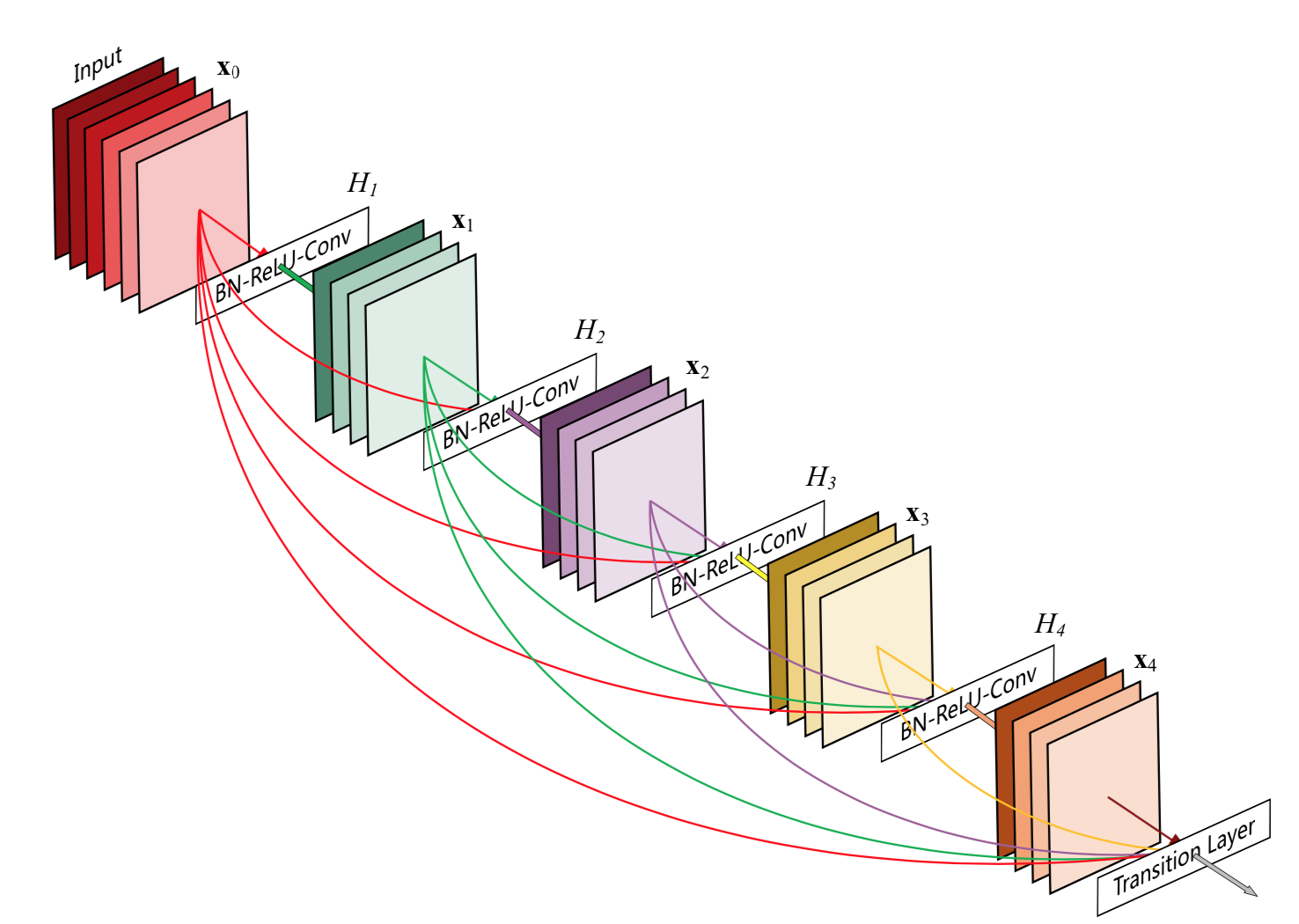
ResNetと比べて前のレイヤーの情報を累積・保存できるという点で優れているが、
-
層の深さの2乗に比例してメモリアクセスが増える
- MAC(Memory Access Cost)が大きくなる(後述)
- そのままではえげつないペースで入力チャンネル数が増えるので、Dense Block内で1x1 conv (bottleneck layer)→3x3 convという構造にし、チャンネルの増加率を成長率kに減らしている
-
1
- しかし、それは巨大なテンソルの計算に適したGPUの長所を削る結果になってしまっている
-
まとめると、DenseNetは理論上のFLOPSは小さいが実際のGPU上ではエネルギー・時間的に非効率的である。
(なお、これらの性質自体はすでに知られていた。例えば……
- ShuffleNet v2はMobileNet v2と同じくらいのFLOPSだがより速く走る
- SqueezeNetのパラメータ数はAlexNetの50分の1だが、エネルギー消費量はむしろ大きい)
→FLOPSやパラメータ数より実用的な測定基準として、FPS[image/sec]とenergy per image[J/image]でこの論文では考える。実際の計算時は
\text{Energy per iamge[J/image]} = \frac{\text{Average Power[J/sec = W]}}{\text{FPS[image/sec]}}
で求めている。$\text{Average Power}$はご存知nvidia-smiで測定する
モデルの効率に対する考察
MAC
メモリアクセスコスト (MAC) は
\operatorname{MAC}=h w\left(c_{i}+c_{o}\right)+k^{2} c_{i} c_{o}
で表される
- 第一項が画像へのアクセス
- 第二項がフィルターへのアクセス
- 一度アクセスすればキャッシュに保存しておけるとする
パラメータ数に関係なく、たとえば特徴マップ ($hw$) が大きければMACは大きくなり、また計算量も増える
CNNのエネルギー消費の主要な原因はメモリアクセスであり、またメモリアクセスは時間もかかるので**計算時間のボトルネックにもなりうる。**MACを小さくすることは重要である。
GPU計算効率
上述したように、GPUは巨大なデータテンソルの計算が得意である。
大きなconvの前に1x1を挟んだり、1x1+depthwiseに取り替えることも、一見FLOPSやパラメータ数をへらすが、GPU的にはあまり嬉しくない。
提案手法
DenseNetの問題点まとめ
-
DenseNetでは、層が深くなるごとに線形にチャンネルがガンガン増える
-
FLOPSあたりに新しく得られる特徴量が少ない
-
Dense Connectionのおかげで特徴の質は良いが、特徴の量はあまり増やせなくなってしまった
-
メモリアクセスコストが大きい
-
相加相乗平均より$c_i = c_o$のときにMACは最小になる、すなわち
-
MAC \geq 2hw\sqrt{c_ic_o} + k^2c_ic_o = 2 \sqrt{\frac{h w B}{k^{2}}}+\frac{B}{h w}
* $B=k^{2} h w c_{i} c_{o}$はFLOPS。FLOPSによってMACの下界が決まっている、言い換えれば、**FLOPSが同じなら$c_i = c_o$を満たすと一番嬉しい** * だがDenseNetでは$c_o$が一定であるのに対して$c_i$が線形に大きくなるのでこれらが大きく異なり、MACも大きくなってしまう(詳しくは[下の図](#one-shot-aggregation)を見よ) -
-
GPUの並列計算に対する強さを損なう
- 1x1 convはGPU的にはあまり嬉しくないので
重みの考察
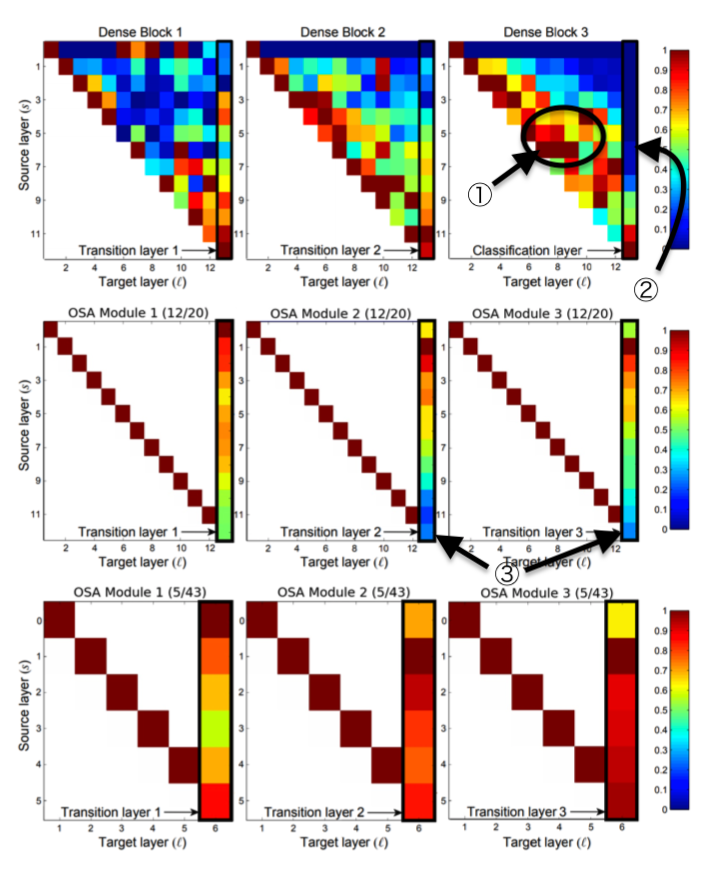
Dense Block3でTransition Layerはあまり中央のレイヤーを使っていない(②)が中央のレイヤーは中央のレイヤー自身をよく使っている(①)。Dense Block1では逆。
→負の相関があり、片方があれば十分ということは、無駄に情報を伝えている?
One-Shot Aggregation
これは無駄なので、最終層でのみconcatする新たなアーキテクチャ(One-Shot Aggregation, OSA)を提案
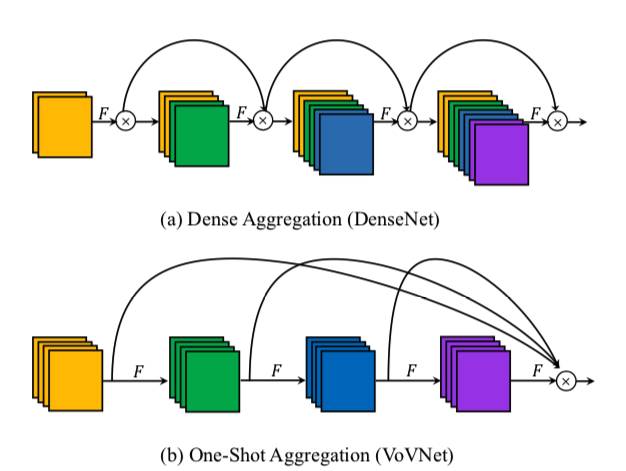
- これは各コンボリューションに対して$c_{i}=c_{o}$、MAC最小化条件を満たす
- 上の図にチャンネル数を明記すると以下のようになる:
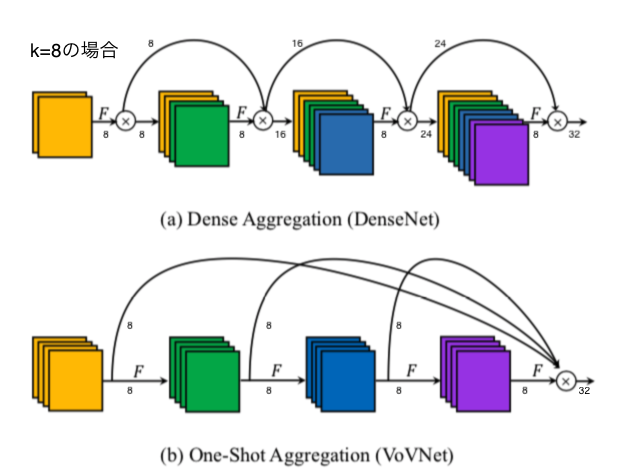
- Denseblockでは入力チャンネル数と出力チャンネル数がだんだん食い違っていくが、OSAでは常に同じであることがわかる
- 上の図にチャンネル数を明記すると以下のようになる:
- 1x1 convはブロック(OSA Module)の最後にのみ使われ、一気にチャンネルを圧縮する
モデルの詳細な仕様は以下の通り:
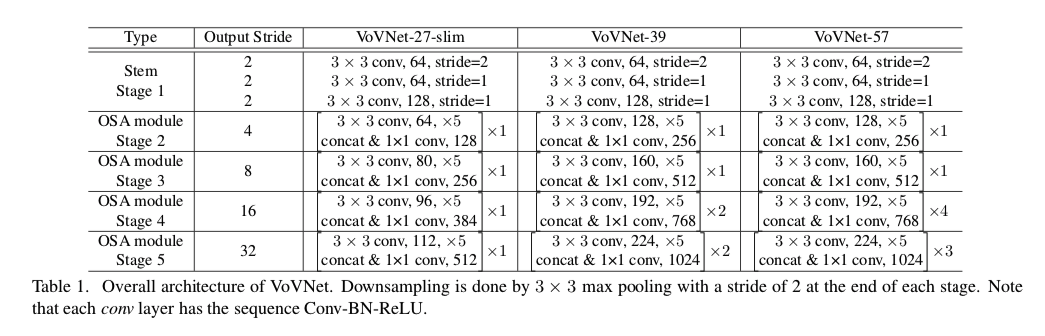
- まずStem Stageと呼ばれる初めの層で基本的なConvolutionを行う2
- その次にOSA Moduleを4回積み重ねる
- OSA Moduleの設定が3つの各モデルで異なる
- 例えば27-SlimのStage 2だと、各convが64チャンネル出力するので、最後に$64\times 5=320$チャンネルがconcatenateされ、それを1x1 convで128にまで減らす
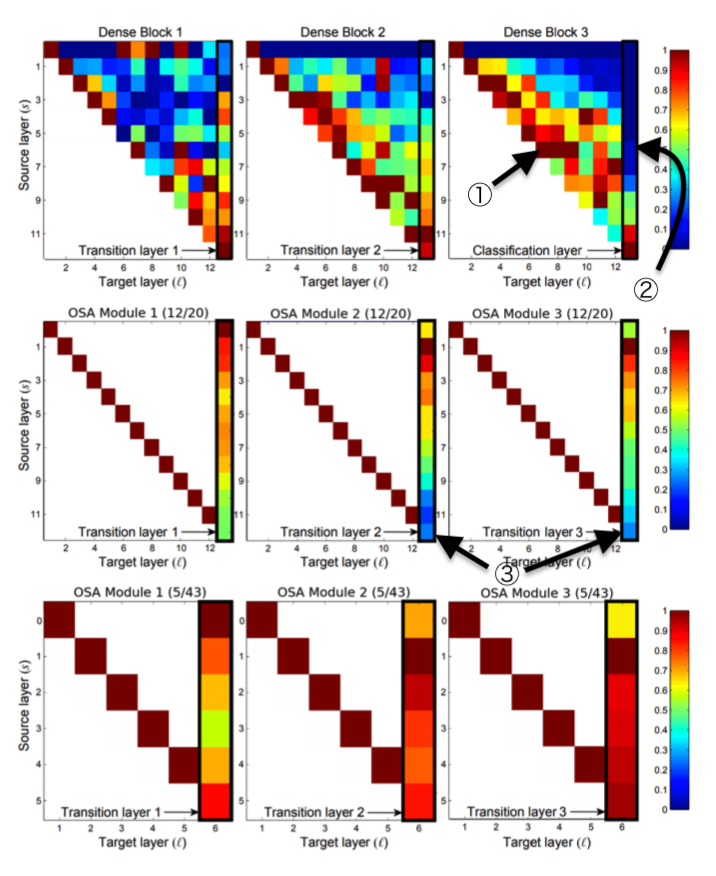
また、OSA Module内のconvの回数を最初は12回にしていたが、③に示されるように最後の方のレイヤーの出力は最後の1x1 convであまり使われていない。
これを取り除いてもさして影響はないと思われたので、最終的にひとつのOSA内のconvの数は5回とされた。
実験
VoV vs Dense
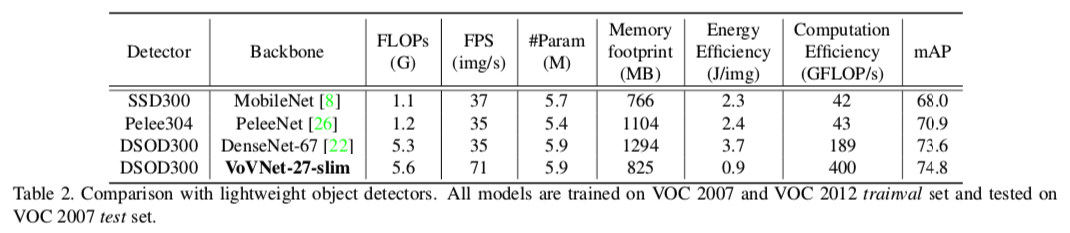
- SSD300-MobileNetがベースライン
- PeleeはDenseBlockやprediction blockにResblockを導入した新しい画像認識モデル
結果
- VoV27は同程度のパラメータ数であるDense67に実測値で勝利。
- FLOPS自体も同程度だが、計算効率(Computation Efficiency)が2倍近く良いので結果としてFPSでは圧勝
- エネルギー効率も4.1倍良い
- PeleeはFLOPS的にはこれらより小さいのに、実際の推論速度はDense67並で残念な感じ
- GPU的にはPeleeの特徴であるdense blockの小さい切り分けは嬉しくないのだろう
- 【参考】(a)がDense Layer, (b)がPeleeで使われた2way dense layer
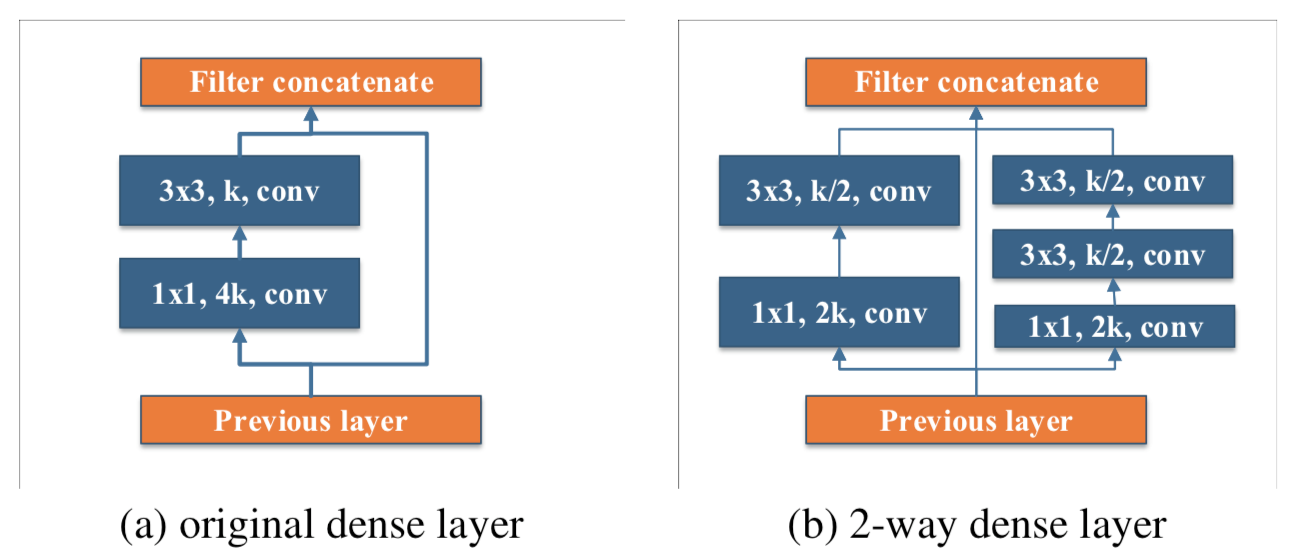
- 中間特徴マップの数も増えてしまうので、メモリアクセスも大きくなってしまう
- MobileNetはメモリー消費量的には小さいのに、エネルギー効率は悪い
- depthwise convがばらばらに (fragmented) メモリアクセスするから効率が悪い
Ablation study on 1x1 conv bottleneck
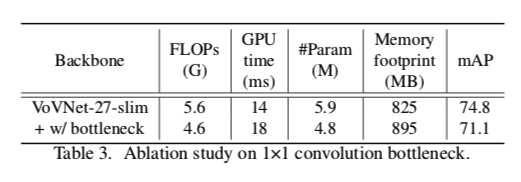
3x3 convのあとに逐一bottleneck layer(1x1 conv)を挟んだら、FLOPSもパラメータ数も減ったけど実際の実行時間とかは伸びてしまったよ😢という図
「1x1 convはリアルタイム推論にとって嬉しくない」という仮説を交絡因子を減らして示した対照実験と言える
もちろん精度も微減😢
RefineDetにいろいろなものを載せてみる
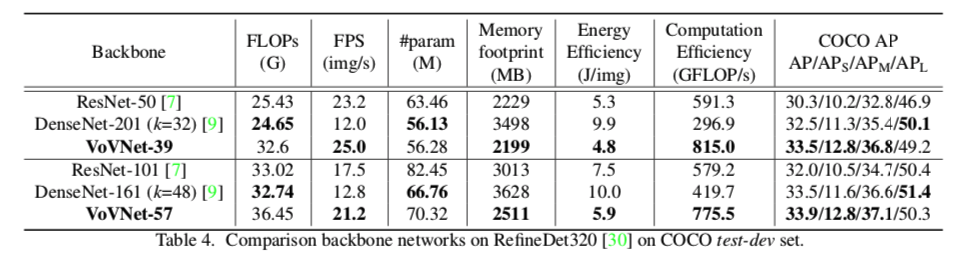
結果
- DenseNet-201(k=32)がDenseNet-161(k=48)よりFLOPSは少ないのに遅い
- 計算効率が悪いことがわかる
- (特徴マップが)薄く、深層であるモデルはGPUの並列計算的には非効率であると考えられる3
- 同じVoVNetでも、メモリフットプリントが少ないもののほうがエネルギー効率はいい
-
小さい物体の検出にはVoVNet/DenseNetが強い
- concatによる特徴表現の集積が効いていると思われる
Kerasによる実装例
DenseNetと同じく実装は非常に簡単。Classifierとして軽く訓練してみたが、DenseNetより速くて性能も良い感じだ。
次回は、これを用いて訓練スピードなどを定量的にDenseNetと比較していこうと思う。乞うご期待!
この記事は、METRICAの社内勉強会用の資料を改稿して作りました。
[2019/7/7追記]後編できました。